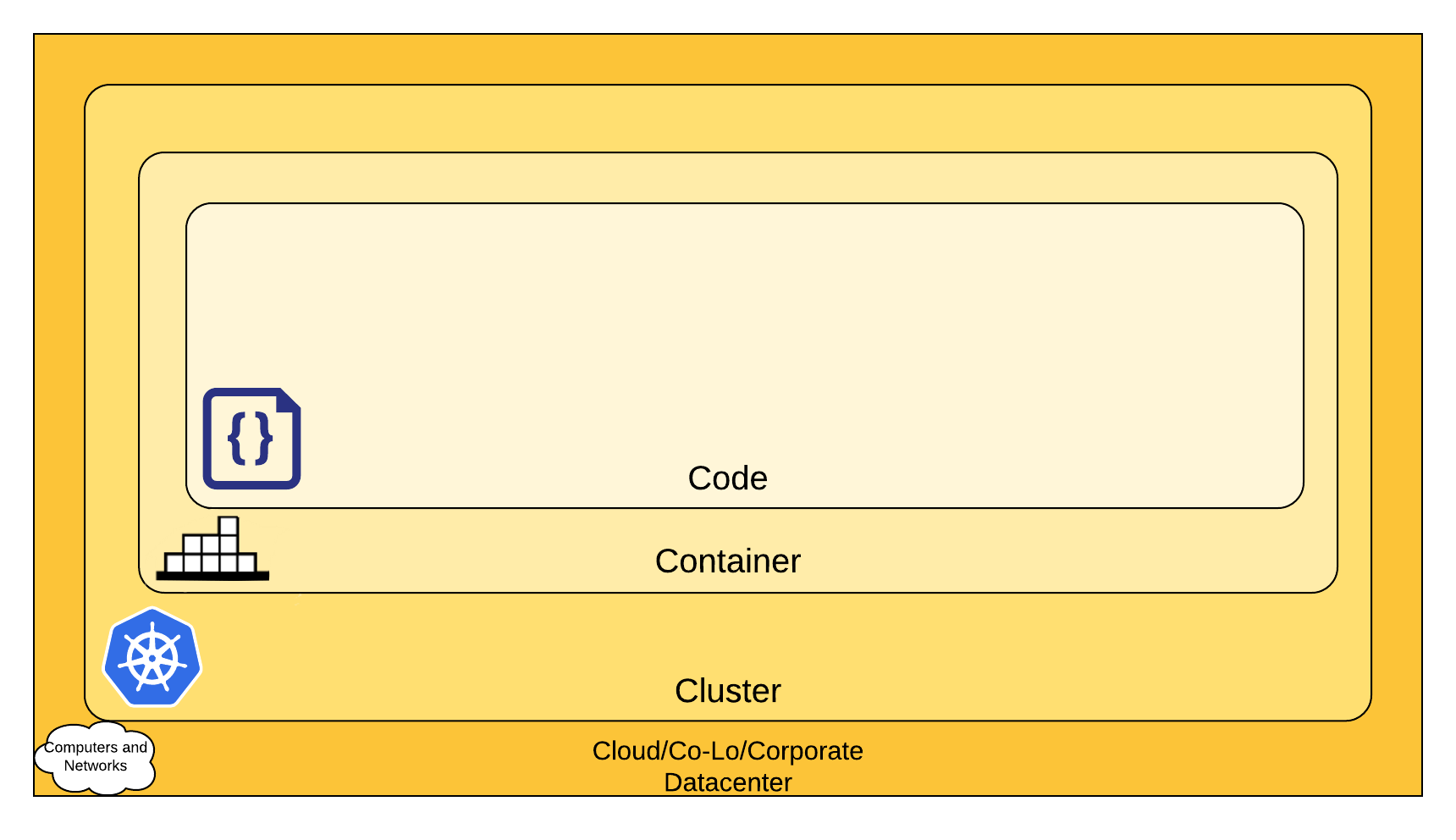
コンセプト
本セクションは、Kubernetesシステムの各パートと、クラスター を表現するためにKubernetesが使用する抽象概念について学習し、Kubernetesの仕組みをより深く理解するのに役立ちます。
概要
Kubernetesを機能させるには、Kubernetes API オブジェクト を使用して、実行したいアプリケーションやその他のワークロード、使用するコンテナイメージ、レプリカ(複製)の数、どんなネットワークやディスクリソースを利用可能にするかなど、クラスターの desired state (望ましい状態)を記述します。desired state (望ましい状態)をセットするには、Kubernetes APIを使用してオブジェクトを作成します。通常はコマンドラインインターフェース kubectl を用いてKubernetes APIを操作しますが、Kubernetes APIを直接使用してクラスターと対話し、desired state (望ましい状態)を設定、または変更することもできます。
一旦desired state (望ましい状態)を設定すると、Pod Lifecycle Event Generator(PLEG )を使用したKubernetes コントロールプレーン が機能し、クラスターの現在の状態をdesired state (望ましい状態)に一致させます。そのためにKubernetesはさまざまなタスク(たとえば、コンテナの起動または再起動、特定アプリケーションのレプリカ数のスケーリング等)を自動的に実行します。Kubernetesコントロールプレーンは、クラスターで実行されている以下のプロセスで構成されています。
Kubernetesオブジェクト
Kubernetesには、デプロイ済みのコンテナ化されたアプリケーションやワークロード、関連するネットワークとディスクリソース、クラスターが何をしているかに関するその他の情報といった、システムの状態を表現する抽象が含まれています。これらの抽象は、Kubernetes APIのオブジェクトによって表現されます。詳細については、Kubernetesオブジェクトについて知る をご覧ください。
基本的なKubernetesのオブジェクトは次のとおりです。
Kubernetesには、コントローラー に依存して基本オブジェクトを構築し、追加の機能と便利な機能を提供する高レベルの抽象化も含まれています。これらには以下のものを含みます:
Kubernetesコントロールプレーン
Kubernetesマスターや kubeletプロセスといったKubernetesコントロールプレーンのさまざまなパーツは、Kubernetesがクラスターとどのように通信するかを統制します。コントロールプレーンはシステム内のすべてのKubernetesオブジェクトの記録を保持し、それらのオブジェクトの状態を管理するために継続的制御ループを実行します。コントロールプレーンの制御ループは常にクラスターの変更に反応し、システム内のすべてのオブジェクトの実際の状態が、指定した状態に一致するように動作します。
たとえば、Kubernetes APIを使用してDeploymentを作成する場合、システムには新しいdesired state (望ましい状態)が提供されます。Kubernetesコントロールプレーンは、そのオブジェクトの作成を記録します。そして、要求されたアプリケーションの開始、およびクラスターノードへのスケジューリングにより指示を完遂します。このようにしてクラスターの実際の状態を望ましい状態に一致させます。
Kubernetesマスター
Kubernetesのマスターは、クラスターの望ましい状態を維持する責務を持ちます。kubectl コマンドラインインターフェースを使用するなどしてKubernetesとやり取りするとき、ユーザーは実際にはクラスターにあるKubernetesのマスターと通信しています。
「マスター」とは、クラスター状態を管理するプロセスの集合を指します。通常これらのプロセスは、すべてクラスター内の単一ノードで実行されます。このノードはマスターとも呼ばれます。マスターは、可用性と冗長性のために複製することもできます。
Kubernetesノード
クラスターのノードは、アプリケーションとクラウドワークフローを実行するマシン(VM、物理サーバーなど)です。Kubernetesのマスターは各ノードを制御します。運用者自身がノードと直接対話することはほとんどありません。
次の項目
コンセプトページを追加したい場合は、
ページテンプレートの使用
のコンセプトページタイプとコンセプトテンプレートに関する情報を確認してください。
1 - 概要
Kubernetesは、宣言的な構成管理と自動化を促進し、コンテナ化されたワークロードやサービスを管理するための、ポータブルで拡張性のあるオープンソースのプラットフォームです。Kubernetesは巨大で急速に成長しているエコシステムを備えており、それらのサービス、サポート、ツールは幅広い形で利用可能です。
このページでは、Kubernetesの概要について説明します。
Kubernetesは、宣言的な構成管理と自動化を促進し、コンテナ化されたワークロードやサービスを管理するための、ポータブルで拡張性のあるオープンソースのプラットフォームです。Kubernetesは巨大で急速に成長しているエコシステムを備えており、それらのサービス、サポート、ツールは幅広い形で利用可能です。
Kubernetesの名称は、ギリシャ語に由来し、操舵手やパイロットを意味しています。
"K"と"s"の間にある8つの文字を数えることから、K8sが略語として使われています。
Googleは2014年にKubernetesプロジェクトをオープンソース化しました。
Kubernetesは、本番環境で大規模なワークロードを稼働させたGoogleの15年以上の経験 と、コミュニティからの最高のアイディアや実践を組み合わせています。
過去を振り返ってみると
過去を振り返って、Kubernetesがなぜこんなに便利なのかを見てみましょう。
仮想化ができる前の時代におけるデプロイ (Traditional deployment): 初期の頃は、組織は物理サーバー上にアプリケーションを実行させていました。物理サーバー上でアプリケーションのリソース制限を設定する方法がなかったため、リソースの割当問題が発生していました。例えば、複数のアプリケーションを実行させた場合、ひとつのアプリケーションがリソースの大半を消費してしまうと、他のアプリケーションのパフォーマンスが低下してしまうことがありました。この解決方法は、それぞれのアプリケーションを別々の物理サーバーで動かすことでした。しかし、リソースが十分に活用できなかったため、拡大しませんでした。また組織にとって多くの物理サーバーを維持することは費用がかかりました。
仮想化を使ったデプロイ (Virtualized deployment): ひとつの解決方法として、仮想化が導入されました。1台の物理サーバーのCPU上で、複数の仮想マシン(VM)を実行させることができるようになりました。仮想化によりアプリケーションをVM毎に隔離する事ができ、ひとつのアプリケーションの情報が他のアプリケーションから自由にアクセスさせないといったセキュリティレベルを提供することができます。
仮想化により、物理サーバー内のリソース使用率が向上し、アプリケーションの追加や更新が容易になり、ハードウェアコストの削減などスケーラビリティが向上します。仮想化を利用すると、物理リソースのセットを使い捨て可能な仮想マシンのクラスターとして提示することができます。
各VMは、仮想ハードウェア上で各自のOSを含んだ全コンポーネントを実行する完全なマシンです。
コンテナを使ったデプロイ (Container deployment): コンテナはVMと似ていますが、アプリケーション間でオペレーティング・システム(OS)を共有できる緩和された分離特性を持っています。そのため、コンテナは軽量だといわれます。VMと同じように、コンテナは各自のファイルシステム、CPUの共有、メモリー、プロセス空間等を持っています。基盤のインフラストラクチャから分離されているため、クラウドやOSディストリビューションを越えて移動することが可能です。
コンテナは、その他にも次のようなメリットを提供するため、人気が高まっています。
アジャイルアプリケーションの作成とデプロイ: VMイメージの利用時と比較して、コンテナイメージ作成の容易さと効率性が向上します。
継続的な開発、インテグレーションとデプロイ: 信頼できる頻繁なコンテナイメージのビルドと、素早く簡単にロールバックすることが可能なデプロイを提供します。(イメージが不変であれば)
開発者と運用者の関心を分離: アプリケーションコンテナイメージの作成は、デプロイ時ではなく、ビルド/リリース時に行います。それによって、インフラストラクチャとアプリケーションを分離します。
可観測性: OSレベルの情報とメトリクスだけではなく、アプリケーションの稼働状態やその他の警告も表示します。
開発、テスト、本番環境を越えた環境の一貫性: クラウドで実行させるのと同じようにノートPCでも実行させる事ができます。
クラウドとOSディストリビューションの可搬性: Ubuntu、RHEL、CoreOS上でも、オンプレミスも、主要なパブリッククラウドでも、それ以外のどんな環境でも、実行できます。
アプリケーション中心の管理: 仮想マシン上でOSを実行するから、論理リソースを使用してOS上でアプリケーションを実行するへと抽象度のレベルを向上させます。
疎結合、分散化、拡張性、柔軟性のあるマイクロサービス: アプリケーションを小さく、同時にデプロイと管理が可能な独立した部品に分割されます。1台の大きな単一目的のマシン上に実行するモノリシックなスタックではありません。
リソースの分割: アプリケーションのパフォーマンスが予測可能です。
リソースの効率的な利用: 高い効率性と集約性が可能です。
Kubernetesが必要な理由と提供する機能
コンテナは、アプリケーションを集約して実行する良い方法です。本番環境では、アプリケーションを実行しダウンタイムが発生しないように、コンテナを管理する必要があります。例えば、コンテナがダウンした場合、他のコンテナを起動する必要があります。このような動作がシステムに組込まれていると、管理が簡単になるのではないでしょうか?
そこを助けてくれるのがKubernetesです! Kubernetesは分散システムを弾力的に実行するフレームワークを提供してくれます。あなたのアプリケーションのためにスケーリングとフェイルオーバーの面倒を見てくれて、デプロイのパターンなどを提供します。例えば、Kubernetesはシステムにカナリアデプロイを簡単に管理することができます。
Kubernetesは以下を提供します。
サービスディスカバリーと負荷分散
Kubernetesは、DNS名または独自のIPアドレスを使ってコンテナを公開することができます。コンテナへのトラフィックが多い場合は、Kubernetesは負荷分散し、ネットワークトラフィックを振り分けることができるため、デプロイが安定します。ストレージ オーケストレーション
Kubernetesは、ローカルストレージやパブリッククラウドプロバイダーなど、選択したストレージシステムを自動でマウントすることができます。自動化されたロールアウトとロールバック
Kubernetesを使うとデプロイしたコンテナのあるべき状態を記述することができ、制御されたスピードで実際の状態をあるべき状態に変更することができます。例えば、アプリケーションのデプロイのために、新しいコンテナの作成や既存コンテナの削除、新しいコンテナにあらゆるリソースを適用する作業を、Kubernetesで自動化できます。自動ビンパッキング
コンテナ化されたタスクを実行するノードのクラスターをKubernetesへ提供します。各コンテナがどれくらいCPUやメモリー(RAM)を必要とするのかをKubernetesに宣言することができます。Kubernetesはコンテナをノードにあわせて調整することができ、リソースを最大限に活用してくれます。自己修復
Kubernetesは、処理が失敗したコンテナを再起動し、コンテナを入れ替え、定義したヘルスチェックに応答しないコンテナを強制終了します。処理の準備ができるまでは、クライアントに通知しません。機密情報と構成管理
Kubernetesは、パスワードやOAuthトークン、SSHキーなどの機密の情報を保持し、管理することができます。機密情報をデプロイし、コンテナイメージを再作成することなくアプリケーションの構成情報を更新することができます。スタック構成の中で機密情報を晒してしまうこともありません。
Kubernetesにないもの
Kubernetesは、従来型の全部入りなPaaS(Platform as a Service)のシステムではありません。Kubernetesはハードウェアレベルではなく、コンテナレベルで動作するため、デプロイ、スケーリング、負荷分散といったPaaSが提供するのと共通の機能をいくつか提供し、またユーザーはロギングやモニタリング及びアラートを行うソリューションを統合できます。また一方、Kubernetesはモノリシックでなく、標準のソリューションは選択が自由で、追加と削除が容易な構成になっています。Kubernetesは開発プラットフォーム構築のためにビルディングブロックを提供しますが、重要な部分はユーザーの選択と柔軟性を維持しています。
Kubernetesは...
サポートするアプリケーションの種類を制限しません。Kubernetesは、ステートレス、ステートフルやデータ処理のワークロードなど、非常に多様なワークロードをサポートすることを目的としています。アプリケーションがコンテナで実行できるのであれば、Kubernetes上で問題なく実行できるはずです。
ソースコードのデプロイやアプリケーションのビルドは行いません。継続的なインテグレーション、デリバリー、デプロイ(CI/CD)のワークフローは、技術的な要件だけでなく組織の文化や好みで決められます。
ミドルウェア(例:メッセージバス)、データ処理フレームワーク(例:Spark)、データベース(例:MySQL)、キャッシュ、クラスターストレージシステム(例:Ceph)といったアプリケーションレベルの機能を組み込んで提供しません。それらのコンポーネントは、Kubernetes上で実行することもできますし、Open Service Broker のようなポータブルメカニズムを経由してKubernetes上で実行されるアプリケーションからアクセスすることも可能です。
ロギング、モニタリングやアラートを行うソリューションは指定しません。PoCとしていくつかのインテグレーションとメトリクスを収集し出力するメカニズムを提供します。
構成言語/システム(例:Jsonnet)の提供も指示もしません。任意の形式の宣言型仕様の対象となる可能性のある宣言型APIを提供します。
統合的なマシンの構成、メンテナンス、管理、または自己修復を行うシステムは提供も採用も行いません。
さらに、Kubernetesは単なるオーケストレーションシステムではありません。実際には、オーケストレーションの必要性はありません。オーケストレーションの技術的な定義は、「最初にAを実行し、次にB、その次にCを実行」のような定義されたワークフローの実行です。対照的にKubernetesは、現在の状態から提示されたあるべき状態にあわせて継続的に維持するといった、独立していて構成可能な制御プロセスのセットを提供します。AからCへどのように移行するかは問題ではありません。集中管理も必要ありません。これにより、使いやすく、より強力で、堅牢で、弾力性と拡張性があるシステムが実現します。
次の項目
1.1 - Kubernetesのコンポーネント
Kubernetesクラスターはコントロールプレーンのコンポーネントとノードと呼ばれるマシン群で構成されています。
Kubernetesをデプロイすると、クラスターが展開されます。
Kubernetesクラスターは、 コンテナ化されたアプリケーションを実行する、ノード と呼ばれるワーカーマシンの集合です。すべてのクラスターには少なくとも1つのワーカーノードがあります。
ワーカーノードは、アプリケーションのコンポーネントであるPodをホストします。マスターノードは、クラスター内のワーカーノードとPodを管理します。複数のマスターノードを使用して、クラスターにフェイルオーバーと高可用性を提供します。
ワーカーノードは、アプリケーションワークロードのコンポーネントであるPod をホストします。コントロールプレーン は、クラスター内のワーカーノードとPodを管理します。本番環境では、コントロールプレーンは複数のコンピューターを使用し、クラスターは複数のノードを使用し、耐障害性や高可用性を提供します。
このドキュメントでは、Kubernetesクラスターが機能するために必要となるさまざまなコンポーネントの概要を説明します。
Kubernetesクラスターを構成するコンポーネント
コントロールプレーンコンポーネント
コントロールプレーンコンポーネントは、クラスターに関する全体的な決定(スケジューリングなど)を行います。また、クラスターイベントの検出および応答を行います(たとえば、deploymentのreplicasフィールドが満たされていない場合に、新しい Pod を起動する等)。
コントロールプレーンコンポーネントはクラスター内のどのマシンでも実行できますが、シンプルにするため、セットアップスクリプトは通常、すべてのコントロールプレーンコンポーネントを同じマシンで起動し、そのマシンではユーザーコンテナを実行しません。
複数のマシンにまたがって実行されるコントロールプレーンのセットアップ例については、kubeadmを使用した高可用性クラスターの構築 を参照してください。
kube-apiserver
APIサーバーは、Kubernetes APIを外部に提供するKubernetesコントロールプレーン のコンポーネントです。
APIサーバーはKubernetesコントロールプレーンのフロントエンドになります。
Kubernetes APIサーバーの主な実装はkube-apiserver です。
kube-apiserverは水平方向にスケールするように設計されています—つまり、インスタンスを追加することでスケールが可能です。
複数のkube-apiserverインスタンスを実行することで、インスタンス間でトラフィックを分散させることが可能です。
etcd
一貫性、高可用性を持ったキーバリューストアで、Kubernetesの全てのクラスター情報の保存場所として利用されています。
etcdをKubernetesのデータストアとして使用する場合、必ずデータのバックアップ プランを作成して下さい。
公式ドキュメント でetcdに関する詳細な情報を見つけることができます。
kube-scheduler
コントロールプレーン上で動作するコンポーネントで、新しく作られたPod にノード が割り当てられているか監視し、割り当てられていなかった場合にそのPodを実行するノードを選択します。
スケジューリングの決定は、PodあるいはPod群のリソース要求量、ハードウェア/ソフトウェア/ポリシーによる制約、アフィニティおよびアンチアフィニティの指定、データの局所性、ワークロード間の干渉、有効期限などを考慮して行われます。
kube-controller-manager
コントロールプレーン上で動作するコンポーネントで、複数のコントローラー プロセスを実行します。
論理的には、各コントローラー は個別のプロセスですが、複雑さを減らすために一つの実行ファイルにまとめてコンパイルされ、単一のプロセスとして動きます。
コントローラーには以下が含まれます。
ノードコントローラー:ノードがダウンした場合の通知と対応を担当します。
Jobコントローラー:単発タスクを表すJobオブジェクトを監視し、そのタスクを実行して完了させるためのPodを作成します。
EndpointSliceコントローラー:EndpointSliceオブジェクトを作成します(つまり、ServiceとPodを紐付けます)。
ServiceAccountコントローラー:新規の名前空間に対して、デフォルトのServiceAccountを作成します。
cloud-controller-manager
クラウド特有の制御ロジックを組み込むKubernetesの
control plane コンポーネントです。クラウドコントロールマネージャーは、クラスターをクラウドプロバイダーAPIをリンクし、クラスターのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離します。
cloud-controller-managerは、クラウドプロバイダー固有のコントローラーのみを実行します。
Kubernetesをオンプレミスあるいは個人のPC内での学習環境で動かす際には、クラスターにcloud controller managerはありません。
kube-controller-managerと同様に、cloud-controller-managerは複数の論理的に独立したコントロールループをシングルバイナリにまとめ、一つのプロセスとして動作します。パフォーマンスを向上させるあるいは障害に耐えるために水平方向にスケールする(一つ以上のコピーを動かす)ことができます。
次の各コントローラーは、それぞれ以下に示すような目的のためにクラウドプロバイダーへの依存関係を持つことができるようになっています。
Nodeコントローラー: ノードが応答を停止した後、クラウドで当該ノードが削除されたかどうかを判断するため
Route コントローラー: 基盤となるクラウドインフラのルートを設定するため
Service コントローラー: クラウドプロバイダーのロードバランサーの作成、更新、削除を行うため
ノードコンポーネント
ノードコンポーネントはすべてのノードで実行され、稼働中のPodの管理やKubernetesの実行環境を提供します。
kubelet
クラスター内の各ノード で実行されるエージェントです。各コンテナ がPod で実行されていることを保証します。
kubeletは、さまざまなメカニズムを通じて提供されるPodSpecのセットを取得し、それらのPodSpecに記述されているコンテナが正常に実行されている状態を保証します。kubeletは、Kubernetesが作成したものではないコンテナは管理しません。
kube-proxy
kube-proxyはクラスター内の各node で動作しているネットワークプロキシで、KubernetesのService コンセプトの一部を実装しています。
kube-proxy は、Nodeのネットワークルールをメンテナンスします。これらのネットワークルールにより、クラスターの内部または外部のネットワークセッションからPodへのネットワーク通信が可能になります。
kube-proxyは、オペレーティングシステムにパケットフィルタリング層があり、かつ使用可能な場合、パケットフィルタリング層を使用します。それ以外の場合は自身でトラフィックを転送します。
コンテナランタイム
コンテナランタイムは、コンテナの実行を担当するソフトウェアです。
Kubernetesは次の複数のコンテナランタイムをサポートします。
Docker 、containerd 、CRI-O 、
および全ての
Kubernetes CRI (Container Runtime Interface)
実装です。
アドオン
アドオンはクラスター機能を実装するためにKubernetesリソース(DaemonSet 、Deployment など)を使用します。
アドオンはクラスターレベルの機能を提供しているため、アドオンのリソースで名前空間が必要なものはkube-system名前空間に属します。
いくつかのアドオンについて以下で説明します。より多くの利用可能なアドオンのリストは、アドオン をご覧ください。
DNS
クラスターDNS以外のアドオンは必須ではありませんが、すべてのKubernetesクラスターはクラスターDNS を持つべきです。多くの使用例がクラスターDNSを前提としています。
クラスターDNSは、環境内の他のDNSサーバーに加えて、KubernetesサービスのDNSレコードを提供するDNSサーバーです。
Kubernetesによって開始されたコンテナは、DNS検索にこのDNSサーバーを自動的に含めます。
Web UI (ダッシュボード)
ダッシュボード は、Kubernetesクラスター用の汎用WebベースUIです。これによりユーザーはクラスターおよびクラスター内で実行されているアプリケーションについて、管理およびトラブルシューティングを行うことができます。
コンテナリソース監視
コンテナリソース監視 は、コンテナに関する一般的な時系列メトリックを中央データベースに記録します。また、そのデータを閲覧するためのUIを提供します。
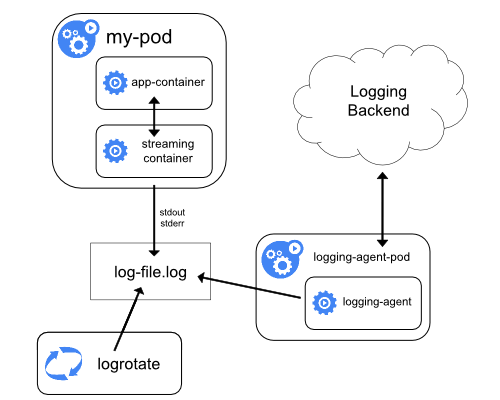
クラスターレベルのロギング
クラスターレベルのロギング メカニズムは、コンテナのログを、検索/参照インターフェースを備えた中央ログストアに保存します。
次の項目
1.2 - Kubernetes API
Kubernetes APIを使用すると、Kubernetes内のオブジェクトの状態をクエリで操作できます。 Kubernetesのコントロールプレーンの中核は、APIサーバーとそれが公開するHTTP APIです。ユーザー、クラスターのさまざまな部分、および外部コンポーネントはすべて、APIサーバーを介して互いに通信します。
Kubernetesの中核である control plane はAPI server です。
APIサーバーは、エンドユーザー、クラスターのさまざまな部分、および外部コンポーネントが相互に通信できるようにするHTTP APIを公開します。
Kubernetes APIを使用すると、Kubernetes API内のオブジェクトの状態をクエリで操作できます(例:Pod、Namespace、ConfigMap、Events)。
ほとんどの操作は、APIを使用しているkubectl コマンドラインインターフェースもしくはkubeadm のような別のコマンドラインツールを通して実行できます。
RESTコールを利用して直接APIにアクセスすることも可能です。
Kubernetes APIを利用してアプリケーションを書いているのであれば、client libraries の利用を考えてみてください。
OpenAPI 仕様
完全なAPIの詳細は、OpenAPI を使用して文書化されています。
OpenAPI V2
Kubernetes APIサーバーは、/openapi/v2エンドポイントを介してOpenAPI v2仕様を提供します。
次のように要求ヘッダーを使用して、応答フォーマットを要求できます。
OpenAPI v2クエリの有効なリクエストヘッダー値
ヘッダー
取りうる値
備考
Accept-Encodinggzipこのヘッダーを使わないことも可能
Acceptapplication/com.github.proto-openapi.spec.v2@v1.0+protobuf主にクラスター内での使用
application/jsonデフォルト
*application/jsonを提供
Kubernetesは、他の手段として主にクラスター間の連携用途向けのAPIに、Protocol buffersをベースにしたシリアライズフォーマットを実装しています。このフォーマットに関しては、Kubernetes Protobuf serialization デザイン提案を参照してください。また、各スキーマのInterface Definition Language(IDL)ファイルは、APIオブジェクトを定義しているGoパッケージ内に配置されています。
OpenAPI V3
FEATURE STATE: Kubernetes v1.24 [beta]
Kubernetes v1.30では、OpenAPI v3によるAPI仕様をベータサポートとして提供しています。これは、デフォルトで有効化されているベータ機能です。kube-apiserverのOpenAPIV3というfeature gate を切ることにより、このベータ機能を無効化することができます。
/openapi/v3が、全ての利用可能なグループやバージョンの一覧を閲覧するためのディスカバリーエンドポイントとして提供されています。このエンドポイントは、JSONのみを返却します。利用可能なグループやバージョンは、次のような形式で提供されます。
{
"paths": {
...,
"api/v1": {
"serverRelativeURL": "/openapi/v3/api/v1?hash=CC0E9BFD992D8C59AEC98A1E2336F899E8318D3CF4C68944C3DEC640AF5AB52D864AC50DAA8D145B3494F75FA3CFF939FCBDDA431DAD3CA79738B297795818CF"
},
"apis/admissionregistration.k8s.io/v1": {
"serverRelativeURL": "/openapi/v3/apis/admissionregistration.k8s.io/v1?hash=E19CC93A116982CE5422FC42B590A8AFAD92CDE9AE4D59B5CAAD568F083AD07946E6CB5817531680BCE6E215C16973CD39003B0425F3477CFD854E89A9DB6597"
},
....
}
クライアントサイドのキャッシングを改善するために、相対URLはイミュータブルな(不変の)OpenAPI記述を指しています。
また、APIサーバーも、同様の目的で適切なHTTPキャッシュヘッダー(Expiresには1年先の日付、Cache-Controlにはimmutable)をセットします。廃止されたURLが使用された場合、APIサーバーは最新のURLへのリダイレクトを返します。
Kubernetes APIサーバーは、/openapi/v3/apis/<group>/<version>?hash=<hash>のエンドポイントにて、KubernetesのグループバージョンごとにOpenAPI v3仕様を公開しています。
受理されるリクエストヘッダーについては、以下の表の通りです。
OpenAPI v3において有効なリクエストヘッダー
ヘッダー
取りうる値
備考
Accept-Encodinggzipこのヘッダーを使わないことも可能
Acceptapplication/com.github.proto-openapi.spec.v3@v1.0+protobuf主にクラスター内での使用
application/jsonデフォルト
*application/jsonを提供
永続性
KubernetesはAPIリソースの観点からシリアル化された状態をetcd に書き込むことで保存します。
APIグループとバージョニング
フィールドの削除やリソース表現の再構成を簡単に行えるようにするため、Kubernetesは複数のAPIバージョンをサポートしており、/api/v1や/apis/rbac.authorization.k8s.io/v1alpha1のように、それぞれ異なるAPIのパスが割り当てられています。
APIが、システムリソースと動作について明確かつ一貫したビューを提供し、サポート終了、実験的なAPIへのアクセス制御を有効にするために、リソースまたはフィールドレベルではなく、APIレベルでバージョンが行われます。
APIの発展や拡張を簡易に行えるようにするため、Kubernetesは有効もしくは無効 を行えるAPIグループ を実装しました。
APIリソースは、APIグループ、リソースタイプ、ネームスペース(namespacedリソースのための)、名前によって区別されます。APIサーバーは、APIバージョン間の変換を透過的に処理します。すべてのバージョンの違いは、実際のところ同じ永続データとして表現されます。APIサーバーは、同じ基本的なデータを複数のAPIバージョンで提供することができます。
例えば、同じリソースでv1とv1beta1の2つのバージョンが有ることを考えてみます。
v1beta1バージョンのAPIを利用しオブジェクトを最初に作成したとして、v1beta1バージョンが非推奨となり削除されるまで、v1beta1もしくはv1どちらのAPIバージョンを利用してもオブジェクトのread、update、deleteができます。
その時点では、v1 APIを使用してオブジェクトの修正やアクセスを継続することが可能です。
APIの変更
成功を収めているシステムはすべて、新しいユースケースの出現や既存の変化に応じて成長し、変化する必要があります。
したがって、Kubernetesには、Kubernetes APIを継続的に変更および拡張できる設計機能があります。
Kubernetesプロジェクトは、既存のクライアントとの互換性を破壊 しないこと 、およびその互換性を一定期間維持して、他のプロジェクトが適応する機会を提供することを目的としています。
基本的に、新しいAPIリソースと新しいリソースフィールドは追加することができます。
リソースまたはフィールドを削除するには、API非推奨ポリシー に従ってください。
Kubernetesは、通常はAPIバージョンv1として、公式のKubernetes APIが一度一般提供(GA)に達した場合、互換性を維持することを強く確約します。
さらに、Kubernetesは、公式Kubernetes APIの beta APIバージョン経由で永続化されたデータとの互換性を維持します。
そして、機能が安定したときにGA APIバージョン経由でデータを変換してアクセスできることを保証します。
beta APIを採用した場合、APIが卒業(Graduate)したら、後続のbetaまたはstable APIに移行する必要があります。
これを行うのに最適な時期は、オブジェクトが両方のAPIバージョンから同時にアクセスできるbeta APIの非推奨期間中です。
beta APIが非推奨期間を終えて提供されなくなったら、代替APIバージョンを使用する必要があります。
備考: Kubernetesは、 alpha APIバージョンについても互換性の維持に注力しますが、いくつかの事情により不可である場合もあります。
alpha APIバージョンを使っている場合、クラスターをアップグレードする時にKubernetesのリリースノートを確認してください。
APIが互換性のない方法で変更された場合は、アップグレードをする前に既存のalphaオブジェクトをすべて削除する必要があります。
APIバージョンレベルの定義に関する詳細はAPIバージョンのリファレンス を参照してください。
APIの拡張
Kubernetes APIは2つの方法で拡張できます。
カスタムリソース は、APIサーバーが選択したリソースAPIをどのように提供するかを宣言的に定義します。アグリゲーションレイヤー を実装することでKubernetes APIを拡張することもできます。
次の項目
1.3 - Kubernetesオブジェクトを利用する
Kubernetesオブジェクトは、Kubernetes上で永続的なエンティティです。Kubernetesはこれらのエンティティを使い、クラスターの状態を表現します。 Kubernetesオブジェクトモデルと、これらのオブジェクトの利用方法について学びます。
1.3.1 - Kubernetesオブジェクトを理解する
このページでは、KubernetesオブジェクトがKubernetes APIでどのように表現されているか、またそれらを.yamlフォーマットでどのように表現するかを説明します。
Kubernetesオブジェクトを理解する
Kubernetesオブジェクト は、Kubernetes上で永続的なエンティティです。Kubernetesはこれらのエンティティを使い、クラスターの状態を表現します。具体的に言うと、下記のような内容が表現できます:
どのようなコンテナ化されたアプリケーションが稼働しているか(またそれらはどのノード上で動いているか)
それらのアプリケーションから利用可能なリソース
アプリケーションがどのように振る舞うかのポリシー、例えば再起動、アップグレード、耐障害性ポリシーなど
Kubernetesオブジェクトは「意図の記録」です。一度オブジェクトを作成すると、Kubernetesは常にそのオブジェクトが存在し続けるように動きます。オブジェクトを作成することで、Kubernetesに対し効果的にあなたのクラスターのワークロードがこのようになっていて欲しいと伝えているのです。これが、あなたのクラスターの望ましい状態 です。
Kubernetesオブジェクトを操作するには、作成、変更、または削除に関わらずKubernetes API を使う必要があるでしょう。例えばkubectlコマンドラインインターフェースを使った場合、このCLIが処理に必要なKubernetes API命令を、あなたに代わり発行します。あなたのプログラムからクライアントライブラリ を利用し、直接Kubernetes APIを利用することも可能です。
オブジェクトのspec(仕様)とstatus(状態)
ほとんどのKubernetesオブジェクトは、オブジェクトの設定を管理する2つの入れ子になったオブジェクトのフィールドを持っています。それはオブジェクト specstatusspecを持っているオブジェクトに関しては、オブジェクト作成時にspecを設定する必要があり、望ましい状態としてオブジェクトに持たせたい特徴を記述する必要があります。
status オブジェクトはオブジェクトの 現在の状態 を示し、その情報はKubernetesシステムとそのコンポーネントにより提供、更新されます。Kubernetesコントロールプレーン は、あなたから指定された望ましい状態と現在の状態が一致するよう常にかつ積極的に管理をします。
例えば、KubernetesのDeploymentはクラスター上で稼働するアプリケーションを表現するオブジェクトです。Deploymentを作成するとき、アプリケーションの複製を3つ稼働させるようDeploymentのspecで指定するかもしれません。KubernetesはDeploymentのspecを読み取り、指定されたアプリケーションを3つ起動し、現在の状態がspecに一致するようにします。もしこれらのインスタンスでどれかが落ちた場合(statusが変わる)、Kubernetesはspecと、statusの違いに反応し、修正しようとします。この場合は、落ちたインスタンスの代わりのインスタンスを立ち上げます。
spec、status、metadataに関するさらなる情報は、Kubernetes API Conventions をご確認ください。
Kubernetesオブジェクトを記述する
Kubernetesでオブジェクトを作成する場合、オブジェクトの基本的な情報(例えば名前)と共に、望ましい状態を記述したオブジェクトのspecを渡さなければいけません。KubernetesAPIを利用しオブジェクトを作成する場合(直接APIを呼ぶか、kubectlを利用するかに関わらず)、APIリクエストはそれらの情報をJSON形式でリクエストのBody部に含んでいなければなりません。
ここで、KubernetesのDeploymentに必要なフィールドとオブジェクトのspecを記載した.yamlファイルの例を示します:
apiVersion : apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind : Deployment
metadata :
name : nginx-deployment
spec :
selector :
matchLabels :
app : nginx
replicas : 2 # tells deployment to run 2 pods matching the template
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
上に示した.yamlファイルを利用してDeploymentを作成するには、kubectlコマンドラインインターフェースに含まれているkubectl apply.yamlファイルを引数に指定し、実行します。ここで例を示します:
kubectl apply -f https://k8s.io/examples/application/deployment.yaml --record
出力結果は、下記に似た形になります:
deployment.apps/nginx-deployment created
必須フィールド
Kubernetesオブジェクトを.yamlファイルに記載して作成する場合、下記に示すフィールドに値をセットしておく必要があります:
apiVersion - どのバージョンのKubernetesAPIを利用してオブジェクトを作成するかkind - どの種類のオブジェクトを作成するかmetadata - オブジェクトを一意に特定するための情報、文字列のname、UID、また任意のnamespaceが該当するspec - オブジェクトの望ましい状態
specの正確なフォーマットは、Kubernetesオブジェクトごとに異なり、オブジェクトごとに特有な入れ子のフィールドを持っています。Kubernetes API リファレンス が、Kubernetesで作成できる全てのオブジェクトに関するspecのフォーマットを探すのに役立ちます。
例えば、Podオブジェクトに関するspecのフォーマットはPodSpec v1 core を、またDeploymentオブジェクトに関するspecのフォーマットはDeploymentSpec v1 apps をご確認ください。
次の項目
1.3.2 - Kubernetesオブジェクト管理
kubectlコマンドラインツールは、Kubernetesオブジェクトを作成、管理するためにいくつかの異なる方法をサポートしています。
このドキュメントでは、それらの異なるアプローチごとの概要を提供します。
Kubectlを使ったオブジェクト管理の詳細は、Kubectl book を参照してください。
管理手法
警告: Kubernetesのオブジェクトは、いずれか一つの手法で管理してください。
同じオブジェクトに対して、複数の手法を組み合わせた場合、未定義の挙動をもたらします。
管理手法
何を対象にするか
推奨環境
サポートライター
学習曲線
命令型コマンド
現行のオブジェクト
開発用プロジェクト
1+
緩やか
命令型オブジェクト設定
個々のファイル
本番用プロジェクト
1
中程度
宣言型オブジェクト設定
ファイルのディレクトリ
本番用プロジェクト
1+
急
命令型コマンド
命令型コマンドを使う場合、ユーザーはクラスター内の現行のオブジェクトに対して処理を行います。
ユーザーはkubectlコマンドに処理内容を引数、もしくはフラグで指定します。
これはKubernetesの使い始め、またはクラスターに対して一度限りのタスクを行う際の最も簡単な手法です。
なぜなら、この手法は現行のオブジェクトに対して直接操作ができ、以前の設定履歴は提供されないからです。
例
Deploymentオブジェクトを作成し、nginxコンテナの単一インスタンスを起動します:
kubectl run nginx --image nginx
同じことを異なる構文で行います:
kubectl create deployment nginx --image nginx
トレードオフ
オブジェクト設定手法に対する長所:
コマンドは簡潔、簡単に学ぶことができ、そして覚えやすいです
コマンドではクラスターの設定を変えるのに、わずか1ステップしか必要としません
オブジェクト設定手法に対する短所:
コマンドは変更レビュープロセスと連携しません
コマンドは変更に伴う監査証跡を提供しません
コマンドは現行がどうなっているかという情報を除き、レコードのソースを提供しません
コマンドはオブジェクトを作成するためのテンプレートを提供しません
命令型オブジェクト設定
命令型オブジェクト設定では、kubectlコマンドに処理内容(create、replaceなど)、任意のフラグ、そして最低1つのファイル名を指定します。
指定されたファイルは、YAMLまたはJSON形式でオブジェクトの全ての定義情報を含んでいなければいけません。
オブジェクト定義の詳細は、APIリファレンス を参照してください。
警告: 命令型のreplaceコマンドは、既存の構成情報を新しく提供された設定に置き換え、設定ファイルに無いオブジェクトの全ての変更を削除します。
このアプローチは、構成情報が設定ファイルとは無関係に更新されるリソースタイプでは使用しないでください。
例えば、タイプがLoadBalancerのServiceオブジェクトにおけるexternalIPsフィールドは、設定ファイルとは無関係に、クラスターによって更新されます。
例
設定ファイルに定義されたオブジェクトを作成します:
kubectl create -f nginx.yaml
設定ファイルに定義されたオブジェクトを削除します:
kubectl delete -f nginx.yaml -f redis.yaml
設定ファイルに定義された情報で、現行の設定を上書き更新します:
kubectl replace -f nginx.yaml
トレードオフ
命令型コマンド手法に対する長所:
オブジェクト設定をGitのような、ソースコード管理システムに格納することができます
オブジェクト設定の変更内容をプッシュする前にレビュー、監査証跡を残すようなプロセスと連携することができます
オブジェクト設定は新しいオブジェクトを作る際のテンプレートを提供します
命令型コマンド手法に対する短所:
オブジェクト設定ではオブジェクトスキーマの基礎的な理解が必要です
オブジェクト設定ではYAMLファイルを書くという、追加のステップが必要です
宣言型オブジェクト設定手法に対する長所:
命令型オブジェクト設定の振る舞いは、よりシンプルで簡単に理解ができます
Kubernetesバージョン1.5においては、命令型オブジェクト設定の方がより成熟しています
宣言型オブジェクト設定手法に対する短所:
命令型オブジェクト設定は各ファイルごとに設定を書くには最も適していますが、ディレクトリには適していません
現行オブジェクトの更新は設定ファイルに対して反映しなければなりません。反映されない場合、次の置き換え時に更新内容が失われてしまいます
宣言型オブジェクト設定
宣言型オブジェクト設定を利用する場合、ユーザーはローカルに置かれている設定ファイルを操作します。
しかし、ユーザーはファイルに対する操作内容を指定しません。作成、更新、そして削除といった操作はオブジェクトごとにkubectlが検出します。
この仕組みが、異なるオブジェクトごとに異なる操作をディレクトリに対して行うことを可能にしています。
備考: 宣言型オブジェクト設定は、他の人が行った変更が設定ファイルにマージされなかったとしても、それらの変更を保持します。
これは、replaceAPI操作のように、全てのオブジェクト設定を置き換えるわけではなく、patchAPI操作による、変更箇所のみの更新が可能にしています。
例
configディレクトリ配下にある全てのオブジェクト設定ファイルを処理し、作成、または現行オブジェクトへのパッチを行います。
まず、diffでどのような変更が行われるかを確認した後に適用します:
kubectl diff -f configs/
kubectl apply -f configs/
再帰的にディレクトリを処理します:
kubectl diff -R -f configs/
kubectl apply -R -f configs/
トレードオフ
命令型オブジェクト設定手法に対する長所:
現行オブジェクトに直接行われた変更が、それらが設定ファイルに反映されていなかったとしても、保持されます
宣言型オブジェクト設定は、ディレクトリごとの処理をより良くサポートしており、自動的にオブジェクトごとに操作のタイプ(作成、パッチ、削除)を検出します
命令型オブジェクト設定手法に対する短所:
宣言型オブジェクト設定は、デバッグ、そして想定外の結果が出たときに理解するのが困難です
差分を利用した一部のみの更新は、複雑なマージ、パッチの操作が必要です
次の項目
1.3.3 - オブジェクトの名前とID
クラスター内の各オブジェクトには、そのタイプのリソースに固有の名前 UID
たとえば、同じ名前空間 内にmyapp-1234という名前のPodは1つしか含められませんが、myapp-1234という名前の1つのPodと1つのDeploymentを含めることができます。
ユーザーが一意ではない属性を付与するために、Kubernetesはラベル とアノテーション を提供しています。
名前
クライアントから提供され、リソースURL内のオブジェクトを参照する文字列です。例えば/api/v1/pods/何らかの名前のようになります。
同じ種類のオブジェクトは、同じ名前を同時に持つことはできません。しかし、オブジェクトを削除することで、旧オブジェクトと同じ名前で新しいオブジェクトを作成できます。
次の3つの命名規則がよく使われます。
DNSサブドメイン名
ほとんどのリソースタイプには、RFC 1123 で定義されているDNSサブドメイン名として使用できる名前が必要です。
つまり、名前は次のとおりでなければなりません:
253文字以内
英小文字、数字、「-」または「.」のみを含む
英数字で始まる
英数字で終わる
DNSラベル名
一部のリソースタイプでは、RFC 1123 で定義されているDNSラベル標準に従う名前が必要です。
つまり、名前は次のとおりでなければなりません:
63文字以内
英小文字、数字または「-」のみを含む
英数字で始まる
英数字で終わる
パスセグメント名
一部のリソースタイプでは、名前をパスセグメントとして安全にエンコードできるようにする必要があります。
つまり、名前を「.」や「..」にすることはできず、名前に「/」または「%」を含めることはできません。
以下は、nginx-demoという名前のPodのマニフェストの例です。
apiVersion : v1
kind : Pod
metadata :
name : nginx-demo
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
備考: 一部のリソースタイプには、名前に追加の制限があります。
UID
オブジェクトを一意に識別するためのKubernetesが生成する文字列です。
Kubernetesクラスターの生存期間中にわたって生成された全てのオブジェクトは、異なるUIDを持っています。これは類似のエンティティの、同一時間軸での存在を区別するのが目的です。
Kubernetes UIDは、UUIDのことを指します。
UUIDは、ISO/IEC 9834-8およびITU-T X.667として標準化されています。
次の項目
1.3.4 - ラベル(Labels)とセレクター(Selectors)
ラベル(Labels) はPodなどのオブジェクトに割り当てられたキーとバリューのペアです。
"metadata" : {
"labels" : {
"key1" : "value1" ,
"key2" : "value2"
}
}
ラベルは効率的な検索・閲覧を可能にし、UIやCLI上での利用に最適です。
識別用途でない情報は、アノテーション を用いて記録されるべきです。
ラベルを使う動機
ラベルは、クライアントにそのマッピング情報を保存することを要求することなく、ユーザー独自の組織構造をシステムオブジェクト上で疎結合にマッピングできます。
サービスデプロイメントとバッチ処理のパイプラインは多くの場合、多次元のエンティティとなります(例: 複数のパーティション、Deployment、リリーストラック、ティアー、ティアー毎のマイクロサービスなど)
ラベルの例:
"release" : "stable", "release" : "canary""environment" : "dev", "environment" : "qa", "environment" : "production""tier" : "frontend", "tier" : "backend", "tier" : "cache""partition" : "customerA", "partition" : "customerB""track" : "daily", "track" : "weekly"
これらは単によく使われるラベルの例です。ユーザーは自由に規約を決めることができます。
ラベルのキーは、ある1つのオブジェクトに対してユニークである必要があることは覚えておかなくてはなりません。
構文と文字セット
ラベルは、キーとバリューのベアです。正しいラベルキーは2つのセグメントを持ちます。/によって分割されたオプショナルなプレフィックスと名前です。[a-z0-9A-Z])で、文字列の間ではこれに加えてダッシュ(-)、アンダースコア(_)、ドット(.)を使うことができます。.)で区切られたDNSラベルのセットで、253文字以下である必要があり、最後にスラッシュ(/)が続きます。
もしプレフィックスが省略された場合、ラベルキーはそのユーザーに対してプライベートであると推定されます。kube-scheduler kube-controller-manager kube-apiserver kubectlやその他のサードパーティツール)は、プレフィックスを指定しなくてはなりません。
kubernetes.io/とk8s.io/プレフィックスは、Kubernetesコアコンポーネントのために予約されています。
正しいラベル値は63文字以下の長さで、空文字か、もしくは開始と終了が英数字([a-z0-9A-Z])で、文字列の間がダッシュ(-)、アンダースコア(_)、ドット(.)と英数字である文字列を使うことができます。
例えば、environment: productionとapp: nginxの2つのラベルを持つPodの設定ファイルは下記のようになります。
apiVersion : v1
kind : Pod
metadata :
name : label-demo
labels :
environment : production
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
ラベルセレクター
名前とUID とは異なり、ラベルはユニーク性を提供しません。通常、多くのオブジェクトが同じラベルを保持することを想定します。
ラベルセレクター を介して、クライアントとユーザーはオブジェクトのセットを指定できます。ラベルセレクターはKubernetesにおいてコアなグルーピング機能となります。
Kubernetes APIは現在2タイプのセレクターをサポートしています。等価ベース(equality-based) と集合ベース(set-based) です。要件(requirements) で構成されています。AND (&&)オペレーターと同様にふるまい、全ての要件を満たす必要があります。
空文字の場合や、指定なしのセレクターに関するセマンティクスは、コンテキストに依存します。
そしてセレクターを使うAPIタイプは、それらのセレクターの妥当性とそれらが示す意味をドキュメントに記載するべきです。
備考: ReplicaSetなど、いくつかのAPIタイプにおいて、2つのインスタンスのラベルセレクターは単一の名前空間において重複してはいけません。重複していると、コントローラーがそれらのラベルセレクターがコンフリクトした操作とみなし、どれだけの数のレプリカを稼働させるべきか決めることができなくなります。
注意: 等価ベース、集合ベースともに、論理OR (||) オペレーターは存在しません。フィルターステートメントが意図した通りになっていることを確認してください。
等価ベース(Equality-based) の要件(requirement)等価ベース(Equality-based) もしくは不等ベース(Inequality-based) の要件は、ラベルキーとラベル値によるフィルタリングを可能にします。=、==、!=となります。=、==)は等価(Equality) を表現し(この2つは単なる同義語)、最後の1つ(!=)は不等(Inequality) を意味します。
environment = production
tier != frontend
最初の例は、キーがenvironmentで、値がproductionである全てのリソースを対象にします。tierで、値がfrontendとは異なるリソースと、tierという名前のキーを持たない全てのリソースを対象にします。,を使って、productionの中から、frontendのものを除外するようにフィルターすることもできます。environment=production,tier!=frontend
等価ベースのラベル要件の1つの使用シナリオとして、PodにおけるNodeの選択要件を指定するケースがあります。accelerator=nvidia-tesla-p100をもったNodeを選択します。
apiVersion : v1
kind : Pod
metadata :
name : cuda-test
spec :
containers :
- name : cuda-test
image : "registry.k8s.io/cuda-vector-add:v0.1"
resources :
limits :
nvidia.com/gpu : 1
nodeSelector :
accelerator : nvidia-tesla-p100
集合ベース(Set-based) の要件(requirement)集合ベース(Set-based) のラベルの要件は値のセットによってキーをフィルタリングします。in、notin、existsの3つのオペレーターをサポートしています(キーを特定するのみ)。
例えば:
environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
最初の例では、キーがenvironmentで、値がproductionかqaに等しいリソースを全て選択します。
第2の例では、キーがtierで、値がfrontendとbackend以外のもの、そしてtierキーを持たないリソースを全て選択します。
第3の例では、partitionというキーをもつラベルを全て選択し、値はチェックしません。
第4の例では、partitionというキーを持たないラベルを全て選択し、値はチェックしません。
同様に、コンマセパレーターは、AND オペレーターと同様にふるまいます。そのため、partitionとenvironmentキーの値がともにqaでないラベルを選択するには、partition,environment notin (qa)と記述することで可能です。集合ベース のラベルセレクターは、environment=productionという記述がenvironment in (production)と等しいため、一般的な等価形式となります。 !=とnotinも同様に等価となります。
集合ベース の要件は、等価ベース の要件と混在できます。partition in (customerA, customerB),environment!=qa.
API
LISTとWATCHによるフィルタリング
LISTとWATCHオペレーションは、単一のクエリパラメーターを使うことによって返されるオブジェクトのセットをフィルターするためのラベルセレクターを指定できます。集合ベース と等価ベース のどちらの要件も許可されています(ここでは、URLクエリストリング内で出現します)。
等価ベース での要件: ?labelSelector=environment%3Dproduction,tier%3Dfrontend集合ベース での要件: ?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
上記の2つの形式のラベルセレクターはRESTクライアントを介してリストにしたり、もしくは確認するために使われます。kubectlによってapiserverをターゲットにし、等価ベース の要件でフィルターすると以下のように書けます。
kubectl get pods -l environment = production,tier= frontend
もしくは、集合ベース の要件を指定すると以下のようになります。
kubectl get pods -l 'environment in (production),tier in (frontend)'
すでに言及したように、集合ベース の要件は、等価ベース の要件より表現力があります。OR オペレーターを実装して以下のように書けます。
kubectl get pods -l 'environment in (production, qa)'
もしくは、notin オペレーターを介して、否定マッチングによる制限もできます。
kubectl get pods -l 'environment,environment notin (frontend)'
APIオブジェクトに参照を設定する
ServiceReplicationControllerPod のような他のリソースのセットを指定するのにも使われます。
ServiceとReplicationController
Serviceが対象とするPodの集合は、ラベルセレクターによって定義されます。ReplicationControllerが管理するべきPod数についてもラベルセレクターを使って定義されます。
それぞれのオブジェクトに対するラベルセレクターはマップを使ってjsonもしくはyaml形式のファイルで定義され、等価ベース のセレクターのみサポートされています。
"selector" : {
"component" : "redis" ,
}
もしくは
selector :
component : redis
このセレクター(それぞれjsonまたはyaml形式)は、component=redisまたはcomponent in (redis)と等価です。
集合ベース の要件指定をサポートするリソースJobDeploymentReplicaSetDaemonSet集合ベース での要件指定もサポートしています。
selector :
matchLabels :
component : redis
matchExpressions :
- {key: tier, operator: In, values : [cache]}
- {key: environment, operator: NotIn, values : [dev]}
matchLabelsは、{key,value}ペアのマップです。matchLabels内の単一の{key,value}は、matchExpressionsの要素と等しく、それは、keyフィールドがキー名で、operatorが"In"で、values配列は単に"値"を保持します。matchExpressionsはPodセレクター要件のリストです。対応しているオペレーターはIn、NotIn、ExistsとDoesNotExistです。valuesのセットは、InとNotInオペレーターにおいては空文字を許容しません。matchLabelsとmatchExpressionsの両方によって指定された全ての要件指定はANDで判定されます。つまり要件にマッチするには指定された全ての要件を満たす必要があります。
Nodeのセットを選択する
ラベルを選択するための1つのユースケースはPodがスケジュールできるNodeのセットを制限することです。Node選定 のドキュメントを参照してください。
1.3.5 - Namespace(名前空間)
Kubernetesは、同一の物理クラスター上で複数の仮想クラスターの動作をサポートします。
この仮想クラスターをNamespaceと呼びます。
複数のNamespaceを使う時
Namespaceは、複数のチーム・プロジェクトにまたがる多くのユーザーがいる環境での使用を目的としています。
数人から数十人しかユーザーのいないクラスターに対して、あなたはNamespaceを作成したり、考える必要は全くありません。
Kubernetesが提供するNamespaceの機能が必要となった時に、Namespaceの使用を始めてください。
Namespaceは名前空間のスコープを提供します。リソース名は単一のNamespace内ではユニークである必要がありますが、Namespace全体ではその必要はありません。Namespaceは相互にネストすることはできず、各Kubernetesリソースは1つのNamespaceにのみ存在できます。
Namespaceは、複数のユーザーの間でクラスターリソースを分割する方法です。(これはリソースクォータ を介して分割します。)
同じアプリケーションの異なるバージョンなど、少し違うリソースをただ分割するだけに、複数のNamespaceを使う必要はありません。
同一のNamespace内でリソースを区別するためにはラベル を使用してください。
Namespaceを利用する
Namespaceの作成と削除方法はNamespaceの管理ガイドドキュメント に記載されています。
備考: プレフィックスkube-を持つNamespaceは、KubernetesシステムのNamespaceとして予約されているため利用は避けてください。
Namespaceの表示
ユーザーは、以下の方法で単一クラスター内の現在のNamespaceの一覧を表示できます。
NAME STATUS AGE
default Active 1d
kube-node-lease Active 1d
kube-system Active 1d
kube-public Active 1d
Kubernetesの起動時には4つの初期Namespaceが作成されています。
default 他にNamespaceを持っていないオブジェクトのためのデフォルトNamespacekube-system Kubernetesシステムによって作成されたオブジェクトのためのNamespacekube-public このNamespaceは自動的に作成され、全てのユーザーから読み取り可能です。(認証されていないユーザーも含みます。)
このNamespaceは、リソースをクラスター全体を通じてパブリックに表示・読み取り可能にするため、ほとんどクラスターによって使用される用途で予約されます。 このNamespaceのパブリックな側面は単なる慣例であり、要件ではありません。kube-node-lease クラスターのスケールに応じたノードハートビートのパフォーマンスを向上させる各ノードに関連したLeaseオブジェクトのためのNamespace。
Namespaceの設定
現在のリクエストのNamespaceを設定するには、--namespaceフラグを使用します。
例:
kubectl run nginx --image= nginx --namespace= <insert-namespace-name-here>
kubectl get pods --namespace= <insert-namespace-name-here>
Namespace設定の永続化
ユーザーはあるコンテキストのその後のコマンドで使うために、コンテキスト内で永続的にNamespaceを保存できます。
kubectl config set-context --current --namespace= <insert-namespace-name-here>
# Validate it
kubectl config view --minify | grep namespace:
NamespaceとDNS
ユーザーがService を作成するとき、Serviceは対応するDNSエントリ を作成します。
このエントリは<service-name>.<namespace-name>.svc.cluster.localという形式になり、これはもしあるコンテナがただ<service-name>を指定していた場合、Namespace内のローカルのServiceに対して名前解決されます。
これはデベロップメント、ステージング、プロダクションといった複数のNamespaceをまたいで同じ設定を使う時に効果的です。
もしユーザーがNamespaceをまたいでアクセスしたい時、 完全修飾ドメイン名(FQDN)を指定する必要があります。
すべてのオブジェクトはNamespaceに属しているとは限らない
ほとんどのKubernetesリソース(例えば、Pod、Service、ReplicationControllerなど)はいくつかのNamespaceにあります。
しかしNamespaceのリソースそれ自体は単一のNamespace内にありません。
そしてNode やPersistentVolumeのような低レベルのリソースはどのNamespaceにも属していません。
どのKubernetesリソースがNamespaceに属しているか、属していないかを見るためには、以下のコマンドで確認できます。
# Namespaceに属しているもの
kubectl api-resources --namespaced= true
# Namespaceに属していないもの
kubectl api-resources --namespaced= false
次の項目
1.3.6 - アノテーション(Annotations)
ユーザーは、識別用途でない任意のメタデータをオブジェクトに割り当てるためにアノテーションを使用できます。ツールやライブラリなどのクライアントは、このメタデータを取得できます。
オブジェクトにメタデータを割り当てる
ユーザーは、Kubernetesオブジェクトに対してラベルやアノテーションの両方またはどちらか一方を割り当てることができます。
ラベルはオブジェクトの選択や、特定の条件を満たしたオブジェクトの集合を探すことに使うことができます。
それと対照的に、アノテーションはオブジェクトを識別、または選択するために使用されません。
アノテーション内のメタデータは大小様々で、構造化されているものや、そうでないものも設定でき、ラベルでは許可されていない文字も含むことができます。
アノテーションは、ラベルと同様に、キーとバリューのマップとなります。
"metadata" : {
"annotations" : {
"key1" : "value1" ,
"key2" : "value2"
}
}
下記は、アノテーション内で記録できる情報の例です。
宣言的設定レイヤーによって管理されているフィールド。これらのフィールドをアノテーションとして割り当てることで、クライアントもしくはサーバによってセットされたデフォルト値、オートサイジングやオートスケーリングシステムによってセットされたフィールドや、自動生成のフィールドなどと区別することができます。
ビルド、リリースやタイムスタンプのようなイメージの情報、リリースID、gitのブランチ、PR番号、イメージハッシュ、レジストリアドレスなど
ロギング、監視、分析用のポインタ、もしくは監査用リポジトリ
デバッグ目的で使用されるためのクライアントライブラリやツールの情報。例えば、名前、バージョン、ビルド情報など。
他のエコシステムのコンポーネントからの関連オブジェクトのURLなど、ユーザーやツール、システムの出所情報。
軽量ロールアウトツールのメタデータ。 例えば設定やチェックポイントなど。
情報をどこで確認できるかを示すためのもの。例えばチームのウェブサイト、責任者の電話番号や、ページャー番号やディレクトリエンティティなど。
システムのふるまいの変更や、標準ではない機能を利用可能にするために、エンドユーザーがシステムに対して指定する値
アノテーションを使用するかわりに、ユーザーはこのようなタイプの情報を外部のデータベースやディレクトリに保存することもできます。しかし、それによりデプロイ、管理、イントロスペクションを行うためのクライアンライブラリやツールの生成が非常に難しくなります。
構文と文字セット
アノテーション はキーとバリューのペアです。有効なアノテーションのキーの形式は2つのセグメントがあります。
プレフィックス(オプション)と名前で、それらはスラッシュ/で区切られます。
名前セグメントは必須で、63文字以下である必要があり、文字列の最初と最後は英数字([a-z0-9A-Z])と、文字列の間にダッシュ(-)、アンダースコア(_)、ドット(.)を使うことができます。
プレフィックスはオプションです。もしプレフィックスが指定されていた場合、プレフィックスはDNSサブドメイン形式である必要があり、それはドット(.)で区切られたDNSラベルのセットで、253文字以下である必要があり、最後にスラッシュ(/)が続きます。
もしプレフィックスが除外された場合、アノテーションキーはそのユーザーに対してプライベートであると推定されます。
エンドユーザーのオブジェクトにアノテーションを追加するような自動化されたシステムコンポーネント(例: kube-scheduler kube-controller-manager kube-apiserver kubectlやその他のサードパーティツール)は、プレフィックスを指定しなくてはなりません。
kubernetes.io/とk8s.io/プレフィックスは、Kubernetesコアコンポーネントのために予約されています。
たとえば、imageregistry: https://hub.docker.com/というアノテーションが付いたPodの構成ファイルは次のとおりです:
apiVersion : v1
kind : Pod
metadata :
name : annotations-demo
annotations :
imageregistry : "https://hub.docker.com/"
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
次の項目
ラベルとセレクター について学習してください。
1.3.7 - フィールドセレクター(Field Selectors)
フィールドセレクター(Field Selectors) は、1つかそれ以上のリソースフィールドの値を元にKubernetesリソースを選択 するためのものです。
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
下記のkubectlコマンドは、status.phaseRunningである全てのPodを選択します。
kubectl get pods --field-selector status.phase= Running
備考: フィールドセレクターは本質的にリソースの フィルター となります。デフォルトでは、セレクター/フィルターが指定されていない場合は、全てのタイプのリソースが取得されます。これは、kubectlクエリのkubectl get podsとkubectl get pods --field-selector ""が同じであることを意味します。
サポートされているフィールド
サポートされているフィールドセレクターはKubernetesリソースタイプによって異なります。全てのリソースタイプはmetadata.nameとmetadata.namespaceフィールドをサポートしています。サポートされていないフィールドセレクターの使用をするとエラーとなります。
kubectl get ingress --field-selector foo.bar= baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
サポートされているオペレーター
ユーザーは、=、==や!=といったオペレーターをフィールドセレクターと組み合わせて使用できます。(=と==は同義)kubectlコマンドはdefaultネームスペースに属していない全てのKubernetes Serviceを選択します。
kubectl get services --all-namespaces --field-selector metadata.namespace!= default
連結されたセレクター
ラベル や他のセレクターと同様に、フィールドセレクターはコンマ区切りのリストとして連結することができます。kubectlコマンドは、status.phaseがRunnningでなく、かつspec.restartPolicyフィールドがAlwaysに等しいような全てのPodを選択します。
kubectl get pods --field-selector= status.phase!= Running,spec.restartPolicy= Always
複数のリソースタイプ
ユーザーは複数のリソースタイプにまたがったフィールドセレクターを利用できます。kubectlコマンドは、defaultネームスペースに属していない全てのStatefulSetとServiceを選択します。
kubectl get statefulsets,services --field-selector metadata.namespace!= default
1.3.8 - ファイナライザー(Finalizers)
ファイナライザーは、削除対象としてマークされたリソースを完全に削除する前に、特定の条件が満たされるまでKubernetesを待機させるための名前空間付きのキーです。
ファイナライザーは、削除されたオブジェクトが所有していたリソースをクリーンアップするようにコントローラー に警告します。
Kubernetesにファイナライザーが指定されたオブジェクトを削除するように指示すると、Kubernetes APIはそのオブジェクトに.metadata.deletionTimestampを追加し削除対象としてマークして、ステータスコード202(HTTP "Accepted")を返します。
コントロールプレーンやその他のコンポーネントがファイナライザーによって定義されたアクションを実行している間、対象のオブジェクトは終了中の状態のまま残っています。
それらのアクションが完了したら、そのコントローラーは関係しているファイナライザーを対象のオブジェクトから削除します。
metadata.finalizersフィールドが空になったら、Kubernetesは削除が完了したと判断しオブジェクトを削除します。
ファイナライザーはリソースのガベージコレクション を管理するために使うことができます。
例えば、コントローラーが対象のリソースを削除する前に関連するリソースやインフラをクリーンアップするためにファイナライザーを定義することができます。
ファイナライザーを利用すると、対象のリソースを削除する前に特定のクリーンアップを行うようにコントローラー に警告することで、ガベージコレクション を管理することができます。
大抵の場合ファイナライザーは実行されるコードを指定することはありません。
その代わり、一般的にはアノテーションのように特定のリソースに関するキーのリストになります。
Kubernetesはいくつかのファイナライザーを自動的に追加しますが、自分で追加することもできます。
ファイナライザーはどのように動作するか
マニフェストファイルを使ってリソースを作るとき、metadata.finalizersフィールドの中でファイナライザーを指定することができます。
リソースを削除しようとするとき、削除リクエストを扱うAPIサーバーはfinalizersフィールドの値を確認し、以下のように扱います。
削除を開始した時間をオブジェクトのmetadata.deletionTimestampフィールドに設定します。
metadata.finalizersフィールドが空になるまでオブジェクトが削除されるのを阻止します。ステータスコード202(HTTP "Accepted")を返します。
ファイナライザーを管理しているコントローラーは、オブジェクトの削除がリクエストされたことを示すmetadata.deletionTimestampがオブジェクトに設定されたことを検知します。
するとコントローラーはリソースに指定されたファイナライザーの要求を満たそうとします。
ファイナライザーの条件が満たされるたびに、そのコントローラーはリソースのfinalizersフィールドの対象のキーを削除します。
finalizersフィールドが空になったとき、deletionTimestampフィールドが設定されたオブジェクトは自動的に削除されます。管理外のリソース削除を防ぐためにファイナライザーを利用することもできます。
ファイナライザーの一般的な例はkubernetes.io/pv-protectionで、これは PersistentVolumeオブジェクトが誤って削除されるのを防ぐためのものです。
PersistentVolumeオブジェクトをPodが利用中の場合、Kubernetesはpv-protectionファイナライザーを追加します。
PersistentVolumeを削除しようとするとTerminatingステータスになりますが、ファイナライザーが存在しているためコントローラーはボリュームを削除することができません。
PodがPersistentVolumeの利用を停止するとKubernetesはpv-protectionファイナライザーを削除し、コントローラーがボリュームを削除します。
オーナーリファレンス、ラベル、ファイナライザー
ラベル のように、
オーナーリファレンス はKubernetesのオブジェクト間の関係性を説明しますが、利用される目的が異なります。
コントローラー がPodのようなオブジェクトを管理するとき、関連するオブジェクトのグループの変更を追跡するためにラベルを利用します。
例えば、Job がいくつかのPodを作成するとき、JobコントローラーはそれらのPodにラベルを付け、クラスター内の同じラベルを持つPodの変更を追跡します。
Jobコントローラーは、Podを作成したJobを指すオーナーリファレンス もそれらのPodに追加します。
Podが実行されているときにJobを削除すると、Kubernetesはオーナーリファレンス(ラベルではない)を使って、クリーンアップする必要のあるPodをクラスター内から探し出します。
また、Kubernetesは削除対象のリソースのオーナーリファレンスを認識して、ファイナライザーを処理します。
状況によっては、ファイナライザーが依存オブジェクトの削除をブロックしてしまい、対象のオーナーオブジェクトが完全に削除されず予想以上に長時間残ってしまうことがあります。
このような状況では、対象のオーナーと依存オブジェクトの、ファイナライザーとオーナーリファレンスを確認して問題を解決する必要があります。
備考: オブジェクトが削除中の状態で詰まってしまった場合、削除を続行するために手動でファイナライザーを削除することは避けてください。
通常、ファイナライザーは理由があってリソースに追加されているものであるため、強制的に削除してしまうとクラスターで何らかの問題を引き起こすことがあります。
そのファイナライザーの目的を理解しているかつ、別の方法で達成できる場合にのみ行うべきです(例えば、依存オブジェクトを手動で削除するなど)。
次の項目
1.3.9 - オーナーと従属
Kubernetesでは、いくつかのオブジェクトは他のオブジェクトのオーナー になっています。
例えば、ReplicaSet はPodの集合のオーナーです。
これらの所有されているオブジェクトはオーナーに従属 しています。
オーナーシップはいくつかのリソースでも使われているラベルとセレクター とは仕組みが異なります。
例として、EndpointSliceオブジェクトを作成するServiceオブジェクトを考えてみます。
Serviceはラベルを使ってどのEndpointSliceがどのServiceに利用されているかをコントロールプレーンに判断させています。
ラベルに加えて、Serviceの代わりに管理される各EndpointSliceはオーナーリファレンスを持ちます。
オーナーリファレンスは、Kubernetesの様々な箇所で管理外のオブジェクトに干渉してしまうのを避けるのに役立ちます。
オブジェクト仕様におけるオーナーリファレンス
従属オブジェクトはオーナーオブジェクトを参照するためのmetadata.ownerReferencesフィールドを持っています。
有効なオーナーリファレンスは従属オブジェクトと同じ名前空間に存在するオブジェクトの名前とUIDで構成されます。
KubernetesはReplicaSet、DaemonSet、Deployment、Job、CronJob、ReplicationControllerのようなオブジェクトの従属オブジェクトに、自動的に値を設定します。
このフィールドの値を手動で変更することで、これらの関係性を自分で設定することもできます。
ただし、通常はその必要はなく、Kubernetesが自動で管理するようにすることができます。
従属オブジェクトは、オーナーオブジェクトが削除されたときにガベージコレクションをブロックするかどうかを管理する真偽値を取るownerReferences.blockOwnerDeletionフィールドも持っています。
Kubernetesは、コントローラー
(例:Deploymentコントローラー)がmetadata.ownerReferencesフィールドに値を設定している場合、自動的にこのフィールドをtrueに設定します。
blockOwnerDeletionフィールドに手動で値を設定することで、どの従属オブジェクトがガベージコレクションをブロックするかを設定することもできます。
Kubernetesのアドミッションコントローラーはオーナーの削除権限に基づいて、ユーザーが従属リソースのこのフィールドを変更できるかを管理しています。
これにより、認証されていないユーザーがオーナーオブジェクトの削除を遅らせることを防ぎます。
備考: 名前空間をまたぐオーナーリファレンスは仕様により許可されていません。
名前空間付き従属オブジェクトには、クラスタースコープ、または名前空間付きのオーナーを指定することができます。名前空間付きオーナーは必ず 従属オブジェクトと同じ名前空間に存在していなければなりません。
そうでない場合、オーナーリファレンスはないものとして扱われ、全てのオーナーがいなくなった時点で従属オブジェクトは削除対象となります。
クラスタースコープの従属オブジェクトはクラスタースコープのオーナーのみ指定できます。
v1.20以降では、クラスタースコープの従属オブジェクトが名前空間付きのオブジェクトをオーナーとした場合、
解決できないオーナーリファレンスを持っているものとして扱われ、ガベージコレクションの対象とすることができません。
v1.20以降で、ガベージコレクターが無効な名前空間またぎのownerReferenceや名前空間付きのオーナーに依存するクラスタースコープのオブジェクトなどを検知した場合、OwnerRefInvalidNamespaceを理由とした警告のEventを出し、involvedObjectで無効な従属オブジェクトを報告します。
kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespaceを実行することで、この種類のEventを確認することができます。
オーナーシップとファイナライザー
Kubernetesでリソースを削除するとき、APIサーバーはリソースを管理するコントローラーにファイナライザールール を処理させることができます。
ファイナライザー はクラスターが正しく機能するために必要なリソースを誤って削除してしまうことを防ぎます。
例えば、まだPodが使用中のPersistentVolumeを削除しようとするとき、PersistentVolumeが持っているkubernetes.io/pv-protectionファイナライザーにより、削除は即座には行われません。
その代わり、Kubernetesがファイナライザーを削除するまでボリュームはTerminatingステータスのまま残り、PersistentVolumeがPodにバインドされなくなった後で削除が行われます。
またKubernetesはフォアグラウンド、孤立したオブジェクトのカスケード削除 を行ったとき、オーナーリソースにファイナライザーを追加します。
フォアグラウンド削除では、foregroundファイナライザーを追加し、オーナーを削除する前にコントローラーがownerReferences.blockOwnerDeletion=trueを持っている従属リソースを削除するようにします。
孤立したオブジェクトの削除を行う場合、Kubernetesはorphanファイナライザーを追加し、オーナーオブジェクトを削除した後にコントローラーが従属リソースを無視するようにします。
次の項目
1.3.10 - 推奨ラベル(Recommended Labels)
ユーザーはkubectlやダッシュボード以外に、多くのツールでKubernetesオブジェクトの管理と可視化ができます。共通のラベルセットにより、全てのツールにおいて解釈可能な共通のマナーに沿ってオブジェクトを表現することで、ツールの相互運用を可能にします。
ツール化に対するサポートに加えて、推奨ラベルはクエリ可能な方法でアプリケーションを表現します。
メタデータは、アプリケーション のコンセプトを中心に構成されています。KubernetesはPaaS(Platform as a Service)でなく、アプリケーションの公式な概念を持たず、またそれを強制することはありません。
そのかわり、アプリケーションは、非公式で、メタデータによって表現されています。単一のアプリケーションが有する項目に対する定義は厳密に決められていません。
備考: ラベルには推奨ラベルというものがあります。それらのラベルはアプリケーションの管理を容易にします。しかしコア機能のツール化において必須のものではありません。
共有されたラベルとアノテーションは、app.kubernetes.ioという共通のプレフィックスを持ちます。プレフィックスの無いラベルはユーザーに対してプライベートなものになります。その共有されたプレフィックスは、共有ラベルがユーザーのカスタムラベルに干渉しないことを保証します。
ラベル
これらの推奨ラベルの利点を最大限得るためには、全てのリソースオブジェクトに対して推奨ラベルが適用されるべきです。
キー
説明
例
型
app.kubernetes.io/nameアプリケーション名
mysql文字列
app.kubernetes.io/instanceアプリケーションのインスタンスを特定するための固有名
mysql-abcxzy文字列
app.kubernetes.io/versionアプリケーションの現在のバージョン (例: セマンティックバージョン、リビジョンのハッシュなど)
5.7.21文字列
app.kubernetes.io/componentアーキテクチャ内のコンポーネント
database文字列
app.kubernetes.io/part-ofこのアプリケーションによって構成される上位レベルのアプリケーション
wordpress文字列
app.kubernetes.io/managed-byこのアプリケーションの操作を管理するために使われているツール
helm文字列
これらのラベルが実際にどう使われているかを表すために、下記のStatefulSetのオブジェクトを考えましょう。
apiVersion : apps/v1
kind : StatefulSet
metadata :
labels :
app.kubernetes.io/name : mysql
app.kubernetes.io/instance : mysql-abcxzy
app.kubernetes.io/version : "5.7.21"
app.kubernetes.io/component : database
app.kubernetes.io/part-of : wordpress
app.kubernetes.io/managed-by : helm
アプリケーションとアプリケーションのインスタンス
単一のアプリケーションは、Kubernetesクラスター内で、いくつかのケースでは同一の名前空間に対して1回または複数回インストールされることがあります。
例えば、WordPressは複数のウェブサイトがあれば、それぞれ別のWordPressが複数回インストールされることがあります。
アプリケーション名と、アプリケーションのインスタンス名はそれぞれ別に記録されます。
例えば、WordPressはapp.kubernetes.io/nameにwordpressと記述され、インスタンス名に関してはapp.kubernetes.io/instanceにwordpress-abcxzyと記述されます。この仕組みはアプリケーションと、アプリケーションのインスタンスを特定可能にします。全てのアプリケーションインスタンスは固有の名前を持たなければなりません。
ラベルの使用例
ここでは、ラベルの異なる使用例を示します。これらの例はそれぞれシステムの複雑さが異なります。
シンプルなステートレスサービス
DeploymentとServiceオブジェクトを使って、シンプルなステートレスサービスをデプロイするケースを考えます。下記の2つのスニペットはラベルが最もシンプルな形式においてどのように使われるかをあらわします。
下記のDeploymentは、アプリケーションを稼働させるポッドを管理するのに使われます。
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
app.kubernetes.io/name : myservice
app.kubernetes.io/instance : myservice-abcxzy
...
下記のServiceは、アプリケーションを公開するために使われます。
apiVersion : v1
kind : Service
metadata :
labels :
app.kubernetes.io/name : myservice
app.kubernetes.io/instance : myservice-abcxzy
...
データベースを使ったウェブアプリケーション
次にもう少し複雑なアプリケーションについて考えます。データベース(MySQL)を使ったウェブアプリケーション(WordPress)で、Helmを使ってインストールします。
下記のスニペットは、このアプリケーションをデプロイするために使うオブジェクト設定の出だし部分です。
はじめに下記のDeploymentは、WordPressのために使われます。
apiVersion : apps/v1
kind : Deployment
metadata :
labels :
app.kubernetes.io/name : wordpress
app.kubernetes.io/instance : wordpress-abcxzy
app.kubernetes.io/version : "4.9.4"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : server
app.kubernetes.io/part-of : wordpress
...
下記のServiceは、WordPressを公開するために使われます。
apiVersion : v1
kind : Service
metadata :
labels :
app.kubernetes.io/name : wordpress
app.kubernetes.io/instance : wordpress-abcxzy
app.kubernetes.io/version : "4.9.4"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : server
app.kubernetes.io/part-of : wordpress
...
MySQLはStatefulSetとして公開され、MySQL自身と、MySQLが属する親アプリケーションのメタデータを持ちます。
apiVersion : apps/v1
kind : StatefulSet
metadata :
labels :
app.kubernetes.io/name : mysql
app.kubernetes.io/instance : mysql-abcxzy
app.kubernetes.io/version : "5.7.21"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : database
app.kubernetes.io/part-of : wordpress
...
このServiceはMySQLをWordPressアプリケーションの一部として公開します。
apiVersion : v1
kind : Service
metadata :
labels :
app.kubernetes.io/name : mysql
app.kubernetes.io/instance : mysql-abcxzy
app.kubernetes.io/version : "5.7.21"
app.kubernetes.io/managed-by : helm
app.kubernetes.io/component : database
app.kubernetes.io/part-of : wordpress
...
MySQLのStatefulSetとServiceにより、MySQLとWordPressに関するより広範な情報が含まれていることに気づくでしょう。
2 - クラスターのアーキテクチャ
Kubernetesの背後にあるアーキテクチャのコンセプト。
Kubernetesクラスターのアーキテクチャ
2.1 - ノード
Kubernetesはコンテナを Node 上で実行されるPodに配置することで、ワークロードを実行します。
ノードはクラスターによりますが、1つのVMまたは物理的なマシンです。
各ノードはPod やそれを制御するコントロールプレーン を実行するのに必要なサービスを含んでいます。
通常、1つのクラスターで複数のノードを持ちます。学習用途やリソースの制限がある環境では、1ノードかもしれません。
1つのノード上のコンポーネント には、kubelet 、コンテナランタイム 、kube-proxy が含まれます。
管理
ノードをAPIサーバー に加えるには2つの方法があります:
ノード上のkubeletが、コントロールプレーンに自己登録する。
あなた、もしくは他のユーザーが手動でNodeオブジェクトを追加する。
Nodeオブジェクトの作成、もしくはノード上のkubeletによる自己登録の後、コントロールプレーンはNodeオブジェクトが有効かチェックします。例えば、下記のjsonマニフェストでノードを作成してみましょう:
{
"kind" : "Node" ,
"apiVersion" : "v1" ,
"metadata" : {
"name" : "10.240.79.157" ,
"labels" : {
"name" : "my-first-k8s-node"
}
}
}
Kubernetesは内部的にNodeオブジェクトを作成します。 APIサーバーに登録したkubeletがノードのmetadata.nameフィールドが一致しているか検証します。ノードが有効な場合、つまり必要なサービスがすべて実行されている場合は、Podを実行する資格があります。それ以外の場合、該当ノードが有効になるまではいかなるクラスターの活動に対しても無視されます。
備考: Kubernetesは無効なNodeのオブジェクトを保持し、それが有効になるまで検証を続けます。
ヘルスチェックを止めるためには、あなた、もしくはコントローラー が明示的にNodeを削除する必要があります。
Nodeオブジェクトの名前は有効なDNSサブドメイン名 である必要があります。
ノードの自己登録
kubeletのフラグ --register-nodeがtrue(デフォルト)のとき、kubeletは自分自身をAPIサーバーに登録しようとします。これはほとんどのディストリビューションで使用されている推奨パターンです。
自己登録については、kubeletは以下のオプションを伴って起動されます:
--kubeconfig - 自分自身をAPIサーバーに対して認証するための資格情報へのパス--cloud-provider - 自身に関するメタデータを読むためにクラウドプロバイダー と会話する方法--register-node - 自身をAPIサーバーに自動的に登録--register-with-taints - 与えられたtaint のリストでノードを登録します (カンマ区切りの <key>=<value>:<effect>)。
register-nodeがfalseの場合、このオプションは機能しません
--node-ip - ノードのIPアドレス--node-labels - ノードをクラスターに登録するときに追加するLabel (NodeRestriction許可プラグイン によって適用されるラベルの制限を参照)--node-status-update-frequency - kubeletがノードのステータスをマスターにPOSTする頻度の指定
ノード認証モード およびNodeRestriction許可プラグイン が有効になっている場合、kubeletは自分自身のノードリソースを作成/変更することのみ許可されています。
手動によるノード管理
クラスター管理者はkubectl を使用してNodeオブジェクトを作成および変更できます。
管理者が手動でNodeオブジェクトを作成したい場合は、kubeletフラグ --register-node = falseを設定してください。
管理者は--register-nodeの設定に関係なくNodeオブジェクトを変更することができます。
例えば、ノードにラベルを設定し、それをunschedulableとしてマークすることが含まれます。
ノード上のラベルは、スケジューリングを制御するためにPod上のノードセレクターと組み合わせて使用できます。
例えば、Podをノードのサブセットでのみ実行する資格があるように制限します。
ノードをunschedulableとしてマークすると、新しいPodがそのノードにスケジュールされるのを防ぎますが、ノード上の既存のPodには影響しません。
これは、ノードの再起動などの前の準備ステップとして役立ちます。
ノードにスケジュール不可能のマークを付けるには、次のコマンドを実行します:
備考: DaemonSet によって作成されたPodはノード上のunschedulable属性を考慮しません。
これは、再起動の準備中にアプリケーションからアプリケーションが削除されている場合でも、DaemonSetがマシンに属していることを前提としているためです。
ノードのステータス
ノードのステータスは以下の情報を含みます:
kubectlを使用し、ノードのステータスや詳細を確認できます:
kubectl describe node <ノード名をここに挿入>
出力情報の各箇所について、以下で説明します。
Addresses
これらのフィールドの使い方は、お使いのクラウドプロバイダーやベアメタルの設定内容によって異なります。
HostName: ノードのカーネルによって伝えられたホスト名です。kubeletの--hostname-overrideパラメーターによって上書きすることができます。
ExternalIP: 通常は、外部にルーティング可能(クラスターの外からアクセス可能)なノードのIPアドレスです。
InternalIP: 通常は、クラスター内でのみルーティング可能なノードのIPアドレスです。
Conditions
conditionsフィールドは全てのRunningなノードのステータスを表します。例として、以下のような状態を含みます:
ノードのConditionと、各condition適用時の概要
ノードのCondition
概要
Readyノードの状態が有効でPodを配置可能な場合にTrueになります。ノードの状態に問題があり、Podが配置できない場合にFalseになります。ノードコントローラーが、node-monitor-grace-periodで設定された時間内(デフォルトでは40秒)に該当ノードと疎通できない場合、Unknownになります。
DiskPressureノードのディスク容量が圧迫されているときにTrueになります。圧迫とは、ディスクの空き容量が少ないことを指します。それ以外のときはFalseです。
MemoryPressureノードのメモリが圧迫されているときにTrueになります。圧迫とは、メモリの空き容量が少ないことを指します。それ以外のときはFalseです。
PIDPressureプロセスが圧迫されているときにTrueになります。圧迫とは、プロセス数が多すぎることを指します。それ以外のときはFalseです。
NetworkUnavailableノードのネットワークが適切に設定されていない場合にTrueになります。それ以外のときはFalseです。
備考: コマンドラインを使用してcordonされたNodeを表示する場合、ConditionはSchedulingDisabledを含みます。
SchedulingDisabledはKubernetesのAPIにおけるConditionではありません;その代わり、cordonされたノードはUnschedulableとしてマークされます。
Nodeの状態は、Nodeリソースの.statusの一部として表現されます。例えば、正常なノードの場合は以下のようなjson構造が表示されます。
"conditions" : [
{
"type" : "Ready" ,
"status" : "True" ,
"reason" : "KubeletReady" ,
"message" : "kubelet is posting ready status" ,
"lastHeartbeatTime" : "2019-06-05T18:38:35Z" ,
"lastTransitionTime" : "2019-06-05T11:41:27Z"
}
]
Ready conditionがpod-eviction-timeout(kube-controller-manager に渡された引数)に設定された時間を超えてもUnknownやFalseのままになっている場合、該当ノード上にあるPodはノードコントローラーによって削除がスケジュールされます。デフォルトの退役のタイムアウトの時間は5分 です。ノードが到達不能ないくつかの場合においては、APIサーバーが該当ノードのkubeletと疎通できない状態になっています。その場合、APIサーバーがkubeletと再び通信を確立するまでの間、Podの削除を行うことはできません。削除がスケジュールされるまでの間、削除対象のPodは切り離されたノードの上で稼働を続けることになります。
ノードコントローラーはクラスター内でPodが停止するのを確認するまでは強制的に削除しないようになりました。到達不能なノード上で動いているPodはTerminatingまたはUnknownのステータスになります。Kubernetesが基盤となるインフラストラクチャーを推定できない場合、クラスター管理者は手動でNodeオブジェクトを削除する必要があります。KubernetesからNodeオブジェクトを削除すると、そのノードで実行されているすべてのPodオブジェクトがAPIサーバーから削除され、それらの名前が解放されます。
ノードのライフサイクルコントローラーがconditionを表したtaint を自動的に生成します。
スケジューラーがPodをノードに割り当てる際、ノードのtaintを考慮します。Podが許容するtaintは例外です。
詳細は条件によるtaintの付与 を参照してください。
CapacityとAllocatable
ノードで利用可能なリソース(CPU、メモリ、およびノードでスケジュールできる最大Pod数)について説明します。
capacityブロック内のフィールドは、ノードが持っているリソースの合計量を示します。
allocatableブロックは、通常のPodによって消費されるノード上のリソースの量を示します。
CapacityとAllocatableについて深く知りたい場合は、ノード上でどのようにコンピュートリソースが予約されるか を読みながら学ぶことができます。
Info
カーネルのバージョン、Kubernetesのバージョン(kubeletおよびkube-proxyのバージョン)、(使用されている場合)Dockerのバージョン、OS名など、ノードに関する一般的な情報です。
この情報はノードからkubeletを通じて取得され、Kubernetes APIに公開されます。
ノードのハートビート
ハートビートは、Kubernetesノードから送信され、ノードが利用可能か判断するのに役立ちます。
以下の2つのハートビートがあります:
Nodeの.statusの更新
Lease object です。
各ノードはkube-node-leaseというnamespace に関連したLeaseオブジェクトを持ちます。
Leaseは軽量なリソースで、クラスターのスケールに応じてノードのハートビートにおけるパフォーマンスを改善します。
kubeletがNodeStatusとLeaseオブジェクトの作成および更新を担当します。
kubeletは、ステータスに変化があったり、設定した間隔の間に更新がない時にNodeStatusを更新します。NodeStatus更新のデフォルト間隔は5分です。(到達不能の場合のデフォルトタイムアウトである40秒よりもはるかに長いです)
kubeletは10秒間隔(デフォルトの更新間隔)でLeaseオブジェクトの生成と更新を実施します。Leaseの更新はNodeStatusの更新とは独立されて行われます。Leaseの更新が失敗した場合、kubeletは200ミリ秒から始まり7秒を上限とした指数バックオフでリトライします。
ノードコントローラー
ノードコントローラー は、ノードのさまざまな側面を管理するKubernetesのコントロールプレーンコンポーネントです。
ノードコントローラーは、ノードの存続期間中に複数の役割を果たします。1つ目は、ノードが登録されたときにCIDRブロックをノードに割り当てることです(CIDR割り当てがオンになっている場合)。
2つ目は、ノードコントローラーの内部ノードリストをクラウドの利用可能なマシンのリストと一致させることです。
クラウド環境で実行している場合、ノードに異常があると、ノードコントローラーはクラウドプロバイダーにそのNodeのVMがまだ使用可能かどうかを問い合わせます。
使用可能でない場合、ノードコントローラーはノードのリストから該当ノードを削除します。
3つ目は、ノードの状態を監視することです。
ノードが到達不能(例えば、ノードがダウンしているなどので理由で、ノードコントローラーがハートビートの受信を停止した場合)になると、ノードコントローラーは、NodeStatusのNodeReady conditionをConditionUnknownに変更する役割があります。その後も該当ノードが到達不能のままであった場合、Graceful Terminationを使って全てのPodを退役させます。デフォルトのタイムアウトは、ConditionUnknownの報告を開始するまで40秒、その後Podの追い出しを開始するまで5分に設定されています。
ノードコントローラーは、--node-monitor-periodに設定された秒数ごとに各ノードの状態をチェックします。
信頼性
ほとんどの場合、排除の速度は1秒あたり--node-eviction-rateに設定された数値(デフォルトは秒間0.1)です。つまり、10秒間に1つ以上のPodをノードから追い出すことはありません。
特定のアベイラビリティーゾーン内のノードのステータスが異常になると、ノード排除の挙動が変わります。ノードコントローラーは、ゾーン内のノードの何%が異常(NodeReady条件がConditionUnknownまたはConditionFalseである)であるかを同時に確認します。
異常なノードの割合が少なくとも --healthy-zone-thresholdに設定した値を下回る場合(デフォルトは0.55)であれば、退役率は低下します。クラスターが小さい場合(すなわち、 --large-cluster-size-thresholdの設定値よりもノード数が少ない場合。デフォルトは50)、退役は停止し、そうでない場合、退役率は秒間で--secondary-node-eviction-rateの設定値(デフォルトは0.01)に減少します。
これらのポリシーがアベイラビリティーゾーンごとに実装されているのは、1つのアベイラビリティーゾーンがマスターから分割される一方、他のアベイラビリティーゾーンは接続されたままになる可能性があるためです。
クラスターが複数のクラウドプロバイダーのアベイラビリティーゾーンにまたがっていない場合、アベイラビリティーゾーンは1つだけです(クラスター全体)。
ノードを複数のアベイラビリティゾーンに分散させる主な理由は、1つのゾーン全体が停止したときにワークロードを正常なゾーンに移動できることです。
したがって、ゾーン内のすべてのノードが異常である場合、ノードコントローラーは通常のレート --node-eviction-rateで退役します。
コーナーケースは、すべてのゾーンが完全にUnhealthyである(すなわち、クラスター内にHealthyなノードがない)場合です。
このような場合、ノードコントローラーはマスター接続に問題があると見なし、接続が回復するまですべての退役を停止します。
ノードコントローラーは、Podがtaintを許容しない場合、 NoExecuteのtaintを持つノード上で実行されているPodを排除する責務もあります。
さらに、ノードコントローラーはノードに到達できない、または準備ができていないなどのノードの問題に対応するtaint を追加する責務があります。これはスケジューラーが、問題のあるノードにPodを配置しない事を意味しています。
ノードのキャパシティ
Nodeオブジェクトはノードのリソースキャパシティ(CPUの数とメモリの量)を監視します。
自己登録 したノードは、Nodeオブジェクトを作成するときにキャパシティを報告します。
手動によるノード管理 を実行している場合は、ノードを追加するときにキャパシティを設定する必要があります。
Kubernetesスケジューラー は、ノード上のすべてのPodに十分なリソースがあることを確認します。スケジューラーは、ノード上のコンテナが要求するリソースの合計がノードキャパシティ以下であることを確認します。
これは、kubeletによって管理されたすべてのコンテナを含みますが、コンテナランタイムによって直接開始されたコンテナやkubeletの制御外で実行されているプロセスは含みません。
ノードのトポロジー
FEATURE STATE: Kubernetes v1.16 [alpha]
TopologyManagerの
フィーチャーゲート を有効にすると、
kubeletはリソースの割当を決定する際にトポロジーのヒントを利用できます。
詳細は、
ノードのトポロジー管理ポリシーを制御する を参照してください。
ノードの正常終了
FEATURE STATE: Kubernetes v1.21 [beta]
kubeletは、ノードのシステムシャットダウンを検出すると、ノード上で動作しているPodを終了させます。
Kubelet は、ノードのシャットダウン時に、ポッドが通常の通常のポッド終了プロセス に従うようにします。
Graceful Node Shutdownはsystemdに依存しているため、systemd inhibitor locks を
利用してノードのシャットダウンを一定時間遅らせることができます。
Graceful Node Shutdownは、v1.21でデフォルトで有効になっているGracefulNodeShutdown フィーチャーゲート で制御されます。
なお、デフォルトでは、後述の設定オプションShutdownGracePeriodおよびShutdownGracePeriodCriticalPodsの両方がゼロに設定されているため、Graceful node shutdownは有効になりません。この機能を有効にするには、この2つのkubeletの設定を適切に設定し、ゼロ以外の値を設定する必要があります。
Graceful shutdownでは、kubeletは以下の2段階でPodを終了させます。
そのノード上で動作している通常のPodを終了させます。
そのノード上で動作しているcritical pods を終了させます。
Graceful Node Shutdownには、2つのKubeletConfiguration
ShutdownGracePeriod:
ノードがシャットダウンを遅らせるべき合計期間を指定します。これは、通常のPodとcritical pods の両方のPod終了の合計猶予期間です。
ShutdownGracePeriodCriticalPods:
ノードのシャットダウン時にcritical pods を終了させるために使用する期間を指定します。この値は、ShutdownGracePeriodよりも小さくする必要があります。
例えば、ShutdownGracePeriod=30s、ShutdownGracePeriodCriticalPods=10sとすると、
kubeletはノードのシャットダウンを30秒遅らせます。シャットダウンの間、最初の20(30-10)秒は通常のポッドを優雅に終了させるために確保され、
残りの10秒は重要なポッドを終了させるために確保されることになります。
備考: Graceful Node Shutdown中にPodが退避された場合、それらのPodの.statusはFailedになります。
kubectl get podsを実行すると、退避させられたPodのステータスが Shutdown と表示されます。
また、kubectl describe podを実行すると、ノードのシャットダウンのためにPodが退避されたことがわかります。
Status: Failed
Reason: Shutdown
Message: Node is shutting, evicting pods
失敗したポッドオブジェクトは、明示的に削除されるか、GCによってクリーンアップ されるまで保存されます。
これは、ノードが突然終了した場合とは異なった振る舞いです。
ノードの非正常終了
FEATURE STATE: Kubernetes v1.26 [beta]
コマンドがkubeletのinhibitor locksメカニズムをトリガーしない場合や、ShutdownGracePeriodやShutdownGracePeriodCriticalPodsが適切に設定されていないといったユーザーによるミス等が原因で、ノードがシャットダウンしたことをkubeletのNode Shutdownマネージャーが検知できないことがあります。詳細は上記セクションノードの正常終了 を参照ください。
ノードのシャットダウンがkubeletのNode Shutdownマネージャーに検知されない場合、StatefulSetを構成するPodはシャットダウン状態のノード上でterminating状態のままになってしまい、他の実行中のノードに移動することができなくなってしまいます。これは、ノードがシャットダウンしているため、その上のkubeletがPodを削除できず、それにより、StatefulSetが新しいPodを同じ名前で作成できなくなってしまうためです。Podがボリュームを使用している場合、VolumeAttachmentsはシャットダウン状態のノードによって削除されないため、Podが使用しているボリュームは他の実行中のノードにアタッチすることができなくなってしまいます。その結果として、StatefulSet上で実行中のアプリケーションは適切に機能しなくなってしまいます。シャットダウンしていたノードが復旧した場合、そのノード上のPodはkubeletに削除され、他の実行中のノード上に作成されます。また、シャットダウン状態のノードが復旧できなかった場合は、そのノード上のPodは永久にterminating状態のままとなります。
上記の状況を脱却するには、ユーザーが手動でNoExecuteまたはNoSchedule effectを設定してnode.kubernetes.io/out-of-service taintをノードに付与することで、故障中の状態に設定することができます。kube-controller-manager において NodeOutOfServiceVolumeDetachフィーチャーゲート が有効になっており、かつノードがtaintによって故障中としてマークされている場合は、ノードに一致するtolerationがないPodは強制的に削除され、ノード上のterminating状態のPodに対するボリュームデタッチ操作が直ちに実行されます。これにより、故障中のノード上のPodを異なるノード上にすばやく復旧させることが可能になります。
non-graceful shutdownの間に、Podは以下の2段階で終了します:
一致するout-of-service tolerationを持たないPodを強制的に削除する。
上記のPodに対して即座にボリュームデタッチ操作を行う。
備考:
node.kubernetes.io/out-of-service taintを付与する前に、ノードがシャットダウンしているか電源がオフになっていることを確認してください(再起動中ではないこと)。Podの別ノードへの移動後、シャットダウンしていたノードが回復した場合は、ユーザーが手動で付与したout-of-service taintをユーザー自ら手動で削除する必要があります。
スワップメモリの管理
FEATURE STATE: Kubernetes v1.22 [alpha]
Kubernetes 1.22以前では、ノードはスワップメモリの使用をサポートしておらず、ノード上でスワップが検出された場合、
kubeletはデフォルトで起動に失敗していました。1.22以降では、スワップメモリのサポートをノードごとに有効にすることができます。
ノードでスワップを有効にするには、kubeletの NodeSwap フィーチャーゲート を有効にし、
--fail-swap-onコマンドラインフラグまたはfailSwapOnKubeletConfiguration を false に設定する必要があります。
ユーザーはオプションで、ノードがスワップメモリをどのように使用するかを指定するために、memorySwap.swapBehaviorを設定することもできます。ノードがスワップメモリをどのように使用するかを指定します。例えば、以下のようになります。
memorySwap :
swapBehavior : LimitedSwap
swapBehaviorで使用できる設定オプションは以下の通りです。:
LimitedSwap: Kubernetesのワークロードが、使用できるスワップ量に制限を設けます。Kubernetesが管理していないノード上のワークロードは、依然としてスワップを使用できます。UnlimitedSwap: Kubernetesのワークロードが使用できるスワップ量に制限を設けません。システムの限界まで、要求されただけのスワップメモリを使用することができます。
memorySwapの設定が指定されておらず、フィーチャーゲート が有効な場合、デフォルトのkubeletはLimitedSwapの設定と同じ動作を適用します。
LimitedSwap設定の動作は、ノードがコントロールグループ(「cgroups」とも呼ばれる)のv1とv2のどちらで動作しているかによって異なります。
Kubernetesのワークロードでは、メモリとスワップを組み合わせて使用することができ、ポッドのメモリ制限が設定されている場合はその制限まで使用できます。
cgroupsv1: Kubernetesのワークロードは、メモリとスワップを組み合わせて使用することができ、ポッドのメモリ制限が設定されている場合はその制限まで使用できます。cgroupsv2: Kubernetesのワークロードは、スワップメモリを使用できません。
詳しくは、KEP-2400 と
design proposal をご覧いただき、テストにご協力、ご意見をお聞かせください。
次の項目
2.2 - ノードとコントロールプレーン間の通信
本ドキュメントは、APIサーバー とKubernetesクラスター 間の通信経路をまとめたものです。
その目的は、信頼できないネットワーク上(またはクラウドプロバイダー上の完全なパブリックIP)でクラスターが実行できるよう、ユーザーがインストールをカスタマイズしてネットワーク構成を強固にできるようにすることです。
ノードからコントロールプレーンへの通信
Kubernetesには「ハブアンドスポーク」というAPIパターンがあります。ノード(またはノードが実行するPod)からのすべてのAPIの使用は、APIサーバーで終了します。他のコントロールプレーンコンポーネントは、どれもリモートサービスを公開するようには設計されていません。APIサーバーは、1つ以上の形式のクライアント認証 が有効になっている状態で、セキュアなHTTPSポート(通常は443)でリモート接続をリッスンするように設定されています。
特に匿名リクエスト やサービスアカウントトークン が許可されている場合は、1つ以上の認可 形式を有効にする必要があります。
ノードは、有効なクライアント認証情報とともに、APIサーバーに安全に接続できるように、クラスターのパブリックルート証明書 でプロビジョニングされる必要があります。適切なやり方は、kubeletに提供されるクライアント認証情報が、クライアント証明書の形式であることです。kubeletクライアント証明書の自動プロビジョニングについては、kubelet TLSブートストラップ を参照してください。
APIサーバーに接続したいPod は、サービスアカウントを利用することで、安全に接続することができます。これにより、Podのインスタンス化時に、Kubernetesはパブリックルート証明書と有効なBearerトークンを自動的にPodに挿入します。
kubernetesサービス(デフォルトの名前空間)は、APIサーバー上のHTTPSエンドポイントに(kube-proxy
また、コントロールプレーンのコンポーネントは、セキュアなポートを介してAPIサーバーとも通信します。
その結果、ノードやノード上で動作するPodからコントロールプレーンへの接続は、デフォルトでセキュアであり、信頼されていないネットワークやパブリックネットワークを介して実行することができます。
コントロールプレーンからノードへの通信
コントロールプレーン(APIサーバー)からノードへの主要な通信経路は2つあります。
1つ目は、APIサーバーからクラスター内の各ノードで実行されるkubelet プロセスへの通信経路です。
2つ目は、APIサーバーの プロキシ 機能を介した、APIサーバーから任意のノード、Pod、またはサービスへの通信経路です。
APIサーバーからkubeletへの通信
APIサーバーからkubeletへの接続は、以下の目的で使用されます:
Podのログの取得。
実行中のPodへのアタッチ(通常はkubectlを使用)。
kubeletのポート転送機能の提供。
これらの接続は、kubeletのHTTPSエンドポイントで終了します。デフォルトでは、APIサーバーはkubeletのサービング証明書を検証しないため、接続は中間者攻撃の対象となり、信頼されていないネットワークやパブリックネットワークを介して実行するのは安全ではありません 。
この接続を検証するには、--kubelet-certificate-authorityフラグを使用して、kubeletのサービング証明書を検証するために使用するルート証明書バンドルを、APIサーバーに提供します。
それができない場合は、信頼できないネットワークやパブリックネットワークを介した接続を回避するため、必要に応じてAPIサーバーとkubeletの間でSSHトンネル を使用します。
最後に、kubelet APIを保護するために、Kubelet認証/認可 を有効にする必要があります。
APIサーバーからノード、Pod、サービスへの通信
APIサーバーからノード、Pod、またはサービスへの接続は、デフォルトで平文のHTTP接続になるため、認証も暗号化もされません。API URL内のノード、Pod、サービス名にhttps:を付けることで、セキュアなHTTPS接続を介して実行できますが、HTTPSエンドポイントから提供された証明書を検証したり、クライアント認証情報を提供したりすることはありません。そのため、接続の暗号化はされますが、完全性の保証はありません。これらの接続を、信頼されていないネットワークやパブリックネットワークを介して実行するのは、現在のところ安全ではありません 。
SSHトンネル
Kubernetesは、コントロールプレーンからノードへの通信経路を保護するために、SSHトンネル をサポートしています。この構成では、APIサーバーがクラスター内の各ノードへのSSHトンネルを開始(ポート22でリッスンしているSSHサーバーに接続)し、kubelet、ノード、Pod、またはサービス宛てのすべてのトラフィックをトンネル経由で渡します。
このトンネルにより、ノードが稼働するネットワークの外部にトラフィックが公開されないようになります。
備考: SSHトンネルは現在非推奨であるため、自分が何をしているのか理解していないのであれば、使用すべきではありません。この通信経路の代替となるものとして、
Konnectivityサービス があります。
Konnectivityサービス
FEATURE STATE: Kubernetes v1.18 [beta]
SSHトンネルの代替として、Konnectivityサービスは、コントロールプレーンからクラスターへの通信に、TCPレベルのプロキシを提供します。Konnectivityサービスは、コントロールプレーンネットワークのKonnectivityサーバーと、ノードネットワークのKonnectivityエージェントの、2つの部分で構成されています。
Konnectivityエージェントは、Konnectivityサーバーへの接続を開始し、ネットワーク接続を維持します。
Konnectivityサービスを有効にすると、コントロールプレーンからノードへのトラフィックは、すべてこの接続を経由するようになります。
Konnectivityサービスのセットアップ に従って、クラスターにKonnectivityサービスをセットアップしてください。
次の項目
2.3 - リース
しばしば分散システムでは共有リソースをロックしたりノード間の活動を調整する機構として"リース"が必要になります。
Kubernetesでは、"リース"のコンセプトはcoordination.k8s.ioAPIグループのLeaseオブジェクトに表されていて、ノードのハートビートやコンポーネントレベルのリーダー選出といったシステムにとって重要な機能に利用されています。
ノードハートビート
Kubernetesでは、kubeletのノードハートビートをKubernetes APIサーバーに送信するのにLease APIが使われています。
各Nodeごとに、kube-node-lease名前空間にノードとマッチする名前のLeaseオブジェクトが存在します。
内部的には、kubeletのハートビートはこのLeaseオブジェクトに対するUPDATEリクエストであり、Leaseのspec.renewTimeフィールドを更新しています。
Kubernetesのコントロールプレーンはこのフィールドのタイムスタンプを見て、Nodeが利用可能かを判断しています。
詳しくはNode Leaseオブジェクト をご覧ください。
リーダー選出
Kubernetesでは、あるコンポーネントのインスタンスが常に一つだけ実行されていることを保証するためにもリースが利用されています。
これはkube-controller-managerやkube-schedulerといったコントロールプレーンのコンポーネントで、一つのインスタンスのみがアクティブに実行され、その他のインスタンスをスタンバイ状態とする必要があるような冗長構成を組むために利用されています。
APIサーバーのアイデンティティー
FEATURE STATE: Kubernetes v1.26 [beta]
Kubernetes v1.26から、各kube-apiserverはLease APIを利用して自身のアイデンティティーをその他のシステムに向けて公開するようになりました。
それ自体は特に有用ではありませんが、何台のkube-apiserverがKubernetesコントロールプレーンを稼働させているのかをクライアントが知るためのメカニズムを提供します。
kube-apiserverリースが存在することで、各kube-apiserver間の調整が必要となる可能性がある将来の機能が使えるようになります。
kube-system名前空間のkube-apiserver-<sha256-hash>という名前のリースオブジェクトを確認することで、各kube-apiserverが所有しているLeaseを確認することができます。
また、k8s.io/component=kube-apiserverラベルセレクターを利用することもできます。
$ kubectl -n kube-system get lease -l k8s.io/component= kube-apiserver
NAME HOLDER AGE
kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a_9cbf54e5-1136-44bd-8f9a-1dcd15c346b4 5m33s
kube-apiserver-dz2dqprdpsgnm756t5rnov7yka kube-apiserver-dz2dqprdpsgnm756t5rnov7yka_84f2a85d-37c1-4b14-b6b9-603e62e4896f 4m23s
kube-apiserver-fyloo45sdenffw2ugwaz3likua kube-apiserver-fyloo45sdenffw2ugwaz3likua_c5ffa286-8a9a-45d4-91e7-61118ed58d2e 4m43s
リースの名前に使われているSHA256ハッシュはkube-apiserverのOSホスト名に基づいています。各kube-apiserverはクラスター内で一意なホスト名を使用するように構成する必要があります。
同じホスト名を利用する新しいkube-apiserverインスタンスは、新しいリースオブジェクトを作成せずに、既存のLeaseを新しいインスタンスのアイデンティティーを利用して引き継ぎます。
kube-apiserverが使用するホスト名はkubernetes.io/hostnameラベルの値で確認できます。
$ kubectl -n kube-system get lease kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a -o yaml
apiVersion : coordination.k8s.io/v1
kind : Lease
metadata :
creationTimestamp : "2022-11-30T15:37:15Z"
labels :
k8s.io/component : kube-apiserver
kubernetes.io/hostname : kind-control-plane
name : kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a
namespace : kube-system
resourceVersion : "18171"
uid : d6c68901-4ec5-4385-b1ef-2d783738da6c
spec :
holderIdentity : kube-apiserver-c4vwjftbvpc5os2vvzle4qg27a_9cbf54e5-1136-44bd-8f9a-1dcd15c346b4
leaseDurationSeconds : 3600
renewTime : "2022-11-30T18:04:27.912073Z"
すでに存在しなくなったkube-apiserverの期限切れリースは、1時間後に新しいkube-apiserverによってガベージコレクションされます。
2.4 - コントローラー
ロボット工学やオートメーションの分野において、 制御ループ とは、あるシステムの状態を制御する終了状態のないループのことです。
ここでは、制御ループの一例として、部屋の中にあるサーモスタットを挙げます。
あなたが温度を設定すると、それはサーモスタットに 目的の状態(desired state) を伝えることになります。実際の部屋の温度は 現在の状態 です。サーモスタットは、装置をオンまたはオフにすることによって、現在の状態を目的の状態に近づけるように動作します。
Kubernetesにおいて、コントローラーは
クラスター の状態を監視し、必要に応じて変更を加えたり要求したりする制御ループです。それぞれのコントローラーは現在のクラスターの状態を望ましい状態に近づけるように動作します。
コントローラーパターン
コントローラーは少なくとも1種類のKubernetesのリソースを監視します。これらのオブジェクト には目的の状態を表すspecフィールドがあります。リソースのコントローラーは、現在の状態を目的の状態に近づける責務を持ちます。
コントローラーは自分自身でアクションを実行する場合もありますが、KubernetesではコントローラーがAPIサーバー に意味のある副作用を持つメッセージを送信することが一般的です。以下では、このような例を見ていきます。
APIサーバー経由でコントロールする
Job コントローラーはKubernetesのビルトインのコントローラーの一例です。ビルトインのコントローラーは、クラスターのAPIサーバーとやりとりをして状態を管理します。
Jobは、1つ以上のPod を起動して、タスクを実行した後に停止する、Kubernetesのリソースです。
(1度スケジュール されると、Podオブジェクトはkubeletに対する目的の状態の一部になります。)
Jobコントローラーが新しいタスクを見つけると、その処理が完了するように、クラスター上のどこかで、一連のNode上のkubeletが正しい数のPodを実行することを保証します。ただし、Jobコントローラーは、自分自身でPodやコンテナを実行することはありません。代わりに、APIサーバーに対してPodの作成や削除を依頼します。コントロールプレーン 上の他のコンポーネントが(スケジュールして実行するべき新しいPodが存在するという)新しい情報を基に動作することによって、最終的に目的の処理が完了します。
新しいJobが作成されたとき、目的の状態は、そのJobが完了することです。JobコントローラーはそのJobに対する現在の状態を目的の状態に近づけるようにします。つまり、そのJobが行ってほしい処理を実行するPodを作成し、Jobが完了に近づくようにします。
コントローラーは、コントローラーを設定するオブジェクトも更新します。たとえば、あるJobが完了した場合、Jobコントローラーは、JobオブジェクトにFinishedというマークを付けます。
(これは、部屋が設定温度になったことを示すために、サーモスタットがランプを消灯するのに少し似ています。)
直接的なコントロール
Jobとは対照的に、クラスターの外部に変更を加える必要があるコントローラーもあります。
たとえば、クラスターに十分な数のNode が存在することを保証する制御ループの場合、そのコントローラーは、必要に応じて新しいNodeをセットアップするために、現在のクラスターの外部とやりとりをする必要があります。
外部の状態とやりとりをするコントローラーは、目的の状態をAPIサーバーから取得した後、外部のシステムと直接通信し、現在の状態を目的の状態に近づけます。
(クラスター内のノードを水平にスケールさせるコントローラー が実際に存在します。)
ここで重要な点は、コントローラーが目的の状態を実現するために変更を加えてから、現在の状態をクラスターのAPIサーバーに報告することです。他の制御ループは、その報告されたデータを監視し、独自のアクションを実行できます。
サーモスタットの例では、部屋が非常に寒い場合、別のコントローラーが霜防止ヒーターをオンにすることもあります。Kubernetesクラスターを使用すると、コントロールプレーンは、Kubernetesを拡張して 実装することにより、IPアドレス管理ツールやストレージサービス、クラウドプロバイダーAPI、およびその他のサービスと間接的に連携します。
目的の状態 vs 現在の状態
Kubernetesはシステムに対してクラウドネイティブな見方をするため、常に変化し続けるような状態を扱えるように設計されています。
処理を実行したり、制御ループが故障を自動的に修正したりしているどの時点でも、クラスターは変化中である可能性があります。つまり、クラスターは決して安定した状態にならない可能性があるということです。
コントローラーがクラスターのために実行されていて、有用な変更が行われるのであれば、全体的な状態が安定しているかどうかは問題にはなりません。
設計
設計理念として、Kubernetesは多数のコントローラーを使用しており、各コントローラーはクラスターの状態の特定の側面をそれぞれ管理しています。最もよくあるパターンは、特定の制御ループ(コントローラー)が目的の状態として1種類のリソースを使用し、目的の状態を実現することを管理するために別の種類のリソースを用意するというものです。たとえば、Jobのコントローラーは、Jobオブジェクト(新しい処理を見つけるため)およびPodオブジェクト(Jobを実行し、処理が完了したか確認するため)を監視します。この場合、なにか別のものがJobを作成し、JobコントローラーはPodを作成します。
相互にリンクされた単一のモノリシックな制御ループよりは、複数の単純なコントローラーが存在する方が役に立ちます。コントローラーは故障することがあるため、Kubernetesは故障を許容するように設計されています。
備考: 同じ種類のオブジェクトを作成または更新するコントローラーが、複数存在する場合があります。実際には、Kubernetesコントローラーは、自分が制御するリソースに関連するリソースにのみ注意を払うように作られています。
たとえば、DeploymentとJobがありますが、これらは両方ともPodを作成するものです。しかし、JobコントローラーはDeploymentが作成したPodを削除することはありません。各コントローラーが2つのPodを区別できる情報(ラベル )が存在するためです。
コントローラーを実行する方法
Kubernetesには、kube-controller-manager 内部で動作する一組のビルトインのコントローラーが用意されています。これらビルトインのコントローラーは、コアとなる重要な振る舞いを提供します。
DeploymentコントローラーとJobコントローラーは、Kubernetes自体の一部として同梱されているコントローラーの例です(それゆえ「ビルトイン」のコントローラーと呼ばれます)。Kubernetesは回復性のあるコントロールプレーンを実行できるようにしているため、ビルトインのコントローラーの一部が故障しても、コントロールプレーンの別の部分が作業を引き継いでくれます。
Kubernetesを拡張するためにコントロールプレーンの外で動作するコントローラーもあります。もし望むなら、新しいコントローラーを自分で書くこともできます。自作のコントローラーをPodセットとして動作させたり、Kubernetesの外部で動作させることもできます。どのような動作方法が最も適しているかは、そのコントローラーがどのようなことを行うのかに依存します。
次の項目
2.5 - クラウドコントローラーマネージャー
FEATURE STATE: Kubernetes v1.11 [beta]
クラウドインフラストラクチャー技術により、パブリック、プライベート、ハイブリッドクラウド上でKubernetesを動かすことができます。Kubernetesは、コンポーネント間の密なつながりが不要な自動化されたAPI駆動インフラストラクチャーを信条としています。
cloud-controller-managerは クラウド特有の制御ロジックを組み込むKubernetesのcontrol plane コンポーネントです。クラウドコントロールマネージャーは、クラスターをクラウドプロバイダーAPIをリンクし、クラスターのみで相互作用するコンポーネントからクラウドプラットフォームで相互作用するコンポーネントを分離します。
Kubernetesと下のクラウドインフラストラクチャー間の相互運用ロジックを分離することで、cloud-controller-managerコンポーネントはクラウドプロバイダを主なKubernetesプロジェクトと比較し異なるペースで機能をリリース可能にします。
cloud-controller-managerは、プラグイン機構を用い、異なるクラウドプロバイダーに対してそれぞれのプラットフォームとKubernetesの結合を可能にする構成になっています。
設計
クラウドコントローラーマネージャーは、複製されたプロセスの集合としてコントロールプレーンで実行されます。(通常、Pod内のコンテナとなります)各cloud-controller-managerは、シングルプロセスで複数のcontrollers を実装します。
備考: コントロールプレーンの一部ではなく、Kubernetesの
addon としてクラウドコントローラーマネージャーを実行することもできます。
クラウドコントローラーマネージャーの機能
クラウドコントローラーマネージャーのコントローラーは以下を含んでいます。
ノードコントローラー
ノードコントローラーは、クラウドインフラストラクチャーで新しいサーバーが作成された際に、Node オブジェクトを作成する責務を持ちます。ノードコントローラーは、クラウドプロバイダーのテナント内で動作しているホストの情報を取得します。ノードコントローラーは下記に示す機能を実行します:
Nodeオブジェクトを、コントローラーがクラウドプロバイダーAPIを通じて見つけた各サーバーで初期化する
Nodeオブジェクトに、ノードがデプロイされているリージョンや利用可能なリソース(CPU、メモリなど)のようなクラウド特有な情報を注釈付けやラベル付けをする
ノードのホスト名とネットワークアドレスを取得する
ノードの正常性を検証する。ノードが応答しなくなった場合、クラウドプロバイダーのAPIを利用しサーバーがdeactivated / deleted / terminatedであるかを確認する。クラウドからノードが削除されていた場合、KubernetesクラスターからNodeオブジェクトを削除する
いくつかのクラウドプロバイダーは、これをノードコントローラーと個別のノードライフサイクルコントローラーに分けて実装しています。
ルートコントローラー
ルートコントローラーは、クラスター内の異なるノード上で稼働しているコンテナが相互に通信できるように、クラウド内のルートを適切に設定する責務を持ちます。
クラウドプロバイダーによっては、ルートコントローラーはPodネットワークのIPアドレスのブロックを割り当てることもあります。
サービスコントローラー
Services は、マネージドロードバランサー、IPアドレスネットワークパケットフィルタや対象のヘルスチェックのようなクラウドインフラストラクチャーコンポーネントのインテグレーションを行います。サービスコントローラーは、ロードバランサーや他のインフラストラクチャーコンポーネントを必要とするServiceリソースを宣言する際にそれらのコンポーネントを設定するため、クラウドプロバイダーのAPIと対話します。
認可
このセクションでは、クラウドコントローラーマネージャーが操作を行うために様々なAPIオブジェクトに必要な権限を分類します。
ノードコントローラー
ノードコントローラーはNodeオブジェクトのみに対して働きます。Nodeオブジェクトに対して、readとmodifyの全権限が必要です。
v1/Node:
Get
List
Create
Update
Patch
Watch
Delete
ルートコントローラー
ルートコントローラーは、Nodeオブジェクトの作成を待ち受け、ルートを適切に設定します。Nodeオブジェクトについて、get権限が必要です。
v1/Node:
サービスコントローラー
サービスコントローラーは、Serviceオブジェクトの作成、更新、削除イベントを待ち受け、その後、サービスのEndpointを適切に設定します。
サービスにアクセスするため、list、watchの権限が必要です。サービスを更新するため、patch、updateの権限が必要です。
サービスのEndpointリソースを設定するため、create、list、get、watchそしてupdateの権限が必要です。
v1/Service:
List
Get
Watch
Patch
Update
その他
クラウドコントローラーマネージャーのコア機能の実装は、Eventオブジェクトのcreate権限と、セキュアな処理を保証するため、ServiceAccountのcreate権限が必要です。
v1/Event:
v1/ServiceAccount:
クラウドコントローラーマネージャーのRBAC ClusterRoleはこのようになります:
apiVersion : rbac.authorization.k8s.io/v1
kind : ClusterRole
metadata :
name : cloud-controller-manager
rules :
apiGroups :
- ""
resources :
- events
verbs :
- create
- patch
- update
apiGroups :
- ""
resources :
- nodes
verbs :
- '*'
apiGroups :
- ""
resources :
- nodes/status
verbs :
- patch
apiGroups :
- ""
resources :
- services
verbs :
- list
- patch
- update
- watch
apiGroups :
- ""
resources :
- serviceaccounts
verbs :
- create
apiGroups :
- ""
resources :
- persistentvolumes
verbs :
- get
- list
- update
- watch
apiGroups :
- ""
resources :
- endpoints
verbs :
- create
- get
- list
- watch
- update
次の項目
Cloud Controller Manager Administration
はクラウドコントラーマネージャーの実行と管理を説明しています。
どのようにあなた自身のクラウドコントローラーマネージャーが実装されるのか、もしくは既存プロジェクトの拡張について知りたいですか?
クラウドコントローラーマネージャーは、いかなるクラウドからもプラグインとしての実装を許可するためにGoインターフェースを使います。具体的には、kubernetes/cloud-provider の cloud.goCloudProviderを使います。
本ドキュメントでハイライトした共有コントローラー(Node、Route、Service)の実装と共有クラウドプロバイダーインターフェースに沿ったいくつかの足場は、Kubernetesコアの一部です。クラウドプロバイダに特化した実装は、Kubernetesのコアの外部として、またCloudProviderインターフェースを実装します。
プラグイン開発ついての詳細な情報は、Developing Cloud Controller Manager を見てください。
2.6 - cgroup v2について
Linuxでは、コントロールグループ がプロセスに割り当てられるリソースを制限しています。
コンテナ化されたワークロードの、CPU/メモリーの要求と制限を含むPodとコンテナのリソース管理 を強制するために、
kubelet と基盤となるコンテナランタイムはcgroupをインターフェースとして接続する必要があります。
Linuxではcgroup v1とcgroup v2の2つのバージョンのcgroupがあります。
cgroup v2は新世代のcgroup APIです。
cgroup v2とは何か?
FEATURE STATE: Kubernetes v1.25 [stable]
cgroup v2はLinuxのcgroup APIの次のバージョンです。
cgroup v2はリソース管理機能を強化した統合制御システムを提供しています。
以下のように、cgroup v2はcgroup v1からいくつかの点を改善しています。
統合された単一階層設計のAPI
より安全なコンテナへのサブツリーの移譲
Pressure Stall Information などの新機能強化されたリソース割り当て管理と複数リソース間の隔離
異なるタイプのメモリー割り当ての統一(ネットワークメモリー、カーネルメモリーなど)
ページキャッシュの書き戻しといった、非即時のリソース変更
Kubernetesのいくつかの機能では、強化されたリソース管理と隔離のためにcgroup v2のみを使用しています。
例えば、MemoryQoS 機能はメモリーQoSを改善し、cgroup v2の基本的な機能に依存しています。
cgroup v2を使う
cgroup v2を使うおすすめの方法は、デフォルトでcgroup v2が有効で使うことができるLinuxディストリビューションを使うことです。
あなたのディストリビューションがcgroup v2を使っているかどうかを確認するためには、Linux Nodeのcgroupバージョンを特定する を参照してください。
必要要件
cgroup v2を使うには以下のような必要要件があります。
OSディストリビューションでcgroup v2が有効であること
Linuxカーネルバージョンが5.8以上であること
コンテナランタイムがcgroup v2をサポートしていること。例えば、
kubeletとコンテナランタイムがsystemd cgroupドライバー を使うように設定されていること
Linuxディストリビューションのcgroup v2サポート
cgroup v2を使っているLinuxディストリビューションの一覧はcgroup v2ドキュメント をご覧ください。
Container-Optimized OS (M97以降)
Ubuntu (21.10以降, 22.04以降推奨)
Debian GNU/Linux (Debian 11 bullseye以降)
Fedora (31以降)
Arch Linux (April 2021以降)
RHEL and RHEL-like distributions (9以降)
あなたのディストリビューションがcgroup v2を使っているかどうかを確認するためには、あなたのディストリビューションのドキュメントを参照するか、Linux Nodeのcgroupバージョンを特定する の説明に従ってください。
カーネルのcmdlineの起動時引数を修正することで、手動であなたのLinuxディストリビューションのcgroup v2を有効にすることもできます。
あなたのディストリビューションがGRUBを使っている場合は、
/etc/default/grubの中のGRUB_CMDLINE_LINUXにsystemd.unified_cgroup_hierarchy=1を追加し、sudo update-grubを実行してください。
ただし、おすすめの方法はデフォルトですでにcgroup v2が有効になっているディストリビューションを使うことです。
cgroup v2への移行
cgroup v2に移行するには、必要要件 を満たすことを確認し、
cgroup v2がデフォルトで有効であるカーネルバージョンにアップグレードします。
kubeletはOSがcgroup v2で動作していることを自動的に検出し、それに応じて処理を行うため、追加設定は必要ありません。
ノード上やコンテナ内からユーザーが直接cgroupファイルシステムにアクセスしない限り、cgroup v2に切り替えたときのユーザー体験に目立った違いはないはずです。
cgroup v2はcgroup v1とは違うAPIを利用しているため、cgroupファイルシステムに直接アクセスしているアプリケーションはcgroup v2をサポートしている新しいバージョンに更新する必要があります。例えば、
サードパーティーの監視またはセキュリティエージェントはcgroupファイルシステムに依存していることがあります。
エージェントをcgroup v2をサポートしているバージョンに更新してください。
Podやコンテナを監視するためにcAdvisor をスタンドアローンのDaemonSetとして起動している場合、v0.43.0以上に更新してください。
Javaアプリケーションをデプロイする場合は、完全にcgroup v2をサポートしているバージョンを利用してください:
uber-go/automaxprocs パッケージを利用している場合は、利用するバージョンがv1.5.1以上であることを確認してください。
Linux Nodeのcgroupバージョンを特定する
cgroupバージョンは利用されているLinuxディストリビューションと、OSで設定されているデフォルトのcgroupバージョンに依存します。
あなたのディストリビューションがどちらのcgroupバージョンを利用しているのかを確認するには、stat -fc %T /sys/fs/cgroup/コマンドをノード上で実行してください。
stat -fc %T /sys/fs/cgroup/
cgroup v2では、cgroup2fsと出力されます。
cgroup v1では、tmpfsと出力されます。
次の項目
2.7 - コンテナランタイムインターフェース(CRI)
CRIは、クラスターコンポーネントを再コンパイルすることなく、kubeletがさまざまなコンテナランタイムを使用できるようにするプラグインインターフェースです。
kubelet がPod とそのコンテナを起動できるように、クラスター内の各ノードで動作するcontainer runtime が必要です。
kubeletとContainerRuntime間の通信のメインプロトコルです。
Kubernetes Container Runtime Interface(CRI)は、クラスターコンポーネント kubelet とcontainer runtime 間の通信用のメインgRPC プロトコルを定義します。
API
FEATURE STATE: Kubernetes v1.23 [stable]
kubeletは、gRPCを介してコンテナランタイムに接続するときにクライアントとして機能します。ランタイムおよびイメージサービスエンドポイントは、コンテナランタイムで使用可能である必要があります。コンテナランタイムは、--image-service-endpointコマンドラインフラグ を使用して、kubelet内で個別に設定できます。
Kubernetes v1.30の場合、kubeletはCRI v1の使用を優先します。
コンテナランタイムがCRIのv1をサポートしていない場合、kubeletはサポートされている古いバージョンのネゴシエーションを試みます。
kubelet v1.30はCRI v1alpha2をネゴシエートすることもできますが、このバージョンは非推奨と見なされます。
kubeletがサポートされているCRIバージョンをネゴシエートできない場合、kubeletはあきらめて、ノードとして登録されません。
アップグレード
Kubernetesをアップグレードする場合、kubeletはコンポーネントの再起動時に最新のCRIバージョンを自動的に選択しようとします。
それが失敗した場合、フォールバックは上記のように行われます。
コンテナランタイムがアップグレードされたためにgRPCリダイヤルが必要な場合は、コンテナランタイムも最初に選択されたバージョンをサポートする必要があります。
そうでない場合、リダイヤルは失敗することが予想されます。これには、kubeletの再起動が必要です。
次の項目
2.8 - ガベージコレクション
ガベージコレクションは、Kubernetesがクラスターリソースをクリーンアップするために使用するさまざまなメカニズムの総称です。これにより、次のようなリソースのクリーンアップが可能になります:
オーナーの依存関係
Kubernetesの多くのオブジェクトは、owner reference
Ownershipは、一部のリソースでも使用されるラベルおよびセレクター メカニズムとは異なります。
たとえば、EndpointSliceオブジェクトを作成するService を考えます。
Serviceはラベル を使用して、コントロールプレーンがServiceに使用されているEndpointSliceオブジェクトを判別できるようにします。
ラベルに加えて、Serviceに代わって管理される各EndpointSliceには、owner referenceがあります。
owner referenceは、Kubernetesのさまざまな部分が制御していないオブジェクトへの干渉を回避するのに役立ちます。
備考: namespace間のowner referenceは、設計上許可されていません。
namespaceの依存関係は、クラスタースコープまたはnamespaceのオーナーを指定できます。
namespaceのオーナーは、依存関係と同じnamespaceに存在する必要があります 。
そうでない場合、owner referenceは不在として扱われ、すべてのオーナーが不在であることが確認されると、依存関係は削除される可能性があります。
クラスタースコープの依存関係は、クラスタースコープのオーナーのみを指定できます。
v1.20以降では、クラスタースコープの依存関係がnamespaceを持つkindをオーナーとして指定している場合、それは解決できないowner referenceを持つものとして扱われ、ガベージコレクションを行うことはできません。
V1.20以降では、ガベージコレクタは無効な名前空間間のownerReference、またはnamespaceのkindを参照するownerReferenceをもつクラスター・スコープの依存関係を検出した場合、無効な依存関係のOwnerRefInvalidNamespaceとinvolvedObjectを理由とする警告イベントが報告されます。
以下のコマンドを実行すると、そのようなイベントを確認できます。
kubectl get events -A --field-selector=reason=OwnerRefInvalidNamespace
カスケード削除
Kubernetesは、ReplicaSetを削除したときに残されたPodなど、owner referenceがなくなったオブジェクトをチェックして削除します。
オブジェクトを削除する場合、カスケード削除と呼ばれるプロセスで、Kubernetesがオブジェクトの依存関係を自動的に削除するかどうかを制御できます。
カスケード削除には、次の2つのタイプがあります。
フォアグラウンドカスケード削除
バックグラウンドカスケード削除
また、Kubernetes finalizer を使用して、ガベージコレクションがowner referenceを持つリソースを削除する方法とタイミングを制御することもできます。
フォアグラウンドカスケード削除
フォアグラウンドカスケード削除では、削除するオーナーオブジェクトは最初に削除進行中 の状態になります。
この状態では、オーナーオブジェクトに次のことが起こります。
Kubernetes APIサーバーは、オブジェクトのmetadata.deletionTimestampフィールドを、オブジェクトに削除のマークが付けられた時刻に設定します。
Kubernetes APIサーバーは、metadata.finalizersフィールドをforegroundDeletionに設定します。
オブジェクトは、削除プロセスが完了するまで、KubernetesAPIを介して表示されたままになります。
オーナーオブジェクトが削除進行中の状態に入ると、コントローラーは依存関係を削除します。
すべての依存関係オブジェクトを削除した後、コントローラーはオーナーオブジェクトを削除します。
この時点で、オブジェクトはKubernetesAPIに表示されなくなります。
フォアグラウンドカスケード削除中に、オーナーの削除をブロックする依存関係は、ownerReference.blockOwnerDeletion=trueフィールドを持つ依存関係のみです。
詳細については、フォアグラウンドカスケード削除の使用 を参照してください。
バックグラウンドカスケード削除
バックグラウンドカスケード削除では、Kubernetes APIサーバーがオーナーオブジェクトをすぐに削除し、コントローラーがバックグラウンドで依存オブジェクトをクリーンアップします。
デフォルトでは、フォアグラウンド削除を手動で使用するか、依存オブジェクトを孤立させることを選択しない限り、Kubernetesはバックグラウンドカスケード削除を使用します。
詳細については、バックグラウンドカスケード削除の使用 を参照してください。
孤立した依存関係
Kubernetesがオーナーオブジェクトを削除すると、残された依存関係はorphan オブジェクトと呼ばれます。
デフォルトでは、Kubernetesは依存関係オブジェクトを削除します。この動作をオーバーライドする方法については、オーナーオブジェクトの削除と従属オブジェクトの孤立 を参照してください。
未使用のコンテナとイメージのガベージコレクション
kubelet は未使用のイメージに対して5分ごとに、未使用のコンテナに対して1分ごとにガベージコレクションを実行します。
外部のガベージコレクションツールは、kubeletの動作を壊し、存在するはずのコンテナを削除する可能性があるため、使用しないでください。
未使用のコンテナとイメージのガベージコレクションのオプションを設定するには、設定ファイル を使用してkubeletを調整し、KubeletConfiguration
コンテナイメージのライフサイクル
Kubernetesは、kubeletの一部であるイメージマネージャー を通じて、cadvisor の協力を得て、すべてのイメージのライフサイクルを管理します。kubeletは、ガベージコレクションを決定する際に、次のディスク使用制限を考慮します。
HighThresholdPercentLowThresholdPercent
設定されたHighThresholdPercent値を超えるディスク使用量はガベージコレクションをトリガーします。
ガベージコレクションは、最後に使用された時間に基づいて、最も古いものから順にイメージを削除します。
kubeletは、ディスク使用量がLowThresholdPercent値に達するまでイメージを削除します。
コンテナのガベージコレクション
kubeletは、次の変数に基づいて未使用のコンテナをガベージコレクションします。
MinAge: kubeletがガベージコレクションできるコンテナの最低期間。0を設定すると無効化されます。MaxPerPodContainer: 各Podが持つことができるデッドコンテナの最大数。0未満に設定すると無効化されます。MaxContainers: クラスターが持つことができるデッドコンテナの最大数。0未満に設定すると無効化されます。
これらの変数に加えて、kubeletは、通常、最も古いものから順に、定義されていない削除されたコンテナをガベージコレクションします。
MaxPerPodContainerとMaxContainersは、Podごとのコンテナの最大数(MaxPerPodContainer)を保持すると、グローバルなデッドコンテナの許容合計(MaxContainers)を超える状況で、互いに競合する可能性があります。
この状況では、kubeletはMaxPerPodContainerを調整して競合に対処します。最悪のシナリオは、MaxPerPodContainerを1にダウングレードし、最も古いコンテナを削除することです。
さらに、削除されたPodが所有するコンテナは、MinAgeより古くなると削除されます。
備考: kubeletがガベージコレクションするのは、自分が管理するコンテナのみです。
ガベージコレクションの設定
これらのリソースを管理するコントローラーに固有のオプションを設定することにより、リソースのガベージコレクションを調整できます。次のページは、ガベージコレクションを設定する方法を示しています。
次の項目
3 - コンテナ
アプリケーションとランタイムの依存関係を一緒にパッケージ化するための技術
実行するそれぞれのコンテナは繰り返し使用可能です。依存関係を含めて標準化されており、どこで実行しても同じ動作が得られることを意味しています。
コンテナは基盤となるホストインフラからアプリケーションを切り離します。これにより、さまざまなクラウドやOS環境下でのデプロイが容易になります。
コンテナイメージ
コンテナイメージ はすぐに実行可能なソフトウェアパッケージで、アプリケーションの実行に必要なものをすべて含んています。コードと必要なランタイム、アプリケーションとシステムのライブラリ、そして必須な設定項目のデフォルト値を含みます。
設計上、コンテナは不変で、既に実行中のコンテナのコードを変更することはできません。コンテナ化されたアプリケーションがあり変更したい場合は、変更を含んだ新しいイメージをビルドし、コンテナを再作成して、更新されたイメージから起動する必要があります。
コンテナランタイム
コンテナランタイムは、コンテナの実行を担当するソフトウェアです。
Kubernetesは次の複数のコンテナランタイムをサポートします。
Docker 、containerd 、CRI-O 、
および全ての
Kubernetes CRI (Container Runtime Interface)
実装です。
次の項目
3.1 - イメージ
コンテナイメージはアプリケーションと依存関係のあるすべてソフトウェアをカプセル化したバイナリデータを表します。コンテナイメージはスタンドアロンで実行可能なソフトウェアをひとつにまとめ、ランタイム環境に関する想定を明確に定義しています。
アプリケーションのコンテナイメージを作成し、一般的にはPod で参照する前にレジストリへPushします。
このページではコンテナイメージの概要を説明します。
イメージの名称
コンテナイメージは、pause、example/mycontainer、またはkube-apiserverのような名前が通常つけられます。
イメージにはレジストリのホスト名も含めることができ(例:fictional.registry.example/imagename)、さらにポート番号も含めることが可能です(例:fictional.registry.example:10443/imagename)。
レジストリのホスト名を指定しない場合は、KubernetesはDockerパブリックレジストリを意味していると見なします。
イメージ名の後に、タグ を追加することができます(dockerやpodmanのようなコマンドを利用した場合と同様)。
タグによって同じイメージの異なるバージョンを識別できます。
イメージタグは大文字と小文字、数値、アンダースコア(_)、ピリオド(.)とマイナス(-)で構成されます。
イメージタグでは区切り記号(_、-、.)を指定できる追加ルールがあります。
タグを指定しない場合は、Kubernetesはlatestタグを指定したと見なします。
イメージの更新
Deployment 、StatefulSet 、Pod、またはPodテンプレートを含むその他のオブジェクトを最初に作成するとき、デフォルトでは、Pod内のすべてのコンテナのPullポリシーは、明示的に指定されていない場合、IfNotPresentに設定されます。
イメージがすでに存在する場合、このポリシーはkubelet にイメージのPullをスキップさせます。
イメージPullポリシー
コンテナのimagePullPolicyとイメージのタグは、kubelet が指定されたイメージをPull(ダウンロード)しようとする時に影響します。
以下は、imagePullPolicyに設定できる値とその効果の一覧です。
IfNotPresentイメージがローカルにまだ存在しない場合のみ、イメージがPullされます。
Alwayskubeletがコンテナを起動するときは常にコンテナイメージレジストリに照会して、イメージ名をイメージダイジェスト に解決します。
ローカルにキャッシュされた同一ダイジェストのコンテナイメージがあった場合、kubeletはキャッシュされたイメージを使用します。
そうでない場合、kubeletは解決されたダイジェストのイメージをPullし、そのイメージを使ってコンテナを起動します。
Neverkubeletは、イメージを取得しようとしません。ローカルにイメージがすでに存在する場合、kubeletはコンテナを起動しようとします。それ以外の場合、起動に失敗します。
詳細は、事前にPullしたイメージ を参照してください。
レジストリに確実にアクセスできるのであれば、基盤となるイメージプロバイダーのキャッシュセマンティクスによりimagePullPolicy: Alwaysでも効率的です。
コンテナランタイムは、イメージレイヤーが既にノード上に存在することを認識できるので、再度ダウンロードする必要がありません。
備考: 本番環境でコンテナをデプロイする場合は、:latestタグの使用を避けるべきです。
実行中のイメージのバージョンを追跡するのが難しく、正しくロールバックすることがより困難になるためです。
かわりに、v1.42.0のような特定できるタグを指定してください。
Podがいつも同じバージョンのコンテナイメージを使用するために、イメージのダイジェストを指定することができます。<image-name>:<tag>を<image-name>@<digest>に置き換えてください(例えば、image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2)。
イメージタグを使用する場合、イメージレジストリがそのイメージのタグが表すコードを変更すると、新旧のコードを実行するPodが混在することになるかもしれません。
イメージダイジェストは特定のバージョンのイメージを一意に識別するため、Kubernetesは特定のイメージ名とダイジェストが指定されたコンテナを起動するたびに同じコードを実行します。
イメージをダイジェストで指定することは、レジストリの変更でそのようなバージョンの混在を起こさないように、実行するコードを固定します。
Pod(およびPodテンプレート)を作成する時に、実行中のワークロードがタグではなくイメージダイジェストに基づき定義されるように変化させるサードパーティーのアドミッションコントローラー があります。
レジストリでどのようなタグの変更があっても、すべてのワークロードが必ず同じコードを実行するようにしたい場合に役立ちます。
デフォルトのイメージPullポリシー
新しいPodがAPIサーバに送信されると、クラスターは特定の条件が満たされたときにimagePullPolicyフィールドを設定します。
imagePullPolicyフィールドを省略し、コンテナイメージのタグに:latestを指定した場合、imagePullPolicyには自動的にAlwaysが設定されるimagePullPolicyフィールドを省略し、コンテナイメージのタグを指定しなかった場合、imagePullPolicyには自動的にAlwaysが設定されるimagePullPolicyフィールドを省略し、コンテナイメージのタグに:latest以外を指定した場合、imagePullPolicyには自動的にIfNotPresentが設定される
備考: コンテナのimagePullPolicyの値は、そのオブジェクトが最初に 作成 されたときに常に設定され、イメージのタグが後で変更された場合でも更新されません。
例えば、タグが:latest でない イメージを使ってDeploymentを生成した場合、後でDeploymentのイメージを:latestタグに変更しても、imagePullPolicyはAlwaysに更新されません。オブジェクトのPullポリシーは、初期作成後に手動で変更する必要があります。
必要なイメージをPullする
常に強制的にPullしたい場合は、以下のいずれかを行ってください。
コンテナのimagePullPolicyにAlwaysを設定する。
imagePullPolicyを省略し、使用するイメージに:latestタグ使用する。Pod生成時に、KubernetesがポリシーにAlwaysを設定する。imagePullPolicyと使用するイメージのタグを省略する。Pod生成時に、KubernetesがポリシーにAlwaysを設定する。AlwaysPullImages アドミッションコントローラーを有効にする。
ImagePullBackOff
kubeletがコンテナランタイムを使ってPodのコンテナの生成を開始するとき、ImagePullBackOffのためにコンテナがWaiting 状態になる可能性があります。
ImagePullBackOffステータスは、KubernetesがコンテナイメージをPullできないために、コンテナを開始できないことを意味します(イメージ名が無効である、imagePullSecretなしでプライベートレジストリからPullしたなどの理由のため)。BackOffは、バックオフの遅延を増加させながらKubernetesがイメージをPullしようとし続けることを示します。
Kubernetesは、組み込まれた制限である300秒(5分)に達するまで、試行するごとに遅延を増加させます。
イメージインデックスを使ったマルチアーキテクチャイメージ
コンテナレジストリはバイナリイメージの提供だけでなく、コンテナイメージインデックス も提供する事ができます。イメージインデックスはコンテナのアーキテクチャ固有バージョンに関する複数のイメージマニフェスト を指すことができます。イメージインデックスの目的はイメージの名前(例:pause、example/mycontainer、kube-apiserver)をもたせ、様々なシステムが使用しているマシンアーキテクチャにあう適切なバイナリイメージを取得できることです。
Kubernetes自身は、通常コンテナイメージに-$(ARCH)のサフィックスを持つ名前をつけます。下位互換の為にサフィックス付きの古い仕様のイメージを生成してください。その目的は、pauseのようなすべてのアーキテクチャのマニフェストを持つイメージと、サフィックスのあるイメージをハードコードしていた可能性のある古い仕様の設定やYAMLファイルと下位互換があるpause-amd64のようなイメージを生成することです。
プライベートレジストリを使用する方法
プライベートレジストリではイメージを読み込む為にキーが必要になる場合があります。
プライベートレジストリへの認証をNodeに設定する
すべてのPodがプライベートレジストリを読み取ることができる
クラスター管理者によるNodeの設定が必要
事前にPullされたイメージ
すべてのPodがNode上にキャッシュされたイメージを利用できる
セットアップするためにはすべてのNodeに対するrootアクセスが必要
PodでImagePullSecretsを指定する
キーを提供したPodのみがプライベートレジストリへアクセスできる
ベンダー固有またはローカルエクステンション
カスタムNode構成を使っている場合、あなた(または、あなたのクラウドプロバイダー)はコンテナレジストリへの認証の仕組みを組み込むことができる
これらのオプションについて、以下で詳しく説明します。
プライベートレジストリへの認証をNodeに設定する
認証情報を設定するための具体的な手順は、使用するコンテナランタイムとレジストリに依存します。最も正確な情報として、ソリューションのドキュメントを参照する必要があります。
プライベートなコンテナイメージレジストリを設定する例として、プライベートレジストリからイメージをPullする タスクを参照してください。その例では、Docker Hubのプライベートレジストリを使用しています。
config.jsonの解釈
config.jsonの解釈は、Dockerのオリジナルの実装とKubernetesの解釈で異なります。
Dockerでは、authsキーはルートURLしか指定できませんが、Kubernetesではプレフィックスのマッチしたパスだけでなく、グロブパターンのURLも指定できます。
以下のようなconfig.jsonが有効であるということです。
{
"auths" : {
"*my-registry.io/images" : {
"auth" : "…"
}
}
}
ルートURL(*my-registry.io)は、以下の構文でマッチングされます:
pattern:
{ term }
term:
'*' セパレーター以外の任意の文字列にマッチする
'?' セパレーター以外の任意の一文字にマッチする
'[' [ '^' ] { character-range } ']'
文字クラス (空であってはならない)
c 文字 c とマッチする (c != '*', '?', '\\', '[')
'\\' c 文字 c とマッチする
character-range:
c 文字 c とマッチする (c != '\\', '-', ']')
'\\' c 文字 c とマッチする
lo '-' hi lo <= c <= hi の文字 c とマッチする
イメージのPull操作では、有効なパターンごとに認証情報をCRIコンテナランタイムに渡すようになりました。例えば、以下のようなコンテナイメージ名は正常にマッチングされます。
my-registry.io/imagesmy-registry.io/images/my-imagemy-registry.io/images/another-imagesub.my-registry.io/images/my-imagea.sub.my-registry.io/images/my-image
kubeletは、見つかったすべての認証情報に対してイメージのPullを順次実行します。これは、次のようにconfig.jsonに複数のエントリーを書くことも可能であることを意味します。
{
"auths" : {
"my-registry.io/images" : {
"auth" : "…"
},
"my-registry.io/images/subpath" : {
"auth" : "…"
}
}
}
コンテナがmy-registry.io/images/subpath/my-imageをPullするイメージとして指定した場合、kubeletが認証ソースの片方からダウンロードに失敗すると、両方の認証ソースからダウンロードを試みます。
事前にPullしたイメージ
備考: Node構成を制御できる場合、この方法が適しています。
クラウドプロバイダーがNodeを管理し自動的に設定を置き換える場合は、確実に機能できません。
デフォルトでは、kubeletは指定されたレジストリからそれぞれのイメージをPullしようとします。
また一方では、コンテナのimagePullPolicyプロパティにIfNotPresentやNeverが設定されている場合、ローカルのイメージが使用されます。(それぞれに対して、優先的またはか排他的に)
レジストリ認証の代替として事前にPullしたイメージを利用したい場合、クラスターのすべてのNodeが同じ事前にPullしたイメージを持っていることを確認する必要があります。
特定のイメージをあらかじめロードしておくことは高速化やプライベートレジストリへの認証の代替として利用することができます。
すべてのPodは事前にPullしたイメージへの読み取りアクセス権をもちます。
PodでimagePullSecretsを指定する
備考: この方法がプライベートレジストリのイメージに基づいてコンテナを実行するための推奨の方法です。
KubernetesはPodでのコンテナイメージレジストリキーの指定をサポートしています。
Dockerの設定を利用してSecretを作成する。
レジストリへの認証のためにユーザー名、レジストリのパスワード、クライアントのメールアドレス、およびそのホスト名を知っている必要があります。
適切な大文字の値を置き換えて、次のコマンドを実行します。
kubectl create secret docker-registry <name> --docker-server= DOCKER_REGISTRY_SERVER --docker-username= DOCKER_USER --docker-password= DOCKER_PASSWORD --docker-email= DOCKER_EMAIL
既にDocker認証情報ファイルを持っている場合は、上記のコマンドの代わりに、認証情報ファイルをKubernetes Secrets としてインポートすることができます。
既存のDocker認証情報に基づいてSecretを作成する で、この設定方法を説明します.
これは複数のプライベートコンテナレジストリを使用している場合に特に有効です。kubectl create secret docker-registryはひとつのプライベートレジストリにのみ機能するSecretを作成するからです。
備考: Podは自分自身のNamespace内にあるimage pull secretsのみが参照可能であるため、この作業はNemespace毎に1回行う必要があります。
PodのimagePullSecretsを参照する方法
これで、imagePullSecretsセクションをPod定義へ追加することでSecretを参照するPodを作成できます。
例:
cat <<EOF > pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
EOF
cat <<EOF >> ./kustomization.yaml
resources:
- pod.yaml
EOF
これは、プライベートレジストリを使用する各Podで行う必要があります。
ただし、この項目の設定はServiceAccount リソースの中でimagePullSecretsを指定することで自動化することができます。
詳細の手順は、ImagePullSecretsをService Accountに追加する をクリックしてください。
これを各Nodeの.docker/config.jsonに組み合わせて利用できます。認証情報はマージされます。
ユースケース
プライベートレジストリを設定するためのソリューションはいくつかあります。ここでは、いくつかの一般的なユースケースと推奨される解決方法を示します。
クラスターに独自仕様でない(例えば、オープンソース)イメージだけを実行する。イメージを非公開にする必要がない
パブリックレジストリのパブリックイメージを利用する
設定は必要ない
クラウドプロバイダーによっては、可用性の向上とイメージをPullする時間を短くする為に、自動的にキャッシュやミラーされたパプリックイメージが提供される
社外には非公開の必要があるが、すべてのクラスター利用者には見せてよい独自仕様のイメージをクラスターで実行している
ホストされたプライペートレジストリを使用
プライベートレジストリにアクセスする必要があるノードには、手動設定が必要となる場合がある
または、オープンな読み取りアクセスを許可したファイヤーウォールの背後で内部向けプライベートレジストリを実行する
イメージへのアクセスを制御できるホストされたコンテナイメージレジストリサービスを利用する
Nodeを手動設定するよりもクラスターのオートスケーリングのほうがうまく機能する
また、Node設定変更を自由にできないクラスターではimagePullSecretsを使用する
独自仕様のイメージを含むクラスターで、いくつかは厳格なアクセス制御が必要である
それぞれのテナントが独自のプライベートレジストリを必要とするマルチテナントのクラスターである
AlwaysPullImagesアドミッションコントローラー が有効化を確認する必要がある。さもないと、すべてのテナントの全Podが全部のイメージにアクセスできてしまう可能性がある認証が必要なプライベートレジストリを実行する
それぞれのテナントでレジストリ認証を生成し、Secretへ設定し、各テナントのNamespaceに追加する
テナントは、Secretを各NamespaceのimagePullSecretsへ追加する
複数のレジストリへのアクセスが必要な場合、それぞれのレジストリ毎にひとつのSecretを作成する事ができます。
次の項目
3.2 - コンテナ環境
このページでは、コンテナ環境で利用可能なリソースについて説明します。
コンテナ環境
Kubernetesはコンテナにいくつかの重要なリソースを提供します。
イメージと1つ以上のボリュームの組み合わせのファイルシステム
コンテナ自体に関する情報
クラスター内の他のオブジェクトに関する情報
コンテナ情報
コンテナの ホスト名 は、コンテナが実行されているPodの名前です。
ホスト名はhostnameコマンドまたはlibcのgethostname
Podの名前と名前空間はdownward API を通じて環境変数として利用可能です。
Pod定義からのユーザー定義の環境変数もコンテナで利用できます。
コンテナイメージで静的に指定されている環境変数も同様です。
クラスター情報
コンテナの作成時に実行されていたすべてのサービスのリストは、環境変数として使用できます。
このリストは、新しいコンテナのPodおよびKubernetesコントロールプレーンサービスと同じ名前空間のサービスに制限されます。
bar という名前のコンテナに対応する foo という名前のサービスの場合、以下の変数が定義されています。
FOO_SERVICE_HOST = <サービスが実行されているホスト>
FOO_SERVICE_PORT = <サービスが実行されているポート>
サービスは専用のIPアドレスを持ち、DNSアドオン が有効の場合、DNSを介してコンテナで利用可能です。
次の項目
3.3 - ランタイムクラス(Runtime Class)
FEATURE STATE: Kubernetes v1.20 [stable]
このページではRuntimeClassリソースと、runtimeセクションのメカニズムについて説明します。
RuntimeClassはコンテナランタイムの設定を選択するための機能です。そのコンテナランタイム設定はPodのコンテナを稼働させるために使われます。
RuntimeClassを使う動機
異なるPodに異なるRuntimeClassを設定することで、パフォーマンスとセキュリティのバランスをとることができます。例えば、ワークロードの一部に高レベルの情報セキュリティ保証が必要な場合、ハードウェア仮想化を使用するコンテナランタイムで実行されるようにそれらのPodをスケジュールすることを選択できます。その後、追加のオーバーヘッドを犠牲にして、代替ランタイムをさらに分離することでメリットが得られます。
RuntimeClassを使用して、コンテナランタイムは同じで設定が異なるPodを実行することもできます。
セットアップ
ノード上でCRI実装を設定する。(ランタイムに依存)
対応するRuntimeClassリソースを作成する。
1. ノード上でCRI実装を設定する
RuntimeClassを通じて利用可能な設定はContainer Runtime Interface (CRI)の実装依存となります。
ユーザーの環境のCRI実装の設定方法は、対応するドキュメント(下記 )を参照ください。
備考: RuntimeClassは、クラスター全体で同じ種類のノード設定であることを仮定しています。(これは全てのノードがコンテナランタイムに関して同じ方法で構成されていることを意味します)。
設定が異なるノードをサポートするには、
スケジューリング を参照してください。
RuntimeClassの設定は、RuntimeClassによって参照されるハンドラー名を持ちます。そのハンドラーは有効なDNSラベル名 でなくてはなりません。
2. 対応するRuntimeClassリソースを作成する
ステップ1にて設定する各項目は、関連するハンドラー 名を持ちます。それはどの設定かを指定するものです。各ハンドラーにおいて、対応するRuntimeClassオブジェクトが作成されます。
そのRuntimeClassリソースは現時点で2つの重要なフィールドを持ちます。それはRuntimeClassの名前(metadata.name)とハンドラー(handler)です。そのオブジェクトの定義は下記のようになります。
# RuntimeClassはnode.k8s.ioというAPIグループで定義されます。
apiVersion : node.k8s.io/v1
kind : RuntimeClass
metadata :
# RuntimeClass名
# RuntimeClassはネームスペースなしのリソースです。
name : myclass
# 対応するCRI設定
handler : myconfiguration
RuntimeClassオブジェクトの名前はDNSサブドメイン名 に従う必要があります。
備考: RuntimeClassの書き込み操作(create/update/patch/delete)はクラスター管理者のみに制限されることを推奨します。
これはたいていデフォルトで有効となっています。さらなる詳細に関しては
Authorization
Overview を参照してください。
使用例
RuntimeClassがクラスターに対して設定されると、PodSpecでruntimeClassNameを指定して使用できます。
例えば
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
runtimeClassName : myclass
# ...
これは、kubeletに対してPodを稼働させるためのRuntimeClassを使うように指示します。もし設定されたRuntimeClassが存在しない場合や、CRIが対応するハンドラーを実行できない場合、そのPodはFailedというフェーズ になります。
エラーメッセージに関しては対応するイベント を参照して下さい。
もしruntimeClassNameが指定されていない場合、デフォルトのRuntimeHandlerが使用され、これはRuntimeClassの機能が無効であるときのふるまいと同じものとなります。
CRIの設定
CRIランタイムのセットアップに関するさらなる詳細は、コンテナランタイム を参照してください。
ランタイムハンドラーは、/etc/containerd/config.tomlにあるcontainerdの設定ファイルにより設定されます。
正しいハンドラーは、そのruntimeセクションで設定されます。
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.${HANDLER_NAME}]
詳細はcontainerdの設定に関するドキュメント を参照してください。
ランタイムハンドラーは、/etc/crio/crio.confにあるCRI-Oの設定ファイルにより設定されます。
正しいハンドラーはcrio.runtime
table で設定されます。
[crio.runtime.runtimes.${HANDLER_NAME}]
runtime_path = "${PATH_TO_BINARY}"
詳細はCRI-Oの設定に関するドキュメント を参照してください。
スケジューリング
FEATURE STATE: Kubernetes v1.16 [beta]
RuntimeClassのschedulingフィールドを指定することで、設定されたRuntimeClassをサポートするノードにPodがスケジューリングされるように制限することができます。
schedulingが設定されていない場合、このRuntimeClassはすべてのノードでサポートされていると仮定されます。
特定のRuntimeClassをサポートしているノードへPodが配置されることを保証するために、各ノードはruntimeclass.scheduling.nodeSelectorフィールドによって選択される共通のラベルを持つべきです。
RuntimeClassのnodeSelectorはアドミッション機能によりPodのnodeSelectorに統合され、効率よくノードを選択します。
もし設定が衝突した場合は、Pod作成は拒否されるでしょう。
もしサポートされているノードが他のRuntimeClassのPodが稼働しないようにtaint付与されていた場合、RuntimeClassに対してtolerationsを付与することができます。
nodeSelectorと同様に、tolerationsはPodのtolerationsにアドミッション機能によって統合され、効率よく許容されたノードを選択します。
ノードの選択とtolerationsについての詳細はノード上へのPodのスケジューリング を参照してください。
Podオーバーヘッド
FEATURE STATE: Kubernetes v1.24 [stable]
Podが稼働する時に関連する オーバーヘッド リソースを指定できます。オーバーヘッドを宣言すると、クラスター(スケジューラーを含む)がPodとリソースに関する決定を行うときにオーバーヘッドを考慮することができます。
PodのオーバーヘッドはRuntimeClass内のoverheadフィールドによって定義されます。
このフィールドを使用することで、RuntimeClassを使用して稼働するPodのオーバーヘッドを指定することができ、Kubernetes内部で使用されるオーバーヘッドを確保することができます。
次の項目
3.4 - コンテナライフサイクルフック
このページでは、kubeletにより管理されるコンテナがコンテナライフサイクルフックフレームワークを使用して、管理ライフサイクル中にイベントによって引き起こされたコードを実行する方法について説明します。
概要
Angularなどのコンポーネントライフサイクルフックを持つ多くのプログラミング言語フレームワークと同様に、Kubernetesはコンテナにライフサイクルフックを提供します。
フックにより、コンテナは管理ライフサイクル内のイベントを認識し、対応するライフサイクルフックが実行されたときにハンドラーに実装されたコードを実行できます。
コンテナフック
コンテナに公開されている2つのフックがあります。
PostStart
このフックはコンテナが作成された直後に実行されます。
しかし、フックがコンテナのENTRYPOINTの前に実行されるという保証はありません。
ハンドラーにパラメーターは渡されません。
PreStop
このフックは、APIからの要求、またはliveness/startup probeの失敗、プリエンプション、リソース競合などの管理イベントが原因でコンテナが終了する直前に呼び出されます。コンテナがすでに終了状態または完了状態にある場合にはPreStopフックの呼び出しは失敗し、コンテナを停止するTERMシグナルが送信される前にフックは完了する必要があります。PreStopフックが実行される前にPodの終了猶予期間のカウントダウンが開始されるので、ハンドラーの結果に関わらず、コンテナはPodの終了猶予期間内に最終的に終了します。
ハンドラーにパラメーターは渡されません。
終了動作の詳細な説明は、Termination of Pods にあります。
フックハンドラーの実装
コンテナは、フックのハンドラーを実装して登録することでそのフックにアクセスできます。
コンテナに実装できるフックハンドラーは2種類あります。
Exec - コンテナのcgroupsと名前空間の中で、 pre-stop.shのような特定のコマンドを実行します。
コマンドによって消費されたリソースはコンテナに対してカウントされます。
HTTP - コンテナ上の特定のエンドポイントに対してHTTP要求を実行します。
フックハンドラーの実行
コンテナライフサイクル管理フックが呼び出されると、Kubernetes管理システムはフックアクションにしたがってハンドラーを実行します。
httpGetとtcpSocketはkubeletプロセスによって実行され、execはコンテナの中で実行されます。
フックハンドラーの呼び出しは、コンテナを含むPodのコンテキスト内で同期しています。
これは、PostStartフックの場合、コンテナのENTRYPOINTとフックは非同期に起動することを意味します。
しかし、フックの実行に時間がかかりすぎたりハングしたりすると、コンテナはrunning状態になることができません。
PreStopフックはコンテナを停止するシグナルから非同期で実行されるのではなく、TERMシグナルが送られる前に実行を完了する必要があります。
もしPreStopフックが実行中にハングした場合、PodはTerminating状態になり、
terminationGracePeriodSecondsの時間切れで強制終了されるまで続きます。
この猶予時間は、PreStopフックが実行され正常にコンテナを停止できるまでの合計時間に適用されます。
例えばterminationGracePeriodSecondsが60で、フックの終了に55秒かかり、シグナルを受信した後にコンテナを正常に停止させるのに10秒かかる場合、コンテナは正常に停止する前に終了されてしまいます。terminationGracePeriodSecondsが、これら2つの実行にかかる合計時間(55+10)よりも短いからです。
PostStartまたはPreStopフックが失敗した場合、コンテナは強制終了します。
ユーザーはフックハンドラーをできるだけ軽量にするべきです。
ただし、コンテナを停止する前に状態を保存するなどの場合は、長時間のコマンド実行が必要なケースもあります。
フック配信保証
フックの配信は 少なくとも1回 を意図しています。これはフックがPostStartやPreStopのような任意のイベントに対して複数回呼ばれることがあることを意味します。
これを正しく処理するのはフックの実装次第です。
通常、1回の配信のみが行われます。
たとえば、HTTPフックレシーバーがダウンしていてトラフィックを受け取れない場合、再送信は試みられません。
ただし、まれに二重配信が発生することがあります。
たとえば、フックの送信中にkubeletが再起動した場合、kubeletが起動した後にフックが再送信される可能性があります。
フックハンドラーのデバッグ
フックハンドラーのログは、Podのイベントには表示されません。
ハンドラーが何らかの理由で失敗した場合は、イベントをブロードキャストします。
PostStartの場合、これはFailedPostStartHookイベントで、PreStopの場合、これはFailedPreStopHookイベントです。
失敗のFailedPreStopHookイベントを自分自身で生成する場合には、lifecycle-events.yaml ファイルに対してpostStartのコマンドを"badcommand"に変更し、適用してください。
kubectl describe pod lifecycle-demoを実行した結果のイベントの出力例を以下に示します。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7s default-scheduler Successfully assigned default/lifecycle-demo to ip-XXX-XXX-XX-XX.us-east-2...
Normal Pulled 6s kubelet Successfully pulled image "nginx" in 229.604315ms
Normal Pulling 4s (x2 over 6s) kubelet Pulling image "nginx"
Normal Created 4s (x2 over 5s) kubelet Created container lifecycle-demo-container
Normal Started 4s (x2 over 5s) kubelet Started container lifecycle-demo-container
Warning FailedPostStartHook 4s (x2 over 5s) kubelet Exec lifecycle hook ([badcommand]) for Container "lifecycle-demo-container" in Pod "lifecycle-demo_default(30229739-9651-4e5a-9a32-a8f1688862db)" failed - error: command 'badcommand' exited with 126: , message: "OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: \"badcommand\": executable file not found in $PATH: unknown\r\n"
Normal Killing 4s (x2 over 5s) kubelet FailedPostStartHook
Normal Pulled 4s kubelet Successfully pulled image "nginx" in 215.66395ms
Warning BackOff 2s (x2 over 3s) kubelet Back-off restarting failed container
次の項目
4 - ワークロード
Kubernetesにおけるデプロイ可能な最小のオブジェクトであるPodと、高レベルな抽象化がPodの実行を助けることを理解します。
ワークロードとは、Kubernetes上で実行中のアプリケーションです。
ワークロードが1つのコンポーネントからなる場合でも、複数のコンポーネントが協調して動作する場合でも、KubernetesではそれらはPod の集合として実行されます。Kubernetesでは、Podはクラスター上で実行中のコンテナ の集合として表されます。
Podには定義されたライフサイクルがあります。たとえば、一度Podがクラスター上で実行中になると、そのPodが実行中のノード 上で深刻な障害が起こったとき、そのノード上のすべてのPodは停止してしまうことになります。Kubernetesではそのようなレベルの障害を最終的なものとして扱うため、たとえノードが後で復元したとしても、ユーザーは新しいPodを作成し直す必要があります。
しかし、生活をかなり楽にするためには、それぞれのPodを直接管理する必要はありません。ワークロードリソース を利用すれば、あなたの代わりにPodの集合の管理を行ってもらえます。これらのリソースはあなたが指定した状態に一致するようにコントローラー を設定し、正しい種類のPodが正しい数だけ実行中になることを保証してくれます。
ワークロードリソースには、次のような種類があります。
多少関連のある2種類の補助的な概念もあります。
次の項目
各リソースについて読む以外にも、以下のページでそれぞれのワークロードに関連する特定のタスクについて学ぶことができます。
アプリケーションが実行できるようになったら、インターネット上で公開したくなるかもしれません。その場合には、Service として公開したり、ウェブアプリケーションだけの場合、Ingress を使用することができます。
コードを設定から分離するKubernetesのしくみについて学ぶには、設定 を読んでください。
4.1 - Pod
Pod は、Kubernetes内で作成・管理できるコンピューティングの最小のデプロイ可能なユニットです。
Pod (Podという名前は、たとえばクジラの群れ(pod of whales)やえんどう豆のさや(pea pod)などの表現と同じような意味です)は、1つまたは複数のコンテナ のグループであり、ストレージやネットワークの共有リソースを持ち、コンテナの実行方法に関する仕様を持っています。同じPodに含まれるリソースは、常に同じ場所で同時にスケジューリングされ、共有されたコンテキストの中で実行されます。Podはアプリケーションに特化した「論理的なホスト」をモデル化します。つまり、1つのPod内には、1つまたは複数の比較的密に結合されたアプリケーションコンテナが含まれます。クラウド外の文脈で説明すると、アプリケーションが同じ物理ホストや同じバーチャルマシンで実行されることが、クラウドアプリケーションの場合には同じ論理ホスト上で実行されることに相当します。
アプリケーションコンテナと同様に、Podでも、Podのスタートアップ時に実行されるinitコンテナ を含めることができます。また、クラスターで利用できる場合には、エフェメラルコンテナ を注入してデバッグすることもできます。
Podとは何か?
備考: KubernetesはDockerだけでなく複数の
コンテナランタイム をサポートしていますが、
Docker が最も一般的に知られたランタイムであるため、Docker由来の用語を使ってPodを説明するのが理解の助けとなります。
Podの共有コンテキストは、Dockerコンテナを隔離するのに使われているのと同じ、Linuxのnamespaces、cgroups、場合によっては他の隔離技術の集合を用いて作られます。Podのコンテキスト内では、各アプリケーションが追加の準隔離技術を適用することもあります。
Dockerの概念を使って説明すると、Podは共有の名前空間と共有ファイルシステムのボリュームを持つDockerコンテナのグループに似ています。
Podを使用する
以下は、nginx:1.14.2イメージが実行されるコンテナからなるPodの例を記載しています。
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
上記のようなPodを作成するには、以下のコマンドを実行します:
kubectl apply -f https://k8s.io/examples/pods/simple-pod.yaml
Podは通常、直接作成されず、ワークロードリソースで作成されます。ワークロードリソースでPodを作成する方法の詳細については、Podを利用する を参照してください。
Podを管理するためのワークロードリソース
通常、たとえ単一のコンテナしか持たないシングルトンのPodだとしても、自分でPodを直接作成する必要はありません。その代わりに、Deployment やJob などのワークロードリソースを使用してPodを作成します。もしPodが状態を保持する必要がある場合は、StatefulSet リソースを使用することを検討してください。
Kubernetesクラスター内のPodは、主に次の2種類の方法で使われます。
単一のコンテナを稼働させるPod 。「1Pod1コンテナ」構成のモデルは、Kubernetesでは最も一般的なユースケースです。このケースでは、ユーザーはPodを単一のコンテナのラッパーとして考えることができます。Kubernetesはコンテナを直接管理するのではなく、Podを管理します。
協調して稼働させる必要がある複数のコンテナを稼働させるPod 。単一のPodは、密に結合してリソースを共有する必要があるような、同じ場所で稼働する複数のコンテナからなるアプリケーションをカプセル化することもできます。これらの同じ場所で稼働するコンテナ群は、単一のまとまりのあるサービスのユニットを構成します。たとえば、1つのコンテナが共有ボリュームからファイルをパブリックに配信し、別のサイドカー コンテナがそれらのファイルを更新するという構成が考えられます。Podはこれらの複数のコンテナ、ストレージリソース、一時的なネットワークIDなどを、単一のユニットとしてまとめます。
備考: 複数のコンテナを同じ場所で同時に管理するように単一のPod内にグループ化するのは、比較的高度なユースケースです。このパターンを使用するのは、コンテナが密に結合しているような特定のインスタンス内でのみにするべきです。
各Podは、与えられたアプリケーションの単一のインスタンスを稼働するためのものです。もしユーザーのアプリケーションを水平にスケールさせたい場合(例: 複数インスタンスを稼働させる)、複数のPodを使うべきです。1つのPodは各インスタンスに対応しています。Kubernetesでは、これは一般的にレプリケーション と呼ばれます。レプリケーションされたPodは、通常ワークロードリソースと、それに対応するコントローラー によって、作成・管理されます。
Kubernetesがワークロードリソースとそのコントローラーを活用して、スケーラブルで自動回復するアプリケーションを実装する方法については、詳しくはPodとコントローラー を参照してください。
Podが複数のコンテナを管理する方法
Podは、まとまりの強いサービスのユニットを構成する、複数の協調する(コンテナとして実行される)プロセスをサポートするために設計されました。単一のPod内の複数のコンテナは、クラスター内の同じ物理または仮想マシン上で、自動的に同じ場所に配置・スケジューリングされます。コンテナ間では、リソースや依存関係を共有したり、お互いに通信したり、停止するときにはタイミングや方法を協調して実行できます。
たとえば、あるコンテナが共有ボリューム内のファイルを配信するウェブサーバーとして動作し、別の「サイドカー」コンテナがリモートのリソースからファイルをアップデートするような構成が考えられます。この構成を以下のダイアグラムに示します。
Podによっては、appコンテナ に加えてinitコンテナ を持っている場合があります。initコンテナはappコンテナが起動する前に実行・完了するコンテナです。
Podは、Podを構成する複数のコンテナに対して、ネットワーク とストレージ の2種類の共有リソースを提供します。
Podを利用する
通常Kubernetesでは、たとえ単一のコンテナしか持たないシングルトンのPodだとしても、個別のPodを直接作成することはめったにありません。その理由は、Podがある程度一時的で使い捨てできる存在として設計されているためです。Podが作成されると(あなたが直接作成した場合でも、コントローラー が間接的に作成した場合でも)、新しいPodはクラスター内のノード 上で実行されるようにスケジューリングされます。Podは、実行が完了するか、Podオブジェクトが削除されるか、リソース不足によって強制退去 されるか、ノードが停止するまで、そのノード上にとどまります。
備考: Pod内のコンテナの再起動とPodの再起動を混同しないでください。Podはプロセスではなく、コンテナが実行するための環境です。Podは削除されるまでは残り続けます。
Podオブジェクトのためのマニフェストを作成したときは、指定したPodの名前が有効なDNSサブドメイン名 であることを確認してください。
Pod OS
FEATURE STATE: Kubernetes v1.25 [stable]
.spec.os.nameフィールドでwindowsかlinuxのいずれかを設定し、Podを実行させたいOSを指定する必要があります。Kubernetesは今のところ、この2つのOSだけサポートしています。将来的には増える可能性があります。
Kubernetes v1.30では、このフィールドに設定した値はPodのスケジューリング に影響を与えません。.spec.os.nameを設定することで、Pod OSに権限を認証することができ、バリデーションにも使用されます。kubeletが実行されているノードのOSが、指定されたPod OSと異なる場合、kubeletはPodの実行を拒否します。
Podセキュリティの標準 もこのフィールドを使用し、指定したOSと関係ないポリシーの適用を回避しています。
Podとコンテナコントローラー
ワークロードリソースは、複数のPodを作成・管理するために利用できます。リソースに対応するコントローラーが、複製やロールアウトを扱い、Podの障害時には自動回復を行います。たとえば、あるノードに障害が発生した場合、コントローラーはそのノードの動作が停止したことを検知し、代わりのPodを作成します。そして、スケジューラーが代わりのPodを健全なノード上に配置します。
以下に、1つ以上のPodを管理するワークロードリソースの一例をあげます。
Podテンプレート
workload リソース向けのコントローラーは、PodをPodテンプレート を元に作成し、あなたの代わりにPodを管理してくれます。
PodTemplateはPodを作成するための仕様で、Deployment 、Job 、DaemonSet などのワークロードリソースの中に含まれています。
ワークロードリソースに対応する各コントローラーは、ワークロードオブジェクト内にあるPodTemplateを使用して実際のPodを作成します。PodTemplateは、アプリを実行するために使われるワークロードリソースがどんな種類のものであれ、その目的の状態の一部を構成するものです。
以下は、単純なJobのマニフェストの一例で、1つのコンテナを実行するtemplateがあります。Pod内のコンテナはメッセージを出力した後、一時停止します。
apiVersion : batch/v1
kind : Job
metadata :
name : hello
spec :
template :
# これがPodテンプレートです
spec :
containers :
- name : hello
image : busybox:1.28
command : ['sh' , '-c' , 'echo "Hello, Kubernetes!" && sleep 3600' ]
restartPolicy : OnFailure
# Podテンプレートはここまでです
Podテンプレートを修正するか新しいPodに切り替えたとしても、すでに存在するPodには直接の影響はありません。ワークロードリソース内のPodテンプレートを変更すると、そのリソースは更新されたテンプレートを使用して代わりとなるPodを作成する必要があります。
たとえば、StatefulSetコントローラーは、各StatefulSetごとに、実行中のPodが現在のPodテンプレートに一致することを保証します。Podテンプレートを変更するためにStatefulSetを編集すると、StatefulSetは更新されたテンプレートを元にした新しいPodを作成するようになります。最終的に、すべての古いPodが新しいPodで置き換えられ、更新は完了します。
各ワークロードリソースは、Podテンプレートへの変更を処理するための独自のルールを実装しています。特にStatefulSetについて更に詳しく知りたい場合は、StatefulSetの基本チュートリアル内のアップデート戦略 を読んでください。
ノード上では、kubelet はPodテンプレートに関する詳細について監視や管理を直接行うわけではありません。こうした詳細は抽象化されています。こうした抽象化や関心の分離のおかげでシステムのセマンティクスが単純化され、既存のコードを変更せずにクラスターの動作を容易に拡張できるようになっているのです。
Podの更新と取替
前のセクションで述べたように、ワークロードリソースのPodテンプレートが変更されると、コントローラーは既存のPodを更新したりパッチを適用したりするのではなく、更新されたテンプレートに基づいて新しいPodを作成します。
KubernetesはPodを直接管理することを妨げません。実行中のPodの一部のフィールドをその場で更新することが可能です。しかし、patchreplace
Podのメタデータのほとんどは固定されたものです。たとえばnamespace、name、uidまたはcreationTimestampフィールドは変更できません。generationフィールドは特別で、現在の値を増加させる更新のみを受け付けます。
metadata.deletionTimestampが設定されている場合、metadata.finalizersリストに新しい項目を追加することはできません。
Podの更新ではspec.containers[*].image、spec.initContainers[*].image、spec.activeDeadlineSecondsまたはspec.tolerations以外のフィールドを変更してはなりません。
spec.tolerationsについては新しい項目のみを追加することができます。
spec.activeDeadlineSecondsフィールドを更新する場合、2種類の更新が可能です:
未割り当てのフィールドに正の数を設定する
現在の値から負の数でない、より小さい数に更新する
リソースの共有と通信
Podは、データの共有と構成するコンテナ間での通信を可能にします。
Pod内のストレージ
Podでは、共有ストレージであるボリューム の集合を指定できます。Pod内のすべてのコンテナは共有ボリュームにアクセスできるため、それら複数のコンテナでデータを共有できるようになります。また、ボリュームを利用すれば、Pod内のコンテナの1つに再起動が必要になった場合にも、Pod内の永続化データを保持し続けられるようにできます。Kubernetesの共有ストレージの実装方法とPodで利用できるようにする方法に関するさらに詳しい情報は、ストレージ を読んでください。
Podネットワーク
各Podには、各アドレスファミリーごとにユニークなIPアドレスが割り当てられます。Pod内のすべてのコンテナは、IPアドレスとネットワークポートを含むネットワーク名前空間を共有します。Podの中では(かつその場合にのみ )、そのPod内のコンテナはlocalhostを使用して他のコンテナと通信できます。Podの内部にあるコンテナがPodの外部にある エンティティと通信する場合、(ポートなどの)共有ネットワークリソースの使い方をコンテナ間で調整しなければなりません。Pod内では、コンテナはIPアドレスとポートの空間を共有するため、localhostで他のコンテナにアクセスできます。また、Pod内のコンテナは、SystemVのセマフォやPOSIXの共有メモリなど、標準のプロセス間通信を使って他のコンテナと通信することもできます。異なるPod内のコンテナは異なるIPアドレスを持つため、特別な設定をしない限り、OSレベルIPCで通信することはできません。異なるPod上で実行中のコンテナ間でやり取りをしたい場合は、IPネットワークを使用して通信できます。
Pod内のコンテナは、システムのhostnameがPodに設定したnameと同一であると考えます。ネットワークについての詳しい情報は、ネットワーク で説明しています。
コンテナの特権モード
Linuxでは、Pod内のどんなコンテナも、privilegedフラグをコンテナのspecのsecurity context に設定することで、特権モード(privileged mode)を有効にできます。これは、ネットワークスタックの操作やハードウェアデバイスへのアクセスなど、オペレーティングシステムの管理者の権限が必要なコンテナの場合に役に立ちます。
WindowsHostProcessContainers機能を有効にしたクラスターの場合、Pod仕様のsecurityContextにwindowsOptions.hostProcessフラグを設定することで、Windows HostProcess Pod を作成することが可能です。これらのPod内のすべてのコンテナは、Windows HostProcessコンテナとして実行する必要があります。HostProcess Podはホスト上で直接実行され、Linuxの特権コンテナで行われるような管理作業を行うのにも使用できます。
備考: この設定を有効にするには、
コンテナランタイム が特権コンテナの概念をサポートしていなければなりません。
static Pod
static Pod は、APIサーバー には管理されない、特定のノード上でkubeletデーモンによって直接管理されるPodのことです。大部分のPodはコントロールプレーン(たとえばDeployment )によって管理されますが、static Podの場合はkubeletが各static Podを直接管理します(障害時には再起動します)。
static Podは常に特定のノード上の1つのKubelet に紐付けられます。static Podの主な用途は、セルフホストのコントロールプレーンを実行すること、言い換えると、kubeletを使用して個別のコントロールプレーンコンポーネント を管理することです。
kubeletは自動的にKubernetes APIサーバー上に各static Podに対応するミラーPod の作成を試みます。つまり、ノード上で実行中のPodはAPIサーバー上でも見えるようになるけれども、APIサーバー上から制御はできないということです。
コンテナのProbe
Probe はkubeletがコンテナに対して行う定期診断です。診断を実行するために、kubeletはさまざまなアクションを実行できます:
ExecAction (コンテナランタイムの助けを借りて実行)TCPSocketAction (kubeletにより直接チェック)HTTPGetAction (kubeletにより直接チェック)
更に詳しく知りたい場合は、PodのライフサイクルドキュメントにあるProbe を読んでください。
次の項目
Kubernetesが共通のPod APIを他のリソース内(たとえばStatefulSet やDeployment など)にラッピングしている理由の文脈を理解するためには、Kubernetes以前から存在する以下のような既存技術について読むのが助けになります。
4.1.1 - Podのライフサイクル
このページではPodのライフサイクルについて説明します。Podは定義されたライフサイクルに従い Pendingフェーズ から始まり、少なくとも1つのプライマリーコンテナが正常に開始した場合はRunningを経由し、次に失敗により終了したコンテナの有無に応じて、SucceededまたはFailedフェーズを経由します。
Podの実行中、kubeletはコンテナを再起動して、ある種の障害を処理できます。Pod内で、Kubernetesはさまざまなコンテナのステータス を追跡して、回復させるためのアクションを決定します。
Kubernetes APIでは、Podには仕様と実際のステータスの両方があります。Podオブジェクトのステータスは、PodのCondition のセットで構成されます。カスタムのReadiness情報 をPodのConditionデータに挿入することもできます。
Podはその生存期間に1回だけスケジューリング されます。PodがNodeにスケジュール(割り当て)されると、Podは停止または終了 するまでそのNode上で実行されます。
Podのライフタイム
個々のアプリケーションコンテナと同様に、Podは(永続的ではなく)比較的短期間の存在と捉えられます。Podが作成されると、一意のID(UID )が割り当てられ、(再起動ポリシーに従って)終了または削除されるまでNodeで実行されるようにスケジュールされます。ノード が停止した場合、そのNodeにスケジュールされたPodは、タイムアウト時間の経過後に削除 されます。
Pod自体は、自己修復しません。Podがnode にスケジュールされ、その後に失敗した場合、Podは削除されます。同様に、リソースの不足またはNodeのメンテナンスによりPodはNodeから立ち退きます。Kubernetesは、比較的使い捨てのPodインスタンスの管理作業を処理する、controller と呼ばれる上位レベルの抽象化を使用します。
特定のPod(UIDで定義)は新しいNodeに"再スケジュール"されません。代わりに、必要に応じて同じ名前で、新しいUIDを持つ同一のPodに置き換えることができます。
volume など、Podと同じ存続期間を持つものがあると言われる場合、それは(そのUIDを持つ)Podが存在する限り存在することを意味します。そのPodが何らかの理由で削除された場合、たとえ同じ代替物が作成されたとしても、関連するもの(例えばボリューム)も同様に破壊されて再作成されます。
Podの図
file puller(ファイル取得コンテナ)とWebサーバーを含むマルチコンテナのPod。コンテナ間の共有ストレージとして永続ボリュームを使用しています。
Podのフェーズ
Podのstatus項目はPodStatus オブジェクトで、それはphaseのフィールドがあります。
Podのフェーズは、そのPodがライフサイクルのどの状態にあるかを、簡単かつ高レベルにまとめたものです。このフェーズはコンテナやPodの状態を包括的にまとめることを目的としたものではなく、また包括的なステートマシンでもありません。
Podの各フェーズの値と意味は厳重に守られています。ここに記載されているもの以外にphaseの値は存在しないと思ってください。
これらがphaseの取りうる値です。
値
概要
PendingPodがKubernetesクラスターによって承認されましたが、1つ以上のコンテナがセットアップされて稼働する準備ができていません。これには、スケジュールされるまでの時間と、ネットワーク経由でイメージをダウンロードするための時間などが含まれます。
RunningPodがNodeにバインドされ、すべてのコンテナが作成されました。少なくとも1つのコンテナがまだ実行されているか、開始または再起動中です。
SucceededPod内のすべてのコンテナが正常に終了し、再起動されません。
FailedPod内のすべてのコンテナが終了し、少なくとも1つのコンテナが異常終了しました。つまり、コンテナはゼロ以外のステータスで終了したか、システムによって終了されました。
Unknown何らかの理由によりPodの状態を取得できませんでした。このフェーズは通常はPodのホストとの通信エラーにより発生します。
備考: Podの削除中に、kubectlコマンドには
Terminatingが出力されることがあります。この
Terminatingステータスは、Podのフェーズではありません。Podには、正常に終了するための期間を与えられており、デフォルトは30秒です。
--forceフラグを使用して、
Podを強制的に削除する ことができます。
Nodeが停止するか、クラスターの残りの部分から切断された場合、Kubernetesは失われたNode上のすべてのPodのPhaseをFailedに設定するためのポリシーを適用します。
コンテナのステータス
Pod全体のフェーズ と同様に、KubernetesはPod内の各コンテナの状態を追跡します。container lifecycle hooks を使用して、コンテナのライフサイクルの特定のポイントで実行するイベントをトリガーできます。
Podがscheduler によってNodeに割り当てられると、kubeletはcontainer runtime を使用してコンテナの作成を開始します。コンテナの状態はWaiting、RunningまたはTerminatedの3ついずれかです。
Podのコンテナの状態を確認するにはkubectl describe pod [POD_NAME]のコマンドを使用します。Pod内のコンテナごとにStateの項目として表示されます。
各状態の意味は次のとおりです。
WaitingコンテナがRunningまたはTerminatedのいずれの状態でもない場合コンテナはWaitingの状態になります。Waiting状態のコンテナは引き続きコンテナイメージレジストリからイメージを取得したりSecret を適用したりするなど必要な操作を実行します。Waiting状態のコンテナを持つPodに対してkubectlコマンドを使用すると、そのコンテナがWaitingの状態である理由の要約が表示されます。
RunningRunning状態はコンテナが問題なく実行されていることを示します。postStartフックが構成されていた場合、それはすでに実行が完了しています。Running状態のコンテナを持つPodに対してkubectlコマンドを使用すると、そのコンテナがRunning状態になった時刻が表示されます。
TerminatedTerminated状態のコンテナは実行されて、完了したときまたは何らかの理由で失敗したことを示します。Terminated状態のコンテナを持つPodに対してkubectlコマンドを使用すると、いずれにせよ理由と終了コード、コンテナの開始時刻と終了時刻が表示されます。
コンテナがTerminatedに入る前にpreStopフックがあれば実行されます。
コンテナの再起動ポリシー
Podのspecには、Always、OnFailure、またはNeverのいずれかの値を持つrestartPolicyフィールドがあります。デフォルト値はAlwaysです。
restartPolicyは、Pod内のすべてのコンテナに適用されます。restartPolicyは、同じNode上のkubeletによるコンテナの再起動のみを参照します。Pod内のコンテナが終了した後、kubeletは5分を上限とする指数バックオフ遅延(10秒、20秒、40秒...)でコンテナを再起動します。コンテナが10分間実行されると、kubeletはコンテナの再起動バックオフタイマーをリセットします。
PodのCondition
PodにはPodStatusがあります。それにはPodが成功したかどうかの情報を持つPodCondition の配列が含まれています。kubeletは、下記のPodConditionを管理します:
PodScheduled: PodがNodeにスケジュールされました。PodHasNetwork: (アルファ版機能; 明示的に有効 にしなければならない) Podサンドボックスが正常に作成され、ネットワークの設定が完了しました。ContainersReady: Pod内のすべてのコンテナが準備できた状態です。Initialized: すべてのInitコンテナ が正常に終了しました。Ready: Podはリクエストを処理でき、一致するすべてのサービスの負荷分散プールに追加されます。
フィールド名
内容
typeこのPodの状態の名前です。
statusその状態が適用可能かどうか示します。可能な値は"True"、"False"、"Unknown"のうちのいずれかです。
lastProbeTimePod Conditionが最後に確認されたときのタイムスタンプが表示されます。
lastTransitionTime最後にPodのステータスの遷移があった際のタイムスタンプが表示されます。
reason最後の状態遷移の理由を示す、機械可読のアッパーキャメルケースのテキストです。
messageステータスの遷移に関する詳細を示す人間向けのメッセージです。
PodのReadiness
FEATURE STATE: Kubernetes v1.14 [stable]
追加のフィードバックやシグナルをPodStatus:Pod readiness に注入できるようにします。これを使用するには、PodのspecでreadinessGatesを設定して、kubeletがPodのReadinessを評価する追加の状態のリストを指定します。
ReadinessゲートはPodのstatus.conditionsフィールドの現在の状態によって決まります。KubernetesがPodのstatus.conditionsフィールドでそのような状態を発見できない場合、ステータスはデフォルトでFalseになります。
以下はその例です。
Kind : Pod
...
spec :
readinessGates :
- conditionType : "www.example.com/feature-1"
status :
conditions :
- type : Ready # これはビルトインのPodCondition
status : "False"
lastProbeTime : null
lastTransitionTime : 2018-01-01T00:00:00Z
- type : "www.example.com/feature-1" # 追加のPodCondition
status : "False"
lastProbeTime : null
lastTransitionTime : 2018-01-01T00:00:00Z
containerStatuses :
- containerID : docker://abcd...
ready : true
...
PodのConditionは、Kubernetesのlabel key format に準拠している必要があります。
PodのReadinessの状態
kubectl patchコマンドはオブジェクトステータスのパッチ適用をまだサポートしていません。Podにこれらのstatus.conditionsを設定するには、アプリケーションとoperators はPATCHアクションを使用する必要があります。Kubernetes client library を使用して、PodのReadinessのためにカスタムのPodのConditionを設定するコードを記述できます。
カスタムのPodのConditionが導入されるとPodは次の両方の条件に当てはまる場合のみ 準備できていると評価されます:
Pod内のすべてのコンテナが準備完了している。
ReadinessGatesで指定された条件が全てTrueである。
Podのコンテナは準備完了ですが、少なくとも1つのカスタムのConditionが欠落しているか「False」の場合、kubeletはPodのCondition をContainersReadyに設定します。
PodのネットワークのReadiness
FEATURE STATE: Kubernetes v1.25 [alpha]
Podがノードにスケジュールされた後、kubeletによって承認され、任意のボリュームがマウントされる必要があります。これらのフェーズが完了すると、kubeletはコンテナランタイム(コンテナランタイムインターフェース(CRI) を使用)と連携して、ランタイムサンドボックスのセットアップとPodのネットワークを構成します。もしPodHasNetworkConditionフィーチャーゲート が有効になっている場合、kubeletは、Podがこの初期化の節目に到達したかどうかをPodのstatus.conditionsフィールドにあるPodHasNetwork状態を使用して報告します。
ネットワークが設定されたランタイムサンドボックスがPodにないことを検出すると、PodHasNetwork状態は、kubelet によってFalseに設定されます。これは、以下のシナリオで発生します:
Podのライフサイクルの初期で、kubeletがコンテナランタイムを使用してPodのサンドボックスのセットアップをまだ開始していないとき
Podのライフサイクルの後期で、Podのサンドボックスが以下のどちらかの原因で破壊された場合:
Podを退去させず、ノードが再起動する
コンテナランタイムの隔離に仮想マシンを使用している場合、Podサンドボックスの仮想マシンが再起動し、新しいサンドボックスと新しいコンテナネットワーク設定を作成する必要があります
ランタイムプラグインによるサンドボックスの作成とPodのネットワーク設定が正常に完了すると、kubeletによってPodHasNetwork状態がTrueに設定されます。PodHasNetwork状態がTrueに設定された後、kubeletはコンテナイメージの取得とコンテナの作成を開始することができます。
initコンテナを持つPodの場合、initコンテナが正常に完了すると(ランタイムプラグインによるサンドボックスの作成とネットワーク設定が正常に行われた後に発生)、kubeletはInitialized状態をTrueに設定します。initコンテナがないPodの場合、サンドボックスの作成およびネットワーク設定が開始する前にkubeletはInitialized状態をTrueに設定します。
コンテナのProbe
Probe はkubelet により定期的に実行されるコンテナの診断です。診断を行うために、kubeletはコンテナ内でコードを実行するか、ネットワークリクエストします。
チェックのメカニズム
probeを使ってコンテナをチェックする4つの異なる方法があります。
各probeは、この4つの仕組みのうち1つを正確に定義する必要があります:
execコンテナ内で特定のコマンドを実行します。コマンドがステータス0で終了した場合に診断を成功と見なします。
grpcgRPC を使ってリモートプロシージャコールを実行します。
ターゲットは、gRPC health checks を実装する必要があります。
レスポンスのstatusがSERVINGの場合に診断を成功と見なします。
gRPCはアルファ版の機能のため、GRPCContainerProbeフィーチャーゲート が
有効の場合のみ利用可能です。httpGetPodのIPアドレスに対して、指定されたポートとパスでHTTP GETのリクエストを送信します。
レスポンスのステータスコードが200以上400未満の際に診断を成功とみなします。
tcpSocketPodのIPアドレスに対して、指定されたポートでTCPチェックを行います。
そのポートが空いていれば診断を成功とみなします。
オープンしてすぐにリモートシステム(コンテナ)が接続を切断した場合、健全な状態としてカウントします。
Probeの結果
各Probe 次の3つのうちの一つの結果を持ちます:
Successコンテナの診断が成功しました。
Failureコンテナの診断が失敗しました。
Unknownコンテナの診断自体が失敗しました(何も実行する必要はなく、kubeletはさらにチェックを行います)。
Probeの種類
kubeletは3種類のProbeを実行中のコンテナで行い、また反応することができます:
livenessProbeコンテナが動いているかを示します。
livenessProbeに失敗すると、kubeletはコンテナを殺します、そしてコンテナはrestart policy に従います。
コンテナにlivenessProbeが設定されていない場合、デフォルトの状態はSuccessです。
readinessProbeコンテナがリクエスト応答する準備ができているかを示します。
readinessProbeに失敗すると、エンドポイントコントローラーにより、ServiceからそのPodのIPアドレスが削除されます。
initial delay前のデフォルトのreadinessProbeの初期値はFailureです。
コンテナにreadinessProbeが設定されていない場合、デフォルトの状態はSuccessです。
startupProbeコンテナ内のアプリケーションが起動したかどうかを示します。
startupProbeが設定された場合、完了するまでその他のすべてのProbeは無効になります。
startupProbeに失敗すると、kubeletはコンテナを殺します、そしてコンテナはrestart policy に従います。
コンテナにstartupProbeが設定されていない場合、デフォルトの状態はSuccessです。
livenessProbe、readinessProbeまたはstartupProbeを設定する方法の詳細については、Liveness Probe、Readiness ProbeおよびStartup Probeを使用する を参照してください。
livenessProbeをいつ使うべきか?
FEATURE STATE: Kubernetes v1.0 [stable]
コンテナ自体に問題が発生した場合や状態が悪くなった際にクラッシュすることができればlivenessProbeは不要です。
この場合kubeletが自動でPodのrestartPolicyに基づいたアクションを実行します。
Probeに失敗したときにコンテナを殺したり再起動させたりするには、livenessProbeを設定しrestartPolicyをAlwaysまたはOnFailureにします。
readinessProbeをいつ使うべきか?
FEATURE STATE: Kubernetes v1.0 [stable]
Probeが成功したときにのみPodにトラフィックを送信したい場合は、readinessProbeを指定します。
この場合readinessProbeはlivenessProbeと同じになる可能性がありますが、readinessProbeが存在するということは、Podがトラフィックを受けずに開始され、Probe成功が開始した後でトラフィックを受け始めることになります。
コンテナがメンテナンスのために停止できるようにするには、livenessProbeとは異なる、特定のエンドポイントを確認するreadinessProbeを指定することができます。
アプリがバックエンドサービスと厳密な依存関係にある場合、livenessProbeとreadinessProbeの両方を実装することができます。アプリ自体が健全であればlivenessProbeはパスしますが、readinessProbeはさらに、必要なバックエンドサービスが利用可能であるかどうかをチェックします。これにより、エラーメッセージでしか応答できないPodへのトラフィックの転送を避けることができます。
コンテナの起動中に大きなデータ、構成ファイル、またはマイグレーションを読み込む必要がある場合は、startupProbe を使用できます。ただし、失敗したアプリと起動データを処理中のアプリの違いを検出したい場合は、readinessProbeを使用した方が良いかもしれません。
備考: Podが削除されたときにリクエストを来ないようにするためには必ずしもreadinessProbeが必要というわけではありません。Podの削除時にはreadinessProbeが存在するかどうかに関係なくPodは自動的に自身をunreadyにします。Pod内のコンテナが停止するのを待つ間Podはunreadyのままです。
startupProbeをいつ使うべきか?
FEATURE STATE: Kubernetes v1.20 [stable]
startupProbeは、サービスの開始に時間がかかるコンテナを持つPodに役立ちます。livenessProbeの間隔を長く設定するのではなく、コンテナの起動時に別のProbeを構成して、livenessProbeの間隔よりも長い時間を許可できます。
コンテナの起動時間が、initialDelaySeconds + failureThreshold x periodSecondsよりも長い場合は、livenessProbeと同じエンドポイントをチェックするためにstartupProbeを指定します。periodSecondsのデフォルトは10秒です。次に、failureThresholdをlivenessProbeのデフォルト値を変更せずにコンテナが起動できるように、十分に高い値を設定します。これによりデッドロックを防ぐことができます。
Podの終了
Podは、クラスター内のNodeで実行中のプロセスを表すため、不要になったときにそれらのプロセスを正常に終了できるようにすることが重要です(対照的なケースは、KILLシグナルで強制終了され、クリーンアップする機会がない場合)。
ユーザーは削除を要求可能であるべきで、プロセスがいつ終了するかを知ることができなければなりませんが、削除が最終的に完了することも保証できるべきです。ユーザーがPodの削除を要求すると、システムはPodが強制終了される前に意図された猶予期間を記録および追跡します。強制削除までの猶予期間がある場合、kubelet 正常な終了を試みます。
通常、コンテナランタイムは各コンテナのメインプロセスにTERMシグナルを送信します。多くのコンテナランタイムは、コンテナイメージで定義されたSTOPSIGNAL値を尊重し、TERMシグナルの代わりにこれを送信します。猶予期間が終了すると、プロセスにKILLシグナルが送信され、PodはAPI server から削除されます。プロセスの終了を待っている間にkubeletかコンテナランタイムの管理サービスが再起動されると、クラスターは元の猶予期間を含めて、最初からリトライされます。
フローの例は下のようになります。
ユーザーがデフォルトの猶予期間(30秒)でPodを削除するためにkubectlコマンドを送信する。
API server内のPodは、猶予期間を越えるとPodが「死んでいる」と見なされるように更新される。kubectl describeコマンドを使用すると、Podは「終了中」と表示される。
Pod内のコンテナの1つがpreStopフック を定義している場合は、コンテナの内側で呼び出される。猶予期間が終了した後もpreStopフックがまだ実行されている場合は、一度だけ猶予期間を延長される(2秒)。
備考: preStopフックが完了するまでにより長い時間が必要な場合は、terminationGracePeriodSecondsを変更する必要があります。
kubeletはコンテナランタイムをトリガーして、コンテナ内のプロセス番号1にTERMシグナルを送信する。
備考: Pod内のすべてのコンテナが同時にTERMシグナルを受信するわけではなく、シャットダウンの順序が問題になる場合はそれぞれにpreStopフックを使用して同期することを検討する。
kubeletが正常な終了を開始すると同時に、コントロールプレーンは、終了中のPodをEndpointSlice(およびEndpoints)オブジェクトから削除します。これらのオブジェクトは、selector が設定されたService を表します。ReplicaSets とその他のワークロードリソースは、終了中のPodを有効なサービス中のReplicaSetとして扱いません。ゆっくりと終了するPodは、(サービスプロキシのような)ロードバランサーが終了猶予期間が始まる とエンドポイントからそれらのPodを削除するので、トラフィックを継続して処理できません。
猶予期間が終了すると、kubeletは強制削除を開始する。コンテナランタイムは、Pod内でまだ実行中のプロセスにSIGKILLを送信する。kubeletは、コンテナランタイムが非表示のpauseコンテナを使用している場合、そのコンテナをクリーンアップします。
kubeletは猶予期間を0(即時削除)に設定することでAPI server上のPodの削除を終了する。
API serverはPodのAPIオブジェクトを削除し、クライアントからは見えなくなります。
Podの強制削除
注意: 強制削除は、Podによっては潜在的に危険な場合があるため、慎重に実行する必要があります。
デフォルトでは、すべての削除は30秒以内に正常に行われます。kubectl delete コマンドは、ユーザーがデフォルト値を上書きして独自の値を指定できるようにする --grace-period=<seconds> オプションをサポートします。
--grace-periodを0に設定した場合、PodはAPI serverから即座に強制的に削除されます。PodがNode上でまだ実行されている場合、その強制削除によりkubeletがトリガーされ、すぐにクリーンアップが開始されます。
備考: 強制削除を実行するために --grace-period=0 と共に --force というフラグを追加で指定する必要があります。
強制削除が実行されると、API serverは、Podが実行されていたNode上でPodが停止されたというkubeletからの確認を待ちません。API内のPodは直ちに削除されるため、新しいPodを同じ名前で作成できるようになります。Node上では、すぐに終了するように設定されるPodは、強制終了される前にわずかな猶予期間が与えられます。
注意: 即時削除では、実行中のリソースの終了を待ちません。
リソースはクラスター上で無期限に実行し続ける可能性があります。
StatefulSetのPodについては、StatefulSetからPodを削除するためのタスクのドキュメント を参照してください。
終了したPodのガベージコレクション
失敗したPodは人間またはcontroller が明示的に削除するまで存在します。
コントロールプレーンは終了状態のPod(SucceededまたはFailedのphaseを持つ)の数が設定された閾値(kube-controller-manager内のterminated-pod-gc-thresholdによって定義される)を超えたとき、それらのPodを削除します。これはPodが作成されて時間とともに終了するため、リソースリークを避けます。
次の項目
4.1.2 - Initコンテナ
このページでは、Initコンテナについて概観します。Initコンテナとは、Pod 内でアプリケーションコンテナの前に実行される特別なコンテナです。
Initコンテナにはアプリケーションコンテナのイメージに存在しないセットアップスクリプトやユーティリティーを含めることができます。
Initコンテナは、Podの仕様のうちcontainersという配列(これがアプリケーションコンテナを示します)と並べて指定します。
Initコンテナを理解する
単一のPod は、Pod内にアプリケーションを実行している複数のコンテナを持つことができますが、同様に、アプリケーションコンテナが起動する前に実行されるInitコンテナも1つ以上持つことができます。
Initコンテナは下記の項目をのぞいて、通常のコンテナと全く同じものとなります。
Initコンテナは常に完了するまで稼働します。
各Initコンテナは、次のInitコンテナが稼働する前に正常に完了しなくてはなりません。
もしあるPodの単一のInitコンテナが失敗した場合、Kubeletは成功するまで何度もそのInitコンテナを再起動します。しかし、もしそのPodのrestartPolicyがNeverで、そのPodの起動時にInitコンテナが失敗した場合、KubernetesはそのPod全体を失敗として扱います。
PodにInitコンテナを指定するためには、Podの仕様 にinitContainersフィールドをcontainerアイテムの配列として追加してください(アプリケーションのcontainersフィールドとそのコンテンツに似ています)。
詳細については、APIリファレンスのContainer を参照してください。
Initコンテナのステータスは、.status.initContainerStatusesフィールドにコンテナのステータスの配列として返されます(.status.containerStatusesと同様)。
通常のコンテナとの違い
Initコンテナは、リソースリミット、ボリューム、セキュリティ設定などのアプリケーションコンテナの全てのフィールドと機能をサポートしています。しかし、Initコンテナに対するリソースリクエストやリソースリミットの扱いは異なります。リソース にて説明します。
また、InitコンテナはそのPodの準備ができる前に完了しなくてはならないため、lifecycle、livenessProbe、readinessProbeおよびstartupProbeをサポートしていません。
複数のInitコンテナを単一のPodに対して指定した場合、KubeletはそれらのInitコンテナを1つずつ順番に実行します。各Initコンテナは、次のInitコンテナが稼働する前に正常終了しなくてはなりません。全てのInitコンテナの実行が完了すると、KubeletはPodのアプリケーションコンテナを初期化し、通常通り実行します。
Initコンテナを使用する
Initコンテナはアプリケーションコンテナのイメージとは分離されているため、コンテナの起動に関連したコードにおいていくつかの利点があります。
Initコンテナはアプリケーションのイメージに存在しないセットアップ用のユーティリティーやカスタムコードを含むことができます。例えば、セットアップ中にsed、awk、pythonや、digのようなツールを使うためだけに、別のイメージを元にしてアプリケーションイメージを作る必要がなくなります。
アプリケーションイメージをビルドする役割とデプロイする役割は、共同で単一のアプリケーションイメージをビルドする必要がないため、それぞれ独立して実施することができます。
Initコンテナは同一Pod内のアプリケーションコンテナと別のファイルシステムビューで稼働することができます。その結果、アプリケーションコンテナがアクセスできないSecret に対するアクセス権限を得ることができます。
Initコンテナはアプリケーションコンテナが開始する前に完了するまで実行されるため、Initコンテナを使用することで、特定の前提条件が満たされるまでアプリケーションコンテナの起動をブロックしたり遅らせることができます。前提条件が満たされると、Pod内の全てのアプリケーションコンテナを並行して起動することができます。
Initコンテナはアプリケーションコンテナイメージの安全性を低下させるようなユーティリティーやカスタムコードを安全に実行することができます。不必要なツールを分離しておくことで、アプリケーションコンテナイメージのアタックサーフィスを制限することができます。
例
Initコンテナを活用する方法について、いくつかのアイデアを次に示します。
シェルコマンドを使って単一のService が作成されるのを待機する。
for i in { 1..100} ; do sleep 1; if nslookup myservice; then exit 0; fi ; done ; exit 1
以下のようなコマンドを使って下位のAPIからPodの情報をリモートサーバに登録する。
curl -X POST http://$MANAGEMENT_SERVICE_HOST :$MANAGEMENT_SERVICE_PORT /register -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)'
以下のようなコマンドを使ってアプリケーションコンテナの起動を待機する。
gitリポジトリをVolume にクローンする。
いくつかの値を設定ファイルに配置し、メインのアプリケーションコンテナのための設定ファイルを動的に生成するためのテンプレートツールを実行する。例えば、そのPodのPOD_IPの値を設定ファイルに配置し、Jinjaを使ってメインのアプリケーションコンテナの設定ファイルを生成する。
Initコンテナの具体的な使用方法
下記の例は2つのInitコンテナを含むシンプルなPodを定義しています。
1つ目のInitコンテナはmyserviesの起動を、2つ目のInitコンテナはmydbの起動をそれぞれ待ちます。両方のInitコンテナの実行が完了すると、Podはspecセクションにあるアプリケーションコンテナを実行します。
apiVersion : v1
kind : Pod
metadata :
name : myapp-pod
labels :
app.kubernetes.io/name : MyApp
spec :
containers :
- name : myapp-container
image : busybox:1.28
command : ['sh' , '-c' , 'echo The app is running! && sleep 3600' ]
initContainers :
- name : init-myservice
image : busybox:1.28
command : ['sh' , '-c' , "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done" ]
- name : init-mydb
image : busybox:1.28
command : ['sh' , '-c' , "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done" ]
次のコマンドを実行して、このPodを開始できます。
kubectl apply -f myapp.yaml
実行結果は下記のようになります。
pod/myapp-pod created
そして次のコマンドでステータスを確認します。
kubectl get -f myapp.yaml
実行結果は下記のようになります。
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 6m
より詳細な情報は次のコマンドで確認します。
kubectl describe -f myapp.yaml
実行結果は下記のようになります。
Name: myapp-pod
Namespace: default
[...]
Labels: app.kubernetes.io/name=MyApp
Status: Pending
[...]
Init Containers:
init-myservice:
[...]
State: Running
[...]
init-mydb:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Containers:
myapp-container:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
16s 16s 1 {default-scheduler } Normal Scheduled Successfully assigned myapp-pod to 172.17.4.201
16s 16s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulling pulling image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulled Successfully pulled image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Created Created container with docker id 5ced34a04634; Security:[seccomp=unconfined]
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Started Started container with docker id 5ced34a04634
このPod内のInitコンテナのログを確認するためには、次のコマンドを実行します。
kubectl logs myapp-pod -c init-myservice # 1つ目のInitコンテナを調査する
kubectl logs myapp-pod -c init-mydb # 2つ目のInitコンテナを調査する
この時点で、これらのInitコンテナはmydbとmyserviceという名前のServiceの検出を待機しています。
これらのServiceを検出させるための構成は以下の通りです。
---
apiVersion : v1
kind : Service
metadata :
name : myservice
spec :
ports :
- protocol : TCP
port : 80
targetPort : 9376
---
apiVersion : v1
kind : Service
metadata :
name : mydb
spec :
ports :
- protocol : TCP
port : 80
targetPort : 9377
mydbおよびmyserviceというServiceを作成するために、以下のコマンドを実行します。
kubectl apply -f services.yaml
実行結果は下記のようになります。
service/myservice created
service/mydb created
Initコンテナが完了し、myapp-podというPodがRunning状態に移行したことが確認できます。
kubectl get -f myapp.yaml
実行結果は下記のようになります。
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 9m
このシンプルな例を独自のInitコンテナを作成する際の参考にしてください。次の項目 にさらに詳細な使用例に関するリンクがあります。
Initコンテナのふるまいに関する詳細
Podの起動時に、kubeletはネットワークおよびストレージの準備が整うまで、Initコンテナを実行可能な状態にしません。また、kubeletはPodのspecに定義された順番に従ってPodのInitコンテナを起動します。
各Initコンテナは次のInitコンテナが起動する前に正常に終了しなくてはなりません。もしあるInitコンテナがランタイムにより起動失敗した場合、もしくはエラーで終了した場合、そのPodのrestartPolicyの値に従ってリトライされます。しかし、もしPodのrestartPolicyがAlwaysに設定されていた場合、InitコンテナのrestartPolicyはOnFailureが適用されます。
Podは全てのInitコンテナが完了するまでReady状態となりません。Initコンテナ上のポートはServiceによって集約されません。初期化中のPodのステータスはPendingとなりますが、Initializedという値はtrueとなります。
もしそのPodを再起動 するとき、または再起動されたとき、全てのInitコンテナは必ず再度実行されます。
Initコンテナの仕様の変更は、コンテナイメージのフィールドのみに制限されています。
Initコンテナのイメージフィールド値を変更すると、そのPodは再起動されます。
Initコンテナは何度も再起動、リトライおよび再実行可能なため、べき等(Idempotent)である必要があります。特に、EmptyDirsにファイルを書き込むコードは、書き込み先のファイルがすでに存在している可能性を考慮に入れる必要があります。
Initコンテナはアプリケーションコンテナの全てのフィールドを持っています。しかしKubernetesは、Initコンテナが完了と異なる状態を定義できないためreadinessProbeが使用されることを禁止しています。これはバリデーションの際に適用されます。
Initコンテナがずっと失敗し続けたままの状態を防ぐために、PodにactiveDeadlineSecondsを設定してください。activeDeadlineSecondsの設定はInitコンテナが実行中の時間にも適用されます。しかしactiveDeadlineSecondsはInitコンテナが終了した後でも効果があるため、チームがアプリケーションをJobとしてデプロイする場合にのみ使用することが推奨されています。
すでに正しく動作しているPodはactiveDeadlineSecondsを設定すると強制終了されます。
Pod内の各アプリケーションコンテナとInitコンテナの名前はユニークである必要があります。他のコンテナと同じ名前を共有していた場合、バリデーションエラーが返されます。
リソース
Initコンテナの順序と実行を考えるとき、リソースの使用に関して下記のルールが適用されます。
全てのInitコンテナの中で定義された最も高いリソースリクエストとリソースリミットが、有効なinitリクエスト/リミット になります。いずれかのリソースでリミットが設定されていない場合、これが最上級のリミットとみなされます。
Podのリソースの有効なリクエスト/リミット は、下記の2つの中のどちらか高い方となります。
リソースに対する全てのアプリケーションコンテナのリクエスト/リミットの合計
リソースに対する有効なinitリクエスト/リミット
スケジューリングは有効なリクエスト/リミットに基づいて実行されます。つまり、InitコンテナはPodの生存中には使用されない初期化用のリソースを確保することができます。
Podの有効なQoS(quality of service)ティアー は、Initコンテナとアプリケーションコンテナで同様です。
クォータとリミットは有効なPodリクエストとリミットに基づいて適用されます。
Podレベルのコントロールグループ(cgroups)は、スケジューラーと同様に、有効なPodリクエストとリミットに基づいています。
Podの再起動の理由
以下の理由によりPodは再起動し、Initコンテナの再実行も引き起こす可能性があります。
そのPodのインフラストラクチャーコンテナが再起動された場合。これはあまり起きるものでなく、Nodeに対するルート権限を持ったユーザーにより行われることがあります。
restartPolicyがAlwaysと設定されているPod内の全てのコンテナが停止され、強制的に再起動が行われたことで、ガベージコレクションによりInitコンテナの完了記録が失われた場合。
Kubernetes v1.20以降では、initコンテナのイメージが変更されたり、ガベージコレクションによってinitコンテナの完了記録が失われたりした場合でも、Podは再起動されません。以前のバージョンを使用している場合は、対応バージョンのドキュメントを参照してください。
次の項目
4.1.3 - サイドカーコンテナ
FEATURE STATE: Kubernetes v1.29 [beta]
サイドカーコンテナは、メインのアプリケーションコンテナと同じPod 内で実行されるセカンダリーコンテナです。
これらのコンテナは、主要なアプリケーションコードを直接変更することなく、ロギング、モニタリング、セキュリティ、データの同期などの追加サービスや機能を提供することにより、アプリケーションコンテナの機能を強化または拡張するために使用されます。
サイドカーコンテナの有効化
Kubernetes 1.29でデフォルトで有効化されたSidecarContainersという名前の フィーチャーゲート により、
PodのinitContainersフィールドに記載されているコンテナのrestartPolicyを指定することができます。
これらの再起動可能な サイドカー コンテナは、同じポッド内の他のinitコンテナ やメインのアプリケーションコンテナとは独立しています。
これらは、メインアプリケーションコンテナや他のinitコンテナに影響を与えることなく、開始、停止、または再起動することができます。
サイドカーコンテナとPodのライフサイクル
もしinitコンテナがrestartPolicyをAlwaysに設定して作成された場合、それはPodのライフサイクル全体にわたって起動し続けます。
これは、メインアプリケーションコンテナから分離されたサポートサービスを実行するのに役立ちます。
このinitコンテナにreadinessProbeが指定されている場合、その結果はPodのready状態を決定するために使用されます。
これらのコンテナはinitコンテナとして定義されているため、他のinitコンテナと同様に順序に関する保証を受けることができ、複雑なPodの初期化フローに他のinitコンテナと混在させることができます。
通常のinitコンテナと比較して、initContainers内で定義されたサイドカーは、開始した後も実行を続けます。
これは、.spec.initContainersにPod用の複数のエントリーがある場合に重要です。
サイドカースタイルのinitコンテナが実行中になった後(kubeletがそのinitコンテナのstartedステータスをtrueに設定した後)、kubeletは順序付けられた.spec.initContainersリストから次のinitコンテナを開始します。
そのステータスは、コンテナ内でプロセスが実行されておりStartup Probeが定義されていない場合、あるいはそのstartupProbeが成功するとtrueになります。
以下は、サイドカーを含む2つのコンテナを持つDeploymentの例です:
apiVersion : apps/v1
kind : Deployment
metadata :
name : myapp
labels :
app : myapp
spec :
replicas : 1
selector :
matchLabels :
app : myapp
template :
metadata :
labels :
app : myapp
spec :
containers :
- name : myapp
image : alpine:latest
command : ['sh' , '-c' , 'while true; do echo "logging" >> /opt/logs.txt; sleep 1; done' ]
volumeMounts :
- name : data
mountPath : /opt
initContainers :
- name : logshipper
image : alpine:latest
restartPolicy : Always
command : ['sh' , '-c' , 'tail -F /opt/logs.txt' ]
volumeMounts :
- name : data
mountPath : /opt
volumes :
- name : data
emptyDir : {}
この機能は、サイドカーコンテナがメインコンテナが終了した後もジョブが完了するのを妨げないため、サイドカーを持つジョブを実行するのにも役立ちます。
以下は、サイドカーを含む2つのコンテナを持つJobの例です:
apiVersion : batch/v1
kind : Job
metadata :
name : myjob
spec :
template :
spec :
containers :
- name : myjob
image : alpine:latest
command : ['sh' , '-c' , 'echo "logging" > /opt/logs.txt' ]
volumeMounts :
- name : data
mountPath : /opt
initContainers :
- name : logshipper
image : alpine:latest
restartPolicy : Always
command : ['sh' , '-c' , 'tail -F /opt/logs.txt' ]
volumeMounts :
- name : data
mountPath : /opt
restartPolicy : Never
volumes :
- name : data
emptyDir : {}
通常のコンテナとの違い
サイドカーコンテナは、同じPod内の通常のコンテナと並行して実行されます。
しかし、主要なアプリケーションロジックを実行するわけではなく、メインのアプリケーションにサポート機能を提供します。
サイドカーコンテナは独自の独立したライフサイクルを持っています。
通常のコンテナとは独立して開始、停止、再起動することができます。
これは、メインアプリケーションに影響を与えることなく、サイドカーコンテナを更新、スケール、メンテナンスできることを意味します。
サイドカーコンテナは、メインのコンテナと同じネットワークおよびストレージの名前空間を共有します。
このような配置により、密接に相互作用し、リソースを共有することができます。
initコンテナとの違い
サイドカーコンテナは、メインのコンテナと並行して動作し、その機能を拡張し、追加サービスを提供します。
サイドカーコンテナは、メインアプリケーションコンテナと並行して実行されます。
Podのライフサイクル全体を通じてアクティブであり、メインコンテナとは独立して開始および停止することができます。
Initコンテナ とは異なり、サイドカーコンテナはライフサイクルを制御するためのProbe をサポートしています。
これらのコンテナは、メインアプリケーションコンテナと直接相互作用することができ、同じネットワーク名前空間、ファイルシステム、環境変数を共有します。追加の機能を提供するために緊密に連携して動作します。
コンテナ内のリソース共有
Initコンテナ、サイドカーコンテナ、アプリケーションコンテナの順序と実行を考えるとき、リソースの使用に関して下記のルールが適用されます。
全てのInitコンテナの中で定義された最も高いリソースリクエストとリソースリミットが、有効なinitリクエスト/リミット になります。いずれかのリソースでリミットが設定されていない場合、これが最上級のリミットとみなされます。
Podのリソースの有効なリクエスト/リミット は、Podのオーバーヘッド と次のうち大きい方の合計になります。
リソースに対する全てのアプリケーションコンテナとサイドカーコンテナのリクエスト/リミットの合計
リソースに対する有効なinitリクエスト/リミット
スケジューリングは有効なリクエスト/リミットに基づいて実行されます。つまり、InitコンテナはPodの生存中には使用されない初期化用のリソースを確保することができます。
Podの有効なQoS(quality of service)ティアー は、Initコンテナ、サイドカーコンテナ、アプリケーションコンテナで同様です。
クォータとリミットは有効なPodリクエストとリミットに基づいて適用されます。
Podレベルのコントロールグループ(cgroups)は、スケジューラーと同様に、有効なPodリクエストとリミットに基づいています。
次の項目
4.1.4 - Disruption
このガイドは、高可用性アプリケーションを構築したいと考えており、そのために、Podに対してどのような種類のDisruptionが発生する可能性があるか理解する必要がある、アプリケーション所有者を対象としたものです。
また、クラスターのアップグレードやオートスケーリングなどのクラスターの操作を自動化したいクラスター管理者も対象にしています。
自発的なDisruptionと非自発的なDisruption
Podは誰か(人やコントローラー)が破壊するか、避けることができないハードウェアまたはシステムソフトウェアエラーが発生するまで、消えることはありません。
これらの不可避なケースをアプリケーションに対する非自発的なDisruption と呼びます。
例えば:
ノードのバックエンドの物理マシンのハードウェア障害
クラスター管理者が誤ってVM(インスタンス)を削除した
クラウドプロバイダーまたはハイパーバイザーの障害によってVMが消えた
カーネルパニック
クラスターネットワークパーティションが原因でクラスターからノードが消えた
ノードのリソース不足 によるPodの退避
リソース不足を除いて、これら条件は全て、大半のユーザーにとって馴染みのあるものでしょう。
これらはKubernetesに固有のものではありません。
それ以外のケースのことを自発的なDisruption と呼びます。
これらはアプリケーションの所有者によって起こされたアクションと、クラスター管理者によって起こされたアクションの両方を含みます。
典型的なアプリケーションの所有者によるアクションには次のものがあります:
Deploymentやその他のPodを管理するコントローラーの削除
再起動を伴うDeployment内のPodのテンプレートの更新
Podの直接削除(例:アクシデントによって)
クラスター管理者のアクションには、次のようなものが含まれます:
修復やアップグレードのためのノードのドレイン 。
クラスターのスケールダウンのためにクラスターからノードをドレインする(クラスター自動スケーリング について学ぶ)。
そのノードに別のものを割り当てることができるように、ノードからPodを削除する。
これらのアクションはクラスター管理者によって直接実行されるか、クラスター管理者やクラスターをホスティングしているプロバイダーによって自動的に実行される可能性があります。
クラスターに対して自発的なDisruptionの要因となるものが有効になっているかどうかについては、クラスター管理者に聞くか、クラウドプロバイダーに相談または配布文書を参照してください。
有効になっているものが何もなければ、Pod Disruption Budgetの作成はスキップすることができます。
注意: 全ての自発的なDisruptionがPod Disruption Budgetによる制約を受けるわけではありません。
例えばDeploymentやPodの削除はPod Disruption Budgetをバイパスします。
Disruptionへの対応
非自発的なDisruptionを軽減する方法をいくつか紹介します:
Podは必要なリソースを要求 するようにする。
高可用性が必要な場合はアプリケーションをレプリケートする。(レプリケートされたステートレス およびステートフル アプリケーションの実行について学ぶ。)
レプリケートされたアプリケーションを実行する際にさらに高い可用性を得るには、(アンチアフィニティ を使って)ラックを横断して、または(マルチゾーンクラスター を使用している場合には)ゾーンを横断してアプリケーションを分散させる。
自発的なDisruptionの頻度は様々です。
基本的なKubernetesクラスターでは、自動で発生する自発的なDisruptionはありません(ユーザーによってトリガーされたものだけです)。
しかし、クラスター管理者やホスティングプロバイダーが何か追加のサービスを実行して自発的なDisruptionが発生する可能性があります。
例えば、ノード上のソフトウェアアップデートのロールアウトは自発的なDisruptionの原因となります。
また、クラスター(ノード)自動スケーリングの実装の中には、ノードのデフラグとコンパクト化のために自発的なDisruptionを伴うものがあります。
クラスタ管理者やホスティングプロバイダーは、自発的なDisruptionがある場合、どの程度のDisruptionが予想されるかを文書化しているはずです。
Podのspecの中でPriorityClassesを使用している 場合など、特定の設定オプションによっても自発的(および非自発的)なDisruptionを引き起こす可能性があります。
Pod Disruption Budget
FEATURE STATE: Kubernetes v1.21 [stable]
Kubernetesは、自発的なDisruptionが頻繁に発生する場合でも、可用性の高いアプリケーションの運用を支援する機能を提供しています。
アプリケーションの所有者として、各アプリケーションに対してPodDisruptionBudget (PDB)を作成することができます。
PDBは、レプリカを持っているアプリケーションのうち、自発的なDisruptionによって同時にダウンするPodの数を制限します。
例えば、クォーラムベースのアプリケーションでは、実行中のレプリカの数がクォーラムに必要な数を下回らないようにする必要があります。
Webフロントエンドは、負荷に対応するレプリカの数が、全体に対して一定の割合を下回らないようにしたいかもしれません。
クラスター管理者やホスティングプロバイダーは、直接PodやDeploymentを削除するのではなく、Eviction API を呼び出す、PodDisruptionBudgetsに配慮したツールを使用すべきです。
例えば、kubectl drainサブコマンドはノードを休止中とマークします。
kubectl drainを実行すると、ツールは休止中としたノード上の全てのPodを退避しようとします。
kubectlがあなたの代わりに送信する退避要求は一時的に拒否される可能性があるため、ツールは対象のノード上の全てのPodが終了するか、設定可能なタイムアウト時間に達するまで、全ての失敗した要求を定期的に再試行します。
PDBはアプリケーションの意図したレプリカ数に対して、許容できるレプリカの数を指定します。
例えば.spec.replicas: 5を持つDeploymentは常に5つのPodを持つことが想定されます。
PDBが同時に4つまでを許容する場合、Eviction APIは1度に(2つではなく)1つのPodの自発的なDisruptionを許可します。
アプリケーションを構成するPodのグループは、アプリケーションのコントローラー(Deployment、StatefulSetなど)が使用するものと同じラベルセレクターを使用して指定されます。
"意図した"Podの数は、これらのPodを管理するワークロードリソースの.spec.replicasから計算されます。
コントロールプレーンはPodの.metadata.ownerReferencesを調べることで、所有しているワークロードリソースを見つけます。
非自発的なDisruption はPDBによって防ぐことができません;
しかし、予算にはカウントされます。
アプリケーションのローリングアップデートによって削除または利用できなくなったPodはDisruptionの予算にカウントされますが、ローリングアップグレードを実行している時は(DeploymentやStatefulSetなどの)ワークロードリソースはPDBによって制限されません。
代わりに、アプリケーションのアップデート中の障害のハンドリングは、個々のワークロードリソースに対するspecで設定されます。
ノードのドレイン中に動作がおかしくなったアプリケーションの退避をサポートするために、Unhealthy Pod Eviction Policy にAlwaysAllowを設定することを推奨します。
既定の動作は、ドレインを継続する前にアプリケーションPodがhealthy な状態になるまで待機します。
Eviction APIを使用してPodを退避した場合、PodSpec で設定したterminationGracePeriodSecondsに従って正常に終了 します。
PodDisruptionBudgetの例
node-1からnode-3まで3つのノードがあるクラスターを考えます。
クラスターにはいくつかのアプリケーションが動いています。
それらのうちの1つは3つのレプリカを持ち、最初はpod-a、pod-bそしてpod-cと名前が付いています。
もう一つ、これとは独立したPDBなしのpod-xと呼ばれるものもあります。
初期状態ではPodは次のようにレイアウトされています:
node-1
node-2
node-3
pod-a available
pod-b available
pod-c available
pod-x available
3つのPodはすべてDeploymentの一部で、これらはまとめて1つのPDBを持ち、3つのPodのうちの少なくとも2つが常に存在していることを要求します。
例えばクラスター管理者がカーネルのバグを修正するために、再起動して新しいカーネルバージョンにしたいとします。
クラスター管理者はまず、kubectl drainコマンドを使ってnode-1をドレインしようとします。
ツールはpod-aとpod-xを退避しようとします。
これはすぐに成功します。
2つのPodは同時にterminating状態になります。
これにより、クラスターは次のような状態になります:
node-1 draining
node-2
node-3
pod-a terminating
pod-b available
pod-c available
pod-x terminating
DeploymentはPodの1つが終了中であることに気づき、pod-dという代わりのPodを作成します。
node-1はcordonされたため、別のノードに展開されます。
また、pod-xの代わりとしてpod-yも作られました。
(備考: StatefulSetの場合、pod-aはpod-0のように呼ばれ、代わりのPodが作成される前に完全に終了する必要があります。
この代わりのPodは、UIDは異なりますが、同じpod-0という名前になります。
それを除けば、本例はStatefulSetにも当てはまります。)
現在、クラスターは次のような状態になっています:
node-1 draining
node-2
node-3
pod-a terminating
pod-b available
pod-c available
pod-x terminating
pod-d starting
pod-y
ある時点でPodは終了し、クラスターはこのようになります:
node-1 drained
node-2
node-3
pod-b available
pod-c available
pod-d starting
pod-y
この時点で、せっかちなクラスター管理者がnode-2かnode-3をドレインしようとすると、Deploymentの利用可能なPodは2つしかなく、また、PDBによって最低2つのPodが要求されているため、drainコマンドはブロックされます。
しばらくすると、pod-dが使用可能になります。
クラスターの状態はこのようになります:
node-1 drained
node-2
node-3
pod-b available
pod-c available
pod-d available
pod-y
ここでクラスター管理者がnode-2をドレインしようとします。
drainコマンドは2つのPodをなんらかの順番で退避しようとします。
例えば最初にpod-b、次にpod-dとします。
pod-bについては退避に成功します。
しかしpod-dを退避しようとすると、Deploymentに対して利用可能なPodは1つしか残らないため、退避は拒否されます。
Deploymentはpod-bの代わりとしてpod-eを作成します。
クラスターにはpod-eをスケジューリングする十分なリソースがないため、ドレインは再びブロックされます。
クラスターは次のような状態になります:
node-1 drained
node-2
node-3
no node
pod-b terminating
pod-c available
pod-e pending
pod-d available
pod-y
この時点で、クラスター管理者はアップグレードを継続するためにクラスターにノードを追加する必要があります。
KubernetesがどのようにDisruptionの発生率を変化させているかについては、次のようなものから知ることができます:
いくつのレプリカをアプリケーションが必要としているか
インスタンスのグレースフルシャットダウンにどれくらいの時間がかかるか
新しいインスタンスのスタートアップにどれくらいの時間がかかるか
コントローラーの種類
クラスターリソースのキャパシティ
Pod Disruption Condition
FEATURE STATE: Kubernetes v1.26 [beta]
備考: この機能を使用するためには、クラスターで
フィーチャーゲート PodDisruptionConditionsを有効にする必要があります。
有効にすると、専用のPod DisruptionTarget Condition が追加されます。
これはPodがDisruption によって削除されようとしていることを示すものです。
Conditionのreasonフィールドにて、追加で以下のいずれかをPodの終了の理由として示します:
PreemptionBySchedulerPodはより高い優先度を持つ新しいPodを収容するために、スケジューラーによってプリエンプトされる 予定です。
詳細についてはPodの優先度とプリエンプション を参照してください。
DeletionByTaintManagerPodが許容しないNoExecute taintによって、Podは(kube-controller-managerの中のノードライフサイクルコントローラーである)Taintマネージャーによって削除される予定です。
taint ベースの退避を参照してください。
EvictionByEvictionAPIPodはKubernetes APIを使用して退避するように マークされました。
DeletionByPodGCすでに存在しないノードに紐づいているPodのため、Podのガベージコレクション によって削除される予定です。
TerminationByKubeletnode-pressureによる退避 またはGraceful Node Shutdown のため、Podはkubeletによって終了させられました。
備考: PodのDisruptionは一時停止する場合があります。
コントロールプレーンは同じPodに対するDisruptionを継続するために再試行するかもしれませんが、保証はされていません。
その結果、DisruptionTarget ConditionはPodに付与されるかもしれませんが、実際にはPodは削除されていない可能性があります。
そのような状況の場合、しばらくすると、Pod Disruption Conditionはクリアされます。
フィーチャーゲートPodDisruptionConditionsを有効にすると、Podのクリーンアップと共に、Podガベージコレクタ(PodGC)が非終了フェーズにあるPodを失敗とマークします。
(Podガベージコレクション も参照してください)。
Job(またはCronJob)を使用している場合、JobのPod失敗ポリシー の一部としてこれらのPod Disruption Conditionを使用したいと思うかもしれません。
クラスターオーナーとアプリケーションオーナーロールの分離
多くの場合、クラスター管理者とアプリケーションオーナーは、互いの情報を一部しか持たない別の役割であると考えるのが便利です。
このような責任の分離は、次のようなシナリオで意味を持つことがあります:
多くのアプリケーションチームでKubernetesクラスターを共有していて、役割の専門化が自然に行われている場合
クラスター管理を自動化するためにサードパーティのツールやサービスを使用している場合
Pod Disruption Budgetはロール間のインターフェースを提供することによって、この役割の分離をサポートします。
もしあなたの組織でこのような責任の分担がなされていない場合は、Pod Disruption Budgetを使用する必要はないかもしれません。
クラスターで破壊的なアクションを実行する方法
あなたがクラスターの管理者で、ノードやシステムソフトウェアのアップグレードなど、クラスター内のすべてのノードに対して破壊的なアクションを実行する必要がある場合、次のような選択肢があります:
アップグレードの間のダウンタイムを許容する。
もう一つの完全なレプリカクラスターにフェールオーバーする。
ダウンタイムはありませんが、重複するノードと、切り替えを調整する人的労力の両方のコストがかかる可能性があります。
Disruptionに耐性のあるアプリケーションを書き、PDBを使用する。
ダウンタイムはありません。
リソースの重複は最小限です。
クラスター管理をより自動化できます。
Disruptionに耐えうるアプリケーションを書くことは大変ですが、自発的なDisruptionに耐えうるようにするための作業は、非自発的なDisruptionに耐えうるために必要な作業とほぼ重複しています。
次の項目
4.1.5 - エフェメラルコンテナ
FEATURE STATE: Kubernetes v1.16 [alpha]
このページでは、特別な種類のコンテナであるエフェメラルコンテナの概要を説明します。エフェメラルコンテナは、トラブルシューティングなどのユーザーが開始するアクションを実行するために、すでに存在するPod 内で一時的に実行するコンテナです。エフェメラルコンテナは、アプリケーションの構築ではなく、serviceの調査のために利用します。
警告: エフェメラルコンテナは初期のアルファ状態であり、本番クラスターには適しません。
Kubernetesの非推奨ポリシー に従って、このアルファ機能は、将来大きく変更されたり、完全に削除される可能性があります。
エフェメラルコンテナを理解する
Pod は、Kubernetesのアプリケーションの基本的なビルディングブロックです。Podは破棄可能かつ置き換え可能であることが想定されているため、一度Podが作成されると新しいコンテナを追加することはできません。その代わりに、通常はDeployment を使用してPodを削除して置き換えます。
たとえば、再現困難なバグのトラブルシューティングなどのために、すでに存在するPodの状態を調査する必要が出てくることがあります。このような場合、既存のPod内でエフェメラルコンテナを実行することで、Podの状態を調査したり、任意のコマンドを実行したりできます。
エフェメラルコンテナとは何か?
エフェメラルコンテナは、他のコンテナと異なり、リソースや実行が保証されず、自動的に再起動されることも決してないため、アプリケーションを構築する目的には適しません。エフェメラルコンテナは、通常のコンテナと同じContainerSpecで記述されますが、多くのフィールドに互換性がなかったり、使用できなくなっています。
エフェメラルコンテナはポートを持つことができないため、ports、livenessProbe、readinessProbeなどは使えなくなっています。
Podリソースの割り当てはイミュータブルであるため、resourcesの設定が禁止されています。
利用が許可されているフィールドの一覧については、EphemeralContainerのリファレンスドキュメント を参照してください。
エフェメラルコンテナは、直接pod.specに追加するのではなく、API内の特別なephemeralcontainersハンドラを使用して作成します。そのため、エフェメラルコンテナをkubectl editを使用して追加することはできません。
エフェメラルコンテナをPodに追加した後は、通常のコンテナのようにエフェメラルコンテナを変更または削除することはできません。
エフェメラルコンテナの用途
エフェメラルコンテナは、コンテナがクラッシュしてしまったり、コンテナイメージにデバッグ用ユーティリティが同梱されていない場合など、kubectl execでは不十分なときにインタラクティブなトラブルシューティングを行うために役立ちます。
特に、distrolessイメージ を利用すると、攻撃対象領域を減らし、バグや脆弱性を露出する可能性を減らせる最小のコンテナイメージをデプロイできるようになります。distrolessイメージにはシェルもデバッグ用のユーティリティも含まれないため、kubectl execのみを使用してdistrolessイメージのトラブルシューティングを行うのは困難です。
エフェメラルコンテナを利用する場合には、他のコンテナ内のプロセスにアクセスできるように、プロセス名前空間の共有 を有効にすると便利です。
エフェメラルコンテナを利用してトラブルシューティングを行う例については、デバッグ用のエフェメラルコンテナを使用してデバッグする を参照してください。
Ephemeral containers API
備考: このセクションの例を実行するには、
EphemeralContainersフィーチャーゲート を有効にして、Kubernetesクライアントとサーバーのバージョンをv1.16以上にする必要があります。
このセクションの例では、API内でエフェメラルコンテナを表示する方法を示します。通常は、APIを直接呼び出すのではなく、kubectl alpha debugやその他のkubectlプラグイン を使用して、これらのステップを自動化します。
エフェメラルコンテナは、Podのephemeralcontainersサブリソースを使用して作成されます。このサブリソースは、kubectl --rawを使用して確認できます。まずはじめに、以下にEphemeralContainersリストとして追加するためのエフェメラルコンテナを示します。
{
"apiVersion" : "v1" ,
"kind" : "EphemeralContainers" ,
"metadata" : {
"name" : "example-pod"
},
"ephemeralContainers" : [{
"command" : [
"sh"
],
"image" : "busybox" ,
"imagePullPolicy" : "IfNotPresent" ,
"name" : "debugger" ,
"stdin" : true ,
"tty" : true ,
"terminationMessagePolicy" : "File"
}]
}
すでに実行中のexample-podのエフェメラルコンテナを更新するには、次のコマンドを実行します。
kubectl replace --raw /api/v1/namespaces/default/pods/example-pod/ephemeralcontainers -f ec.json
このコマンドを実行すると、新しいエフェメラルコンテナのリストが返されます。
{
"kind" :"EphemeralContainers" ,
"apiVersion" :"v1" ,
"metadata" :{
"name" :"example-pod" ,
"namespace" :"default" ,
"selfLink" :"/api/v1/namespaces/default/pods/example-pod/ephemeralcontainers" ,
"uid" :"a14a6d9b-62f2-4119-9d8e-e2ed6bc3a47c" ,
"resourceVersion" :"15886" ,
"creationTimestamp" :"2019-08-29T06:41:42Z"
},
"ephemeralContainers" :[
{
"name" :"debugger" ,
"image" :"busybox" ,
"command" :[
"sh"
],
"resources" :{
},
"terminationMessagePolicy" :"File" ,
"imagePullPolicy" :"IfNotPresent" ,
"stdin" :true ,
"tty" :true
}
]
}
新しく作成されたエフェメラルコンテナの状態を確認するには、kubectl describeを使用します。
kubectl describe pod example-pod
...
Ephemeral Containers:
debugger:
Container ID: docker://cf81908f149e7e9213d3c3644eda55c72efaff67652a2685c1146f0ce151e80f
Image: busybox
Image ID: docker-pullable://busybox@sha256:9f1003c480699be56815db0f8146ad2e22efea85129b5b5983d0e0fb52d9ab70
Port: <none>
Host Port: <none>
Command:
sh
State: Running
Started: Thu, 29 Aug 2019 06:42:21 +0000
Ready: False
Restart Count: 0
Environment: <none>
Mounts: <none>
...
新しいエフェメラルコンテナとやりとりをするには、他のコンテナと同じように、kubectl attach、kubectl exec、kubectl logsなどのコマンドが利用できます。例えば、次のようなコマンドが実行できます。
kubectl attach -it example-pod -c debugger
4.2 - ワークロードリソース
4.2.1 - Deployment
Deployment はPod とReplicaSet の宣言的なアップデート機能を提供します。
Deploymentにおいて 理想的な状態 を記述すると、Deploymentコントローラー は指定された頻度で現在の状態を理想的な状態に変更します。Deploymentを定義することによって、新しいReplicaSetを作成したり、既存のDeploymentを削除して新しいDeploymentで全てのリソースを適用できます。
備考: Deploymentによって作成されたReplicaSetを管理しないでください。ご自身のユースケースが以下の項目に含まれない場合、メインのKubernetesリポジトリーにIssueを作成することを検討してください。
ユースケース
以下の項目はDeploymentの典型的なユースケースです。
Deploymentの作成
以下はDeploymentの例です。これはnginxPodのレプリカを3つ持つReplicaSetを作成します。
apiVersion : apps/v1
kind : Deployment
metadata :
name : nginx-deployment
labels :
app : nginx
spec :
replicas : 3
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
この例では、
.metadata.nameフィールドで指定されたnginx-deploymentという名前のDeploymentが作成されます。
このDeploymentは.spec.replicasフィールドで指定された通り、3つのレプリカPodを作成します。
.spec.selectorフィールドは、Deploymentが管理するPodのラベルを定義します。ここでは、Podテンプレートにて定義されたラベル(app: nginx)を選択しています。しかし、PodTemplate自体がそのルールを満たす限り、さらに洗練された方法でセレクターを指定することができます。
備考: `.spec.selector.matchLabels`フィールドはキーバリューペアのマップです。
`matchLabels`マップにおいて、{key, value}というペアは、keyというフィールドの値が"key"で、その演算子が"In"で、値の配列が"value"のみ含むような`matchExpressions`の要素と等しくなります。
`matchLabels`と`matchExpressions`の両方が設定された場合、条件に一致するには両方とも満たす必要があります。
templateフィールドは、以下のサブフィールドを持ちます。:
Podは.metadata.labelsフィールドによって指定されたapp: nginxというラベルがつけられます。
PodTemplate、または.template.specフィールドは、Podがnginxという名前でDocker Hub にあるnginxのバージョン1.14.2が動くコンテナを1つ動かすことを示します。
1つのコンテナを作成し、.spec.template.spec.containers[0].nameフィールドを使ってnginxという名前をつけます。
作成を始める前に、Kubernetesクラスターが稼働していることを確認してください。
上記のDeploymentを作成するためには以下のステップにしたがってください:
以下のコマンドを実行してDeploymentを作成してください。
kubectl apply -f https://k8s.io/examples/controllers/nginx-deployment.yaml
Deploymentが作成されたことを確認するために、kubectl get deploymentsを実行してください。
Deploymentがまだ作成中の場合、コマンドの実行結果は以下のとおりです。
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 0/3 0 0 1s
クラスターにてDeploymentを調査するとき、以下のフィールドが出力されます。
NAMEは、クラスター内にあるDeploymentの名前一覧です。READYは、ユーザーが使用できるアプリケーションのレプリカの数です。使用可能な数/理想的な数の形式で表示されます。UP-TO-DATEは、理想的な状態を満たすためにアップデートが完了したレプリカの数です。AVAILABLEは、ユーザーが利用可能なレプリカの数です。AGEは、アプリケーションが稼働してからの時間です。
.spec.replicasフィールドの値によると、理想的なレプリカ数は3であることがわかります。
Deploymentのロールアウトステータスを確認するために、kubectl rollout status deployment.v1.apps/nginx-deploymentを実行してください。
コマンドの実行結果は以下のとおりです。
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment "nginx-deployment" successfully rolled out
数秒後、再度kubectl get deploymentsを実行してください。
コマンドの実行結果は以下のとおりです。
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 18s
Deploymentが3つ全てのレプリカを作成して、全てのレプリカが最新(Podが最新のPodテンプレートを含んでいる)になり、利用可能となっていることを確認してください。
Deploymentによって作成されたReplicaSet(rs)を確認するにはkubectl get rsを実行してください。コマンドの実行結果は以下のとおりです:
NAME DESIRED CURRENT READY AGE
nginx-deployment-75675f5897 3 3 3 18s
ReplicaSetの出力には次のフィールドが表示されます:
NAMEは、名前空間内にあるReplicaSetの名前の一覧です。DESIREDは、アプリケーションの理想的な レプリカ の値です。これはDeploymentを作成したときに定義したもので、これが 理想的な状態 と呼ばれるものです。CURRENTは現在実行されているレプリカの数です。READYは、ユーザーが使用できるアプリケーションのレプリカの数です。AGEは、アプリケーションが稼働してからの時間です。
ReplicaSetの名前は[Deployment名]-[ランダム文字列]という形式になることに注意してください。ランダム文字列はランダムに生成され、pod-template-hashをシードとして使用します。
各Podにラベルが自動的に付けられるのを確認するにはkubectl get pods --show-labelsを実行してください。
コマンドの実行結果は以下のとおりです:
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-75675f5897-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
nginx-deployment-75675f5897-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=75675f5897
作成されたReplicaSetはnginxPodを3つ作成することを保証します。
備考: Deploymentに対して適切なセレクターとPodテンプレートのラベルを設定する必要があります(このケースではapp: nginx)。
ラベルやセレクターを他のコントローラーと重複させないでください(他のDeploymentやStatefulSetを含む)。Kubernetesはユーザーがラベルを重複させることを阻止しないため、複数のコントローラーでセレクターの重複が発生すると、コントローラー間で衝突し予期せぬふるまいをすることになります。
pod-template-hashラベル
注意: このラベルを変更しないでください。
pod-template-hashラベルはDeploymentコントローラーによってDeploymentが作成し適用した各ReplicaSetに対して追加されます。
このラベルはDeploymentが管理するReplicaSetが重複しないことを保証します。このラベルはReplicaSetのPodTemplateをハッシュ化することにより生成され、生成されたハッシュ値はラベル値としてReplicaSetセレクター、Podテンプレートラベル、ReplicaSetが作成した全てのPodに対して追加されます。
Deploymentの更新
備考: Deploymentのロールアウトは、DeploymentのPodテンプレート(この場合.spec.template)が変更された場合にのみトリガーされます。例えばテンプレートのラベルもしくはコンテナイメージが更新された場合です。Deploymentのスケールのような更新では、ロールアウトはトリガーされません。
Deploymentを更新するには以下のステップに従ってください。
nginxのPodで、nginx:1.14.2イメージの代わりにnginx:1.16.1を使うように更新します。
kubectl set image deployment.v1.apps/nginx-deployment nginx = nginx:1.16.1
または単に次のコマンドを使用します。
kubectl set image deployment/nginx-deployment nginx = nginx:1.16.1
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
また、Deploymentを編集して、.spec.template.spec.containers[0].imageをnginx:1.14.2からnginx:1.16.1に変更することができます。
kubectl edit deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment edited
ロールアウトのステータスを確認するには、以下のコマンドを実行してください。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
もしくは
deployment "nginx-deployment" successfully rolled out
更新されたDeploymentのさらなる情報を取得するには、以下を確認してください。
ロールアウトが成功したあと、kubectl get deploymentsを実行してDeploymentを確認できます。
実行結果は以下のとおりです。
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 36s
Deploymentが新しいReplicaSetを作成してPodを更新させたり、新しいReplicaSetのレプリカを3にスケールアップさせたり、古いReplicaSetのレプリカを0にスケールダウンさせるのを確認するにはkubectl get rsを実行してください。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 6s
nginx-deployment-2035384211 0 0 0 36s
get podsを実行させると、新しいPodのみ確認できます。
実行結果は以下のとおりです。
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-khku8 1/1 Running 0 14s
nginx-deployment-1564180365-nacti 1/1 Running 0 14s
nginx-deployment-1564180365-z9gth 1/1 Running 0 14s
次にPodを更新させたいときは、DeploymentのPodテンプレートを再度更新するだけです。
Deploymentは、Podが更新されている間に特定の数のPodのみ停止状態になることを保証します。デフォルトでは、目標とするPod数の少なくとも75%が稼働状態であることを保証します(25% max unavailable)。
また、DeploymentはPodが更新されている間に、目標とするPod数を特定の数まで超えてPodを稼働させることを保証します。デフォルトでは、目標とするPod数に対して最大でも125%を超えてPodを稼働させることを保証します(25% max surge)。
例えば、上記で説明したDeploymentの状態を注意深く見ると、最初に新しいPodが作成され、次に古いPodが削除されるのを確認できます。十分な数の新しいPodが稼働するまでは、Deploymentは古いPodを削除しません。また十分な数の古いPodが削除しない限り新しいPodは作成されません。少なくとも2つのPodが利用可能で、最大でもトータルで4つのPodが利用可能になっていることを保証します。
Deploymentの詳細情報を取得します。
kubectl describe deployments
実行結果は以下のとおりです。
Name: nginx-deployment
Namespace: default
CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=2
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0
最初にDeploymentを作成した時、ReplicaSet(nginx-deployment-2035384211)を作成してすぐにレプリカ数を3にスケールするのを確認できます。Deploymentを更新すると新しいReplicaSet(nginx-deployment-1564180365)を作成してレプリカ数を1にスケールアップし、古いReplicaSeetを2にスケールダウンさせます。これは常に最低でも2つのPodが利用可能で、かつ最大4つのPodが作成されている状態にするためです。Deploymentは同じローリングアップ戦略に従って新しいReplicaSetのスケールアップと古いReplicaSetのスケールダウンを続けます。最終的に新しいReplicaSetを3にスケールアップさせ、古いReplicaSetを0にスケールダウンさせます。
ロールオーバー (リアルタイムでの複数のPodの更新)
Deploymentコントローラーにより、新しいDeploymentが観測される度にReplicaSetが作成され、理想とするレプリカ数のPodを作成します。Deploymentが更新されると、既存のReplicaSetが管理するPodのラベルが.spec.selectorにマッチするが、テンプレートが.spec.templateにマッチしない場合はスケールダウンされます。最終的に、新しいReplicaSetは.spec.replicasの値にスケールアップされ、古いReplicaSetは0にスケールダウンされます。
Deploymentのロールアウトが進行中にDeploymentを更新すると、Deploymentは更新する毎に新しいReplicaSetを作成してスケールアップさせ、以前にスケールアップしたReplicaSetのロールオーバーを行います。Deploymentは更新前のReplicaSetを古いReplicaSetのリストに追加し、スケールダウンを開始します。
例えば、5つのレプリカを持つnginx:1.14.2のDeploymentを作成し、nginx:1.14.2の3つのレプリカが作成されているときに5つのレプリカを持つnginx:1.16.1に更新します。このケースではDeploymentは作成済みのnginx:1.14.2の3つのPodをすぐに削除し、nginx:1.16.1のPodの作成を開始します。nginx:1.14.2の5つのレプリカを全て作成するのを待つことはありません。
ラベルセレクターの更新
通常、ラベルセレクターを更新することは推奨されません。事前にラベルセレクターの使い方を計画しておきましょう。いかなる場合であっても更新が必要なときは十分に注意を払い、変更時の影響範囲を把握しておきましょう。
備考: apps/v1API バージョンにおいて、Deploymentのラベルセレクターは作成後に不変となります。
セレクターの追加は、Deployment Specのテンプレートラベルも新しいラベルで更新する必要があります。そうでない場合はバリデーションエラーが返されます。この変更は重複がない更新となります。これは新しいセレクターは古いセレクターを持つReplicaSetとPodを選択せず、結果として古い全てのReplicaSetがみなし子状態になり、新しいReplicaSetを作成することを意味します。
セレクターの更新により、セレクターキー内の既存の値が変更されます。これにより、セレクターの追加と同じふるまいをします。
セレクターの削除により、Deploymentのセレクターから存在している値を削除します。これはPodテンプレートのラベルに関する変更を要求しません。既存のReplicaSetはみなし子状態にならず、新しいReplicaSetは作成されませんが、削除されたラベルは既存のPodとReplicaSetでは残り続けます。
Deploymentのロールバック
例えば、クラッシュループ状態などのようにDeploymentが不安定な場合においては、Deploymentをロールバックしたくなることがあります。Deploymentの全てのロールアウト履歴は、いつでもロールバックできるようにデフォルトでシステムに保持されています(リビジョン履歴の上限は設定することで変更可能です)。
備考: Deploymentのリビジョンは、Deploymentのロールアウトがトリガーされた時に作成されます。これはDeploymentのPodテンプレート(.spec.template)が変更されたときのみ新しいリビジョンが作成されることを意味します。Deploymentのスケーリングなど、他の種類の更新においてはDeploymentのリビジョンは作成されません。これは手動もしくはオートスケーリングを同時に行うことができるようにするためです。これは過去のリビジョンにロールバックするとき、DeploymentのPodテンプレートの箇所のみロールバックされることを意味します。
nginx:1.16.1の代わりにnginx:1.161というイメージに更新して、Deploymentの更新中にタイプミスをしたと仮定します。
kubectl set image deployment/nginx-deployment nginx = nginx:1.161
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
このロールアウトはうまくいきません。ロールアウトのステータスを見るとそれを確認できます。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
ロールアウトのステータスの確認は、Ctrl-Cを押すことで停止できます。ロールアウトがうまく行かないときは、Deploymentのステータス を読んでさらなる情報を得てください。
古いレプリカ数(nginx-deployment-1564180365 and nginx-deployment-2035384211)が2になっていることを確認でき、新しいレプリカ数(nginx-deployment-3066724191)は1になっています。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 25s
nginx-deployment-2035384211 0 0 0 36s
nginx-deployment-3066724191 1 1 0 6s
作成されたPodを確認していると、新しいReplicaSetによって作成された1つのPodはコンテナイメージのpullに失敗し続けているのがわかります。
実行結果は以下のとおりです。
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-70iae 1/1 Running 0 25s
nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s
nginx-deployment-1564180365-hysrc 1/1 Running 0 25s
nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s
備考: Deploymentコントローラーは、この悪い状態のロールアウトを自動的に停止し、新しいReplicaSetのスケールアップを止めます。これはユーザーが指定したローリングアップデートに関するパラメーター(特に`maxUnavailable`)に依存します。デフォルトではKubernetesがこの値を25%に設定します。
Deploymentの詳細情報を取得します。
kubectl describe deployment
実行結果は以下のとおりです。
Name: nginx-deployment
Namespace: default
CreationTimestamp: Tue, 15 Mar 2016 14:48:04 -0700
Labels: app=nginx
Selector: app=nginx
Replicas: 3 desired | 1 updated | 4 total | 3 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.161
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
OldReplicaSets: nginx-deployment-1564180365 (3/3 replicas created)
NewReplicaSet: nginx-deployment-3066724191 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-2035384211 to 3
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 1
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 2
22s 22s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 2
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 1
21s 21s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-1564180365 to 3
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled down replica set nginx-deployment-2035384211 to 0
13s 13s 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set nginx-deployment-3066724191 to 1
これを修正するために、Deploymentを安定した状態の過去のリビジョンに更新する必要があります。
Deploymentのロールアウト履歴の確認
ロールアウトの履歴を確認するには、以下の手順に従って下さい。
最初に、Deploymentのリビジョンを確認します。
kubectl rollout history deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl apply --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml
2 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1
3 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.161
CHANGE-CAUSEはリビジョンの作成時にDeploymentのkubernetes.io/change-causeアノテーションからリビジョンにコピーされます。以下の方法によりCHANGE-CAUSEメッセージを指定できます。
kubectl annotate deployment.v1.apps/nginx-deployment kubernetes.io/change-cause="image updated to 1.16.1"の実行によりアノテーションを追加します。リソースのマニフェストを手動で編集します。
各リビジョンの詳細を確認するためには以下のコマンドを実行してください。
kubectl rollout history deployment.v1.apps/nginx-deployment --revision= 2
実行結果は以下のとおりです。
deployments "nginx-deployment" revision 2
Labels: app=nginx
pod-template-hash=1159050644
Annotations: kubernetes.io/change-cause=kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
QoS Tier:
cpu: BestEffort
memory: BestEffort
Environment Variables: <none>
No volumes.
過去のリビジョンにロールバックする
現在のリビジョンから過去のリビジョン(リビジョン番号2)にロールバックさせるには、以下の手順に従ってください。
現在のリビジョンから過去のリビジョンにロールバックします。
kubectl rollout undo deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment rolled back
その他に、--to-revisionを指定することにより特定のリビジョンにロールバックできます。
kubectl rollout undo deployment.v1.apps/nginx-deployment --to-revision= 2
実行結果は以下のとおりです。
deployment.apps/nginx-deployment rolled back
ロールアウトに関連したコマンドのさらなる情報はkubectl rollout
Deploymentが過去の安定したリビジョンにロールバックされました。Deploymentコントローラーによって、リビジョン番号2にロールバックするDeploymentRollbackイベントが作成されたのを確認できます。
ロールバックが成功し、Deploymentが正常に稼働していることを確認するために、以下のコマンドを実行してください。
kubectl get deployment nginx-deployment
実行結果は以下のとおりです。
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 30m
Deploymentの詳細情報を取得します。
kubectl describe deployment nginx-deployment
実行結果は以下のとおりです。
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=4
kubernetes.io/change-cause=kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.16.1
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.16.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1
Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2
Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
Deploymentのスケーリング
以下のコマンドを実行させてDeploymentをスケールできます。
kubectl scale deployment.v1.apps/nginx-deployment --replicas= 10
実行結果は以下のとおりです。
deployment.apps/nginx-deployment scaled
クラスター内で水平Podオートスケーラー が有効になっていると仮定します。ここでDeploymentのオートスケーラーを設定し、稼働しているPodのCPU使用量に基づいて、稼働させたいPodのレプリカ数の最小値と最大値を設定できます。
kubectl autoscale deployment.v1.apps/nginx-deployment --min= 10 --max= 15 --cpu-percent= 80
実行結果は以下のとおりです。
deployment.apps/nginx-deployment scaled
比例スケーリング
Deploymentのローリングアップデートは、同時に複数のバージョンのアプリケーションの稼働をサポートします。ユーザーやオートスケーラーがローリングアップデートをロールアウト中(更新中もしくは一時停止中)のDeploymentに対して行うと、Deploymentコントローラーはリスクを削減するために既存のアクティブなReplicaSetのレプリカのバランシングを行います。これを比例スケーリング と呼びます。
レプリカ数が10、maxSurge =3、maxUnavailable =2であるDeploymentが稼働している例です。
Deployment内で10のレプリカが稼働していることを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 10 10 10 10 50s
クラスター内で、解決できない新しいイメージに更新します。
kubectl set image deployment.v1.apps/nginx-deployment nginx = nginx:sometag
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
イメージの更新は新しいReplicaSet nginx-deployment-1989198191へのロールアウトを開始させます。しかしロールアウトは、上述したmaxUnavailableの要求によりブロックされます。ここでロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 5 5 0 9s
nginx-deployment-618515232 8 8 8 1m
次にDeploymentのスケーリングをするための新しい要求が発生します。オートスケーラーはDeploymentのレプリカ数を15に増やします。Deploymentコントローラーは新しい5つのレプリカをどこに追加するか決める必要がでてきます。比例スケーリングを使用していない場合、5つのレプリカは全て新しいReplicaSetに追加されます。比例スケーリングでは、追加されるレプリカは全てのReplicaSetに分散されます。比例割合が大きいものはレプリカ数の大きいReplicaSetとなり、比例割合が低いときはレプリカ数の小さいReplicaSetとなります。残っているレプリカはもっとも大きいレプリカ数を持つReplicaSetに追加されます。レプリカ数が0のReplicaSetはスケールアップされません。
上記の例では、3つのレプリカが古いReplicaSetに追加され、2つのレプリカが新しいReplicaSetに追加されました。ロールアウトの処理では、新しいレプリカ数のPodが正常になったと仮定すると、最終的に新しいReplicaSetに全てのレプリカを移動させます。これを確認するためには以下のコマンドを実行して下さい。
実行結果は以下のとおりです。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
ロールアウトのステータスでレプリカがどのように各ReplicaSetに追加されるか確認できます。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
Deployment更新の一時停止と再開
ユーザーは1つ以上の更新処理をトリガーする前に更新の一時停止と再開ができます。これにより、不必要なロールアウトを実行することなく一時停止と再開を行う間に複数の修正を反映できます。
例えば、作成直後のDeploymentを考えます。
Deploymentの詳細情報を確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 3 3 3 3 1m
ロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 1m
以下のコマンドを実行して更新処理の一時停止を行います。
kubectl rollout pause deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment paused
次にDeploymentのイメージを更新します。
kubectl set image deployment.v1.apps/nginx-deployment nginx = nginx:1.16.1
実行結果は以下のとおりです。
deployment.apps/nginx-deployment image updated
新しいロールアウトが開始されていないことを確認します。
kubectl rollout history deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployments "nginx"
REVISION CHANGE-CAUSE
1 <none>
Deploymentの更新に成功したことを確認するためにロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 2m
更新は何度でも実行できます。例えば、Deploymentが使用するリソースを更新します。
kubectl set resources deployment.v1.apps/nginx-deployment -c= nginx --limits= cpu = 200m,memory= 512Mi
実行結果は以下のとおりです。
deployment.apps/nginx-deployment resource requirements updated
一時停止する前の初期状態では更新処理は機能しますが、Deploymentが一時停止されている間は新しい更新処理は反映されません。
最後に、Deploymentの稼働を再開させ、新しいReplicaSetが更新内容を全て反映させているのを確認します。
kubectl rollout resume deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
deployment.apps/nginx-deployment resumed
更新処理が完了するまでロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 2 2 2 2m
nginx-3926361531 2 2 0 6s
nginx-3926361531 2 2 1 18s
nginx-2142116321 1 2 2 2m
nginx-2142116321 1 2 2 2m
nginx-3926361531 3 2 1 18s
nginx-3926361531 3 2 1 18s
nginx-2142116321 1 1 1 2m
nginx-3926361531 3 3 1 18s
nginx-3926361531 3 3 2 19s
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 20s
最新のロールアウトのステータスを確認します。
実行結果は以下のとおりです。
NAME DESIRED CURRENT READY AGE
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 28s
備考: Deploymentの稼働を再開させない限り、一時停止したDeploymentをロールバックすることはできません。
Deploymentのステータス
Deploymentは、そのライフサイクルの間に様々な状態に遷移します。新しいReplicaSetへのロールアウト中は進行中 になり、その後は完了 し、また失敗 にもなります。
Deploymentの更新処理
以下のタスクが実行中のとき、KubernetesはDeploymentの状態を 進行中 にします。
Deploymentが新しいReplicaSetを作成します。
Deploymentが新しいReplicaSetをスケールアップさせています。
Deploymentが古いReplicaSetをスケールダウンさせています。
新しいPodが準備中もしくは利用可能な状態になります(少なくともMinReadySeconds の間は準備中になります)。
kubectl rollout statusを実行すると、Deploymentの進行状態を確認できます。
Deploymentの更新処理の完了
Deploymentが以下の状態になったとき、KubernetesはDeploymentのステータスを 完了 にします。
Deploymentの全てのレプリカが、指定された最新のバージョンに更新されます。これは指定した更新処理が完了したことを意味します。
Deploymentの全てのレプリカが利用可能になります。
Deploymentの古いレプリカが1つも稼働していません。
kubectl rollout statusを実行して、Deploymentの更新が完了したことを確認できます。ロールアウトが正常に完了するとkubectl rollout statusの終了コードが0で返されます。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 2 of 3 updated replicas are available...
deployment "nginx-deployment" successfully rolled out
そしてkubectl rolloutの終了ステータスが0となります(成功です):
0
Deploymentの更新処理の失敗
新しいReplicaSetのデプロイが完了せず、更新処理が止まる場合があります。これは主に以下の要因によるものです。
不十分なリソースの割り当て
ReadinessProbeの失敗
コンテナイメージの取得ができない
不十分なパーミッション
リソースリミットのレンジ
アプリケーションランタイムの設定の不備
このような状況を検知する1つの方法として、Deploymentのリソース定義でデッドラインのパラメーターを指定します(.spec.progressDeadlineSeconds.spec.progressDeadlineSecondsはDeploymentの更新が停止したことを示す前にDeploymentコントローラーが待つ秒数を示します。
以下のkubectlコマンドでリソース定義にprogressDeadlineSecondsを設定します。これはDeploymentの更新が止まってから10分後に、コントローラーが失敗を通知させるためです。
kubectl patch deployment.v1.apps/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}'
実行結果は以下のとおりです。
deployment.apps/nginx-deployment patched
一度デッドラインを超過すると、DeploymentコントローラーはDeploymentの.status.conditionsに以下のDeploymentConditionを追加します。
Type=Progressing
Status=False
Reason=ProgressDeadlineExceeded
ステータスの状態に関するさらなる情報はKubernetes APIの規則 を参照してください。
備考: Kubernetesは停止状態のDeploymentに対して、ステータス状態を報告する以外のアクションを実行しません。高レベルのオーケストレーターはこれを利用して、状態に応じて行動できます。例えば、前のバージョンへのDeploymentのロールバックが挙げられます。
備考: Deploymentを停止すると、Kubernetesは指定したデッドラインを超えたかどうかチェックしません。
ロールアウトの途中でもDeploymentを安全に一時停止でき、デッドラインを超えたイベントをトリガーすることなく再開できます。
設定したタイムアウトの秒数が小さかったり、一時的なエラーとして扱える他の種類のエラーが原因となり、Deploymentで一時的なエラーが出る場合があります。例えば、リソースの割り当てが不十分な場合を考えます。Deploymentの詳細情報を確認すると、以下のセクションが表示されます。
kubectl describe deployment nginx-deployment
実行結果は以下のとおりです。
<...>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True ReplicaSetUpdated
ReplicaFailure True FailedCreate
<...>
kubectl get deployment nginx-deployment -o yamlを実行すると、Deploymentのステータスは以下のようになります。
status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2
最後に、一度Deploymentの更新処理のデッドラインを越えると、KubernetesはDeploymentのステータスと進行中の状態を更新します。
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
Deploymentか他のリソースコントローラーのスケールダウンを行うか、使用している名前空間内でリソースの割り当てを増やすことで、リソースの割り当て不足の問題に対処できます。割り当て条件を満たすと、DeploymentコントローラーはDeploymentのロールアウトを完了させ、Deploymentのステータスが成功状態になるのを確認できます(Status=TrueとReason=NewReplicaSetAvailable)。
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
Status=TrueのType=Availableは、Deploymentが最小可用性の状態であることを意味します。最小可用性は、Deploymentの更新戦略において指定されているパラメーターにより決定されます。Status=TrueのType=Progressingは、Deploymentのロールアウトの途中で、更新処理が進行中であるか、更新処理が完了し、必要な最小数のレプリカが利用可能であることを意味します(各TypeのReason項目を確認してください。このケースでは、Reason=NewReplicaSetAvailableはDeploymentの更新が完了したことを意味します)。
kubectl rollout statusを実行してDeploymentが更新に失敗したかどうかを確認できます。kubectl rollout statusはDeploymentが更新処理のデッドラインを超えたときに0以外の終了コードを返します。
kubectl rollout status deployment.v1.apps/nginx-deployment
実行結果は以下のとおりです。
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
error: deployment "nginx" exceeded its progress deadline
そしてkubectl rolloutの終了ステータスが1となります(エラーを示しています):
1
失敗したDeploymentの操作
更新完了したDeploymentに適用した全てのアクションは、更新失敗したDeploymentに対しても適用されます。スケールアップ、スケールダウンができ、前のリビジョンへのロールバックや、Deploymentのテンプレートに複数の更新を適用させる必要があるときは一時停止もできます。
古いリビジョンのクリーンアップポリシー
Deploymentが管理する古いReplicaSetをいくつ保持するかを指定するために、.spec.revisionHistoryLimitフィールドを設定できます。この値を超えた古いReplicaSetはバックグラウンドでガーベージコレクションの対象となって削除されます。デフォルトではこの値は10です。
備考: このフィールドを明示的に0に設定すると、Deploymentの全ての履歴を削除します。従って、Deploymentはロールバックできません。
カナリアパターンによるデプロイ
Deploymentを使って一部のユーザーやサーバーに対してリリースのロールアウトをしたい場合、リソースの管理 に記載されているカナリアパターンに従って、リリース毎に1つずつ、複数のDeploymentを作成できます。
Deployment Specの記述
他の全てのKubernetesの設定と同様に、Deploymentは.apiVersion、.kindや.metadataフィールドを必要とします。
設定ファイルの利用に関する情報はアプリケーションのデプロイ を参照してください。コンテナの設定に関してはリソースを管理するためのkubectlの使用 を参照してください。
Deploymentオブジェクトの名前は、有効なDNSサブドメイン名 でなければなりません。
Deploymentは.specセクション
Podテンプレート
.spec.templateと.spec.selectorは.specにおける必須のフィールドです。
.spec.templateはPodテンプレート です。これは.spec内でネストされていないことと、apiVersionやkindを持たないことを除いてはPod と同じスキーマとなります。
Podの必須フィールドに加えて、Deployment内のPodテンプレートでは適切なラベルと再起動ポリシーを設定しなくてはなりません。ラベルは他のコントローラーと重複しないようにしてください。ラベルについては、セレクター を参照してください。
.spec.template.spec.restartPolicyAlwaysに等しいときのみ許可されます。これはテンプレートで指定されていない場合のデフォルト値です。
レプリカ数
.spec.repliasは理想的なPodの数を指定するオプションのフィールドです。デフォルトは1です。
セレクター
.spec.selectorは必須フィールドで、Deploymentによって対象とされるPodのラベルセレクター を指定します。
.spec.selectorは.spec.template.metadata.labelsと一致している必要があり、一致しない場合はAPIによって拒否されます。
apps/v1バージョンにおいて、.spec.selectorと.metadata.labelsが指定されていない場合、.spec.template.metadata.labelsの値に初期化されません。そのため.spec.selectorと.metadata.labelsを明示的に指定する必要があります。またapps/v1のDeploymentにおいて.spec.selectorは作成後に不変になります。
Deploymentのテンプレートが.spec.templateと異なる場合や、.spec.replicasの値を超えてPodが稼働している場合、Deploymentはセレクターに一致するラベルを持つPodを削除します。Podの数が理想状態より少ない場合Deploymentは.spec.templateをもとに新しいPodを作成します。
備考: Deploymentのセレクターに一致するラベルを持つPodを直接作成したり、他のDeploymentやReplicaSetやReplicationControllerによって作成するべきではありません。作成してしまうと、最初のDeploymentがラベルに一致する新しいPodを作成したとみなされます。こうなったとしても、Kubernetesは処理を止めません。
セレクターが重複する複数のコントローラーを持つとき、そのコントローラーは互いに競合状態となり、正しくふるまいません。
更新戦略
.spec.strategyは古いPodから新しいPodに置き換える際の更新戦略を指定します。.spec.strategy.typeは"Recreate"もしくは"RollingUpdate"を指定できます。デフォルトは"RollingUpdate"です。
Deploymentの再作成
.spec.strategy.type==Recreateと指定されているとき、既存の全てのPodは新しいPodが作成される前に削除されます。
備考: これは更新のための作成の前にPodを停止する事を保証するだけです。Deploymentを更新する場合、古いリビジョンのPodは全てすぐに停止されます。削除に成功するまでは、新しいリビジョンのPodは作成されません。手動でPodを削除すると、ライフサイクルがReplicaSetに制御されているのですぐに置き換えが実施されます(たとえ古いPodがまだ停止中のステータスでも)。Podに"高々この程度の"保証を求めるならば
StatefulSet の使用を検討してください。
Deploymentのローリングアップデート
.spec.strategy.type==RollingUpdateと指定されているとき、DeploymentはローリングアップデートによりPodを更新します。ローリングアップデートの処理をコントロールするためにmaxUnavailableとmaxSurgeを指定できます。
Max Unavailable
.spec.strategy.rollingUpdate.maxUnavailableはオプションのフィールドで、更新処理において利用不可となる最大のPod数を指定します。値は絶対値(例: 5)を指定するか、理想状態のPodのパーセンテージを指定します(例: 10%)。パーセンテージを指定した場合、絶対値は小数切り捨てされて計算されます。.spec.strategy.rollingUpdate.maxSurgeが0に指定されている場合、この値を0にできません。デフォルトでは25%です。
例えば、この値が30%と指定されているとき、ローリングアップデートが開始すると古いReplicaSetはすぐに理想状態の70%にスケールダウンされます。一度新しいPodが稼働できる状態になると、古いReplicaSetはさらにスケールダウンされ、続いて新しいReplicaSetがスケールアップされます。この間、利用可能なPodの総数は理想状態のPodの少なくとも70%以上になるように保証されます。
Max Surge
.spec.strategy.rollingUpdate.maxSurgeはオプションのフィールドで、理想状態のPod数を超えて作成できる最大のPod数を指定します。値は絶対値(例: 5)を指定するか、理想状態のPodのパーセンテージを指定します(例: 10%)。パーセンテージを指定した場合、絶対値は小数切り上げで計算されます。MaxUnavailableが0に指定されている場合、この値を0にできません。デフォルトでは25%です。
例えば、この値が30%と指定されているとき、ローリングアップデートが開始すると新しいReplicaSetはすぐに更新されます。このとき古いPodと新しいPodの総数は理想状態の130%を超えないように更新されます。一度古いPodが削除されると、新しいReplicaSetはさらにスケールアップされます。この間、利用可能なPodの総数は理想状態のPodに対して最大130%になるように保証されます。
Progress Deadline Seconds
.spec.progressDeadlineSecondsはオプションのフィールドで、システムがDeploymentの更新に失敗 したと判断するまでに待つ秒数を指定します。更新に失敗したと判断されたとき、リソースのステータスはType=Progressing、Status=FalseかつReason=ProgressDeadlineExceededとなるのを確認できます。DeploymentコントローラーはDeploymentの更新のリトライし続けます。デフォルト値は600です。今後、自動的なロールバックが実装されたとき、更新失敗状態になるとすぐにDeploymentコントローラーがロールバックを行うようになります。
この値が指定されているとき、.spec.minReadySecondsより大きい値を指定する必要があります。
Min Ready Seconds
.spec.minReadySecondsはオプションのフィールドで、新しく作成されたPodが利用可能となるために、最低どれくらいの秒数コンテナがクラッシュすることなく稼働し続ければよいかを指定するものです。デフォルトでは0です(Podは作成されるとすぐに利用可能と判断されます)。Podが利用可能と判断された場合についてさらに学ぶためにContainer Probes を参照してください。
リビジョン履歴の保持上限
Deploymentのリビジョン履歴は、Deploymentが管理するReplicaSetに保持されています。
.spec.revisionHistoryLimitはオプションのフィールドで、ロールバック可能な古いReplicaSetの数を指定します。この古いReplicaSetはetcd内のリソースを消費し、kubectl get rsの出力結果を見にくくします。Deploymentの各リビジョンの設定はReplicaSetに保持されます。このため一度古いReplicaSetが削除されると、そのリビジョンのDeploymentにロールバックすることができなくなります。デフォルトでは10もの古いReplicaSetが保持されます。しかし、この値の最適値は新しいDeploymentの更新頻度と安定性に依存します。
さらに詳しく言うと、この値を0にすると、0のレプリカを持つ古い全てのReplicaSetが削除されます。このケースでは、リビジョン履歴が完全に削除されているため新しいDeploymentのロールアウトを元に戻すことができません。
paused
.spec.pausedはオプションのboolean値で、Deploymentの一時停止と再開のための値です。一時停止されているものと、そうでないものとの違いは、一時停止されているDeploymentはPodTemplateSpecのいかなる変更があってもロールアウトがトリガーされないことです。デフォルトではDeploymentは一時停止していない状態で作成されます。
4.2.2 - ReplicaSet
ReplicaSetの目的は、どのような時でも安定したレプリカPodのセットを維持することです。これは、理想的なレプリカ数のPodが利用可能であることを保証するものとして使用されます。
ReplicaSetがどのように動くか
ReplicaSetは、ReplicaSetが対象とするPodをどう特定するかを示すためのセレクターや、稼働させたいPodのレプリカ数、Podテンプレート(理想のレプリカ数の条件を満たすために作成される新しいPodのデータを指定するために用意されるもの)といったフィールドとともに定義されます。ReplicaSetは、指定された理想のレプリカ数にするためにPodの作成と削除を行うことにより、その目的を達成します。ReplicaSetが新しいPodを作成するとき、ReplicaSetはそのPodテンプレートを使用します。
ReplicaSetがそのPod群と連携するためのリンクは、Podのmetadata.ownerReferences というフィールド(現在のオブジェクトが所有されているリソースを指定する)を介して作成されます。ReplicaSetによって所持された全てのPodは、それらのownerReferencesフィールドにReplicaSetを特定する情報を保持します。このリンクを通じて、ReplicaSetは管理しているPodの状態を把握したり、その後の実行計画を立てます。
ReplicaSetは、そのセレクターを使用することにより、所有するための新しいPodを特定します。もしownerReferenceフィールドの値を持たないPodか、ownerReferenceフィールドの値が コントローラー でないPodで、そのPodがReplicaSetのセレクターとマッチした場合に、そのPodは即座にそのReplicaSetによって所有されます。
ReplicaSetを使うとき
ReplicaSetはどんな時でも指定された数のPodのレプリカが稼働することを保証します。しかし、DeploymentはReplicaSetを管理する、より上位レベルの概念で、Deploymentはその他の多くの有益な機能と共に、宣言的なPodのアップデート機能を提供します。それゆえ、我々はユーザーが独自のアップデートオーケストレーションを必要としたり、アップデートを全く必要としないような場合を除いて、ReplicaSetを直接使うよりも代わりにDeploymentを使うことを推奨します。
これは、ユーザーがReplicaSetのオブジェクトを操作する必要が全く無いことを意味します。
代わりにDeploymentを使用して、specセクションにユーザーのアプリケーションを定義してください。
ReplicaSetの使用例
apiVersion : apps/v1
kind : ReplicaSet
metadata :
name : frontend
labels :
app : guestbook
tier : frontend
spec :
# ケースに応じてレプリカを修正する
replicas : 3
selector :
matchLabels :
tier : frontend
template :
metadata :
labels :
tier : frontend
spec :
containers :
- name : php-redis
image : gcr.io/google_samples/gb-frontend:v3
上記のマニフェストをfrontend.yamlファイルに保存しKubernetesクラスターに適用すると、マニフェストに定義されたReplicaSetとそれが管理するPod群を作成します。
kubectl apply -f http://k8s.io/examples/controllers/frontend.yaml
ユーザーはデプロイされた現在のReplicaSetの情報も取得できます。
そして、ユーザーが作成したfrontendリソースについての情報も取得できます。
NAME DESIRED CURRENT READY AGE
frontend 3 3 3 6s
ユーザーはまたReplicaSetの状態も確認できます。
kubectl describe rs/frontend
その結果は以下のようになります。
Name: frontend
Namespace: default
Selector: tier=frontend
Labels: app=guestbook
tier=frontend
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"ReplicaSet","metadata":{"annotations":{},"labels":{"app":"guestbook","tier":"frontend"},"name":"frontend",...
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 117s replicaset-controller Created pod: frontend-wtsmm
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-b2zdv
Normal SuccessfulCreate 116s replicaset-controller Created pod: frontend-vcmts
そして最後に、ユーザーはReplicaSetによって作成されたPodもチェックできます。
表示されるPodに関する情報は以下のようになります。
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 6m36s
frontend-vcmts 1/1 Running 0 6m36s
frontend-wtsmm 1/1 Running 0 6m36s
ユーザーはまた、それらのPodのownerReferencesがfrontendReplicaSetに設定されていることも確認できます。
これを確認するためには、稼働しているPodの中のどれかのyamlファイルを取得します。
kubectl get pods frontend-b2zdv -o yaml
その表示結果は、以下のようになります。そのfrontendReplicaSetの情報がmetadataのownerReferencesフィールドにセットされています。
apiVersion : v1
kind : Pod
metadata :
creationTimestamp : "2020-02-12T07:06:16Z"
generateName : frontend-
labels :
tier : frontend
name : frontend-b2zdv
namespace : default
ownerReferences :
- apiVersion : apps/v1
blockOwnerDeletion : true
controller : true
kind : ReplicaSet
name : frontend
uid : f391f6db-bb9b-4c09-ae74-6a1f77f3d5cf
...
テンプレートなしのPodの所有
ユーザーが問題なくベアPod(Bare Pod: ここではPodテンプレート無しのPodのこと)を作成しているとき、そのベアPodがユーザーのReplicaSetの中のいずれのセレクターともマッチしないことを確認することを強く推奨します。
この理由として、ReplicaSetは、所有対象のPodがReplicaSetのテンプレートによって指定されたPodのみに限定されていないからです(ReplicaSetは前のセクションで説明した方法によって他のPodも所有できます)。
前のセクションで取り上げたfrontendReplicaSetと、下記のマニフェストのPodをみてみます。
apiVersion : v1
kind : Pod
metadata :
name : pod1
labels :
tier : frontend
spec :
containers :
- name : hello1
image : gcr.io/google-samples/hello-app:2.0
---
apiVersion : v1
kind : Pod
metadata :
name : pod2
labels :
tier : frontend
spec :
containers :
- name : hello2
image : gcr.io/google-samples/hello-app:1.0
これらのPodはownerReferencesに何のコントローラー(もしくはオブジェクト)も指定されておらず、そしてfrontendReplicaSetにマッチするセレクターをもっており、これらのPodは即座にfrontendReplicaSetによって所有されます。
このfrontendReplicaSetがデプロイされ、初期のPodレプリカがレプリカ数の要求を満たすためにセットアップされた後で、ユーザーがそのPodを作成することを考えます。
kubectl apply -f http://k8s.io/examples/pods/pod-rs.yaml
新しいPodはそのReplicaSetによって所有され、そのReplicaSetのレプリカ数が、設定された理想のレプリカ数を超えた場合すぐにそれらのPodは削除されます。
下記のコマンドでPodを取得できます。
その表示結果で、新しいPodがすでに削除済みか、削除中のステータスになっているのを確認できます。
NAME READY STATUS RESTARTS AGE
frontend-b2zdv 1/1 Running 0 10m
frontend-vcmts 1/1 Running 0 10m
frontend-wtsmm 1/1 Running 0 10m
pod1 0/1 Terminating 0 1s
pod2 0/1 Terminating 0 1s
もしユーザーがそのPodを最初に作成する場合
kubectl apply -f http://k8s.io/examples/pods/pod-rs.yaml
そしてその後にfrontendReplicaSetを作成すると、
kubectl apply -f http://k8s.io/examples/controllers/frontend.yaml
ユーザーはそのReplicaSetが作成したPodを所有し、さらにもともと存在していたPodと今回新たに作成されたPodの数が、理想のレプリカ数になるまでPodを作成するのを確認できます。
ここでまたPodの状態を取得します。
取得結果は下記のようになります。
NAME READY STATUS RESTARTS AGE
frontend-hmmj2 1/1 Running 0 9s
pod1 1/1 Running 0 36s
pod2 1/1 Running 0 36s
この方法で、ReplicaSetはテンプレートで指定されたもの以外のPodを所有することができます。
ReplicaSetのマニフェストを記述する。
他の全てのKubernetes APIオブジェクトのように、ReplicaSetはapiVersion、kindとmetadataフィールドを必要とします。
ReplicaSetでは、kindフィールドの値はReplicaSetです。
ReplicaSetオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
また、ReplicaSetは.spec セクション
Pod テンプレート
.spec.templateはラベルを持つことが必要なPodテンプレート です。先ほど作成したfrontend.yamlの例では、tier: frontendというラベルを1つ持っています。
他のコントローラーがこのPodを所有しようとしないためにも、他のコントローラーのセレクターでラベルを上書きしないように注意してください。
テンプレートの再起動ポリシー のためのフィールドである.spec.template.spec.restartPolicyはAlwaysのみ許可されていて、そしてそれがデフォルト値です。
Pod セレクター
.spec.selectorフィールドはラベルセレクター です。
先ほど 議論したように、ReplicaSetが所有するPodを指定するためにそのラベルが使用されます。
先ほどのfrontend.yamlの例では、そのセレクターは下記のようになっていました
matchLabels :
tier : frontend
そのReplicaSetにおいて、.spec.template.metadata.labelsフィールドの値はspec.selectorと一致しなくてはならず、一致しない場合はAPIによって拒否されます。
備考: 2つのReplicaSetが同じ.spec.selectorの値を設定しているが、それぞれ異なる.spec.template.metadata.labelsと.spec.template.specフィールドの値を持っていたとき、それぞれのReplicaSetはもう一方のReplicaSetによって作成されたPodを無視します。
レプリカ数について
ユーザーは.spec.replicasフィールドの値を設定することにより、いくつのPodを同時に稼働させるか指定できます。そのときReplicaSetはレプリカ数がこの値に達するまでPodを作成、または削除します。
もしユーザーが.spec.replicasを指定しない場合、デフォルト値として1がセットされます。
ReplicaSetを利用する
ReplicaSetとPodの削除
ReplicaSetとそれが所有する全てのPod削除したいときは、kubectl deleteガベージコレクター がデフォルトで自動的に全ての依存するPodを削除します。
REST APIもしくはclient-goライブラリーを使用するとき、ユーザーは-dオプションでpropagationPolicyをBackgroundかForegroundと指定しなくてはなりません。例えば下記のように実行します。
kubectl proxy --port= 8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
'{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
"Content-Type: application/json"
ReplicaSetのみを削除する
ユーザーはkubectl delete--cascade=falseオプションを付けることにより、所有するPodに影響を与えることなくReplicaSetを削除できます。
REST APIもしくはclient-goライブラリーを使用するとき、ユーザーは-dオプションでpropagationPolicyをOrphanと指定しなくてはなりません。
例えば下記のように実行します:
kubectl proxy --port= 8080
curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
'{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
"Content-Type: application/json"
一度元のReplicaSetが削除されると、ユーザーは新しいものに置き換えるため新しいReplicaSetを作ることができます。新旧のReplicaSetの.spec.selectorの値が同じである間、新しいReplicaSetは古いReplicaSetで稼働していたPodを取り入れます。
しかし、存在するPodが新しく異なるPodテンプレートとマッチさせようとするとき、この仕組みは機能しません。
ReplicaSetはローリングアップデートを直接サポートしないため、ユーザーのコントロール下においてPodを新しいspecにアップデートしたい場合は、Deployment を使用してください。
PodをReplicaSetから分離させる
ユーザーはPodのラベルを変更することにより、ReplicaSetからそのPodを削除できます。この手法はデバッグや、データ修復などのためにサービスからPodを削除したいときに使用できます。
この方法で削除されたPodは自動的に新しいものに置き換えられます。(レプリカ数は変更されないものと仮定します。)
ReplicaSetのスケーリング
ReplicaSetは、ただ.spec.replicasフィールドを更新することによって簡単にスケールアップまたはスケールダウンできます。ReplicaSetコントローラーは、ラベルセレクターにマッチするような指定した数のPodが利用可能であり、操作可能であることを保証します。
スケールダウンする場合、ReplicaSetコントローラーは以下の一般的なアルゴリズムに基づき、利用可能なPodをソートし、スケールダウンするPodの優先順位を付け、削除するPodを選択します:
保留している(またはスケジュール不可な)Podが先にスケールダウンされます。
controller.kubernetes.io/pod-deletion-costアノテーションが設定されている場合、値の小さいPodが優先されます。レプリカ数の多いノード上のPodが、レプリカ数の少ないノード上のPodより優先されます。
Podの作成時間が異なる場合、より新しく作成されたPodが古いPodより優先されます(LogarithmicScaleDownフィーチャーゲート が有効の場合、作成時間は整数対数スケールでバケット化されます)。
上記条件のすべてに該当する場合は、ランダム選択となります。
Pod削除コスト
FEATURE STATE: Kubernetes v1.22 [beta]
controller.kubernetes.io/pod-deletion-cost
アノテーションはPodに設定する必要があり、範囲は[-2147483648, 2147483647]になります。同じReplicaSetに属する他のPodと比較して、Podを削除する際のコストを表しています。削除コストの低いPodは、削除コストの高いPodより優先的に削除されます。
このアノテーションを設定しないPodは暗黙的に0と設定され、負の値は許容されます。
無効な値はAPIサーバーによって拒否されます。
この機能はbeta版で、デフォルトで有効になっています。kube-apiserverとkube-controller-managerでフィーチャーゲート PodDeletionCostを設定することで無効にすることができます。
備考:
これはベストエフォートで実行されているもので、Pod削除の順番を保証するものではありません。
ユーザーは、メトリック値に基づいてアノテーションを更新するなど、頻繁に更新することは避けるべきです。APIサーバー上で大量のPodの更新操作を発生させることになるためです。
使用事例
アプリケーションの異なるPodは、異なる使用レベルになる可能性があります。スケールダウンする場合、アプリケーションは使用率の低いPodを削除することを優先しています。Podを頻繁に更新することを避けるため、アプリケーションはスケールダウンする前に一度controller.kubernetes.io/pod-deletion-costを更新する必要があります(アノテーションをPod使用レベルに比例する値に設定します)。Spark DeploymentのドライバーPodのように、アプリケーション自体がスケールダウンを制御する場合も機能します。
HorizontalPodAutoscaler(HPA)のターゲットとしてのReplicaSet
ReplicaSetはまた、Horizontal Pod Autoscalers (HPA) のターゲットにもなることができます。
これはつまりReplicaSetがHPAによってオートスケールされうることを意味します。
ここではHPAが、前の例で作成したReplicaSetをターゲットにする例を示します。
apiVersion : autoscaling/v1
kind : HorizontalPodAutoscaler
metadata :
name : frontend-scaler
spec :
scaleTargetRef :
kind : ReplicaSet
name : frontend
minReplicas : 3
maxReplicas : 10
targetCPUUtilizationPercentage : 50
このマニフェストをhpa-rs.yamlに保存し、Kubernetesクラスターに適用すると、レプリケートされたPodのCPU使用量にもとづいてターゲットのReplicaSetをオートスケールするHPAを作成します。
kubectl apply -f https://k8s.io/examples/controllers/hpa-rs.yaml
同様のことを行うための代替案として、kubectl autoscaleコマンドも使用できます。(こちらの方がより簡単です。)
kubectl autoscale rs frontend --max= 10 --min= 3 --cpu-percent= 50
ReplicaSetの代替案
Deployment (推奨)
Deployment
ベアPod(Bare Pods)
ユーザーがPodを直接作成するケースとは異なり、ReplicaSetはNodeの故障やカーネルのアップグレードといった破壊的なNodeのメンテナンスなど、どのような理由に限らず削除または停止されたPodを置き換えます。
このため、我々はもしユーザーのアプリケーションが単一のPodのみ必要とする場合でもReplicaSetを使用することを推奨します。プロセスのスーパーバイザーについても同様に考えると、それは単一Node上での独立したプロセスの代わりに複数のNodeにまたがった複数のPodを監視します。
ReplicaSetは、KubeletのようなNode上のいくつかのエージェントに対して、ローカルのコンテナ再起動を移譲します。
Job
PodをPodそれ自身で停止させたいような場合(例えば、バッチ用のジョブなど)は、ReplicaSetの代わりにJob
DaemonSet
マシンの監視やロギングなど、マシンレベルの機能を提供したい場合は、ReplicaSetの代わりにDaemonSet
ReplicationController
ReplicaSetはReplicationControllers ラベルについてのユーザーガイド に書かれているように、集合ベース(set-based)のセレクター要求をサポートしていないことを除いては、同じ目的を果たし、同じようにふるまいます。
次の項目
4.2.3 - StatefulSet
StatefulSetはステートフルなアプリケーションを管理するためのワークロードAPIです。
StatefulSetはPod のデプロイとスケーリングを管理し、それらのPodの順序と一意性を保証 します。
Deployment のように、StatefulSetは指定したコンテナのspecに基づいてPodを管理します。Deploymentとは異なり、StatefulSetは各Podにおいて管理が大変な同一性を維持します。これらのPodは同一のspecから作成されますが、それらは交換可能ではなく、リスケジュール処理をまたいで維持される永続的な識別子を持ちます。
ワークロードに永続性を持たせるためにストレージボリュームを使いたい場合は、解決策の1つとしてStatefulSetが利用できます。StatefulSet内の個々のPodは障害の影響を受けやすいですが、永続化したPodの識別子は既存のボリュームと障害によって置換された新しいPodの紐付けを簡単にします。
StatefulSetの使用
StatefulSetは下記の1つ以上の項目を要求するアプリケーションにおいて最適です。
安定した一意のネットワーク識別子
安定した永続ストレージ
規則的で安全なデプロイとスケーリング
規則的で自動化されたローリングアップデート
上記において安定とは、Podのスケジュール(または再スケジュール)をまたいでも永続的であることと同義です。
もしアプリケーションが安定したネットワーク識別子と規則的なデプロイや削除、スケーリングを全く要求しない場合、ユーザーはステートレスなレプリカのセットを提供するワークロードを使ってアプリケーションをデプロイするべきです。
Deployment やReplicaSet のようなコントローラーはこのようなステートレスな要求に対して最適です。
制限事項
提供されたPodのストレージは、要求されたstorage classにもとづいてPersistentVolume Provisioner によってプロビジョンされるか、管理者によって事前にプロビジョンされなくてはなりません。
StatefulSetの削除もしくはスケールダウンをすることにより、StatefulSetに関連したボリュームは削除されません 。 これはデータ安全性のためで、関連するStatefulSetのリソース全てを自動的に削除するよりもたいてい有効です。
StatefulSetは現在、Podのネットワークアイデンティティーに責務をもつためにHeadless Service を要求します。ユーザーはこのServiceを作成する責任があります。
StatefulSetは、StatefulSetが削除されたときにPodの停止を行うことを保証していません。StatefulSetにおいて、規則的で安全なPodの停止を行う場合、削除のために事前にそのStatefulSetの数を0にスケールダウンさせることが可能です。
デフォルト設定のPod管理ポリシー (OrderedReady)によってローリングアップデート を行う場合、修復のための手動介入 を要求するようなブロークンな状態に遷移させることが可能です。
コンポーネント
下記の例は、StatefulSetのコンポーネントのデモンストレーションとなります。
apiVersion : v1
kind : Service
metadata :
name : nginx
labels :
app : nginx
spec :
ports :
- port : 80
name : web
clusterIP : None
selector :
app : nginx
---
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : web
spec :
selector :
matchLabels :
app : nginx # .spec.template.metadata.labelsの値と一致する必要があります
serviceName : "nginx"
replicas : 3 # by default is 1
template :
metadata :
labels :
app : nginx # .spec.selector.matchLabelsの値と一致する必要があります
spec :
terminationGracePeriodSeconds : 10
containers :
- name : nginx
image : registry.k8s.io/nginx-slim:0.8
ports :
- containerPort : 80
name : web
volumeMounts :
- name : www
mountPath : /usr/share/nginx/html
volumeClaimTemplates :
- metadata :
name : www
spec :
accessModes : [ "ReadWriteOnce" ]
storageClassName : "my-storage-class"
resources :
requests :
storage : 1Gi
上記の例では、
nginxという名前のHeadlessServiceは、ネットワークドメインをコントロールするために使われます。
webという名前のStatefulSetは、specで3つのnginxコンテナのレプリカを持ち、そのコンテナはそれぞれ別のPodで稼働するように設定されています。
volumeClaimTemplatesは、PersistentVolumeプロビジョナーによってプロビジョンされたPersistentVolume を使って安定したストレージを提供します。
StatefulSetの名前は有効な名前 である必要があります。
Podセレクター
ユーザーは、StatefulSetの.spec.template.metadata.labelsのラベルと一致させるため、StatefulSetの.spec.selectorフィールドをセットしなくてはなりません。Kubernetes1.8以前では、.spec.selectorフィールドは省略された場合デフォルト値になります。Kubernetes1.8とそれ以降のバージョンでは、ラベルに一致するPodセレクターの指定がない場合はStatefulSetの作成時にバリデーションエラーになります。
Podアイデンティティー
StatefulSetのPodは、順番を示す番号、安定したネットワークアイデンティティー、安定したストレージからなる一意なアイデンティティーを持ちます。
そのアイデンティティーはどのNode上にスケジュール(もしくは再スケジュール)されるかに関わらず、そのPodに紐付きます。
順序インデックス
N個のレプリカをもったStatefulSetにおいて、StatefulSet内の各Podは、0からはじまりN-1までの整数値を順番に割り当てられ、そのStatefulSetにおいては一意となります。
安定したネットワークID
StatefulSet内の各Podは、そのStatefulSet名とPodの順序番号から派生してホストネームが割り当てられます。
作成されたホストネームの形式は$(StatefulSet名)-$(順序番号)となります。先ほどの上記の例では、web-0,web-1,web-2という3つのPodが作成されます。
StatefulSetは、PodのドメインをコントロールするためにHeadless Service を使うことができます。
このHeadless Serviceによって管理されたドメインは$(Service名).$(ネームスペース).svc.cluster.local形式となり、"cluster.local"というのはそのクラスターのドメインとなります。
各Podが作成されると、Podは$(Pod名).$(管理するServiceドメイン名)に一致するDNSサブドメインを取得し、管理するServiceはStatefulSetのserviceNameで定義されます。
クラスターでのDNSの設定方法によっては、新たに起動されたPodのDNS名をすぐに検索できない場合があります。
この動作は、クラスター内の他のクライアントが、Podが作成される前にそのPodのホスト名に対するクエリーをすでに送信していた場合に発生する可能性があります。
(DNSでは通常)ネガティブキャッシュは、Podの起動後でも、少なくとも数秒間、以前に失敗したルックアップの結果が記憶され、再利用されることを意味します。
Podが作成された後、速やかにPodを検出する必要がある場合は、いくつかのオプションがあります。
DNSルックアップに依存するのではなく、Kubernetes APIに直接(例えばwatchを使って)問い合わせる。
Kubernetes DNS プロバイダーのキャッシュ時間を短縮する(これは現在30秒キャッシュされるようになっているCoreDNSのConfigMapを編集することを意味しています。)。
制限事項 セクションで言及したように、ユーザーはPodのネットワークアイデンティティーのためにHeadless Service を作成する責任があります。
ここで、クラスタードメイン、Service名、StatefulSet名の選択と、それらがStatefulSetのPodのDNS名にどう影響するかの例をあげます。
Cluster Domain
Service (ns/name)
StatefulSet (ns/name)
StatefulSet Domain
Pod DNS
Pod Hostname
cluster.local
default/nginx
default/web
nginx.default.svc.cluster.local
web-{0..N-1}.nginx.default.svc.cluster.local
web-{0..N-1}
cluster.local
foo/nginx
foo/web
nginx.foo.svc.cluster.local
web-{0..N-1}.nginx.foo.svc.cluster.local
web-{0..N-1}
kube.local
foo/nginx
foo/web
nginx.foo.svc.kube.local
web-{0..N-1}.nginx.foo.svc.kube.local
web-{0..N-1}
備考: クラスタードメインは
その他の設定 がされない限り、
cluster.localにセットされます。
安定したストレージ
StatefulSetで定義された各VolumeClaimTemplateに対して、各Podは1つのPersistentVolumeClaimを受け取ります。上記のnginxの例において、各Podはmy-storage-classというStorageClassをもち、1GiBのストレージ容量を持った単一のPersistentVolumeを受け取ります。もしStorageClassが指定されていない場合、デフォルトのStorageClassが使用されます。PodがNode上にスケジュール(もしくは再スケジュール)されたとき、そのvolumeMountsはPersistentVolume Claimに関連したPersistentVolumeをマウントします。
注意点として、PodのPersistentVolume Claimと関連したPersistentVolumeは、PodやStatefulSetが削除されたときに削除されません。
削除する場合は手動で行わなければなりません。
Podのネームラベル
StatefulSet コントローラー がPodを作成したとき、Podの名前として、statefulset.kubernetes.io/pod-nameにラベルを追加します。このラベルによってユーザーはServiceにStatefulSet内の指定したPodを割り当てることができます。
デプロイとスケーリングの保証
N個のレプリカをもつStatefulSetにおいて、Podがデプロイされるとき、それらのPodは{0..N-1}の番号で順番に作成されます。
Podが削除されるとき、それらのPodは{N-1..0}の番号で降順に削除されます。
Podに対してスケーリングオプションが適用される前に、そのPodの前の順番の全てのPodがRunningかつReady状態になっていなくてはなりません。
Podが停止される前に、そのPodの番号より大きい番号を持つの全てのPodは完全にシャットダウンされていなくてはなりません。
StatefulSetはpod.Spec.TerminationGracePeriodSecondsを0に指定すべきではありません。これは不安全で、やらないことを強く推奨します。さらなる説明としては、StatefulSetのPodの強制削除 を参照してください。
上記の例のnginxが作成されたとき、3つのPodはweb-0、web-1、web-2の順番でデプロイされます。web-1はweb-0がRunningかつReady状態 になるまでは決してデプロイされないのと、同様にweb-2はweb-1がRunningかつReady状態にならないとデプロイされません。もしweb-0がweb-1がRunningかつReady状態になった後だが、web-2が起動する前に失敗した場合、web-2はweb-0の再起動が成功し、RunningかつReady状態にならないと再起動されません。
もしユーザーがreplicas=1といったようにStatefulSetにパッチをあてることにより、デプロイされたものをスケールすることになった場合、web-2は最初に停止されます。web-1はweb-2が完全にシャットダウンされ削除されるまでは、停止されません。もしweb-0が、web-2が完全に停止され削除された後だが、web-1の停止の前に失敗した場合、web-1はweb-0がRunningかつReady状態になるまでは停止されません。
Podの管理ポリシー
Kubernetes1.7とそれ以降のバージョンでは、StatefulSetは.spec.podManagementPolicyフィールドを介して、Podの一意性とアイデンティティーを保証します。
OrderedReadyなPod管理
OrderedReadyなPod管理はStatefulSetにおいてデフォルトです。これはデプロイとスケーリングの保証 に記載されている項目の振る舞いを実装します。
並行なPod管理
ParallelなPod管理は、StatefulSetコントローラーに対して、他のPodが起動や停止される前にそのPodが完全に起動し準備完了になるか停止するのを待つことなく、Podが並行に起動もしくは停止するように指示します。
アップデートストラテジー
Kubernetes1.7とそれ以降のバージョンにおいて、StatefulSetの.spec.updateStrategyフィールドで、コンテナの自動のローリングアップデートの設定やラベル、リソースのリクエストとリミットや、StatefulSet内のPodのアノテーションを指定できます。
OnDelete
OnDeleteというアップデートストラテジーは、レガシーな(Kubernetes1.6以前)振る舞いとなります。StatefulSetの.spec.updateStrategy.typeがOnDeleteにセットされていたとき、そのStatefulSetコントローラーはStatefulSet内でPodを自動的に更新しません。StatefulSetの.spec.template項目の修正を反映した新しいPodの作成をコントローラーに支持するためには、ユーザーは手動でPodを削除しなければなりません。
RollingUpdate
RollingUpdateというアップデートストラテジーは、StatefulSet内のPodに対する自動化されたローリングアップデートの機能を実装します。これは.spec.updateStrategyフィールドが未指定の場合のデフォルトのストラテジーです。StatefulSetの.spec.updateStrategy.typeがRollingUpdateにセットされたとき、そのStatefulSetコントローラーは、StatefulSet内のPodを削除し、再作成します。これはPodの停止(Podの番号の降順)と同じ順番で、一度に1つのPodを更新します。コントローラーは、その前のPodの状態がRunningかつReady状態になるまで次のPodの更新を待ちます。
パーティション
RollingUpdateというアップデートストラテジーは、.spec.updateStrategy.rollingUpdate.partitionを指定することにより、パーティションに分けることができます。もしパーティションが指定されていたとき、そのパーティションの値と等しいか、大きい番号を持つPodが更新されます。パーティションの値より小さい番号を持つPodは更新されず、たとえそれらのPodが削除されたとしても、それらのPodは以前のバージョンで再作成されます。もしStatefulSetの.spec.updateStrategy.rollingUpdate.partitionが、.spec.replicasより大きい場合、.spec.templateへの更新はPodに反映されません。
多くのケースの場合、ユーザーはパーティションを使う必要はありませんが、もし一部の更新を行う場合や、カナリー版のバージョンをロールアウトする場合や、段階的ロールアウトを行う場合に最適です。
強制ロールバック
デフォルトのPod管理ポリシー (OrderedReady)によるローリングアップデート を行う際、修復のために手作業が必要な状態にすることが可能です。
もしユーザーが、決してRunningかつReady状態にならないような設定になるようにPodテンプレートを更新した場合(例えば、不正なバイナリや、アプリケーションレベルの設定エラーなど)、StatefulSetはロールアウトを停止し、待機します。
この状態では、Podテンプレートを正常な状態に戻すだけでは不十分です。既知の問題 によって、StatefulSetは元の正常な状態へ戻す前に、壊れたPodがReady状態(決して起こりえない)に戻るのを待ち続けます。
そのテンプレートを戻したあと、ユーザーはまたStatefulSetが異常状態で稼働しようとしていたPodをすべて削除する必要があります。StatefulSetはその戻されたテンプレートを使ってPodの再作成を始めます。
次の項目
4.2.4 - DaemonSet
DaemonSet は全て(またはいくつか)のNodeが単一のPodのコピーを稼働させることを保証します。Nodeがクラスターに追加されるとき、PodがNode上に追加されます。Nodeがクラスターから削除されたとき、それらのPodはガーベージコレクターにより除去されます。DaemonSetの削除により、DaemonSetが作成したPodもクリーンアップします。
DaemonSetのいくつかの典型的な使用例は以下の通りです。
クラスターのストレージデーモンを全てのNode上で稼働させる。
ログ集計デーモンを全てのNode上で稼働させる。
Nodeのモニタリングデーモンを全てのNode上で稼働させる。
シンプルなケースとして、各タイプのデーモンにおいて、全てのNodeをカバーする1つのDaemonSetが使用されるケースがあります。さらに複雑な設定では、単一のタイプのデーモン用ですが、異なるフラグや、異なるハードウェアタイプに対するメモリー、CPUリクエストを要求する複数のDaemonSetを使用するケースもあります。
DaemonSet Specの記述
DaemonSetの作成
ユーザーはYAMLファイル内でDaemonSetの設定を記述することができます。例えば、下記のdaemonset.yamlファイルではfluentd-elasticsearchというDockerイメージを稼働させるDaemonSetの設定を記述します。
apiVersion : apps/v1
kind : DaemonSet
metadata :
name : fluentd-elasticsearch
namespace : kube-system
labels :
k8s-app : fluentd-logging
spec :
selector :
matchLabels :
name : fluentd-elasticsearch
template :
metadata :
labels :
name : fluentd-elasticsearch
spec :
tolerations :
- key : node-role.kubernetes.io/master
operator : Exists
effect : NoSchedule
containers :
- name : fluentd-elasticsearch
image : quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources :
limits :
memory : 200Mi
requests :
cpu : 100m
memory : 200Mi
volumeMounts :
- name : varlog
mountPath : /var/log
- name : varlibdockercontainers
mountPath : /var/lib/docker/containers
readOnly : true
terminationGracePeriodSeconds : 30
volumes :
- name : varlog
hostPath :
path : /var/log
- name : varlibdockercontainers
hostPath :
path : /var/lib/docker/containers
YAMLファイルに基づいてDaemonSetを作成します。
kubectl apply -f https://k8s.io/examples/controllers/daemonset.yaml
必須のフィールド
他の全てのKubernetesの設定と同様に、DaemonSetはapiVersion、kindとmetadataフィールドが必須となります。設定ファイルの活用法に関する一般的な情報は、ステートレスアプリケーションの稼働 、kubectlを用いたオブジェクトの管理 といったドキュメントを参照ください。
DaemonSetオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
また、DaemonSetにおいて.spec
Podテンプレート
.spec.templateは.spec内での必須のフィールドの1つです。
.spec.templateはPodテンプレート となります。これはフィールドがネストされていて、apiVersionやkindをもたないことを除いては、Pod のテンプレートと同じスキーマとなります。
Podに対する必須のフィールドに加えて、DaemonSet内のPodテンプレートは適切なラベルを指定しなくてはなりません(Podセレクター の項目を参照ください)。
DaemonSet内のPodテンプレートでは、RestartPolicyAlwaysを使用するか、明示的にAlwaysを設定するかのどちらかである必要があります。
Podセレクター
.spec.selectorフィールドはPodセレクターとなります。これはJob の.spec.selectorと同じものです。
ユーザーは.spec.templateのラベルにマッチするPodセレクターを指定しなくてはいけません。
また、一度DaemonSetが作成されると、その.spec.selectorは変更不可能になります。Podセレクターの変更は、意図しないPodの孤立を引き起こし、ユーザーにとってやっかいなものとなります。
.spec.selectorは2つのフィールドからなるオブジェクトです。
matchLabels - ReplicationController の.spec.selectorと同じように機能します。matchExpressions - キーと、値のリストとさらにはそれらのキーとバリューに関連したオペレーターを指定することにより、より洗練された形式のセレクターを構成できます。
上記の2つが指定された場合は、2つの条件をANDでどちらも満たすものを結果として返します。
spec.selectorは.spec.template.metadata.labelsとマッチしなければなりません。この2つの値がマッチしない設定をした場合、APIによってリジェクトされます。
選択したNode上でPodを稼働させる
もしユーザーが.spec.template.spec.nodeSelectorを指定したとき、DaemonSetコントローラーは、そのnode selector にマッチするNode上にPodを作成します。同様に、もし.spec.template.spec.affinityを指定したとき、DaemonSetコントローラーはnode affinity にマッチするNode上にPodを作成します。
もしユーザーがどちらも指定しないとき、DaemonSetコントローラーは全てのNode上にPodを作成します。
Daemon Podがどのようにスケジューリングされるか
DaemonSetは、全ての利用可能なNodeがPodのコピーを稼働させることを保証します。DaemonSetコントローラーは対象となる各Nodeに対してPodを作成し、ターゲットホストに一致するようにPodのspec.affinity.nodeAffinityフィールドを追加します。Podが作成されると、通常はデフォルトのスケジューラーが引き継ぎ、.spec.nodeNameを設定することでPodをターゲットホストにバインドします。新しいNodeに適合できない場合、デフォルトスケジューラーは新しいPodの優先度 に基づいて、既存Podのいくつかを先取り(退避)させることがあります。
ユーザーは、DaemonSetの.spec.template.spec.schedulerNameフィールドを設定することにより、DaemonSetのPodに対して異なるスケジューラーを指定することができます。
.spec.template.spec.affinity.nodeAffinityフィールド(指定された場合)で指定された元のNodeアフィニティは、DaemonSetコントローラーが対象Nodeを評価する際に考慮されますが、作成されたPod上では対象Nodeの名前と一致するNodeアフィニティに置き換わります。
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchFields :
- key : metadata.name
operator : In
values :
- target-host-name
TaintとToleration
DaemonSetコントローラーはDaemonSet Podに一連のToleration を自動的に追加します:
DaemonSetのPodテンプレートで定義すれば、DaemonSetのPodに独自のTolerationを追加することも可能です。
DaemonSetコントローラーはnode.kubernetes.io/unschedulable:NoScheduleのTolerationを自動的に設定するため、Kubernetesは スケジューリング不可能 としてマークされているNodeでDaemonSet Podを実行することが可能です。
クラスターのネットワーク のような重要なNodeレベルの機能をDaemonSetで提供する場合、KubernetesがDaemonSet PodをNodeが準備完了になる前に配置することは有用です。
例えば、その特別なTolerationがなければ、ネットワークプラグインがそこで実行されていないためにNodeが準備完了としてマークされず、同時にNodeがまだ準備完了でないためにそのNode上でネットワークプラグインが実行されていないというデッドロック状態に陥ってしまう可能性があるのです。
Daemon Podとのコミュニケーション
DaemonSet内のPodとのコミュニケーションをする際に考えられるパターンは以下の通りです:
Push : DaemonSet内のPodは統計データベースなどの他のサービスに対して更新情報を送信するように設定されます。クライアントは持っていません。NodeIPとKnown Port : PodがNodeIPを介して疎通できるようにするため、DaemonSet内のPodはhostPortを使用できます。慣例により、クライアントはNodeIPのリストとポートを知っています。DNS : 同じPodセレクターを持つHeadlessService を作成し、endpointsリソースを使ってDaemonSetを探すか、DNSから複数のAレコードを取得します。Service : 同じPodセレクターを持つServiceを作成し、複数のうちのいずれかのNode上のDaemonに疎通させるためにそのServiceを使います。(特定のNodeにアクセスする方法はありません。)
DaemonSetの更新
もしNodeラベルが変更されたとき、そのDaemonSetは直ちに新しくマッチしたNodeにPodを追加し、マッチしなくなったNodeからPodを削除します。
ユーザーはDaemonSetが作成したPodを修正可能です。しかし、Podは全てのフィールドの更新を許可していません。また、DaemonSetコントローラーは次のNode(同じ名前でも)が作成されたときにオリジナルのテンプレートを使ってPodを作成します。
ユーザーはDaemonSetを削除可能です。kubectlコマンドで--cascade=orphanを指定するとDaemonSetのPodはNode上に残り続けます。その後、同じセレクターで新しいDaemonSetを作成すると、新しいDaemonSetは既存のPodを再利用します。PodでDaemonSetを置き換える必要がある場合は、updateStrategyに従ってそれらを置き換えます。
ユーザーはDaemonSet上でローリングアップデートの実施 が可能です。
DaemonSetの代替案
Initスクリプト
Node上で直接起動することにより(例: init、upstartd、systemdを使用する)、デーモンプロセスを稼働することが可能です。この方法は非常に良いですが、このようなプロセスをDaemonSetを介して起動することはいくつかの利点があります。
アプリケーションと同じ方法でデーモンの監視とログの管理ができる。
デーモンとアプリケーションで同じ設定用の言語とツール(例: Podテンプレート、kubectl)を使える。
リソースリミットを使ったコンテナ内でデーモンを稼働させることにより、デーモンとアプリケーションコンテナの分離性が高まります。ただし、これはPod内ではなく、コンテナ内でデーモンを稼働させることでも可能です。
ベアPod
特定のNode上で稼働するように指定したPodを直接作成することは可能です。しかし、DaemonSetはNodeの故障やNodeの破壊的なメンテナンスやカーネルのアップグレードなど、どのような理由に限らず、削除されたもしくは停止されたPodを置き換えます。このような理由で、ユーザーはPod単体を作成するよりもむしろDaemonSetを使うべきです。
静的Pod
Kubeletによって監視されているディレクトリに対してファイルを書き込むことによって、Podを作成することが可能です。これは静的Pod と呼ばれます。DaemonSetと違い、静的Podはkubectlや他のKubernetes APIクライアントで管理できません。静的PodはApiServerに依存しておらず、クラスターの自立起動時に最適です。また、静的Podは将来的には廃止される予定です。
Deployment
DaemonSetは、Podの作成し、そのPodが停止されることのないプロセスを持つことにおいてDeployment と同様です(例: webサーバー、ストレージサーバー)。
フロントエンドのようなServiceのように、どのホスト上にPodが稼働するか制御するよりも、レプリカ数をスケールアップまたはスケールダウンしたりローリングアップデートする方が重要であるような、状態をもたないServiceに対してDeploymentを使ってください。
DaemonSetがNodeレベルの機能を提供し、他のPodがその特定のNodeで正しく動作するようにする場合、Podのコピーが全てまたは特定のホスト上で常に稼働していることが重要な場合にDaemonSetを使ってください。
例えば、ネットワークプラグイン には、DaemonSetとして動作するコンポーネントが含まれていることがよくあります。DaemonSetコンポーネントは、それが動作しているNodeでクラスターネットワークが動作していることを確認します。
次の項目
4.2.5 - Jobs
Jobは一つ以上のPodを作成し、指定された数のPodが正常に終了するまで、Podの実行を再試行し続けます。Podが正常に終了すると、Jobは成功したPodの数を追跡します。指定された完了数に達すると、そのタスク(つまりJob)は完了したとみなされます。Jobを削除すると、作成されたPodも一緒に削除されます。Jobを一時停止すると、再開されるまで、稼働しているPodは全部削除されます。
単純なケースを言うと、確実に一つのPodが正常に完了するまで実行されるよう、一つのJobオブジェクトを作成します。
一つ目のPodに障害が発生したり、(例えばノードのハードウェア障害またノードの再起動が原因で)削除されたりすると、Jobオブジェクトは新しいPodを作成します。
Jobで複数のPodを並列で実行することもできます。
スケジュールに沿ってJob(単一のタスクか複数タスク並列のいずれか)を実行したい場合は CronJob を参照してください。
実行例
下記にJobの定義例を記載しています。πを2000桁まで計算して出力するJobで、完了するまで約10秒かかります。
apiVersion : batch/v1
kind : Job
metadata :
name : pi
spec :
template :
spec :
containers :
- name : pi
image : perl:5.34.0
command : ["perl" , "-Mbignum=bpi" , "-wle" , "print bpi(2000)" ]
restartPolicy : Never
backoffLimit : 4
このコマンドで実行できます:
kubectl apply -f https://kubernetes.io/examples/controllers/job.yaml
実行結果はこのようになります:
job.batch/pi created
kubectlでJobの状態を確認できます:
Name: pi
Namespace: default
Selector: batch.kubernetes.io/controller-uid= c9948307-e56d-4b5d-8302-ae2d7b7da67c
Labels: batch.kubernetes.io/controller-uid= c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name= pi
...
Annotations: batch.kubernetes.io/job-tracking: ""
Parallelism: 1
Completions: 1
Start Time: Mon, 02 Dec 2019 15:20:11 +0200
Completed At: Mon, 02 Dec 2019 15:21:16 +0200
Duration: 65s
Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
Pod Template:
Labels: batch.kubernetes.io/controller-uid= c9948307-e56d-4b5d-8302-ae2d7b7da67c
batch.kubernetes.io/job-name= pi
Containers:
pi:
Image: perl:5.34.0
Port: <none>
Host Port: <none>
Command:
perl
-Mbignum= bpi
-wle
print bpi( 2000)
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 21s job-controller Created pod: pi-xf9p4
Normal Completed 18s job-controller Job completed
apiVersion: batch/v1
kind: Job
metadata:
annotations: batch.kubernetes.io/job-tracking: ""
...
creationTimestamp: "2022-11-10T17:53:53Z"
generation: 1
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
name: pi
namespace: default
resourceVersion: "4751"
uid: 204fb678-040b-497f-9266-35ffa8716d14
spec:
backoffLimit: 4
completionMode: NonIndexed
completions: 1
parallelism: 1
selector:
matchLabels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
suspend: false
template:
metadata:
creationTimestamp: null
labels:
batch.kubernetes.io/controller-uid: 863452e6-270d-420e-9b94-53a54146c223
batch.kubernetes.io/job-name: pi
spec:
containers:
- command:
- perl
- -Mbignum= bpi
- -wle
- print bpi( 2000)
image: perl:5.34.0
imagePullPolicy: IfNotPresent
name: pi
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Never
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
status:
active: 1
ready: 0
startTime: "2022-11-10T17:53:57Z"
uncountedTerminatedPods: {}
Jobの完了したPodを確認するには、kubectl get podsを使います。
Jobに属するPodの一覧を機械可読形式で出力するには、下記のコマンドを使います:
pods = $( kubectl get pods --selector= batch.kubernetes.io/job-name= pi --output= jsonpath = '{.items[*].metadata.name}' )
echo $pods
出力結果はこのようになります:
pi-5rwd7
ここのセレクターはJobのセレクターと同じです。--output=jsonpathオプションは、返されたリストからPodのnameフィールドを指定するための表現です。
その中の一つのPodの標準出力を確認するには:
Jobの標準出力を確認するもう一つの方法は:
出力結果はこのようになります:
3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989380952572010654858632788659361533818279682303019520353018529689957736225994138912497217752834791315155748572424541506959508295331168617278558890750983817546374649393192550604009277016711390098488240128583616035637076601047101819429555961989467678374494482553797747268471040475346462080466842590694912933136770289891521047521620569660240580381501935112533824300355876402474964732639141992726042699227967823547816360093417216412199245863150302861829745557067498385054945885869269956909272107975093029553211653449872027559602364806654991198818347977535663698074265425278625518184175746728909777727938000816470600161452491921732172147723501414419735685481613611573525521334757418494684385233239073941433345477624168625189835694855620992192221842725502542568876717904946016534668049886272327917860857843838279679766814541009538837863609506800642251252051173929848960841284886269456042419652850222106611863067442786220391949450471237137869609563643719172874677646575739624138908658326459958133904780275901
Job spec(仕様)の書き方
他のKubernetesオブジェクト設定ファイルと同様に、JobにもapiVersion、kindまたはmetadataフィールドが必要です。
コントロールプレーンがJobのために新しいPodを作成するとき、Jobの.metadata.nameはそれらのPodに名前をつけるための基礎の一部になります。Jobの名前は有効なDNSサブドメイン名 である必要がありますが、これはPodのホスト名に予期しない結果をもたらす可能性があります。最高の互換性を得るためには、名前はDNSラベル のより限定的な規則に従うべきです。名前がDNSサブドメインの場合でも、名前は63文字以下でなければなりません。
Jobには.specセクション
Jobラベル
Jobラベルのjob-nameとcontroller-uidの接頭辞はbatch.kubernetes.io/となります。
Podテンプレート
.spec.templateは.specの唯一の必須フィールドです。
.spec.templateはpodテンプレート です。ネストされていることとapiVersionやkindフィールドが不要になったことを除いて、仕様の定義がPod と全く同じです。
Podの必須フィールドに加えて、Job定義ファイルにあるPodテンプレートでは、適切なラベル(podセレクター を参照)と適切な再起動ポリシーを指定する必要があります。
RestartPolicyNeverかOnFailureのみ設定可能です。
Podセレクター
.spec.selectorフィールドはオプションです。ほとんどの場合はむしろ指定しないほうがよいです。
独自のPodセレクターを指定 セクションを参照してください。
Jobの並列実行
Jobで実行するのに適したタスクは主に3種類あります:
非並列Job
通常、Podに障害が発生しない限り、一つのPodのみが起動されます。
Podが正常に終了すると、Jobはすぐに完了します。
固定の完了数 を持つ並列Job:
.spec.completionsに0以外の正の値を指定します。Jobは全体的なタスクを表し、.spec.completions個のPodが成功すると、Jobの完了となります。
.spec.completionMode="Indexed"を利用する場合、各Podは0から.spec.completions-1までの範囲内のインデックスがアサインされます。
ワークキュー を利用した並列Job:
.spec.completionsの指定をしない場合、デフォルトは.spec.parallelismとなります。Pod間で調整する、または外部サービスを使う方法で、それぞれ何のタスクに着手するかを決めます。例えば、一つのPodはワークキューから最大N個のタスクを一括で取得できます。
各Podは他のPodがすべて終了したかどうか、つまりJobが完了したかどうかを単独で判断できます。
Jobに属する 任意 のPodが正常に終了すると、新しいPodは作成されません。
一つ以上のPodが正常に終了し、すべてのPodが終了すると、Jobは正常に完了します。
一つのPodが正常に終了すると、他のPodは同じタスクの作業を行ったり、出力を書き込んだりすることはできません。すべてのPodが終了プロセスに進む必要があります。
非並列 Jobの場合、.spec.completionsと.spec.parallelismの両方を未設定のままにしておくことも可能です。未設定の場合、両方がデフォルトで1になります。
完了数固定 Jobの場合、.spec.completionsを必要完了数に設定する必要があります。
.spec.parallelismを設定してもいいですし、未設定の場合、デフォルトで1になります。
ワークキュー 並列Jobの場合、.spec.completionsを未設定のままにし、.spec.parallelismを非負の整数に設定する必要があります。
各種類のJobの使用方法の詳細については、Jobパターン セクションを参照してください。
並列処理の制御
必要並列数(.spec.parallelism)は任意の非負の値に設定できます。
未設定の場合は、デフォルトで1になります。
0に設定した際には、増加するまでJobは一時停止されます。
実際の並列数(任意の瞬間に実行されているPod数)は、さまざまな理由により、必要並列数と異なる可能性があります:
完了数固定 Jobの場合、実際に並列して実行されるPodの数は、残りの完了数を超えることはありません。 .spec.parallelismの値が高い場合は無視されます。ワークキュー Jobの場合、任意のPodが成功すると、新しいPodは作成されません。ただし、残りのPodは終了まで実行し続けられます。Jobコントローラー の応答する時間がなかった場合。
Jobコントローラーが何らかの理由で(ResourceQuotaの不足、権限の不足など)、Podを作成できない場合、
実際の並列数は必要並列数より少なくなる可能性があります。
同じJobで過去に発生した過度のPod障害が原因で、Jobコントローラーは新しいPodの作成を抑制することがあります。
Podがグレースフルシャットダウンされた場合、停止するのに時間がかかります。
完了モード
FEATURE STATE: Kubernetes v1.24 [stable]
完了数固定 Job、つまり.spec.completionsの値がnullではないJobは.spec.completionModeで完了モードを指定できます:
NonIndexed(デフォルト): .spec.completions個のPodが成功した場合、Jobの完了となります。言い換えれば、各Podの完了状態は同質です。ここで要注意なのは、.spec.completionsの値がnullの場合、暗黙的にNonIndexedとして指定されることです。
Indexed: Jobに属するPodはそれぞれ、0から.spec.completions-1の範囲内の完了インデックスを取得できます。インデックスは下記の三つの方法で取得できます。
Podアノテーションbatch.kubernetes.io/job-completion-index。
Podホスト名の一部として、$(job-name)-$(index)の形式になっています。
インデックス付きJob(Indexed Job)とService を一緒に使用すると、Jobに属するPodはお互いにDNSを介して確定的ホスト名で通信できます。この設定方法の詳細はPod間通信を使用したJob を参照してください。
コンテナ化されたタスクの環境変数JOB_COMPLETION_INDEX。
各インデックスに1つずつ正常に完了したPodがあると、Jobは完了したとみなされます。このモードの使い方については、静的な処理の割り当てを使用した並列処理のためのインデックス付きJob を参照してください。
備考: めったに発生しませんが、同じインデックスに対して複数のPodが起動することがあります。(Nodeの障害、kubeletの再起動、Podの立ち退きなど)。この場合、正常に完了した最初のPodだけ完了数にカウントされ、Jobのステータスが更新されます。同じインデックスに対して実行中または完了した他のPodは、検出されるとJobコントローラーによって削除されます。
Podとコンテナの障害対策
Pod内のコンテナは、その中のプロセスが0以外の終了コードで終了した、またはメモリ制限を超えたためにコンテナが強制終了されたなど、様々な理由で失敗することがあります。この場合、もし.spec.template.spec.restartPolicy = "OnFailure"と設定すると、Podはノード上に残りますが、コンテナは再実行されます。そのため、プログラムがローカルで再起動した場合の処理を行うか、.spec.template.spec.restartPolicy = "Never"と指定する必要があります。
restartPolicyの詳細についてはPodのライフサイクル を参照してください。
Podがノードからキックされた(ノードがアップグレード、再起動、削除されたなど)、または.spec.template.spec.restartPolicy = "Never"と設定されたときにPodに属するコンテナが失敗したなど、様々な理由でPod全体が故障することもあります。Podに障害が発生すると、Jobコントローラーは新しいPodを起動します。つまりアプリケーションは新しいPodで再起動された場合の処理を行う必要があります。特に、過去に実行した際に生じた一時ファイル、ロック、不完全な出力などを処理する必要があります。
デフォルトでは、それぞれのPodの失敗は.spec.backoffLimitにカウントされます。詳しくはPod失敗のバックオフポリシー をご覧ください。しかし、JobのPod失敗ポリシー を設定することで、Pod失敗の処理をカスタマイズすることができます。
.spec.parallelism = 1、.spec.completions = 1と.spec.template.spec.restartPolicy = "Never"を指定しても、同じプログラムが2回起動されることもありますので注意してください。
.spec.parallelismと.spec.completionsを両方とも2以上指定した場合、複数のPodが同時に実行される可能性があります。そのため、Podは並行処理を行えるようにする必要があります。
フィーチャーゲート のPodDisruptionConditionsとJobPodFailurePolicyの両方が有効で、.spec.podFailurePolicyフィールドが設定されている場合、Jobコントローラーは終了するPod(.metadata.deletionTimestampフィールドが設定されているPod)を、そのPodが終了する(.status.phaseがFailedまたはSucceededになる)までは失敗とはみなしません。ただし、Jobコントローラーは、終了が明らかになるとすみやかに代わりのPodを作成します。Podが終了すると、Jobコントローラーはこの終了したPodを考慮に入れて、該当のJobの.backoffLimitと.podFailurePolicyを評価します。
これらの要件のいずれかが満たされていない場合、Jobコントローラーは、そのPodが後にphase: "Succeeded"で終了する場合でも、終了するPodを即時に失敗として数えます。
Pod失敗のバックオフポリシー
設定の論理エラーなどにより、Jobが数回再試行した後に失敗状態にしたい場合があります。.spec.backoffLimitを設定すると、失敗したと判断するまでの再試行回数を指定できます。バックオフ制限はデフォルトで6に設定されています。Jobに属していて失敗したPodはJobコントローラーにより再作成され、バックオフ遅延は指数関数的に増加し(10秒、20秒、40秒…)、最大6分まで増加します。
再実行回数の算出方法は以下の2通りです:
.status.phase = "Failed"で設定されたPod数を計算します。restartPolicy = "OnFailure"と設定された場合、.status.phaseがPendingまたはRunningであるPodに属するすべてのコンテナで再試行する回数を計算します。
どちらかの計算が.spec.backoffLimitに達した場合、Jobは失敗とみなされます。
JobTrackingWithFinalizers
備考: restartPolicy = "OnFailure"が設定されたJobはバックオフ制限に達すると、属するPodは全部終了されるので注意してください。これにより、Jobの実行ファイルのデバッグ作業が難しくなる可能性があります。失敗したJobからの出力が不用意に失われないように、Jobのデバッグ作業をする際はrestartPolicy = "Never"を設定するか、ロギングシステムを使用することをお勧めします。
Pod失敗ポリシー
FEATURE STATE: Kubernetes v1.26 [beta]
備考: クラスターで
JobPodFailurePolicyフィーチャーゲート が有効になっている場合のみ、Jobに対してPod失敗ポリシーを設定することができます。さらにPod失敗ポリシーでPodの中断条件を検知して処理できるように、
PodDisruptionConditionsフィーチャーゲートを有効にすることが推奨されます。(
Podの中断条件 を参照してください)。どちらのフィーチャーゲートもKubernetes 1.27で利用可能です。
.spec.podFailurePolicyフィールドで定義されるPod失敗ポリシーを使用すると、コンテナの終了コードとPodの条件に基づいてクラスターがPodの失敗を処理できるようになります。
状況によっては、Podの失敗を処理するときに、Jobの.spec.backoffLimitに基づいたPod失敗のバックオフポリシー が提供する制御よりも、Podの失敗処理に対してより良い制御を求めるかもしれません。これらはいくつかの使用例です:
不要なPodの再起動を回避してワークロードの実行コストを最適化するために、Podの1つがソフトウェアバグを示す終了コードで失敗するとすぐにJobを終了させることができます。
中断が発生してもJobが完了するように、中断によって発生したPodの失敗(preemption 、APIを起点とした退避 、taint を起点とした立ち退き)を無視し、.spec.backoffLimitのリトライ回数にカウントしないようにすることができます。
上記のユースケースを満たすために、.spec.podFailurePolicyフィールドでPod失敗ポリシーを設定できます。このポリシーは、コンテナの終了コードとPodの条件に基づいてPodの失敗を処理できます。
以下は、podFailurePolicyを定義するJobのマニフェストです:
apiVersion : batch/v1
kind : Job
metadata :
name : job-pod-failure-policy-example
spec :
completions : 12
parallelism : 3
template :
spec :
restartPolicy : Never
containers :
- name : main
image : docker.io/library/bash:5
command : ["bash" ] # example command simulating a bug which triggers the FailJob action
args :
- -c
- echo "Hello world!" && sleep 5 && exit 42
backoffLimit : 6
podFailurePolicy :
rules :
- action : FailJob
onExitCodes :
containerName : main # optional
operator: In # one of : In, NotIn
values : [42 ]
- action: Ignore # one of : Ignore, FailJob, Count
onPodConditions :
- type : DisruptionTarget # indicates Pod disruption
上記の例では、Pod失敗ポリシーの最初のルールは、mainコンテナが42の終了コードで失敗した場合、そのJobを失敗とマークすることを指定しています。以下は特に mainコンテナに関するルールです:
終了コード0はコンテナが成功したことを意味します。
終了コード42はJob全体 が失敗したことを意味します。
それ以外の終了コードは、コンテナが失敗したこと、つまりPod全体が失敗したことを示します。再起動の合計回数がbackoffLimit未満であれば、Podは再作成されます。backoffLimitに達した場合、Job全体 が失敗したことになります。
備考: PodテンプレートはrestartPolicy.Neverを指定しているため、kubeletはその特定のPodのmainコンテナを再起動しません。
Pod失敗ポリシーの2つ目のルールでは、DisruptionTargetという条件で失敗したPodに対してIgnoreアクションを指定することで、Podの中断が.spec.backoffLimitによるリトライの制限にカウントされないようにします。
備考: Pod失敗ポリシーまたはPod失敗のバックオフポリシーのいずれかによってJobが失敗し、そのJobが複数のPodを実行している場合、KubernetesはそのJob内の保留中または実行中のすべてのPodを終了します。
これらはAPIの要件と機能です:
.spec.podFailurePolicyフィールドをJobに使いたい場合は、.spec.restartPolicyをNeverに設定してそのJobのPodテンプレートも定義する必要があります。spec.podFailurePolicy.rulesで指定したPod失敗ポリシーのルールが順番に評価されます。あるPodの失敗がルールに一致すると、残りのルールは無視されます。Pod失敗に一致するルールがない場合は、デフォルトの処理が適用されます。spec.podFailurePolicy.rules[*].onExitCodes.containerNameを指定することで、ルールを特定のコンテナに制限することができます。指定しない場合、ルールはすべてのコンテナに適用されます。指定する場合は、Pod テンプレート内のコンテナ名またはinitContainer名のいずれかに一致する必要があります。Pod失敗ポリシーがspec.podFailurePolicy.rules[*].actionにマッチしたときに実行されるアクションを指定できます。指定可能な値は以下のとおりです。
FailJob: PodのJobをFailedとしてマークし、実行中の Pod をすべて終了させる必要があることを示します。Ignore: .spec.backoffLimitのカウンターは加算されず、代替のPodが作成すべきであることを示します。Count: Podがデフォルトの方法で処理されるべきであることを示します。.spec.backoffLimitのカウンターが加算されます。
備考: PodFailurePolicyを使用すると、Jobコントローラーは
FailedフェーズのPodのみにマッチします。削除タイムスタンプを持つPodで、終了フェーズ(
Failedまたは
Succeeded)にないものは、まだ終了中と見なされます。これは、終了中Podは終了フェーズに達するまで
追跡ファイナライザー を保持することを意味します。Kubernetes 1.27以降、Kubeletは削除されたPodを終了フェーズに遷移させます(参照:
Podのフェーズ )。これにより、削除されたPodはJobコントローラーによってファイナライザーが削除されます。
Jobの終了とクリーンアップ
Jobが完了すると、それ以上Podは作成されませんが、通常 Podが削除されることもありません。
これらを残しておくと、完了したPodのログを確認でき、エラーや警告などの診断出力を確認できます。
またJobオブジェクトはJob完了後も残っているため、状態を確認することができます。古いJobの状態を把握した上で、削除するかどうかはユーザー次第です。Jobを削除するにはkubectl (例:kubectl delete jobs/piまたはkubectl delete -f ./job.yaml)を使います。kubectlでJobを削除する場合、Jobが作成したPodも全部削除されます。
デフォルトでは、Podが失敗しない(restartPolicy=Never)またはコンテナがエラーで終了しない(restartPolicy=OnFailure)限り、Jobは中断されることなく実行されます。.spec.backoffLimitに達するとそのJobは失敗と見なされ、実行中のPodはすべて終了します。
Jobを終了させるもう一つの方法は、活動期間を設定することです。
Jobの.spec.activeDeadlineSecondsフィールドに秒数を設定することで、活動期間を設定できます。
Podがいくつ作成されても、activeDeadlineSecondsはJobの存続する時間に適用されます。
JobがactiveDeadlineSecondsに達すると、実行中のすべてのPodは終了され、Jobの状態はtype: Failedになり、理由はreason: DeadlineExceededになります。
ここで要注意なのは、Jobの.spec.activeDeadlineSecondsは.spec.backoffLimitよりも優先されます。したがって、失敗して再試行しているPodが一つ以上持っているJobは、backoffLimitに達していなくても、activeDeadlineSecondsで指定された設定時間に達すると、追加のPodをデプロイしなくなります。
例えば:
apiVersion : batch/v1
kind : Job
metadata :
name : pi-with-timeout
spec :
backoffLimit : 5
activeDeadlineSeconds : 100
template :
spec :
containers :
- name : pi
image : perl:5.34.0
command : ["perl" , "-Mbignum=bpi" , "-wle" , "print bpi(2000)" ]
restartPolicy : Never
Job仕様と、Jobに属するPodテンプレートの仕様 は両方ともactiveDeadlineSecondsフィールドを持っているので注意してください。適切なレベルで設定していることを確認してください。
またrestartPolicyはJob自体ではなく、Podに適用されることも注意してください: Jobの状態はtype: Failedになると、自動的に再起動されることはありません。
つまり、.spec.activeDeadlineSecondsと.spec.backoffLimitによって引き起こされるJob終了メカニズムは、永久的なJob失敗につながり、手動で介入して解決する必要があります。
終了したJobの自動クリーンアップ
終了したJobは通常システムに残す必要はありません。残ったままにしておくとAPIサーバーに負担をかけることになります。Jobが上位コントローラーにより直接管理されている場合、例えばCronJobs の場合、Jobは指定された容量ベースのクリーンアップポリシーに基づき、CronJobによりクリーンアップされます。
終了したJobのTTLメカニズム
FEATURE STATE: Kubernetes v1.23 [stable]
終了したJob(状態がCompleteかFailedになったJob)を自動的にクリーンアップするもう一つの方法は
TTLコントローラー より提供されたTTLメカニズムです。.spec.ttlSecondsAfterFinishedフィールドを指定することで、終了したリソースをクリーンアップすることができます。
TTLコントローラーでJobをクリーンアップする場合、Jobはカスケード的に削除されます。つまりJobを削除する際に、Jobに属しているオブジェクト、例えばPodなども一緒に削除されます。Jobが削除される場合、Finalizerなどの、Jobのライフサイクル保証は守られることに注意してください。
例えば:
apiVersion : batch/v1
kind : Job
metadata :
name : pi-with-ttl
spec :
ttlSecondsAfterFinished : 100
template :
spec :
containers :
- name : pi
image : perl:5.34.0
command : ["perl" , "-Mbignum=bpi" , "-wle" , "print bpi(2000)" ]
restartPolicy : Never
Job pi-with-ttlは終了してからの100秒後に自動的に削除されるようになっています。
このフィールドに0を設定すると、Jobは終了後すぐに自動削除の対象になります。このフィールドに何も設定しないと、Jobが終了してもTTLコントローラーによるクリーンアップはされません。
備考: ttlSecondsAfterFinishedフィールドを設定することが推奨されます。管理されていないJob(CronJobなどの、他のワークロードAPIを経由せずに、直接作成したJob)はorphanDependentsというデフォルトの削除ポリシーがあるため、Jobが完全に削除されても、属しているPodが残ってしまうからです。
コントロールプレーン は最終的に、失敗または完了して削除されたJobに属するPodをガベージコレクション しますが、Podが残っていると、クラスターのパフォーマンスが低下することがあり、最悪の場合、この低下によりクラスターがオフラインになることがあります。
LimitRanges とリソースクォータ で、指定する名前空間が消費できるリソースの量に上限を設定することができます。
Jobパターン
Jobオブジェクトは、Podの確実な並列実行をサポートするために使用されます。科学技術計算でよく見られるような、密接に通信を行う並列処理をサポートするようには設計されていません。独立だが関連性のある一連の作業項目 の並列処理をサポートします。例えば送信すべき電子メール、レンダリングすべきフレーム、トランスコードすべきファイル、スキャンすべきNoSQLデータベースのキーの範囲、などです。
複雑なシステムでは、異なる作業項目のセットが複数存在する場合があります。ここでは、ユーザーが一斉に管理したい作業項目のセットが一つだけの場合 — つまりバッチJob だけを考えます。
並列計算にはいくつかのパターンがあり、それぞれに長所と短所があります。
トレードオフの関係にあるのは:
各作業項目に1つのJobオブジェクト vs. すべての作業項目に1つのJobオブジェクト。
作成されるPod数が作業項目数と等しい、 vs. 各Podが複数の作業項目を処理する。
前者は通常、既存のコードやコンテナへの変更が少なくて済みます。
後者は上記と同じ理由で、大量の作業項目を処理する場合に適しています。
ワークキューを利用するアプローチもいくつかあります。それを使うためには、キューサービスを実行し、既存のプログラムやコンテナにワークキューを利用させるための改造を行う必要があります。
他のアプローチは既存のコンテナ型アプリケーションに適用しやすいです。
ここでは、上記のトレードオフをまとめてあり、それぞれ2~4列目に対応しています。
またパターン名のところは、例やより詳しい説明が書いてあるページへのリンクになっています。
.spec.completionsで完了数を指定する場合、Jobコントローラーより作成された各Podは同一のspec
この表は、各パターンで必要な.spec.parallelismと.spec.completionsの設定を示しています。
ここで、Wは作業項目の数を表しています。
高度な使い方
Jobの一時停止
FEATURE STATE: Kubernetes v1.24 [stable]
Jobが作成されると、JobコントローラーはJobの要件を満たすために直ちにPodの作成を開始し、Jobが完了するまで作成し続けます。しかし、Jobの実行を一時的に中断して後で再開したい場合、または一時停止状態のJobを再開し、再開時間は後でカスタムコントローラーに判断させたい場合はあると思います。
Jobを一時停止するには、Jobの.spec.suspendフィールドをtrueに修正し、後でまた再開したい場合にはfalseに修正すればよいです。
.spec.suspendをtrueに設定してJobを作成すると、一時停止状態のままで作成されます。
一時停止状態のJobを再開すると、.status.startTimeフィールドの値は現在時刻にリセットされます。これはつまり、Jobが一時停止して再開すると、.spec.activeDeadlineSecondsタイマーは停止してリセットされることになります。
Jobを中断すると、状態がCompletedではない実行中のPodはすべてSIGTERMシグナルを受信して終了されます 。Podのグレースフル終了の猶予期間がカウントダウンされ、この期間内に、Podはこのシグナルを処理しなければなりません。場合により、その後のために処理状況を保存したり、変更を元に戻したりする処理が含まれます。この方法で終了したPodはcompletions数にカウントされません。
下記は一時停止状態のままで作成されたJobの定義例になります:
kubectl get job myjob -o yaml
apiVersion : batch/v1
kind : Job
metadata :
name : myjob
spec :
suspend : true
parallelism : 1
completions : 5
template :
spec :
...
コマンドラインを使ってJobにパッチを当てることで、Jobの一時停止状態を切り替えることもできます。
活動中のJobを一時停止する:
kubectl patch job/myjob --type= strategic --patch '{"spec":{"suspend":true}}'
一時停止中のJobを再開する:
kubectl patch job/myjob --type= strategic --patch '{"spec":{"suspend":false}}'
Jobのstatusセクションで、Jobが停止中なのか、過去に停止したことがあるかを判断できます:
kubectl get jobs/myjob -o yaml
apiVersion : batch/v1
kind : Job
# .metadata and .spec omitted
status :
conditions :
- lastProbeTime : "2021-02-05T13:14:33Z"
lastTransitionTime : "2021-02-05T13:14:33Z"
status : "True"
type : Suspended
startTime : "2021-02-05T13:13:48Z"
Jobのcondition.typeが"Suspended"で、statusが"True"になった場合、Jobは一時停止中になります。lastTransitionTimeフィールドで、どのぐらい中断されたかを判断できます。statusが"False"になった場合、Jobは一時停止状態でしたが、今は実行されていることになります。conditionが書いていない場合、Jobは一度も停止していないことになります。
Jobが一時停止して再開した場合、Eventsも作成されます:
kubectl describe jobs/myjob
Name: myjob
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m job-controller Created pod: myjob-hlrpl
Normal SuccessfulDelete 11m job-controller Deleted pod: myjob-hlrpl
Normal Suspended 11m job-controller Job suspended
Normal SuccessfulCreate 3s job-controller Created pod: myjob-jvb44
Normal Resumed 3s job-controller Job resumed
最後の4つのイベント、特に"Suspended"と"Resumed"のイベントは、.spec.suspendフィールドの値を切り替えた直接の結果です。この2つのイベントの間に、Podは作成されていないことがわかりますが、Jobが再開されるとすぐにPodの作成も再開されました。
可変スケジューリング命令
FEATURE STATE: Kubernetes v1.27 [stable]
ほとんどの場合、並列Jobは、すべてのPodが同じゾーン、またはすべてのGPUモデルxかyのいずれかであるが、両方の混在ではない、などの制約付きで実行することが望ましいです。
suspend フィールドは、これらの機能を実現するための第一歩です。Suspendは、カスタムキューコントローラーがJobをいつ開始すべきかを決定することができます。しかし、Jobの一時停止が解除されると、カスタムキューコントローラーは、Job内のPodの実際の配置場所には影響を与えません。
この機能により、Jobが開始する前にスケジューリング命令を更新でき、カスタムキューコントローラーがPodの配置に影響を与えることができるようになります。同時に実際のPodからNodeへの割り当てをkube-schedulerにオフロードする能力を提供します。これは一時停止されたJobの中で、一度も一時停止解除されたことのないJobに対してのみ許可されます。
JobのPodテンプレートで更新可能なフィールドはnodeAffinity、nodeSelector、tolerations、labelsとannotations、スケジューリングゲート です。
独自のPodセレクターを指定
Jobオブジェクトを作成する際には通常、.spec.selectorを指定しません。Jobが作成された際に、システムのデフォルトロジックは、他のJobと重ならないようなセレクターの値を選択し、このフィールドに追加します。
しかし、場合によっては、この自動設定されたセレクターをオーバーライドする必要があります。そのためには、Jobの.spec.selectorを指定します。
その際には十分な注意が必要です。そのJobの他のPodと重なったラベルセレクターを指定し、無関係のPodにマッチした場合、無関係のJobのPodが削除されたり、無関係のPodが完了されてもこのJobの完了数とカウントしたり、片方または両方のJobがPodの作成または完了までの実行を拒否する可能性があります。
一意でないセレクターを選択した場合、他のコントローラー(例えばReplicationController)や属しているPodが予測できない挙動をする可能性があります。Kubernetesは.spec.selectorを間違って設定しても止めることはしません。
下記はこの機能の使用例を紹介しています。
oldと名付けたJobがすでに実行されていると仮定します。既存のPodをそのまま実行し続けてほしい一方で、作成する残りのPodには別のテンプレートを使用し、そのJobには新しい名前を付けたいとしましょう。これらのフィールドは更新できないため、Jobを直接更新できません。そのため、kubectl delete jobs/old --cascade=orphanで、属しているPodが実行されたまま 、oldJobを削除します。削除する前に、どのセレクターを使用しているかをメモしておきます:
kubectl get job old -o yaml
出力結果はこのようになります:
kind : Job
metadata :
name : old
...
spec :
selector :
matchLabels :
batch.kubernetes.io/controller-uid : a8f3d00d-c6d2-11e5-9f87-42010af00002
...
次に、newという名前で新しくJobを作成し、同じセレクターを明示的に指定します。既存のPodもbatch.kubernetes.io/controller-uid=a8f3d00d-c6d2-11e5-9f87-42010af00002ラベルが付いているので、同じくnewJobによってコントロールされます。
通常システムが自動的に生成するセレクターを使用しないため、新しいJobで manualSelector: trueを指定する必要があります。
kind : Job
metadata :
name : new
...
spec :
manualSelector : true
selector :
matchLabels :
batch.kubernetes.io/controller-uid : a8f3d00d-c6d2-11e5-9f87-42010af00002
...
新しいJobはa8f3d00d-c6d2-11e5-9f87-42010af00002ではなく、別のuidを持つことになります。manualSelector: trueを設定することで、自分は何をしているかを知っていて、またこのミスマッチを許容することをシステムに伝えます。
FinalizerによるJob追跡
FEATURE STATE: Kubernetes v1.26 [stable]
備考: JobTrackingWithFinalizers機能が無効になっている時に作成されたJobについては、コントロールプレーンを1.26にアップグレードしても、ファイナライザーを使用してJobを追跡しません。
コントロールプレーンは任意のJobに属するPodを追跡し、そのPodがAPIサーバーから削除されたかどうか認識します。そのためJobコントローラーはファイナライザーbatch.kubernetes.io/job-trackingを持つPodを作成します。コントローラーがファイナライザーを削除するのは、PodがJobステータスに反映された後なので、他のコントローラーやユーザがPodを削除することができます。
Kubernetes 1.26にアップグレードする前、またはフィーチャーゲートJobTrackingWithFinalizersが有効になる前に作成されたJobは、Podファイナライザーを使用せずに追跡されます。Jobコントローラー は、クラスターに存在するPodのみに基づいて、succeededPodとfailedPodのステータスカウンタを更新します。クラスターからPodが削除されると、コントロールプレーンはJobの進捗を見失う可能性があります。
Jobがbatch.kubernetes.io/job-trackingというアノテーションを持っているかどうかをチェックすることで、コントロールプレーンがPodファイナライザーを使ってJobを追跡しているかどうかを判断できます。Jobからこのアノテーションを手動で追加したり削除したりしてはいけません 。代わりに、JobがPodファイナライザーを使用して追跡されていることを確認するために、Jobを再作成することができます。
静的なインデックス付きJob
FEATURE STATE: Kubernetes v1.27 [beta]
.spec.parallelismと.spec.compleitionsの両方を、.spec.parallelism == .spec.compleitionsとなるように変更することで、インデックス付きJobを増減させることができます。APIサーバ のElasticIndexedJobフィーチャーゲート が無効になっている場合、.spec.compleitionsは不変です。
静的なインデックス付きJobの使用例としては、MPI、Horovord、Ray、PyTorchトレーニングジョブなど、インデックス付きJobのスケーリングを必要とするバッチワークロードがあります。
代替案
単なるPod
Podが動作しているノードが再起動または故障した場合、Podは終了し、再起動されません。しかし、終了したPodを置き換えるため、Jobが新しいPodを作成します。このため、たとえアプリケーションが1つのPodしか必要としない場合でも、単なるPodではなくJobを使用することをお勧めします。
Replication Controller
JobはReplication Controllers を補完するものです。
Replication Controllerは、終了することが想定されていないPod(Webサーバーなど)を管理し、Jobは終了することが想定されているPod(バッチタスクなど)を管理します。
Podのライフサイクル で説明したように、JobはRestartPolicyがOnFailureかNeverと設定されているPodにのみ 適用されます。(注意:RestartPolicyが設定されていない場合、デフォルト値はAlwaysになります)
シングルJobによるコントローラーPodの起動
もう一つのパターンは、一つのJobが一つPodを作り、そのPodがカスタムコントローラーのような役割を果たし、他のPodを作ります。これは最も柔軟性がありますが、使い始めるにはやや複雑で、Kubernetesとの統合もあまりできません。
このパターンの一例としては、Sparkマスターコントローラーを起動し、sparkドライバーを実行してクリーンアップするスクリプトを実行するPodをJobで起動する(sparkの例 を参照)が挙げられます。
この方法のメリットは、全処理過程でJobオブジェクトが完了する保証がありながらも、どのPodを作成し、どのように作業を割り当てるかを完全に制御できることです。
次の項目
Pods について学ぶ。Jobのさまざまな実行方法について学ぶ:
終了したJobの自動クリーンアップ のリンクから、クラスターが完了または失敗したJobをどのようにクリーンアップするかをご確認ください。JobはKubernetes REST APIの一部です。JobのAPIを理解するために、
Job オブジェクトの定義をお読みください。UNIXツールのcronと同様に、スケジュールに基づいて実行される一連のJobを定義するために使用できるCronJob
段階的な例 に基づいて、PodFailurePolicyを使用して、回復可能なPod失敗と回復不可能なPod失敗の処理を構成する方法を練習します。
4.2.6 - 終了したリソースのためのTTLコントローラー(TTL Controller for Finished Resources)
FEATURE STATE: Kubernetes v1.12 [alpha]
TTLコントローラーは実行を終えたリソースオブジェクトのライフタイムを制御するためのTTL (time to live) メカニズムを提供します。Job のみ扱っていて、将来的にPodやカスタムリソースなど、他のリソースの実行終了を扱えるように拡張される予定です。
α版の免責事項: この機能は現在α版の機能で、kube-apiserverとkube-controller-managerのFeature Gate のTTLAfterFinishedを有効にすることで使用可能です。
TTLコントローラー
TTLコントローラーは現在Jobに対してのみサポートされています。クラスターオペレーターはこの例 のように、Jobの.spec.ttlSecondsAfterFinishedフィールドを指定することにより、終了したJob(完了したもしくは失敗した)を自動的に削除するためにこの機能を使うことができます。
TTL秒はいつでもセット可能です。下記はJobの.spec.ttlSecondsAfterFinishedフィールドのセットに関するいくつかの例です。
Jobがその終了後にいくつか時間がたった後に自動的にクリーンアップできるように、そのリソースマニフェストにこの値を指定します。
この新しい機能を適用させるために、存在していてすでに終了したリソースに対してこのフィールドをセットします。
リソース作成時に、このフィールドを動的にセットするために、管理webhookの変更 をさせます。クラスター管理者は、終了したリソースに対して、このTTLポリシーを強制するために使うことができます。
リソースが終了した後に、このフィールドを動的にセットしたり、リソースステータスやラベルなどの値に基づいて異なるTTL値を選択するために、管理webhookの変更 をさせます。
注意
TTL秒の更新
注意点として、Jobの.spec.ttlSecondsAfterFinishedフィールドといったTTL期間はリソースが作成された後、もしくは終了した後に変更できます。しかし、一度Jobが削除可能(TTLの期限が切れたとき)になると、それがたとえTTLを伸ばすような更新に対してAPIのレスポンスで成功したと返されたとしても、そのシステムはJobが稼働し続けることをもはや保証しません。
タイムスキュー(Time Skew)
TTLコントローラーが、TTL値が期限切れかそうでないかを決定するためにKubernetesリソース内に保存されたタイムスタンプを使うため、この機能はクラスター内のタイムスキュー(時刻のずれ)に対してセンシティブとなります。タイムスキューは、誤った時間にTTLコントローラーに対してリソースオブジェクトのクリーンアップしてしまうことを引き起こすものです。
Kubernetesにおいてタイムスキューを避けるために、全てのNode上でNTPの稼働を必須とします(#6159 を参照してください)。クロックは常に正しいものではありませんが、Node間におけるその差はとても小さいものとなります。TTLに0でない値をセットするときにこのリスクに対して注意してください。
次の項目
4.2.7 - CronJob
FEATURE STATE: Kubernetes v1.8 [beta]
CronJob は繰り返しのスケジュールによってJob を作成します。
CronJob オブジェクトとは crontab (cron table)ファイルでみられる一行のようなものです。
Cron 形式で記述された指定のスケジュールの基づき、定期的にジョブが実行されます。
注意: すべてのCronJob スケジュール: 時刻はジョブが開始されたkube-controller-manager のタイムゾーンに基づいています。
コントロールプレーンがkube-controller-managerをPodもしくは素のコンテナで実行している場合、CronJobコントローラーのタイムゾーンとして、kube-controller-managerコンテナに設定されたタイムゾーンを使用します。
CronJobリソースのためのマニフェストを作成する場合、その名前が有効なDNSサブドメイン名 か確認してください。
名前は52文字を超えることはできません。これはCronJobコントローラーが自動的に、与えられたジョブ名に11文字を追加し、ジョブ名の長さは最大で63文字以内という制約があるためです。
CronJob
CronJobは、バックアップの実行やメール送信のような定期的であったり頻発するタスクの作成に役立ちます。
CronJobは、クラスターがアイドル状態になりそうなときにJobをスケジューリングするなど、特定の時間に個々のタスクをスケジュールすることもできます。
例
このCronJobマニフェスト例は、毎分ごとに現在の時刻とhelloメッセージを表示します。
apiVersion : batch/v1
kind : CronJob
metadata :
name : hello
spec :
schedule : "* * * * *"
jobTemplate :
spec :
template :
spec :
containers :
- name : hello
image : busybox
command :
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy : OnFailure
(Running Automated Tasks with a CronJob ではこの例をより詳しく説明しています。).
CronJobの制限
cronジョブは一度のスケジュール実行につき、 おおよそ 1つのジョブオブジェクトを作成します。ここで おおよそ と言っているのは、ある状況下では2つのジョブが作成される、もしくは1つも作成されない場合があるためです。通常、このようなことが起こらないようになっていますが、完全に防ぐことはできません。したがって、ジョブは 冪等 であるべきです。
startingDeadlineSecondsが大きな値、もしくは設定されていない(デフォルト)、そして、concurrencyPolicyをAllowに設定している場合には、少なくとも一度、ジョブが実行されることを保証します。
最後にスケジュールされた時刻から現在までの間に、CronJobコントローラー はどれだけスケジュールが間に合わなかったのかをCronJobごとにチェックします。もし、100回以上スケジュールが失敗していると、ジョブは開始されずに、ログにエラーが記録されます。
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.
startingDeadlineSecondsフィールドが設定されると(nilではない)、最後に実行された時刻から現在までではなく、startingDeadlineSecondsの値から現在までで、どれだけジョブを逃したのかをコントローラーが数えます。 startingDeadlineSecondsが200の場合、過去200秒間にジョブが失敗した回数を記録します。
スケジュールされた時間にCronJobが作成できないと、失敗したとみなされます。たとえば、concurrencyPolicyがForbidに設定されている場合、前回のスケジュールがまだ実行中にCronJobをスケジュールしようとすると、CronJobは作成されません。
例として、CronJobが08:30:00を開始時刻として1分ごとに新しいJobをスケジュールするように設定され、startingDeadlineSecondsフィールドが設定されていない場合を想定します。CronJobコントローラーが08:29:00 から10:21:00の間にダウンしていた場合、スケジューリングを逃したジョブの数が100を超えているため、ジョブは開始されません。
このコンセプトをさらに掘り下げるために、CronJobが08:30:00から1分ごとに新しいJobを作成し、startingDeadlineSecondsが200秒に設定されている場合を想定します。CronJobコントローラーが前回の例と同じ期間(08:29:00 から10:21:00まで)にダウンしている場合でも、10:22:00時点でJobはまだ動作しています。このようなことは、過去200秒間(言い換えると、3回の失敗)に何回スケジュールが間に合わなかったをコントローラーが確認するときに発生します。これは最後にスケジュールされた時間から今までのものではありません。
CronJobはスケジュールに一致するJobの作成にのみ関与するのに対して、JobはJobが示すPod管理を担います。
次の項目
Cron表現形式 では、CronJobのscheduleフィールドのフォーマットを説明しています。
cronジョブの作成や動作の説明、CronJobマニフェストの例については、Running automated tasks with cron jobs を見てください。
4.3 -
自動スケーリングによって、何らかのかたちでワークロードを自動的に更新できます。これによりクラスターはリソース要求の変化に対してより弾力的かつ効率的に対応できるようになります。
Kubernetesでは、現在のリソース要求に応じてワークロードをスケールできます。
これによりクラスターはリソース要求の変化に対してより弾力的かつ効率的に対応できるようになります。
ワークロードをスケールするとき、ワークロードによって管理されるレプリカ数を増減したり、レプリカで使用可能なリソースをインプレースで調整できます。
ひとつ目のアプローチは 水平スケーリング と呼ばれ、一方でふたつ目のアプローチは 垂直スケーリング と呼ばれます。
ユースケースに応じて、ワークロードをスケールするには手動と自動の方法があります。
ワークロードを手動でスケーリングする
Kubernetesはワークロードの 手動スケーリング をサポートします。
水平スケーリングは kubectl CLIを使用して行うことができます。
垂直スケーリングの場合、ワークロードのリソース定義を パッチ適用 する必要があります。
両方の戦略の例については以下をご覧ください。
ワークロードを自動でスケーリングする
Kubernetesはワークロードの 自動スケーリング もサポートしており、これがこのページの焦点です。
Kubernetesにおける オートスケーリング の概念は一連のPodを管理するオブジェクト(例えばDeployment )を自動的に更新する機能を指します。
ワークロードを水平方向にスケーリングする
Kubernetesにおいて、 HorizontalPodAutoscaler (HPA)を使用してワークロードを水平方向に自動的にスケールできます。
これはKubernetes APIリソースおよびコントローラー として実装されておりCPUやメモリ使用率のような観測されたリソース使用率と一致するようにワークロードのレプリカ 数を定期的に調整します。
Deployment用のHorizontalPodAutoscalerを構成するウォークスルーチュートリアル があります。
ワークロードを垂直方向にスケーリングする
FEATURE STATE: Kubernetes v1.25 [stable]
VerticalPodAutoscaler (VPA)を使用してワークロードを垂直方向に自動的にスケールできます。
HPAと異なり、VPAはデフォルトでKubernetesに付属していませんが、GitHubで 見つかる別のプロジェクトです。
インストールすることにより、管理されたレプリカのリソースを どのように いつ スケールするのかを定義するワークロードのCustomResourceDefinitions (CRDs)を作成できるようになります。
現時点では、VPAは4つの異なるモードで動作できます:
VPAの異なるモード
モード
説明
Auto現在、Recreateは将来インプレースアップデートに変更される可能性があります
RecreateVPAはPod作成時にリソースリクエストを割り当てるだけでなく、要求されたリソースが新しい推奨事項と大きく異なる場合にそれらを削除することによって既存のPod上でリソースリクエストを更新します
InitialVPAはPod作成時にリソースリクエストを割り当て、後から変更することはありません
OffVPAはPodのリソース要件を自動的に変更しません。推奨事項は計算され、VPAオブジェクトで検査できます
インプレースリサイズの要件
FEATURE STATE: Kubernetes v1.27 [alpha]
Pod またはそのコンテナ を再起動せずに インプレースでワークロードをリサイズするには、Kubernetesバージョン1.27以降が必要です。
さらに、InPlaceVerticalScalingフィーチャーゲートを有効にする必要があります。
InPlacePodVerticalScaling: Podリソースの再作成なしで垂直オートスケーリングができる機能を有効にします。
クラスターサイズに基づく自動スケーリング
クラスターのサイズに基づいてスケールする必要があるワークロード(例えばcluster-dnsや他のシステムコンポーネント)の場合は、Cluster Proportional Autoscaler
Cluster Proportional Autoscalerはスケジュール可能なノード とコアの数を監視し、それに応じてターゲットワークロードのレプリカ数をスケールします。
レプリカ数を同じままにする必要がある場合、Cluster Proportional Vertical Autoscaler 現在ベータ版 でありGitHubで見つけることができます。
Cluster Proportional Autoscalerがワークロードのレプリカ数をスケールする一方で、Cluster Proportional Vertical Autoscalerはクラスター内のノードおよび/またはコアの数に基づいてワークロード(例えばDeploymentやDaemonSet)のリソース要求を調整します。
イベント駆動型自動スケーリング
例えばKubernetes Event Driven Autoscaler
(KEDA )
KEDAは例えばキューのメッセージ数などの処理するべきイベント数に基づいてワークロードをスケールするCNCF graduatedプロジェクトです。様々なイベントソースに合わせて選択できる幅広いアダプターが存在します。
スケジュールに基づく自動スケーリング
ワークロードををスケールするためのもう一つの戦略は、例えばオフピークの時間帯にリソース消費を削減するために、スケーリング操作をスケジュールする ことです。
イベント駆動型オートスケーリングと同様に、そのような動作はKEDAをCronスケーラーCronスケーラーによりワークロードをスケールインまたはスケールアウトするためのスケジュール(およびタイムゾーン)を定義できます。
クラスターのインフラストラクチャーのスケーリング
ワークロードのスケーリングだけではニーズを満たすのに十分でない場合は、クラスターのインフラストラクチャー自体をスケールすることもできます。
クラスターのインフラストラクチャーのスケーリングは通常ノード の追加または削除を意味します。
詳しくはクラスターの自動スケーリング を読んでください。
次の項目
5 - Service、負荷分散とネットワーキング
Kubernetesにおけるネットワーキングの概念とリソース。
Kubernetesのネットワーキングは4つの懸念事項に対処します。
Pod内のコンテナは、ネットワーキングを利用してループバック経由の通信を行います。
クラスターネットワーキングは、異なるPod間の通信を提供します。
Serviceリソースは、Pod内で動作しているアプリケーションへクラスターの外部から到達可能なように露出を許可します。
Serviceを利用して、クラスター内部のみで使用するServiceの公開も可能です。
5.1 - Service
KubernetesにおけるServiceとは、 クラスター内で1つ以上のPod として実行されているネットワークアプリケーションを公開する方法です。
Kubernetesでは、なじみのないサービスディスカバリーのメカニズムを使用するためにユーザーがアプリケーションの修正をする必要はありません。
KubernetesはPodにそれぞれのIPアドレス割り振りや、Podのセットに対する単一のDNS名を提供したり、それらのPodのセットに対する負荷分散が可能です。
Serviceを利用する動機
Kubernetes Pod はクラスターの状態に合わせて作成され削除されます。Podは揮発的なリソースです。
Deployment をアプリケーションを稼働させるために使用すると、Podを動的に作成・削除してくれます。
各Podはそれ自身のIPアドレスを持ちます。しかしDeploymentでは、ある時点において同時に稼働しているPodのセットは、その後のある時点において稼働しているPodのセットとは異なる場合があります。
この仕組みはある問題を引き起こします。もし、あるPodのセット(ここでは"バックエンド"と呼びます)がクラスター内で他のPodのセット(ここでは"フロントエンド"と呼びます)に対して機能を提供する場合、フロントエンドのPodがワークロードにおけるバックエンドを使用するために、バックエンドのPodのIPアドレスを探し出したり、記録し続けるためにはどうすればよいでしょうか?
ここで Service について説明します。
Serviceリソース
Kubernetesにおいて、ServiceはPodの論理的なセットや、そのPodのセットにアクセスするためのポリシーを定義します(このパターンはよくマイクロサービスと呼ばることがあります)。
ServiceによってターゲットとされたPodのセットは、たいてい セレクター によって定義されます。
その他の方法について知りたい場合はセレクターなしのService を参照してください。
例えば、3つのレプリカが稼働しているステートレスな画像処理用のバックエンドを考えます。これらのレプリカは代替可能です。— フロントエンドはバックエンドが何であろうと気にしません。バックエンドのセットを構成する実際のPodのセットが変更された際、フロントエンドクライアントはその変更を気にしたり、バックエンドのPodのセットの情報を記録しておく必要はありません。
Serviceによる抽象化は、クライアントからバックエンドのPodの管理する責務を分離することを可能にします。
クラウドネイティブのサービスディスカバリー
アプリケーション内でサービスディスカバリーのためにKubernetes APIが使える場合、ユーザーはエンドポイントをAPI Server に問い合わせることができ、またService内のPodのセットが変更された時はいつでも更新されたエンドポイントの情報を取得できます。
非ネイティブなアプリケーションのために、KubernetesはアプリケーションとバックエンドPodの間で、ネットワークポートやロードバランサーを配置する方法を提供します。
Serviceの定義
KubernetesのServiceはPodと同様にRESTのオブジェクトです。他のRESTオブジェクトと同様に、ユーザーはServiceの新しいインスタンスを作成するためにAPIサーバーに対してServiceの定義をPOSTできます。Serviceオブジェクトの名前は、有効なDNSラベル名 である必要があります。
例えば、TCPで9376番ポートで待ち受けていて、app=MyappというラベルをもつPodのセットがあるとします。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
この定義では、"my-service"という名前のついた新しいServiceオブジェクトを作成します。これはapp=Myappラベルのついた各Pod上でTCPの9376番ポートをターゲットとします。
Kubernetesは、このServiceに対してIPアドレス("clusterIP"とも呼ばれます)を割り当てます。これはServiceのプロキシによって使用されます(下記の仮想IPとServiceプロキシ を参照ください)。
Serviceセレクターのコントローラーはセレクターに一致するPodを継続的にスキャンし、“my-service”という名前のEndpointsオブジェクトに対して変更をPOSTします。
備考: ServiceはportからtargetPortへのマッピングを行います。デフォルトでは、利便性のためにtargetPortフィールドはportフィールドと同じ値で設定されます。
Pod内のポートの定義は名前を設定でき、ServiceのtargetPort属性にてその名前を参照できます。これは単一の設定名をもつService内で、複数の種類のPodが混合していたとしても有効で、異なるポート番号を介することによって利用可能な、同一のネットワークプロトコルを利用します。
この仕組みはServiceをデプロイしたり、設定を追加する場合に多くの点でフレキシブルです。例えば、バックエンドソフトウェアにおいて、次のバージョンでPodが公開するポート番号を変更するときに、クライアントの変更なしに行えます。
ServiceのデフォルトプロトコルはTCPです。また、他のサポートされているプロトコル も利用可能です。
多くのServiceが、1つ以上のポートを公開する必要があるように、Kubernetesは1つのServiceオブジェクトに対して複数のポートの定義をサポートしています。
各ポート定義は同一のprotocolまたは異なる値を設定できます。
セレクターなしのService
Serviceは多くの場合、KubernetesのPodに対するアクセスを抽象化しますが、他の種類のバックエンドも抽象化できます。
例えば:
プロダクション環境で外部のデータベースクラスターを利用したいが、テスト環境では、自身のクラスターが持つデータベースを利用したい場合
Serviceを、異なるNamespace のServiceや他のクラスターのServiceに向ける場合
ワークロードをKubernetesに移行するとき、アプリケーションに対する処理をしながら、バックエンドの一部をKubernetesで実行する場合
このような場合において、ユーザーはPodセレクターなしで Serviceを定義できます。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
ports :
- protocol : TCP
port : 80
targetPort : 9376
このServiceはセレクターがないため、対応するEndpointsオブジェクトは自動的に作成されません。
ユーザーはEndpointsオブジェクトを手動で追加することにより、向き先のネットワークアドレスとポートを手動でマッピングできます。
apiVersion : v1
kind : Endpoints
metadata :
name : my-service
subsets :
- addresses :
- ip : 192.0.2.42
ports :
- port : 9376
Endpointsオブジェクトの名前は、有効なDNSサブドメイン名 である必要があります。
備考: Endpointsのipは、loopback (127.0.0.0/8 for IPv4, ::1/128 for IPv6), や
link-local (169.254.0.0/16 and 224.0.0.0/24 for IPv4, fe80::/64 for IPv6)に設定することができません。
kube-proxy が仮想IPを最終的な到達先に設定することをサポートしていないため、Endpointsのipアドレスは他のKubernetes ServiceのClusterIPにすることができません。
セレクターなしのServiceへのアクセスは、セレクターをもっているServiceと同じようにふるまいます。上記の例では、トラフィックはYAMLファイル内で192.0.2.42:9376 (TCP)で定義された単一のエンドポイントにルーティングされます。
ExternalName Serviceはセレクターの代わりにDNS名を使用する特殊なケースのServiceです。さらなる情報は、このドキュメントの後で紹介するExternalName を参照ください。
エンドポイントスライス
FEATURE STATE: Kubernetes v1.17 [beta]
エンドポイントスライスは、Endpointsに対してよりスケーラブルな代替手段を提供できるAPIリソースです。概念的にはEndpointsに非常に似ていますが、エンドポイントスライスを使用すると、ネットワークエンドポイントを複数のリソースに分割できます。デフォルトでは、エンドポイントスライスは、100個のエンドポイントに到達すると「いっぱいである」と見なされ、その時点で追加のエンドポイントスライスが作成され、追加のエンドポイントが保存されます。
エンドポイントスライスは、エンドポイントスライスのドキュメント にて詳しく説明されている追加の属性と機能を提供します。
アプリケーションプロトコル
FEATURE STATE: Kubernetes v1.19 [beta]
AppProtocolフィールドによってServiceの各ポートに対して特定のアプリケーションプロトコルを指定することができます。
この値は、対応するEndpointsオブジェクトとEndpointSliceオブジェクトに反映されます。
仮想IPとサービスプロキシ
Kubernetesクラスターの各Nodeはkube-proxyを稼働させています。kube-proxyはExternalNameService用に仮想IPを実装する責務があります。
なぜ、DNSラウンドロビンを使わないのでしょうか。
ここで湧き上がる質問として、なぜKubernetesは内部のトラフィックをバックエンドへ転送するためにプロキシに頼るのでしょうか。
他のアプローチはどうなのでしょうか。例えば、複数のAバリュー(もしくはIPv6用にAAAAバリューなど)をもつDNSレコードを設定し、ラウンドロビン方式で名前を解決することは可能でしょうか。
Serviceにおいてプロキシを使う理由はいくつかあります。
DNSの実装がレコードのTTLをうまく扱わず、期限が切れた後も名前解決の結果をキャッシュするという長い歴史がある。
いくつかのアプリケーションではDNSルックアップを1度だけ行い、その結果を無期限にキャッシュする。
アプリケーションとライブラリーが適切なDNS名の再解決を行ったとしても、DNSレコード上の0もしくは低い値のTTLがDNSに負荷をかけることがあり、管理が難しい。
user-spaceプロキシモード
このモードでは、kube-proxyはServiceやEndpointsオブジェクトの追加・削除をチェックするために、Kubernetes Masterを監視します。
各Serviceは、ローカルのNode上でポート(ランダムに選ばれたもの)を公開します。この"プロキシポート"に対するどのようなリクエストも、そのServiceのバックエンドPodのどれか1つにプロキシされます(Endpointsを介して通知されたPodに対して)。
kube-proxyは、どのバックエンドPodを使うかを決める際にServiceのSessionAffinity項目の設定を考慮に入れます。
最後に、user-spaceプロキシはServiceのclusterIP(仮想IP)とportに対するトラフィックをキャプチャするiptablesルールをインストールします。
そのルールは、トラフィックをバックエンドPodにプロキシするためのプロキシポートにリダイレクトします。
デフォルトでは、user-spaceモードにおけるkube-proxyはラウンドロビンアルゴリズムによってバックエンドPodを選択します。
iptablesプロキシモードこのモードでは、kube-proxyはServiceやEndpointsオブジェクトの追加・削除のチェックのためにKubernetesコントロールプレーンを監視します。
各Serviceでは、そのServiceのclusterIPとportに対するトラフィックをキャプチャするiptablesルールをインストールし、そのトラフィックをServiceのあるバックエンドのセットに対してリダイレクトします。
各Endpointsオブジェクトは、バックエンドのPodを選択するiptablesルールをインストールします。
デフォルトでは、iptablesモードにおけるkube-proxyはバックエンドPodをランダムで選択します。
トラフィックのハンドリングのためにiptablesを使用すると、システムのオーバーヘッドが少なくなります。これは、トラフィックがLinuxのnetfilterによってuser-spaceとkernel-spaceを切り替える必要がないためです。
このアプローチは、オーバーヘッドが少ないことに加えて、より信頼できる方法でもあります。
kube-proxyがiptablesモードで稼働し、最初に選択されたPodが応答しない場合、そのコネクションは失敗します。
これはuser-spaceモードでの挙動と異なります: user-spaceモードにおいては、kube-proxyは最初のPodに対するコネクションが失敗したら、自動的に他のバックエンドPodに対して再接続を試みます。
iptablesモードのkube-proxyが正常なバックエンドPodのみをリダイレクト対象とするために、PodのReadinessProbe を使用してバックエンドPodが正常に動作しているか確認できます。これは、ユーザーがkube-proxyを介して、コネクションに失敗したPodに対してトラフィックをリダイレクトするのを除外することを意味します。
IPVSプロキシモード
FEATURE STATE: Kubernetes v1.11 [stable]
ipvsモードにおいて、kube-proxyはServiceとEndpointsオブジェクトを監視し、IPVSルールを作成するためにnetlinkインターフェースを呼び出し、定期的にKubernetesのServiceとEndpointsとIPVSルールを同期させます。
このコントロールループはIPVSのステータスが理想的な状態になることを保証します。
Serviceにアクセスするとき、IPVSはトラフィックをバックエンドのPodに向けます。
IPVSプロキシモードはiptablesモードと同様に、netfilterのフック関数に基づいています。ただし、基礎となるデータ構造としてハッシュテーブルを使っているのと、kernel-spaceで動作します。
これは、IPVSモードにおけるkube-proxyはiptablesモードに比べてより低いレイテンシーでトラフィックをリダイレクトし、プロキシのルールを同期する際にはよりパフォーマンスがよいことを意味します。
他のプロキシモードと比較して、IPVSモードはより高いネットワークトラフィックのスループットをサポートしています。
IPVSはバックエンドPodに対するトラフィックのバランシングのために多くのオプションを下記のとおりに提供します。
rr: ラウンドロビンlc: 最低コネクション数(オープンされているコネクション数がもっとも小さいもの)dh: 送信先IPによって割り当てられたハッシュ値をもとに割り当てる(Destination Hashing)sh: 送信元IPによって割り当てられたハッシュ値をもとに割り当てる(Source Hashing)sed: 見込み遅延が最小なものnq: キューなしスケジューリング
備考: IPVSモードでkube-proxyを稼働させるためには、kube-proxyを稼働させる前にNode上でIPVSを有効にしなければなりません。
kube-proxyはIPVSモードで起動する場合、IPVSカーネルモジュールが利用可能かどうかを確認します。
もしIPVSカーネルモジュールが見つからなかった場合、kube-proxyはiptablesモードで稼働するようにフォールバックされます。
このダイアグラムのプロキシモデルにおいて、ServiceのIP:Portに対するトラフィックは、クライアントがKubernetesのServiceやPodについて何も知ることなく適切にバックエンドにプロキシされています。
特定のクライアントからのコネクションが、毎回同一のPodにリダイレクトされるようにするためには、service.spec.sessionAffinityに"ClientIP"を設定することにより、クライアントのIPアドレスに基づいたSessionAffinityを選択することができます(デフォルトは"None")。
また、service.spec.sessionAffinityConfig.clientIP.timeoutSecondsを適切に設定することにより、セッションのタイムアウト時間を設定できます(デフォルトではこの値は18,000で、3時間となります)。
複数のポートを公開するService
いくつかのServiceにおいて、ユーザーは1つ以上のポートを公開する必要があります。Kubernetesは、Serviceオブジェクト上で複数のポートを定義するように設定できます。
Serviceで複数のポートを使用するとき、どのポートかを明確にするために、複数のポート全てに対して名前をつける必要があります。
例えば:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app : MyApp
ports :
- name : http
protocol : TCP
port : 80
targetPort : 9376
- name : https
protocol : TCP
port : 443
targetPort : 9377
備考: KubernetesのPod名と同様に、ポート名は小文字の英数字と-のみ含める必要があります。また、ポート名の最初と最後の文字は英数字である必要があります。
例えば、123-abcやwebという名前は有効で、123_abcや-webは無効です。
ユーザー所有のIPアドレスを選択する
Serviceを作成するリクエストの一部として、ユーザー所有のclusterIPアドレスを指定することができます。
これを行うためには.spec.clusterIPフィールドにセットします。
使用例として、もしすでに再利用したいDNSエントリーが存在していた場合や、特定のIPアドレスを設定されたレガシーなシステムや、IPの再設定が難しい場合です。
ユーザーが指定したIPアドレスは、そのAPIサーバーのために設定されているservice-cluster-ip-rangeというCIDRレンジ内の有効なIPv4またはIPv6アドレスである必要があります。
もし無効なclusterIPアドレスの値を設定してServiceを作成した場合、問題があることを示すためにAPIサーバーはHTTPステータスコード422を返します。
サービスディスカバリー
Kubernetesは、Serviceオブジェクトを見つけ出すために2つの主要なモードをサポートしています。 - それは環境変数とDNSです。
環境変数
PodがNode上で稼働するとき、kubeletはアクティブな各Serviceに対して、環境変数のセットを追加します。
これはDocker links互換性 のある変数(
makeLinkVariables関数 を確認してください)や、より簡単な{SVCNAME}_SERVICE_HOSTや、{SVCNAME}_SERVICE_PORT変数をサポートします。この変数名で使われるService名は大文字に変換され、-は_に変換されます。
例えば、TCPポート6379番を公開していて、さらにclusterIPが10.0.0.11に割り当てられているredis-masterというServiceは、下記のような環境変数を生成します。
REDIS_MASTER_SERVICE_HOST = 10.0.0.11
REDIS_MASTER_SERVICE_PORT = 6379
REDIS_MASTER_PORT = tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP = tcp://10.0.0.11:6379
REDIS_MASTER_PORT_6379_TCP_PROTO = tcp
REDIS_MASTER_PORT_6379_TCP_PORT = 6379
REDIS_MASTER_PORT_6379_TCP_ADDR = 10.0.0.11
備考: Serviceにアクセスする必要のあるPodがあり、クライアントであるそのPodに対して環境変数を使ってポートとclusterIPを公開する場合、クライアントのPodが存在する前に Serviceを作成しなくてはなりません。
そうでない場合、クライアントのPodはそれらの環境変数を作成しません。
ServiceのclusterIPを発見するためにDNSのみを使う場合、このような問題を心配する必要はありません。
DNS
ユーザーはアドオン を使ってKubernetesクラスターにDNS Serviceをセットアップできます(常にセットアップすべきです)。
CoreDNSなどのクラスター対応のDNSサーバーは新しいServiceや、各Service用のDNSレコードのセットのためにKubernetes APIを常に監視します。
もしクラスターを通してDNSが有効になっている場合、全てのPodはDNS名によって自動的にServiceに対する名前解決をするようにできるはずです。
例えば、Kubernetesのmy-nsというNamespace内でmy-serviceというServiceがある場合、KubernetesコントロールプレーンとDNS Serviceが協調して動作し、my-service.my-nsというDNSレコードを作成します。
my-nsというNamespace内のPodはmy-serviceという名前で簡単に名前解決できるはずです(my-service.my-nsでも動作します)。
他のNamespace内でのPodはmy-service.my-nsといった形で指定しなくてはなりません。これらのDNS名は、そのServiceのclusterIPに名前解決されます。
Kubernetesは名前付きのポートに対するDNS SRV(Service)レコードもサポートしています。もしmy-service.my-nsというServiceがhttpという名前のTCPポートを持っていた場合、IPアドレスと同様に、httpのポート番号を探すために_http._tcp.my-service.my-nsというDNS SRVクエリを実行できます。
KubernetesのDNSサーバーはExternalName Serviceにアクセスする唯一の方法です。
DNS Pods と Service にてExternalNameによる名前解決に関するさらなる情報を確認できます。
Headless Service
場合によっては、負荷分散と単一のService IPは不要です。このケースにおいて、clusterIP(.spec.clusterIP)の値を"None"に設定することにより、"Headless"とよばれるServiceを作成できます。
ユーザーは、Kubernetesの実装と紐づくことなく、他のサービスディスカバリーのメカニズムと連携するためにHeadless Serviceを使用できます。
例えば、ユーザーはこのAPI上でカスタムオペレーター を実装することができます。
このServiceにおいては、clusterIPは割り当てられず、kube-proxyはこのServiceをハンドリングしないのと、プラットフォームによって行われるはずの
ロードバランシングやプロキシとしての処理は行われません。DNSがどのように自動で設定されるかは、定義されたServiceが定義されたラベルセレクターを持っているかどうかに依存します。
ラベルセレクターの利用
ラベルセレクターを定義したHeadless Serviceにおいて、EndpointsコントローラーはAPIにおいてEndpointsレコードを作成し、ServiceのバックエンドにあるPodへのIPを直接指し示すためにDNS設定を修正します。
ラベルセレクターなしの場合
ラベルセレクターを定義しないHeadless Serviceにおいては、EndpointsコントローラーはEndpointsレコードを作成しません。
しかしDNSのシステムは下記の2つ両方を探索し、設定します。
ExternalName他の全てのServiceタイプを含む、Service名を共有している全てのEndpointsレコード
Serviceの公開 (Serviceのタイプ)
ユーザーのアプリケーションのいくつかの部分において(例えば、frontendsなど)、ユーザーのクラスターの外部にあるIPアドレス上でServiceを公開したい場合があります。
KubernetesのServiceTypesによって、ユーザーがどのような種類のServiceを使いたいかを指定することが可能です。
デフォルトではClusterIPとなります。
Type項目の値と、そのふるまいは以下のようになります。
また、Serviceを公開するためにIngress も利用可能です。IngressはServiceのタイプではありませんが、クラスターに対するエントリーポイントとして動作します。
Ingressは同一のIPアドレスにおいて、複数のServiceを公開するように、ユーザーの設定した転送ルールを1つのリソースにまとめることができます。
NodePort タイプ
もしtypeフィールドの値をNodePortに設定すると、Kubernetesコントロールプレーンは--service-node-port-rangeフラグによって指定されたレンジのポート(デフォルト: 30000-32767)を割り当てます。
各Nodeはそのポート(各Nodeで同じポート番号)への通信をServiceに転送します。
作成したServiceは、.spec.ports[*].nodePortフィールド内に割り当てられたポートを記述します。
もしポートへの通信を転送する特定のIPを指定したい場合、特定のIPブロックをkube-proxyの--nodeport-addressフラグで指定できます。これはKubernetes v1.10からサポートされています。
このフラグは、コンマ区切りのIPブロックのリスト(例: 10.0.0./8, 192.0.2.0/25)を使用し、kube-proxyがこのNodeに対してローカルとみなすべきIPアドレスの範囲を指定します。
例えば、--nodeport-addresses=127.0.0.0/8というフラグによってkube-proxyを起動した時、kube-proxyはNodePort Serviceのためにループバックインターフェースのみ選択します。--nodeport-addressesのデフォルト値は空のリストになります。これはkube-proxyがNodePort Serviceに対して全てのネットワークインターフェースを利用可能とするべきということを意味します(これは以前のKubernetesのバージョンとの互換性があります)。
もしポート番号を指定したい場合、nodePortフィールドに値を指定できます。コントロールプレーンは指定したポートを割り当てるか、APIトランザクションが失敗したことを知らせるかのどちらかになります。
これは、ユーザーが自分自身で、ポート番号の衝突に関して気をつける必要があることを意味します。
また、ユーザーは有効なポート番号を指定する必要があり、NodePortの使用において、設定された範囲のポートを指定する必要があります。
NodePortの使用は、Kubernetesによって完全にサポートされていないようなユーザー独自の負荷分散を設定をするための有効な方法や、1つ以上のNodeのIPを直接公開するための方法となりえます。
注意点として、このServiceは<NodeIP>:spec.ports[*].nodePortと、.spec.clusterIP:spec.ports[*].portとして疎通可能です。
(もしkube-proxyにおいて--nodeport-addresssesが設定された場合、はフィルターされたNodeIPとなります。)
例えば:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
type : NodePort
selector :
app : MyApp
ports :
# デフォルトでは利便性のため、 `targetPort` は `port` と同じ値にセットされます。
- port : 80
targetPort : 80
# 省略可能なフィールド
# デフォルトでは利便性のため、Kubernetesコントロールプレーンはある範囲から1つポートを割り当てます(デフォルト値の範囲:30000-32767)
nodePort : 30007
LoadBalancer タイプ
外部のロードバランサーをサポートするクラウドプロバイダー上で、typeフィールドにLoadBalancerを設定すると、Service用にロードバランサーがプロビジョニングされます。
実際のロードバランサーの作成は非同期で行われ、プロビジョンされたバランサーの情報は、Serviceの.status.loadBalancerフィールドに記述されます。
例えば:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
clusterIP : 10.0.171.239
type : LoadBalancer
status :
loadBalancer :
ingress :
- ip : 192.0.2.127
外部のロードバランサーからのトラフィックはバックエンドのPodに直接転送されます。クラウドプロバイダーはどのようにそのリクエストをバランシングするかを決めます。
LoadBalancerタイプのサービスで複数のポートが定義されている場合、すべてのポートが同じプロトコルである必要があり、さらにそのプロトコルはTCP、UDP、SCTPのいずれかである必要があります。
いくつかのクラウドプロバイダーにおいて、loadBalancerIPの設定をすることができます。このようなケースでは、そのロードバランサーはユーザーが指定したloadBalancerIPに対してロードバランサーを作成します。
もしloadBalancerIPフィールドの値が指定されていない場合、そのロードバランサーはエフェメラルなIPアドレスに対して作成されます。もしユーザーがloadBalancerIPを指定したが、使っているクラウドプロバイダーがその機能をサポートしていない場合、そのloadBalancerIPフィールドに設定された値は無視されます。
備考: もしSCTPを使っている場合、
LoadBalancer タイプのServiceに関する
使用上の警告 を参照してください。
内部のロードバランサー
複雑な環境において、同一の(仮想)ネットワークアドレスブロック内のServiceからのトラフィックを転送する必要がでてきます。
Split-HorizonなDNS環境において、ユーザーは2つのServiceを外部と内部の両方からのトラフィックをエンドポイントに転送させる必要がでてきます。
ユーザーは、Serviceに対して下記のアノテーションを1つ追加することでこれを実現できます。
追加するアノテーションは、ユーザーが使っているクラウドプロバイダーに依存しています。
[...]
metadata :
name : my-service
annotations :
networking.gke.io/load-balancer-type : "Internal"
[...]
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-internal : 0.0.0.0 /0
[...]
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/azure-load-balancer-internal : "true"
[...]
metadata :
name : my-service
annotations :
service.kubernetes.io/ibm-load-balancer-cloud-provider-ip-type : "private"
[...]
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/openstack-internal-load-balancer : "true"
[...]
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/cce-load-balancer-internal-vpc : "true"
[...]
metadata :
annotations :
service.kubernetes.io/qcloud-loadbalancer-internal-subnetid : subnet-xxxxx
AWSにおけるTLSのサポート
AWS上で稼働しているクラスターにおいて、部分的なTLS/SSLのサポートをするには、LoadBalancer Serviceに対して3つのアノテーションを追加できます。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-ssl-cert : arn:aws:acm:us-east-1:123456789012:certificate/12345678-1234-1234-1234-123456789012
1つ目は、使用する証明書のARNです。これはIAMにアップロードされたサードパーティーが発行した証明書か、AWS Certificate Managerで作成された証明書になります。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-backend-protocol : (https|http|ssl|tcp)
2つ目のアノテーションはPodが利用するプロトコルを指定するものです。HTTPSとSSLの場合、ELBはそのPodが証明書を使って暗号化されたコネクションを介して自分自身のPodを認証すると推測します。
HTTPとHTTPSでは、レイヤー7でのプロキシを選択します。ELBはユーザーとのコネクションを切断し、リクエストを転送するときにリクエストヘッダーをパースして、X-Forwarded-ForヘッダーにユーザーのIPを追加します(Podは接続相手のELBのIPアドレスのみ確認可能です)。
TCPとSSLでは、レイヤー4でのプロキシを選択します。ELBはヘッダーの値を変更せずにトラフィックを転送します。
いくつかのポートがセキュアに保護され、他のポートではセキュアでないような混合した環境において、下記のようにアノテーションを使うことができます。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-backend-protocol : http
service.beta.kubernetes.io/aws-load-balancer-ssl-ports : "443,8443"
上記の例では、もしServiceが80、443、8443と3つのポートを含んでいる場合、443と8443はSSL証明書を使いますが、80では単純にHTTPでのプロキシとなります。
Kubernetes v1.9以降のバージョンからは、Serviceのリスナー用にHTTPSやSSLと事前定義されたAWS SSLポリシー を使用できます。
どのポリシーが使用できるかを確認するために、awsコマンドラインツールを使用できます。
aws elb describe-load-balancer-policies --query 'PolicyDescriptions[].PolicyName'
ユーザーは"service.beta.kubernetes.io/aws-load-balancer-ssl-negotiation-policy"というアノテーションを使用することにより、複数のポリシーの中からどれか1つを指定できます。
例えば:
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-ssl-negotiation-policy : "ELBSecurityPolicy-TLS-1-2-2017-01"
AWS上でのPROXYプロトコルのサポート
AWS上で稼働するクラスターでPROXY protocol のサポートを有効にするために、下記のServiceのアノテーションを使用できます。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-proxy-protocol : "*"
Kubernetesバージョン1.3.0からは、このアノテーションを使用するとELBによってプロキシされた全てのポートが対象になり、そしてそれ以外の場合は構成されません。
AWS上でのELBのアクセスログ
AWS上でのELB Service用のアクセスログを管理するためにはいくつかのアノテーションが使用できます。
service.beta.kubernetes.io/aws-load-balancer-access-log-enabledというアノテーションはアクセスログを有効にするかを設定できます。
service.beta.kubernetes.io/aws-load-balancer-access-log-emit-intervalというアノテーションはアクセスログをパブリッシュするためのインターバル(分)を設定できます。
ユーザーはそのインターバルで5分もしくは60分で設定できます。
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-nameというアノテーションはロードバランサーのアクセスログが保存されるAmazon S3のバケット名を設定できます。
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefixというアノテーションはユーザーが作成したAmazon S3バケットの論理的な階層を指定します。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-access-log-enabled : "true"
# ロードバランサーのアクセスログが有効かどうか。
service.beta.kubernetes.io/aws-load-balancer-access-log-emit-interval : "60"
# アクセスログをパブリッシュするためのインターバル(分)。ユーザーはそのインターバルで5分もしくは60分で設定できます。
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-name : "my-bucket"
# ロードバランサーのアクセスログが保存されるAmazon S3のバケット名。
service.beta.kubernetes.io/aws-load-balancer-access-log-s3-bucket-prefix : "my-bucket-prefix/prod"
# ユーザーが作成したAmazon S3バケットの論理的な階層。例えば: `my-bucket-prefix/prod`
AWSでの接続の中断
古いタイプのELBでの接続の中断は、service.beta.kubernetes.io/aws-load-balancer-connection-draining-enabledというアノテーションを"true"に設定することで管理できます。
service.beta.kubernetes.io/aws-load-balancer-connection-draining-timeoutというアノテーションで、インスタンスを登録解除するまえに既存の接続をオープンにし続けるための最大時間(秒)を指定できます。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-connection-draining-enabled : "true"
service.beta.kubernetes.io/aws-load-balancer-connection-draining-timeout : "60"
他のELBアノテーション
古いタイプのELBを管理するためのアノテーションは他にもあり、下記で紹介します。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-connection-idle-timeout : "60"
# ロードバランサーによってクローズされる前にアイドル状態(コネクションでデータは送信されない)になれる秒数
service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled : "true"
# ゾーンを跨いだロードバランシングが有効かどうか
service.beta.kubernetes.io/aws-load-balancer-additional-resource-tags : "environment=prod,owner=devops"
# ELBにおいて追加タグとして保存されるキー・バリューのペアのコンマ区切りのリスト
service.beta.kubernetes.io/aws-load-balancer-healthcheck-healthy-threshold : ""
# バックエンドへのトラフィックが正常になったと判断するために必要なヘルスチェックの連続成功数
# デフォルトでは2 この値は2から10の間で設定可能
service.beta.kubernetes.io/aws-load-balancer-healthcheck-unhealthy-threshold : "3"
# バックエンドへのトラフィックが異常になったと判断するために必要なヘルスチェックの連続失敗数
# デフォルトでは6 この値は2から10の間で設定可能
service.beta.kubernetes.io/aws-load-balancer-healthcheck-interval : "20"
# 各インスタンスのヘルスチェックのおよそのインターバル(秒)
# デフォルトでは10 この値は5から300の間で設定可能
service.beta.kubernetes.io/aws-load-balancer-healthcheck-timeout : "5"
# ヘルスチェックが失敗したと判断されるレスポンスタイムのリミット(秒)
# この値はservice.beta.kubernetes.io/aws-load-balancer-healthcheck-intervalの値以下である必要があります。
# デフォルトでは5 この値は2から60の間で設定可能
service.beta.kubernetes.io/aws-load-balancer-security-groups : "sg-53fae93f"
# ELBが作成される際に追加されるセキュリティグループのリスト
# service.beta.kubernetes.io/aws-load-balancer-extra-security-groupsアノテーションと異なり
# 元々ELBに付与されていたセキュリティグループを置き換えることになります。
service.beta.kubernetes.io/aws-load-balancer-extra-security-groups : "sg-53fae93f,sg-42efd82e"
# ELBに追加される予定のセキュリティーグループのリスト
service.beta.kubernetes.io/aws-load-balancer-target-node-labels : "ingress-gw,gw-name=public-api"
# ロードバランサーがターゲットノードを指定する際に利用するキーバリューのペアのコンマ区切りリストです。
AWSでのNetwork Load Balancerのサポート
FEATURE STATE: Kubernetes v1.15 [beta]
AWSでNetwork Load Balancerを使用するには、値をnlbに設定してアノテーションservice.beta.kubernetes.io/aws-load-balancer-typeを付与します。
metadata :
name : my-service
annotations :
service.beta.kubernetes.io/aws-load-balancer-type : "nlb"
備考: NLBは特定のインスタンスクラスでのみ稼働します。サポートされているインスタンスタイプを確認するためには、ELBに関する
AWS documentation を参照してください。
古いタイプのElastic Load Balancersとは異なり、Network Load Balancers (NLBs)はクライアントのIPアドレスをNodeに転送します。
もしServiceの.spec.externalTrafficPolicyの値がClusterに設定されていた場合、クライアントのIPアドレスは末端のPodに伝播しません。
.spec.externalTrafficPolicyをLocalに設定することにより、クライアントIPアドレスは末端のPodに伝播します。しかし、これにより、トラフィックの分配が不均等になります。
特定のLoadBalancer Serviceに紐づいたPodがないNodeでは、自動的に割り当てられた.spec.healthCheckNodePortに対するNLBのターゲットグループのヘルスチェックが失敗し、トラフィックを全く受信しません。
均等なトラフィックの分配を実現するために、DaemonSetの使用や、同一のNodeに配備しないようにPodのanti-affinity を設定します。
また、内部のロードバランサー のアノテーションとNLB Serviceを使用できます。
NLBの背後にあるインスタンスに対してクライアントのトラフィックを転送するために、Nodeのセキュリティーグループは下記のようなIPルールに従って変更されます。
Rule
Protocol
Port(s)
IpRange(s)
IpRange Description
ヘルスチェック
TCP
NodePort(s) (.spec.healthCheckNodePort for .spec.externalTrafficPolicy = Local)
VPC CIDR
kubernetes.io/rule/nlb/health=<loadBalancerName>
クライアントのトラフィック
TCP
NodePort(s)
.spec.loadBalancerSourceRanges (デフォルト: 0.0.0.0/0)kubernetes.io/rule/nlb/client=<loadBalancerName>
MTUによるサービスディスカバリー
ICMP
3,4
.spec.loadBalancerSourceRanges (デフォルト: 0.0.0.0/0)kubernetes.io/rule/nlb/mtu=<loadBalancerName>
どのクライアントIPがNLBにアクセス可能かを制限するためには、loadBalancerSourceRangesを指定してください。
spec :
loadBalancerSourceRanges :
- "143.231.0.0/16"
備考: もし.spec.loadBalancerSourceRangesが設定されていない場合、KubernetesはNodeのセキュリティーグループに対して0.0.0.0/0からのトラフィックを許可します。
もしNodeがパブリックなIPアドレスを持っていた場合、NLBでないトラフィックも修正されたセキュリティーグループ内の全てのインスタンスにアクセス可能になってしまうので注意が必要です。
Tencent Kubernetes Engine(TKE)におけるその他のCLBアノテーション
以下に示すように、TKEでCloud Load Balancerを管理するためのその他のアノテーションがあります。
metadata :
name : my-service
annotations :
# 指定したノードでロードバランサーをバインドします
service.kubernetes.io/qcloud-loadbalancer-backends-label : key in (value1, value2)
# 既存のロードバランサーのID
service.kubernetes.io/tke-existed-lbid : lb-6swtxxxx
# ロードバランサー(LB)のカスタムパラメーターは、LBタイプの変更をまだサポートしていません
service.kubernetes.io/service.extensiveParameters : ""
# LBリスナーのカスタムパラメーター
service.kubernetes.io/service.listenerParameters : ""
# ロードバランサーのタイプを指定します
# 有効な値: classic(Classic Cloud Load Balancer)またはapplication(Application Cloud Load Balancer)
service.kubernetes.io/loadbalance-type : xxxxx
# パブリックネットワーク帯域幅の課金方法を指定します
# 有効な値: TRAFFIC_POSTPAID_BY_HOUR(bill-by-traffic)およびBANDWIDTH_POSTPAID_BY_HOUR(bill-by-bandwidth)
service.kubernetes.io/qcloud-loadbalancer-internet-charge-type : xxxxxx
# 帯域幅の値を指定します(値の範囲:[1-2000] Mbps)。
service.kubernetes.io/qcloud-loadbalancer-internet-max-bandwidth-out : "10"
# この注釈が設定されている場合、ロードバランサーはポッドが実行されているノードのみを登録します
# そうでない場合、すべてのノードが登録されます
service.kubernetes.io/local-svc-only-bind-node-with-pod : true
ExternalName タイプ
ExternalNameタイプのServiceは、ServiceをDNS名とマッピングし、my-serviceやcassandraというような従来のラベルセレクターとはマッピングしません。
ユーザーはこれらのServiceにおいてspec.externalNameフィールドの値を指定します。
このServiceの定義では、例えばprodというNamespace内のmy-serviceというServiceをmy.database.example.comにマッピングします。
apiVersion : v1
kind : Service
metadata :
name : my-service
namespace : prod
spec :
type : ExternalName
externalName : my.database.example.com
備考: ExternalNameはIpv4のアドレスの文字列のみ受け付けますが、IPアドレスではなく、数字で構成されるDNS名として受け入れます。
IPv4アドレスに似ているExternalNamesはCoreDNSもしくはIngress-Nginxによって名前解決されず、これはExternalNameは正規のDNS名を指定することを目的としているためです。
IPアドレスをハードコードする場合、
Headless Service の使用を検討してください。
my-service.prod.svc.cluster.localというホストをルックアップするとき、クラスターのDNS Serviceはmy.database.example.comという値をもつCNAMEレコードを返します。
my-serviceへのアクセスは、他のServiceと同じ方法ですが、再接続する際はプロキシや転送を介して行うよりも、DNSレベルで行われることが決定的に異なる点となります。
後にユーザーが使用しているデータベースをクラスター内に移行することになった場合は、Podを起動させ、適切なラベルセレクターやEndpointsを追加し、Serviceのtypeを変更します。
警告: HTTPやHTTPSなどの一般的なプロトコルでExternalNameを使用する際に問題が発生する場合があります。ExternalNameを使用する場合、クラスター内のクライアントが使用するホスト名は、ExternalNameが参照する名前とは異なります。
ホスト名を使用するプロトコルの場合、この違いによりエラーまたは予期しない応答が発生する場合があります。HTTPリクエストがオリジンサーバーが認識しないHost:ヘッダーを持っていたなら、TLSサーバーはクライアントが接続したホスト名に一致する証明書を提供できません。
External IPs
もし1つ以上のクラスターNodeに転送するexternalIPが複数ある場合、Kubernetes ServiceはexternalIPsに指定したIPで公開されます。
そのexternalIP(到達先のIPとして扱われます)のServiceのポートからトラフィックがクラスターに入って来る場合、ServiceのEndpointsのどれか1つに対して転送されます。
externalIPsはKubernetesによって管理されず、それを管理する責任はクラスターの管理者にあります。
Serviceのspecにおいて、externalIPsは他のどのServiceTypesと併用して設定できます。
下記の例では、"my-service"は"198.51.100.32:80" (externalIP:port)のクライアントからアクセス可能です。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app : MyApp
ports :
- name : http
protocol : TCP
port : 80
targetPort : 9376
externalIPs :
- 80.11.12.10
Serviceの欠点
仮想IP用にuserspaceモードのプロキシを使用すると、小規模もしくは中規模のスケールでうまく稼働できますが、1000以上のServiceがあるようなとても大きなクラスターではうまくスケールしません。
これについては、Serviceのデザインプロポーザル にてさらなる詳細を確認できます。
userspaceモードのプロキシの使用は、Serviceにアクセスするパケットの送信元IPアドレスが不明瞭になります。
これは、いくつかの種類のネットワークフィルタリング(ファイアウォールによるフィルタリング)を不可能にします。
iptablesプロキシモードはクラスター内の送信元IPを不明瞭にはしませんが、依然としてロードバランサーやNodePortへ疎通するクライアントに影響があります。
Typeフィールドはネストされた機能としてデザインされています。 - 各レベルの値は前のレベルに対して追加します。
これは全てのクラウドプロバイダーにおいて厳密に要求されていません(例: Google Compute EngineはLoadBalancerを動作させるためにNodePortを割り当てる必要はありませんが、AWSではその必要があります)が、現在のAPIでは要求しています。
仮想IPの実装について
これより前の情報は、ただServiceを使いたいという多くのユーザーにとっては有益かもしれません。しかし、その裏側では多くのことが行われており、理解する価値があります。
衝突の回避
Kubernetesの主要な哲学のうちの一つは、ユーザーは、ユーザー自身のアクションによるミスでないものによって、ユーザーのアクションが失敗するような状況に晒されるべきでないことです。
Serviceリソースの設計において、これはユーザーの指定したポートが衝突する可能性がある場合はそのポートのServiceを作らないことを意味します。これは障害を分離することとなります。
Serviceのポート番号を選択できるようにするために、我々はどの2つのServiceでもポートが衝突しないことを保証します。
Kubernetesは各Serviceに、それ自身のIPアドレスを割り当てることで実現しています。
各Serviceが固有のIPを割り当てられるのを保証するために、内部のアロケーターは、Serviceを作成する前に、etcd内のグローバルの割り当てマップをアトミックに更新します。
そのマップオブジェクトはServiceのIPアドレスの割り当てのためにレジストリー内に存在しなくてはならず、そうでない場合は、Serviceの作成時にIPアドレスが割り当てられなかったことを示すエラーメッセージが表示されます。
コントロールプレーンにおいて、バックグラウンドのコントローラーはそのマップを作成する責務があります(インメモリーのロックが使われていた古いバージョンのKubernetesからのマイグレーションをサポートすることも必要です)。
また、Kubernetesは(例えば、管理者の介入によって)無効な割り当てがされているかをチェックすることと、現時点でどのServiceにも使用されていない割り当て済みIPアドレスのクリーンアップのためにコントローラーを使用します。
ServiceのIPアドレス
実際に固定された向き先であるPodのIPアドレスとは異なり、ServiceのIPは実際には単一のホストによって応答されません。
その代わり、kube-proxyは必要な時に透過的にリダイレクトされる仮想 IPアドレスを定義するため、iptables(Linuxのパケット処理ロジック)を使用します。
クライアントがVIPに接続する時、そのトラフィックは自動的に適切なEndpointsに転送されます。
Service用の環境変数とDNSは、Serviceの仮想IPアドレス(とポート)の面において、自動的に生成されます。
kube-proxyは3つの微妙に異なった動作をするプロキシモード— userspace、iptablesとIPVS — をサポートしています。
Userspace
例として、上記で記述されている画像処理のアプリケーションを考えます。
バックエンドのServiceが作成されたとき、KubernetesのMasterは仮想IPを割り当てます。例えば10.0.0.1などです。
そのServiceのポートが1234で、そのServiceはクラスター内の全てのkube-proxyインスタンスによって監視されていると仮定します。
kube-proxyが新しいServiceを見つけた時、kube-proxyは新しいランダムポートをオープンし、その仮想IPアドレスの新しいポートにリダイレクトするようにiptablesを更新し、そのポート上で新しい接続を待ち受けを開始します。
クライアントがServiceの仮想IPアドレスに接続したとき、iptablesルールが有効になり、そのパケットをプロキシ自身のポートにリダイレクトします。
その"Service プロキシ"はバックエンドPodの対象を選択し、クライアントのトラフィックをバックエンドPodに転送します。
これはServiceのオーナーは、衝突のリスクなしに、求めるどのようなポートも選択できることを意味します。
クライアントは単純にそのIPとポートに対して接続すればよく、実際にどのPodにアクセスしているかを意識しません。
iptables
また画像処理のアプリケーションについて考えます。バックエンドServiceが作成された時、そのKubernetesコントロールプレーンは仮想IPアドレスを割り当てます。例えば10.0.0.1などです。
Serviceのポートが1234で、そのServiceがクラスター内のすべてのkube-proxyインスタンスによって監視されていると仮定します。
kube-proxyが新しいServiceを見つけた時、kube-proxyは仮想IPから各Serviceのルールにリダイレクトされるような、iptablesルールのセットをインストールします。
Service毎のルールは、トラフィックをバックエンドにリダイレクト(Destination NATを使用)しているEndpoints毎のルールに対してリンクしています。
クライアントがServiceの仮想IPアドレスに対して接続しているとき、そのiptablesルールが有効になります。
バックエンドのPodが選択され(SessionAffinityに基づくか、もしくはランダムで選択される)、パケットはバックエンドにリダイレクトされます。
userspaceモードのプロキシとは異なり、パケットは決してuserspaceにコピーされず、kube-proxyは仮想IPのために稼働される必要はなく、またNodeでは変更されていないクライアントIPからトラフィックがきます。
このように同じ基本的なフローは、NodePortまたはLoadBalancerを介してトラフィックがきた場合に、実行され、ただクライアントIPは変更されます。
IPVS
iptablesの処理は、大規模なクラスターの場合劇的に遅くなります。例としてはServiceが10,000ほどある場合です。
IPVSは負荷分散のために設計され、カーネル内のハッシュテーブルに基づいています。そのためIPVSベースのkube-proxyによって、多数のServiceがある場合でも一貫して高パフォーマンスを実現できます。
次第に、IPVSベースのkube-proxyは負荷分散のアルゴリズムはさらに洗練されています(最小接続数、位置ベース、重み付け、永続性など)。
APIオブジェクト
ServiceはKubernetesのREST APIにおいてトップレベルのリソースです。ユーザーはそのAPIオブジェクトに関して、Service API object でさらなる情報を確認できます。
サポートされているプロトコル
TCP
ユーザーはどの種類のServiceにおいてもTCPを利用できます。これはデフォルトのネットワークプロトコルです。
UDP
ユーザーは多くのServiceにおいてUDPを利用できます。 type=LoadBalancerのServiceにおいては、UDPのサポートはこの機能を提供しているクラウドプロバイダーに依存しています。
HTTP
もしクラウドプロバイダーがサポートしている場合、ServiceのEndpointsに転送される外部のHTTP/HTTPSでのリバースプロキシをセットアップするために、LoadBalancerモードでServiceを作成可能です。
備考: ユーザーはまた、HTTP/HTTPS Serviceを公開するために、Serviceの代わりに
Ingress を利用することもできます。
PROXY プロトコル
もしクラウドプロバイダーがサポートしている場合、Kubernetesクラスターの外部のロードバランサーを設定するためにLoadBalancerモードでServiceを利用できます。これはPROXY protocol がついた接続を転送します。
ロードバランサーは、最初の一連のオクテットを送信します。
下記のような例となります。
PROXY TCP4 192.0.2.202 10.0.42.7 12345 7\r\n
クライアントからのデータのあとに追加されます。
SCTP
FEATURE STATE: Kubernetes v1.19 [beta]
KubernetesはService、Endpoints、EndpointSlice、NetworkPolicyとPodの定義においてprotocolフィールドの値でSCTPをサポートしています。ベータ版の機能のため、この機能はデフォルトで有効になっています。SCTPをクラスターレベルで無効にするには、クラスター管理者はAPI ServerにおいてSCTPSupport フィーチャーゲート を--feature-gates=SCTPSupport=false,…と設定して無効にする必要があります。
そのフィーチャーゲートが有効になった時、ユーザーはService、Endpoints、EndpointSlice、NetworkPolicy、またはPodのprotocolフィールドにSCTPを設定できます。
Kubernetesは、TCP接続と同様に、SCTPアソシエーションに応じてネットワークをセットアップします。
警告
マルチホームSCTPアソシエーションのサポート
警告: マルチホームSCTPアソシエーションのサポートは、複数のインターフェースとPodのIPアドレスの割り当てをサポートできるCNIプラグインを要求します。
マルチホームSCTPアソシエーションにおけるNATは、対応するカーネルモジュール内で特別なロジックを要求します。
type=LoadBalancer Service について
警告: クラウドプロバイダーのロードバランサーの実装がプロトコルとしてSCTPをサポートしている場合は、type がLoadBalancerで protocolがSCTPの場合でのみサービスを作成できます。
そうでない場合、Serviceの作成要求はリジェクトされます。現時点でのクラウドのロードバランサーのプロバイダー(Azure、AWS、CloudStack、GCE、OpenStack)は全てSCTPのサポートをしていません。
Windows
警告: SCTPはWindowsベースのNodeではサポートされていません。
Userspace kube-proxy
警告: kube-proxyはuserspaceモードにおいてSCTPアソシエーションの管理をサポートしません。
次の項目
5.2 - Ingress
FEATURE STATE: Kubernetes v1.19 [stable]
クラスター内のServiceに対する外部からのアクセス(主にHTTP)を管理するAPIオブジェクトです。
Ingressは負荷分散、SSL終端、名前ベースの仮想ホスティングの機能を提供します。
用語
簡単のために、このガイドでは次の用語を定義します。
ノード: Kubernetes内のワーカーマシンで、クラスターの一部です。
クラスター: Kubernetesによって管理されているコンテナ化されたアプリケーションを実行させるノードの集合です。この例や、多くのKubernetesによるデプロイでは、クラスター内のノードはインターネットに公開されていません。
エッジルーター: クラスターでファイアウォールのポリシーを強制するルーターです。クラウドプロバイダーが管理するゲートウェイや、物理的なハードウェアの一部である場合もあります。
クラスターネットワーク: 物理的または論理的な繋がりの集合で、Kubernetesのネットワークモデル によって、クラスター内でのコミュニケーションを司るものです。
Service: ラベル セレクターを使ったPodの集合を特定するKubernetes Service です。特に指定がない限り、Serviceはクラスターネットワーク内でのみ疎通可能な仮想IPを持つものとして扱われます。
Ingressとは何か
Ingress はクラスター外からクラスター内Service へのHTTPとHTTPSのルートを公開します。トラフィックのルーティングはIngressリソース上で定義されるルールによって制御されます。
全てのトラフィックを単一のServiceに送る単純なIngressの例を示します。
図. Ingress
IngressはServiceに対して、外部疎通できるURL、負荷分散トラフィック、SSL/TLS終端の機能や、名前ベースの仮想ホスティングを提供するように設定できます。Ingressコントローラー は通常はロードバランサーを使用してIngressの機能を実現しますが、エッジルーターや、追加のフロントエンドを構成してトラフィックの処理を支援することもできます。
Ingressは任意のポートやプロトコルを公開しません。HTTPやHTTPS以外のServiceをインターネットに公開する場合、Service.Type=NodePort やService.Type=LoadBalancer のServiceタイプを一般的には使用します。
Ingressを使用する上での前提条件
Ingressを提供するためにはIngressコントローラー が必要です。Ingressリソースを作成するのみでは何の効果もありません。
ingress-nginx のようなIngressコントローラーのデプロイが必要な場合があります。いくつかのIngressコントローラー の中から選択してください。
理想的には、全てのIngressコントローラーはリファレンスの仕様を満たすはずです。しかし実際には、各Ingressコントローラーは微妙に異なる動作をします。
備考: Ingressコントローラーのドキュメントを確認して、選択する際の注意点について理解してください。
Ingressリソース
Ingressリソースの最小構成の例は以下のとおりです。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : minimal-ingress
annotations :
nginx.ingress.kubernetes.io/rewrite-target : /
spec :
ingressClassName : nginx-example
rules :
- http :
paths :
- path : /testpath
pathType : Prefix
backend :
service :
name : test
port :
number : 80
IngressにはapiVersion、kind、metadataやspecフィールドが必要です。Ingressオブジェクトの名前は、有効なDNSサブドメイン名 である必要があります。設定ファイルに関する一般的な情報は、アプリケーションのデプロイ 、コンテナの設定 、リソースの管理 を参照してください。Ingressでは、Ingressコントローラーに依存しているいくつかのオプションの設定をするためにアノテーションを一般的に使用します。例としては、rewrite-targetアノテーション などがあります。Ingressコントローラー の種類が異なれば、サポートするアノテーションも異なります。サポートされているアノテーションについて学ぶためには、使用するIngressコントローラーのドキュメントを確認してください。
Ingress Spec は、ロードバランサーやプロキシサーバーを設定するために必要な全ての情報を持っています。最も重要なものとして、外部からくる全てのリクエストに対して一致したルールのリストを含みます。IngressリソースはHTTP(S)トラフィックに対してのルールのみサポートしています。
ingressClassNameが省略された場合、デフォルトのIngressClass を定義する必要があります。
デフォルトのIngressClassを定義しなくても動作するIngressコントローラーがいくつかあります。例えば、Ingress-NGINXコントローラーはフラグ
--watch-ingress-without-classで設定できます。ただし、下記 のようにデフォルトのIngressClassを指定することを推奨します 。
Ingressのルール
各HTTPルールは以下の情報を含みます。
オプションで設定可能なホスト名。上記のリソースの例では、ホスト名が指定されていないので、そのルールは指定されたIPアドレスを経由する全てのインバウンドHTTPトラフィックに適用されます。ホスト名が指定されていると(例: foo.bar.com)、そのルールは指定されたホストに対して適用されます。
パスのリスト(例: /testpath)。各パスにはservice.nameとservice.port.nameまたはservice.port.numberで定義されるバックエンドが関連づけられます。ロードバランサーがトラフィックを関連づけられたServiceに転送するために、外部からくるリクエストのホスト名とパスが条件と一致させる必要があります。
バックエンドはServiceドキュメント に書かれているようなService名とポート名の組み合わせ、またはCRD によるカスタムリソースバックエンド です。Ingressで設定されたホスト名とパスのルールに一致するHTTP(とHTTPS)のリクエストは、リスト内のバックエンドに対して送信されます。
Ingressコントローラーでは、defaultBackendが設定されていることがあります。これはSpec内で指定されているパスに一致しないようなリクエストのためのバックエンドです。
デフォルトのバックエンド
ルールが設定されていないIngressは、全てのトラフィックを単一のデフォルトのバックエンドに転送します。.spec.defaultBackendはその場合にリクエストを処理するバックエンドになります。defaultBackendは、Ingressコントローラー のオプション設定であり、Ingressリソースでは指定されていません。.spec.rulesを設定しない場合、.spec.defaultBackendの設定は必須です。defaultBackendが設定されていない場合、どのルールにもマッチしないリクエストの処理は、Ingressコントローラーに任されます(このケースをどう処理するかは、お使いのIngressコントローラーのドキュメントを参照してください)。
HTTPリクエストがIngressオブジェクトのホスト名とパスの条件に1つも一致しない時、そのトラフィックはデフォルトのバックエンドに転送されます。
リソースバックエンド
ResourceバックエンドはIngressオブジェクトと同じnamespaceにある他のKubernetesリソースを指すObjectRefです。
ResourceはServiceの設定とは排他であるため、両方を指定するとバリデーションに失敗します。
Resourceバックエンドの一般的な用途は、静的なアセットが入ったオブジェクトストレージバックエンドにデータを導入することです。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : ingress-resource-backend
spec :
defaultBackend :
resource :
apiGroup : k8s.example.com
kind : StorageBucket
name : static-assets
rules :
- http :
paths :
- path : /icons
pathType : ImplementationSpecific
backend :
resource :
apiGroup : k8s.example.com
kind : StorageBucket
name : icon-assets
上記のIngressを作成した後に、次のコマンドで参照することができます。
kubectl describe ingress ingress-resource-backend
Name: ingress-resource-backend
Namespace: default
Address:
Default backend: APIGroup: k8s.example.com, Kind: StorageBucket, Name: static-assets
Rules:
Host Path Backends
---- ---- --------
*
/icons APIGroup: k8s.example.com, Kind: StorageBucket, Name: icon-assets
Annotations: <none>
Events: <none>
パスのタイプ
Ingressのそれぞれのパスは対応するパスのタイプを持ちます。pathTypeが明示的に指定されていないパスはバリデーションに通りません。サポートされているパスのタイプは3種類あります。
ImplementationSpecific(実装に特有): このパスタイプでは、パスとの一致はIngressClassに依存します。Ingressの実装はこれを独立したpathTypeと扱うことも、PrefixやExactと同一のパスタイプと扱うこともできます。
Exact: 大文字小文字を区別して完全に一致するURLパスと一致します。
Prefix: /で分割されたURLと前方一致で一致します。大文字小文字は区別され、パスの要素対要素で比較されます。パス要素は/で分割されたパスの中のラベルのリストを参照します。リクエストがパス p に一致するのは、Ingressのパス p がリクエストパス p と要素単位で前方一致する場合です。
備考: パスの最後の要素がリクエストパスの最後の要素の部分文字列である場合、これは一致しません(例えば、/foo/barは/foo/bar/bazと一致しますが、/foo/barbazとは一致しません)。
例
タイプ
パス
リクエストパス
一致するか
Prefix
/(全てのパス)
はい
Exact
/foo/fooはい
Exact
/foo/barいいえ
Exact
/foo/foo/いいえ
Exact
/foo//fooいいえ
Prefix
/foo/foo, /foo/はい
Prefix
/foo//foo, /foo/はい
Prefix
/aaa/bb/aaa/bbbいいえ
Prefix
/aaa/bbb/aaa/bbbはい
Prefix
/aaa/bbb//aaa/bbbはい、末尾のスラッシュは無視
Prefix
/aaa/bbb/aaa/bbb/はい、末尾のスラッシュと一致
Prefix
/aaa/bbb/aaa/bbb/cccはい、パスの一部と一致
Prefix
/aaa/bbb/aaa/bbbxyzいいえ、接頭辞と一致しない
Prefix
/, /aaa/aaa/cccはい、接頭辞/aaaと一致
Prefix
/, /aaa, /aaa/bbb/aaa/bbbはい、接頭辞/aaa/bbbと一致
Prefix
/, /aaa, /aaa/bbb/cccはい、接頭辞/と一致
Prefix
/aaa/cccいいえ、デフォルトバックエンドを使用
Mixed
/foo (Prefix), /foo (Exact)/fooはい、Exactが優先
複数のパスとの一致
リクエストがIngressの複数のパスと一致することがあります。そのような場合は、最も長くパスが一致したものが優先されます。2つのパスが同等に一致した場合は、完全一致が前方一致よりも優先されます。
ホスト名のワイルドカード
ホストは正確に一致する(例えばfoo.bar.com)かワイルドカード(例えば*.foo.com)とすることができます。
正確な一致ではHTTPヘッダーのhostがhostフィールドと一致することが必要です。
ワイルドカードによる一致では、HTTPヘッダーのhostがワイルドカードルールに沿って後方一致することが必要です。
Host
Hostヘッダー
一致するか
*.foo.combar.foo.com共通の接尾辞により一致
*.foo.combaz.bar.foo.com一致しない。ワイルドカードは単一のDNSラベルのみを対象とする
*.foo.comfoo.com一致しない。ワイルドカードは単一のDNSラベルのみを対象とする
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : ingress-wildcard-host
spec :
rules :
- host : "foo.bar.com"
http :
paths :
- pathType : Prefix
path : "/bar"
backend :
service :
name : service1
port :
number : 80
- host : "*.foo.com"
http :
paths :
- pathType : Prefix
path : "/foo"
backend :
service :
name : service2
port :
number : 80
Ingress Class
Ingressは異なったコントローラーで実装されうるため、しばしば異なった設定を必要とします。
各Ingressはクラス、つまりIngressClassリソースへの参照を指定する必要があります。IngressClassリソースには、このクラスを実装するコントローラーの名前などの追加設定が含まれています。
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
name : external-lb
spec :
controller : example.com/ingress-controller
parameters :
apiGroup : k8s.example.com
kind : IngressParameters
name : external-lb
IngressClassの.spec.parametersフィールドを使って、そのIngressClassに関連する設定を持っている別のリソースを参照することができます。
使用するパラメーターの種類は、IngressClassの.spec.controllerフィールドで指定したIngressコントローラーに依存します。
IngressClassスコープ
Ingressコントローラーによっては、クラスター全体で設定したパラメーターを使用できる場合もあれば、1つのNamespaceに対してのみ設定したパラメーターを使用できる場合もあります。
IngressClassパラメーターのデフォルトのスコープは、クラスター全体です。
.spec.parametersフィールドを設定して.spec.parameters.scopeフィールドを設定しなかった場合、または.spec.parameters.scopeをClusterに設定した場合、IngressClassはクラスタースコープのリソースを参照します。
パラーメーターのkind(およびapiGroup)はクラスタースコープのAPI(カスタムリソースの場合もあり)を指し、パラメーターのnameはそのAPIの特定のクラスタースコープのリソースを特定します。
例えば:
---
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
name : external-lb-1
spec :
controller : example.com/ingress-controller
parameters :
# このIngressClassのパラメーターは「external-config-1」という名前の
# ClusterIngressParameter(APIグループk8s.example.net)で指定されています。この定義は、Kubernetesに
# クラスタースコープのパラメーターリソースを探すように指示しています。
scope : Cluster
apiGroup : k8s.example.net
kind : ClusterIngressParameter
name : external-config-1
FEATURE STATE: Kubernetes v1.23 [stable]
.spec.parametersフィールドを設定して.spec.parameters.scopeフィールドをNamespaceに設定した場合、IngressClassはNamespaceスコープのリソースを参照します。また.spec.parameters内のnamespaceフィールドには、使用するパラメーターが含まれているNamespaceを設定する必要があります。
パラメーターのkind(およびapiGroup)はNamespaceスコープのAPI(例えば:ConfigMap)を指し、パラメーターのnameはnamespaceで指定したNamespace内の特定のリソースを特定します。
Namespaceスコープのパラメーターはクラスターオペレーターがワークロードに使用される設定(例えば:ロードバランサー設定、APIゲートウェイ定義)に対する制御を委譲するのに役立ちます。クラスタースコープパラメーターを使用した場合は以下のいずれかになります:
クラスターオペレーターチームは、新しい設定変更が適用されるたびに、別のチームの変更内容を承認する必要があります。
クラスターオペレーターは、アプリケーションチームがクラスタースコープのパラメーターリソースに変更を加えることができるように、RBAC のRoleやRoleBindingといった、特定のアクセス制御を定義する必要があります。
IngressClass API自体は常にクラスタースコープです。
以下はNamespaceスコープのパラメーターを参照しているIngressClassの例です:
---
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
name : external-lb-2
spec :
controller : example.com/ingress-controller
parameters :
# このIngressClassのパラメーターは「external-config」という名前の
# IngressParameter(APIグループk8s.example.com)で指定されています。
# このリソースは「external-configuration」というNamespaceにあります。
scope : Namespace
apiGroup : k8s.example.com
kind : IngressParameter
namespace : external-configuration
name : external-config
非推奨のアノテーション
Kubernetes 1.18でIngressClassリソースとingressClassNameフィールドが追加される前は、Ingressの種別はIngressのkubernetes.io/ingress.classアノテーションにより指定されていました。
このアノテーションは正式に定義されたことはありませんが、Ingressコントローラーに広くサポートされています。
Ingressの新しいingressClassNameフィールドはこのアノテーションを置き換えるものですが、完全に等価ではありません。
アノテーションは一般にIngressを実装すべきIngressのコントローラーの名称を示していましたが、フィールドはIngressClassリソースへの参照であり、Ingressのコントローラーの名称を含む追加のIngressの設定情報を含んでいます。
デフォルトのIngressClass
特定のIngressClassをクラスターのデフォルトとしてマークすることができます。
IngressClassリソースのingressclass.kubernetes.io/is-default-classアノテーションをtrueに設定すると、ingressClassNameフィールドが指定されないIngressにはこのデフォルトIngressClassが割り当てられるようになります。
注意: 複数のIngressClassをクラスターのデフォルトに設定すると、アドミッションコントローラーはingressClassNameが指定されていない新しいIngressオブジェクトを作成できないようにします。クラスターのデフォルトIngressClassを1つ以下にすることで、これを解消することができます。
Ingressコントローラーの中には、デフォルトのIngressClassを定義しなくても動作するものがあります。 例えば、Ingress-NGINXコントローラーはフラグ
--watch-ingress-without-classで設定することができます。ただし、デフォルトIngressClassを指定することを推奨します :
apiVersion : networking.k8s.io/v1
kind : IngressClass
metadata :
labels :
app.kubernetes.io/component : controller
name : nginx-example
annotations :
ingressclass.kubernetes.io/is-default-class : "true"
spec :
controller : k8s.io/ingress-nginx
Ingressのタイプ
単一ServiceのIngress
Kubernetesには、単一のServiceを公開できるようにする既存の概念があります(Ingressの代替案 を参照してください)。ルールなしでデフォルトのバックエンド を指定することにより、Ingressでこれを実現することもできます。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : test-ingress
spec :
defaultBackend :
service :
name : test
port :
number : 80
kubectl apply -fを実行してIngressを作成すると、その作成したIngressの状態を確認することができます。
kubectl get ingress test-ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
test-ingress external-lb * 203.0.113.123 80 59s
203.0.113.123はIngressコントローラーによって割り当てられたIPで、作成したIngressを利用するためのものです。
備考: IngressコントローラーとロードバランサーがIPアドレス割り当てるのに1、2分ほどかかります。この間、ADDRESSの情報は<pending>となっているのを確認できます。
リクエストのシンプルなルーティング
ファンアウト設定では単一のIPアドレスのトラフィックを、リクエストされたHTTP URIに基づいて1つ以上のServiceに転送します。Ingressによってロードバランサーの数を少なくすることができます。例えば、以下のように設定します。
図. Ingressファンアウト
Ingressを以下のように設定します。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : simple-fanout-example
spec :
rules :
- host : foo.bar.com
http :
paths :
- path : /foo
pathType : Prefix
backend :
service :
name : service1
port :
number : 4200
- path : /bar
pathType : Prefix
backend :
service :
name : service2
port :
number : 8080
Ingressをkubectl apply -fによって作成したとき:
kubectl describe ingress simple-fanout-example
Name: simple-fanout-example
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:4200 (10.8.0.90:4200)
/bar service2:8080 (10.8.0.91:8080)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 22s loadbalancer-controller default/test
IngressコントローラーはService(service1、service2)が存在する限り、Ingressの条件を満たす実装固有のロードバランサーを構築します。
構築が完了すると、ADDRESSフィールドでロードバランサーのアドレスを確認できます。
名前ベースのバーチャルホスティング
名前ベースのバーチャルホストは、HTTPトラフィックを同一のIPアドレスの複数のホスト名に転送することをサポートしています。
図. Ingress名前ベースのバーチャルホスティング
以下のIngress設定は、ロードバランサーに対して、Hostヘッダー に基づいてリクエストを転送するように指示するものです。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : name-virtual-host-ingress
spec :
rules :
- host : foo.bar.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service1
port :
number : 80
- host : bar.foo.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service2
port :
number : 80
rules項目でのホストの設定がないIngressを作成すると、IngressコントローラーのIPアドレスに対するwebトラフィックは、要求されている名前ベースのバーチャルホストなしにマッチさせることができます。
例えば、以下のIngressはfirst.bar.comに対するトラフィックをservice1へ、second.foo.comに対するトラフィックをservice2へ、リクエストにおいてホスト名が指定されていない(リクエストヘッダーがないことを意味します)トラフィックはservice3へ転送します。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : name-virtual-host-ingress-no-third-host
spec :
rules :
- host : first.bar.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service1
port :
number : 80
- host : second.bar.com
http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service2
port :
number : 80
- http :
paths :
- pathType : Prefix
path : "/"
backend :
service :
name : service3
port :
number : 80
TLS
TLSの秘密鍵と証明書を含んだSecret を指定することにより、Ingressをセキュアにできます。Ingressは単一のTLSポートである443番ポートのみサポートし、IngressでTLS終端を行うことを想定しています。IngressからServiceやPodへのトラフィックは平文です。IngressのTLS設定のセクションで異なるホストを指定すると、それらのホストはSNI TLSエクステンション(IngressコントローラーがSNIをサポートしている場合)を介して指定されたホスト名に対し、同じポート上で多重化されます。TLSのSecretはtls.crtとtls.keyというキーを含む必要があり、TLSを使用するための証明書と秘密鍵を含む値となります。以下がその例です。
apiVersion : v1
kind : Secret
metadata :
name : testsecret-tls
namespace : default
data :
tls.crt : base64 encoded cert
tls.key : base64 encoded key
type : kubernetes.io/tls
IngressでこのSecretを参照すると、クライアントとロードバランサー間の通信にTLSを使用するようIngressコントローラーに指示することになります。作成したTLS Secretは、https-example.foo.comの完全修飾ドメイン名(FQDN)とも呼ばれる共通名(CN)を含む証明書から作成したものであることを確認する必要があります。
備考: デフォルトルールではTLSが機能しない可能性があることに注意してください。
これは取り得る全てのサブドメインに対する証明書を発行する必要があるからです。
そのため、tlsセクションのhostsはrulesセクションのhostと明示的に一致する必要があります。
apiVersion : networking.k8s.io/v1
kind : Ingress
metadata :
name : tls-example-ingress
spec :
tls :
- hosts :
- https-example.foo.com
secretName : testsecret-tls
rules :
- host : https-example.foo.com
http :
paths :
- path : /
pathType : Prefix
backend :
service :
name : service1
port :
number : 80
備考: サポートされるTLSの機能はIngressコントローラーによって違いがあります。利用する環境でTLSがどのように動作するかを理解するためには、
nginx や、
GCE 、または他のプラットフォーム固有のIngressコントローラーのドキュメントを確認してください。
負荷分散
Ingressコントローラーは、負荷分散アルゴリズムやバックエンドの重みスキームなど、すべてのIngressに適用されるいくつかの負荷分散ポリシーの設定とともにブートストラップされます。発展した負荷分散のコンセプト(例: セッションの永続化、動的重み付けなど)はIngressによってサポートされていません。代わりに、それらの機能はService用のロードバランサーを介して利用できます。
ヘルスチェックの機能はIngressによって直接には公開されていませんが、Kubernetesにおいて、同等の機能を提供するReadiness Probe のようなコンセプトが存在することは注目に値します。コントローラーがどのようにヘルスチェックを行うかについては、コントローラーのドキュメントを参照してください(例えばnginx 、またはGCE )。
Ingressの更新
リソースを編集することで、既存のIngressに対して新しいホストを追加することができます。
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 35s loadbalancer-controller default/test
kubectl edit ingress test
このコマンドを実行すると既存の設定をYAMLフォーマットで編集するエディターが表示されます。新しいホストを追加するには、リソースを修正してください。
spec :
rules :
- host : foo.bar.com
http :
paths :
- backend :
service :
name : service1
port :
number : 80
path : /foo
pathType : Prefix
- host : bar.baz.com
http :
paths :
- backend :
service :
name : service2
port :
number : 80
path : /foo
pathType : Prefix
変更を保存した後、kubectlはAPIサーバー内のリソースを更新し、Ingressコントローラーに対してロードバランサーの再設定を指示します。
変更内容を確認してください。
kubectl describe ingress test
Name: test
Namespace: default
Address: 178.91.123.132
Default backend: default-http-backend:80 (10.8.2.3:8080)
Rules:
Host Path Backends
---- ---- --------
foo.bar.com
/foo service1:80 (10.8.0.90:80)
bar.baz.com
/foo service2:80 (10.8.0.91:80)
Annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ADD 45s loadbalancer-controller default/test
修正されたIngressのYAMLファイルに対してkubectl replace -fを実行することで、同様の結果を得られます。
アベイラビリティーゾーンをまたいだ障害について
障害のあるドメインをまたいでトラフィックを分散する手法は、クラウドプロバイダーによって異なります。詳細に関して、Ingress コントローラー のドキュメントを参照してください。
Ingressの代替案
Ingressリソースを直接含まずにサービスを公開する方法は複数あります。
次の項目
5.3 - サービスとアプリケーションの接続
コンテナを接続するためのKubernetesモデル
継続的に実行され、複製されたアプリケーションの準備ができたので、ネットワーク上で公開することが可能になります。
Kubernetesのネットワークのアプローチについて説明する前に、Dockerの「通常の」ネットワーク手法と比較することが重要です。
デフォルトでは、Dockerはホストプライベートネットワーキングを使用するため、コンテナは同じマシン上にある場合にのみ他のコンテナと通信できます。
Dockerコンテナがノード間で通信するには、マシンのIPアドレスにポートを割り当ててから、コンテナに転送またはプロキシする必要があります。
これは明らかに、コンテナが使用するポートを非常に慎重に調整するか、ポートを動的に割り当てる必要があることを意味します。
コンテナを提供する複数の開発者やチーム間でポートの割り当てを調整することは、規模的に大変困難であり、ユーザが制御できないクラスターレベルの問題にさらされます。
Kubernetesでは、どのホストで稼働するかに関わらず、Podが他のPodと通信できると想定しています。
すべてのPodに独自のクラスタープライベートIPアドレスを付与するため、Pod間のリンクを明示的に作成したり、コンテナポートをホストポートにマップしたりする必要はありません。
これは、Pod内のコンテナがすべてlocalhostの相互のポートに到達でき、クラスター内のすべてのPodがNATなしで相互に認識できることを意味します。
このドキュメントの残りの部分では、このようなネットワークモデルで信頼できるサービスを実行する方法について詳しく説明します。
このガイドでは、シンプルなnginxサーバーを使用して概念実証を示します。
Podをクラスターに公開する
前の例でネットワークモデルを紹介しましたが、再度ネットワークの観点に焦点を当てましょう。
nginx Podを作成し、コンテナポートの仕様を指定していることに注意してください。
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
spec :
selector :
matchLabels :
run : my-nginx
replicas : 2
template :
metadata :
labels :
run : my-nginx
spec :
containers :
- name : my-nginx
image : nginx
ports :
- containerPort : 80
これにより、クラスター内のどのノードからでもアクセスできるようになります。
Podが実行されているノードを確認します:
kubectl apply -f ./run-my-nginx.yaml
kubectl get pods -l run = my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-jr4a2 1/1 Running 0 13s 10.244.3.4 kubernetes-minion-905m
my-nginx-3800858182-kna2y 1/1 Running 0 13s 10.244.2.5 kubernetes-minion-ljyd
PodのIPを確認します:
kubectl get pods -l run = my-nginx -o yaml | grep podIP
podIP: 10.244.3.4
podIP: 10.244.2.5
クラスター内の任意のノードにSSH接続し、両方のIPにcurl接続できるはずです。
コンテナはノードでポート80を使用していない ことに注意してください。
また、Podにトラフィックをルーティングする特別なNATルールもありません。
つまり、同じcontainerPortを使用して同じノードで複数のnginx Podを実行し、IPを使用してクラスター内の他のPodやノードからそれらにアクセスできます。
Dockerと同様に、ポートは引き続きホストノードのインターフェースに公開できますが、ネットワークモデルにより、この必要性は根本的に減少します。
興味があれば、これをどのように達成するか について詳しく読むことができます。
Serviceを作成する
そのため、フラットでクラスター全体のアドレス空間でnginxを実行するPodがあります。
理論的には、これらのPodと直接通信することができますが、ノードが停止するとどうなりますか?
Podはそれで死に、Deploymentは異なるIPを持つ新しいものを作成します。
これは、Serviceが解決する問題です。
Kubernetes Serviceは、クラスター内のどこかで実行されるPodの論理セットを定義する抽象化であり、すべて同じ機能を提供します。
作成されると、各Serviceには一意のIPアドレス(clusterIPとも呼ばれます)が割り当てられます。
このアドレスはServiceの有効期間に関連付けられており、Serviceが動作している間は変更されません。
Podは、Serviceと通信するように構成でき、Serviceへの通信は、ServiceのメンバーであるPodに自動的に負荷分散されることを認識できます。
2つのnginxレプリカのサービスをkubectl exposeで作成できます:
kubectl expose deployment/my-nginx
service/my-nginx exposed
これは次のyamlをkubectl apply -fすることと同等です:
apiVersion : v1
kind : Service
metadata :
name : my-nginx
labels :
run : my-nginx
spec :
ports :
- port : 80
protocol : TCP
selector :
run : my-nginx
この仕様は、run:my-nginxラベルを持つ任意のPodのTCPポート80をターゲットとするサービスを作成し、抽象化されたサービスポートでPodを公開します(targetPort:はコンテナがトラフィックを受信するポート、port:は抽象化されたServiceのポートであり、他のPodがServiceへのアクセスに使用する任意のポートにすることができます)。
サービス定義でサポートされているフィールドのリストはService APIオブジェクトを参照してください。
Serviceを確認します:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx ClusterIP 10.0.162.149 <none> 80/TCP 21s
前述のように、ServiceはPodのグループによってサポートされています。
これらのPodはエンドポイントを通じて公開されます。
Serviceのセレクターは継続的に評価され、結果はmy-nginxという名前のEndpointsオブジェクトにPOSTされます。
Podが終了すると、エンドポイントから自動的に削除され、Serviceのセレクターに一致する新しいPodが自動的にエンドポイントに追加されます。
エンドポイントを確認し、IPが最初のステップで作成されたPodと同じであることを確認します:
kubectl describe svc my-nginx
Name: my-nginx
Namespace: default
Labels: run=my-nginx
Annotations: <none>
Selector: run=my-nginx
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.0.162.149
IPs: 10.0.162.149
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.5:80,10.244.3.4:80
Session Affinity: None
Events: <none>
NAME ENDPOINTS AGE
my-nginx 10.244.2.5:80,10.244.3.4:80 1m
クラスター内の任意のノードから、<CLUSTER-IP>:<PORT>でnginx Serviceにcurl接続できるようになりました。
Service IPは完全に仮想的なもので、ホスト側のネットワークには接続できないことに注意してください。
この仕組みに興味がある場合は、サービスプロキシ の詳細をお読みください。
Serviceにアクセスする
Kubernetesは、環境変数とDNSの2つの主要なService検索モードをサポートしています。
前者はそのまま使用でき、後者はCoreDNSクラスターアドオン を必要とします。
備考: サービス環境変数が望ましくない場合(予想されるプログラム変数と衝突する可能性がある、処理する変数が多すぎる、DNSのみを使用するなど)、
Pod仕様 で
enableServiceLinksフラグを
falseに設定することでこのモードを無効にできます。
環境変数
ノードでPodが実行されると、kubeletはアクティブな各サービスの環境変数のセットを追加します。
これにより、順序付けの問題が発生します。
理由を確認するには、実行中のnginx Podの環境を調べます(Pod名は環境によって異なります):
kubectl exec my-nginx-3800858182-jr4a2 -- printenv | grep SERVICE
KUBERNETES_SERVICE_HOST=10.0.0.1
KUBERNETES_SERVICE_PORT=443
KUBERNETES_SERVICE_PORT_HTTPS=443
サービスに言及がないことに注意してください。これは、サービスの前にレプリカを作成したためです。
これのもう1つの欠点は、スケジューラーが両方のPodを同じマシンに配置し、サービスが停止した場合にサービス全体がダウンする可能性があることです。
2つのPodを強制終了し、Deploymentがそれらを再作成するのを待つことで、これを正しい方法で実行できます。
今回は、サービスはレプリカの「前」に存在します。
これにより、スケジューラーレベルのサービスがPodに広がり(すべてのノードの容量が等しい場合)、適切な環境変数が提供されます:
kubectl scale deployment my-nginx --replicas= 0; kubectl scale deployment my-nginx --replicas= 2;
kubectl get pods -l run = my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-e9ihh 1/1 Running 0 5s 10.244.2.7 kubernetes-minion-ljyd
my-nginx-3800858182-j4rm4 1/1 Running 0 5s 10.244.3.8 kubernetes-minion-905m
Podは強制終了されて再作成されるため、異なる名前が付いていることに気付くでしょう。
kubectl exec my-nginx-3800858182-e9ihh -- printenv | grep SERVICE
KUBERNETES_SERVICE_PORT=443
MY_NGINX_SERVICE_HOST=10.0.162.149
KUBERNETES_SERVICE_HOST=10.0.0.1
MY_NGINX_SERVICE_PORT=80
KUBERNETES_SERVICE_PORT_HTTPS=443
DNS
Kubernetesは、DNS名を他のServiceに自動的に割り当てるDNSクラスターアドオンサービスを提供します。
クラスターで実行されているかどうかを確認できます:
kubectl get services kube-dns --namespace= kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.0.0.10 <none> 53/UDP,53/TCP 8m
このセクションの残りの部分は、寿命の長いIP(my-nginx)を持つServiceと、そのIPに名前を割り当てたDNSサーバーがあることを前提にしています。ここではCoreDNSクラスターアドオン(アプリケーション名: kube-dns)を使用しているため、標準的なメソッド(gethostbyname()など) を使用してクラスター内の任意のPodからServiceに通信できます。CoreDNSが起動していない場合、CoreDNS README またはInstalling CoreDNS を参照し、有効にする事ができます。curlアプリケーションを実行して、これをテストしてみましょう。
kubectl run curl --image= radial/busyboxplus:curl -i --tty --rm
Waiting for pod default/curl-131556218-9fnch to be running, status is Pending, pod ready: false
Hit enter for command prompt
次に、Enterキーを押してnslookup my-nginxを実行します:
[ root@curl-131556218-9fnch:/ ] $ nslookup my-nginx
Server: 10.0.0.10
Address 1: 10.0.0.10
Name: my-nginx
Address 1: 10.0.162.149
Serviceを安全にする
これまでは、クラスター内からnginxサーバーにアクセスしただけでした。
サービスをインターネットに公開する前に、通信チャネルが安全であることを確認する必要があります。
これには、次のものが必要です:
https用の自己署名証明書(既にID証明書を持っている場合を除く)
証明書を使用するように構成されたnginxサーバー
Podが証明書にアクセスできるようにするSecret
これらはすべてnginx httpsの例 から取得できます。
これにはツールをインストールする必要があります。
これらをインストールしたくない場合は、後で手動の手順に従ってください。つまり:
make keys KEY = /tmp/nginx.key CERT = /tmp/nginx.crt
kubectl create secret tls nginxsecret --key /tmp/nginx.key --cert /tmp/nginx.crt
secret/nginxsecret created
NAME TYPE DATA AGE
default-token-il9rc kubernetes.io/service-account-token 1 1d
nginxsecret kubernetes.io/tls 2 1m
configmapも作成します:
kubectl create configmap nginxconfigmap --from-file= default.conf
configmap/nginxconfigmap created
NAME DATA AGE
nginxconfigmap 1 114s
以下は、(Windows上など)makeの実行で問題が発生した場合に実行する手動の手順です:
# 公開秘密鍵ペアを作成します
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /d/tmp/nginx.key -out /d/tmp/nginx.crt -subj "/CN=my-nginx/O=my-nginx"
# キーをbase64エンコードに変換します
cat /d/tmp/nginx.crt | base64
cat /d/tmp/nginx.key | base64
前のコマンドの出力を使用して、次のようにyamlファイルを作成します。
base64でエンコードされた値はすべて1行である必要があります。
apiVersion : "v1"
kind : "Secret"
metadata :
name : "nginxsecret"
namespace : "default"
type : kubernetes.io/tls
data :
nginx.crt : "LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURIekNDQWdlZ0F3SUJBZ0lKQUp5M3lQK0pzMlpJTUEwR0NTcUdTSWIzRFFFQkJRVUFNQ1l4RVRBUEJnTlYKQkFNVENHNW5hVzU0YzNaak1SRXdEd1lEVlFRS0V3aHVaMmx1ZUhOMll6QWVGdzB4TnpFd01qWXdOekEzTVRKYQpGdzB4T0RFd01qWXdOekEzTVRKYU1DWXhFVEFQQmdOVkJBTVRDRzVuYVc1NGMzWmpNUkV3RHdZRFZRUUtFd2h1CloybHVlSE4yWXpDQ0FTSXdEUVlKS29aSWh2Y05BUUVCQlFBRGdnRVBBRENDQVFvQ2dnRUJBSjFxSU1SOVdWM0IKMlZIQlRMRmtobDRONXljMEJxYUhIQktMSnJMcy8vdzZhU3hRS29GbHlJSU94NGUrMlN5ajBFcndCLzlYTnBwbQppeW1CL3JkRldkOXg5UWhBQUxCZkVaTmNiV3NsTVFVcnhBZW50VWt1dk1vLzgvMHRpbGhjc3paenJEYVJ4NEo5Ci82UVRtVVI3a0ZTWUpOWTVQZkR3cGc3dlVvaDZmZ1Voam92VG42eHNVR0M2QURVODBpNXFlZWhNeVI1N2lmU2YKNHZpaXdIY3hnL3lZR1JBRS9mRTRqakxCdmdONjc2SU90S01rZXV3R0ljNDFhd05tNnNTSzRqYUNGeGpYSnZaZQp2by9kTlEybHhHWCtKT2l3SEhXbXNhdGp4WTRaNVk3R1ZoK0QrWnYvcW1mMFgvbVY0Rmo1NzV3ajFMWVBocWtsCmdhSXZYRyt4U1FVQ0F3RUFBYU5RTUU0d0hRWURWUjBPQkJZRUZPNG9OWkI3YXc1OUlsYkROMzhIYkduYnhFVjcKTUI4R0ExVWRJd1FZTUJhQUZPNG9OWkI3YXc1OUlsYkROMzhIYkduYnhFVjdNQXdHQTFVZEV3UUZNQU1CQWY4dwpEUVlKS29aSWh2Y05BUUVGQlFBRGdnRUJBRVhTMW9FU0lFaXdyMDhWcVA0K2NwTHI3TW5FMTducDBvMm14alFvCjRGb0RvRjdRZnZqeE04Tzd2TjB0clcxb2pGSW0vWDE4ZnZaL3k4ZzVaWG40Vm8zc3hKVmRBcStNZC9jTStzUGEKNmJjTkNUekZqeFpUV0UrKzE5NS9zb2dmOUZ3VDVDK3U2Q3B5N0M3MTZvUXRUakViV05VdEt4cXI0Nk1OZWNCMApwRFhWZmdWQTRadkR4NFo3S2RiZDY5eXM3OVFHYmg5ZW1PZ05NZFlsSUswSGt0ejF5WU4vbVpmK3FqTkJqbWZjCkNnMnlwbGQ0Wi8rUUNQZjl3SkoybFIrY2FnT0R4elBWcGxNSEcybzgvTHFDdnh6elZPUDUxeXdLZEtxaUMwSVEKQ0I5T2wwWW5scE9UNEh1b2hSUzBPOStlMm9KdFZsNUIyczRpbDlhZ3RTVXFxUlU9Ci0tLS0tRU5EIENFUlRJRklDQVRFLS0tLS0K"
nginx.key : "LS0tLS1CRUdJTiBQUklWQVRFIEtFWS0tLS0tCk1JSUV2UUlCQURBTkJna3Foa2lHOXcwQkFRRUZBQVNDQktjd2dnU2pBZ0VBQW9JQkFRQ2RhaURFZlZsZHdkbFIKd1V5eFpJWmVEZWNuTkFhbWh4d1NpeWF5N1AvOE9ta3NVQ3FCWmNpQ0RzZUh2dGtzbzlCSzhBZi9WemFhWm9zcApnZjYzUlZuZmNmVUlRQUN3WHhHVFhHMXJKVEVGSzhRSHA3VkpMcnpLUC9QOUxZcFlYTE0yYzZ3MmtjZUNmZitrCkU1bEVlNUJVbUNUV09UM3c4S1lPNzFLSWVuNEZJWTZMMDUrc2JGQmd1Z0ExUE5JdWFubm9UTWtlZTRuMG4rTDQKb3NCM01ZUDhtQmtRQlAzeE9JNHl3YjREZXUraURyU2pKSHJzQmlIT05Xc0RadXJFaXVJMmdoY1kxeWIyWHI2UAozVFVOcGNSbC9pVG9zQngxcHJHclk4V09HZVdPeGxZZmcvbWIvNnBuOUYvNWxlQlkrZStjSTlTMkQ0YXBKWUdpCkwxeHZzVWtGQWdNQkFBRUNnZ0VBZFhCK0xkbk8ySElOTGo5bWRsb25IUGlHWWVzZ294RGQwci9hQ1Zkank4dlEKTjIwL3FQWkUxek1yall6Ry9kVGhTMmMwc0QxaTBXSjdwR1lGb0xtdXlWTjltY0FXUTM5SjM0VHZaU2FFSWZWNgo5TE1jUHhNTmFsNjRLMFRVbUFQZytGam9QSFlhUUxLOERLOUtnNXNrSE5pOWNzMlY5ckd6VWlVZWtBL0RBUlBTClI3L2ZjUFBacDRuRWVBZmI3WTk1R1llb1p5V21SU3VKdlNyblBESGtUdW1vVlVWdkxMRHRzaG9reUxiTWVtN3oKMmJzVmpwSW1GTHJqbGtmQXlpNHg0WjJrV3YyMFRrdWtsZU1jaVlMbjk4QWxiRi9DSmRLM3QraTRoMTVlR2ZQegpoTnh3bk9QdlVTaDR2Q0o3c2Q5TmtEUGJvS2JneVVHOXBYamZhRGR2UVFLQmdRRFFLM01nUkhkQ1pKNVFqZWFKClFGdXF4cHdnNzhZTjQyL1NwenlUYmtGcVFoQWtyczJxWGx1MDZBRzhrZzIzQkswaHkzaE9zSGgxcXRVK3NHZVAKOWRERHBsUWV0ODZsY2FlR3hoc0V0L1R6cEdtNGFKSm5oNzVVaTVGZk9QTDhPTm1FZ3MxMVRhUldhNzZxelRyMgphRlpjQ2pWV1g0YnRSTHVwSkgrMjZnY0FhUUtCZ1FEQmxVSUUzTnNVOFBBZEYvL25sQVB5VWs1T3lDdWc3dmVyClUycXlrdXFzYnBkSi9hODViT1JhM05IVmpVM25uRGpHVHBWaE9JeXg5TEFrc2RwZEFjVmxvcG9HODhXYk9lMTAKMUdqbnkySmdDK3JVWUZiRGtpUGx1K09IYnRnOXFYcGJMSHBzUVpsMGhucDBYSFNYVm9CMUliQndnMGEyOFVadApCbFBtWmc2d1BRS0JnRHVIUVV2SDZHYTNDVUsxNFdmOFhIcFFnMU16M2VvWTBPQm5iSDRvZUZKZmcraEppSXlnCm9RN3hqWldVR3BIc3AyblRtcHErQWlSNzdyRVhsdlhtOElVU2FsbkNiRGlKY01Pc29RdFBZNS9NczJMRm5LQTQKaENmL0pWb2FtZm1nZEN0ZGtFMXNINE9MR2lJVHdEbTRpb0dWZGIwMllnbzFyb2htNUpLMUI3MkpBb0dBUW01UQpHNDhXOTVhL0w1eSt5dCsyZ3YvUHM2VnBvMjZlTzRNQ3lJazJVem9ZWE9IYnNkODJkaC8xT2sybGdHZlI2K3VuCnc1YytZUXRSTHlhQmd3MUtpbGhFZDBKTWU3cGpUSVpnQWJ0LzVPbnlDak9OVXN2aDJjS2lrQ1Z2dTZsZlBjNkQKckliT2ZIaHhxV0RZK2Q1TGN1YSt2NzJ0RkxhenJsSlBsRzlOZHhrQ2dZRUF5elIzT3UyMDNRVVV6bUlCRkwzZAp4Wm5XZ0JLSEo3TnNxcGFWb2RjL0d5aGVycjFDZzE2MmJaSjJDV2RsZkI0VEdtUjZZdmxTZEFOOFRwUWhFbUtKCnFBLzVzdHdxNWd0WGVLOVJmMWxXK29xNThRNTBxMmk1NVdUTThoSDZhTjlaMTltZ0FGdE5VdGNqQUx2dFYxdEYKWSs4WFJkSHJaRnBIWll2NWkwVW1VbGc9Ci0tLS0tRU5EIFBSSVZBVEUgS0VZLS0tLS0K"
ファイルを使用してSecretを作成します:
kubectl apply -f nginxsecrets.yaml
kubectl get secrets
NAME TYPE DATA AGE
default-token-il9rc kubernetes.io/service-account-token 1 1d
nginxsecret kubernetes.io/tls 2 1m
次に、nginxレプリカを変更して、シークレットの証明書とServiceを使用してhttpsサーバーを起動し、両方のポート(80と443)を公開します:
apiVersion : v1
kind : Service
metadata :
name : my-nginx
labels :
run : my-nginx
spec :
type : NodePort
ports :
- port : 8080
targetPort : 80
protocol : TCP
name : http
- port : 443
protocol : TCP
name : https
selector :
run : my-nginx
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
spec :
selector :
matchLabels :
run : my-nginx
replicas : 1
template :
metadata :
labels :
run : my-nginx
spec :
volumes :
- name : secret-volume
secret :
secretName : nginxsecret
containers :
- name : nginxhttps
image : bprashanth/nginxhttps:1.0
ports :
- containerPort : 443
- containerPort : 80
volumeMounts :
- mountPath : /etc/nginx/ssl
name : secret-volume
nginx-secure-appマニフェストに関する注目すべき点:
同じファイルにDeploymentとServiceの両方が含まれています。
nginxサーバー はポート80のHTTPトラフィックと443のHTTPSトラフィックを処理し、nginx Serviceは両方のポートを公開します。各コンテナは/etc/nginx/sslにマウントされたボリュームを介してキーにアクセスできます。
これは、nginxサーバーが起動する前に セットアップされます。
kubectl delete deployments,svc my-nginx; kubectl create -f ./nginx-secure-app.yaml
この時点で、任意のノードからnginxサーバーに到達できます。
kubectl get pods -l run = my-nginx -o custom-columns= POD_IP:.status.podIPs
POD_IP
[ map[ ip:10.244.3.5]]
node $ curl -k https://10.244.3.5
...
<h1>Welcome to nginx!</h1>
最後の手順でcurlに-kパラメーターを指定したことに注意してください。
これは、証明書の生成時にnginxを実行しているPodについて何も知らないためです。
CNameの不一致を無視するようcurlに指示する必要があります。
Serviceを作成することにより、証明書で使用されるCNameを、Service検索中にPodで使用される実際のDNS名にリンクしました。
これをPodからテストしましょう(簡単にするために同じシークレットを再利用しています。PodはServiceにアクセスするためにnginx.crtのみを必要とします):
apiVersion : apps/v1
kind : Deployment
metadata :
name : curl-deployment
spec :
selector :
matchLabels :
app : curlpod
replicas : 1
template :
metadata :
labels :
app : curlpod
spec :
volumes :
- name : secret-volume
secret :
secretName : nginxsecret
containers :
- name : curlpod
command :
- sh
- -c
- while true; do sleep 1; done
image : radial/busyboxplus:curl
volumeMounts :
- mountPath : /etc/nginx/ssl
name : secret-volume
kubectl apply -f ./curlpod.yaml
kubectl get pods -l app = curlpod
NAME READY STATUS RESTARTS AGE
curl-deployment-1515033274-1410r 1/1 Running 0 1m
kubectl exec curl-deployment-1515033274-1410r -- curl https://my-nginx --cacert /etc/nginx/ssl/tls.crt
...
<title>Welcome to nginx!</title>
...
Serviceを公開する
アプリケーションの一部では、Serviceを外部IPアドレスに公開したい場合があります。
Kubernetesは、NodePortとLoadBalancerの2つの方法をサポートしています。
前のセクションで作成したServiceはすでにNodePortを使用しているため、ノードにパブリックIPがあれば、nginx HTTPSレプリカはインターネット上のトラフィックを処理する準備ができています。
kubectl get svc my-nginx -o yaml | grep nodePort -C 5
uid: 07191fb3-f61a-11e5-8ae5-42010af00002
spec:
clusterIP: 10.0.162.149
ports:
- name: http
nodePort: 31704
port: 8080
protocol: TCP
targetPort: 80
- name: https
nodePort: 32453
port: 443
protocol: TCP
targetPort: 443
selector:
run: my-nginx
kubectl get nodes -o yaml | grep ExternalIP -C 1
- address: 104.197.41.11
type: ExternalIP
allocatable:
--
- address: 23.251.152.56
type: ExternalIP
allocatable:
...
$ curl https://<EXTERNAL-IP>:<NODE-PORT> -k
...
<h1>Welcome to nginx!</h1>
クラウドロードバランサーを使用するようにサービスを再作成しましょう。
my-nginxサービスのTypeをNodePortからLoadBalancerに変更するだけです:
kubectl edit svc my-nginx
kubectl get svc my-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx LoadBalancer 10.0.162.149 xx.xxx.xxx.xxx 8080:30163/TCP 21s
curl https://<EXTERNAL-IP> -k
...
<title>Welcome to nginx!</title>
EXTERNAL-IP列のIPアドレスは、パブリックインターネットで利用可能なものです。
CLUSTER-IPは、クラスター/プライベートクラウドネットワーク内でのみ使用できます。
AWSでは、type LoadBalancerはIPではなく(長い)ホスト名を使用するELBが作成されます。
実際、標準のkubectl get svcの出力に収まるには長すぎるので、それを確認するにはkubectl describe service my-nginxを実行する必要があります。
次のようなものが表示されます:
kubectl describe service my-nginx
...
LoadBalancer Ingress: a320587ffd19711e5a37606cf4a74574-1142138393.us-east-1.elb.amazonaws.com
...
次の項目
5.4 - Ingressコントローラー
クラスターで
Ingress を動作させるためには、
ingress controller が動作している必要があります。 少なくとも1つのIngressコントローラーを選択し、クラスター内にセットアップされていることを確認する必要があります。 このページはデプロイ可能な一般的なIngressコントローラーをリストアップします。
Ingressリソースが動作するためには、クラスターでIngressコントローラーが実行されている必要があります。
kube-controller-managerバイナリの一部として実行される他のタイプのコントローラーとは異なり、Ingressコントローラーはクラスターで自動的に起動されません。このページを使用して、クラスターに最適なIngressコントローラーの実装を選択してください。
プロジェクトとしてのKubernetesは現在、AWS 、GCE 、およびnginx のIngressコントローラーをサポート・保守しています。
追加のコントローラー
備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 複数のIngressコントローラーの使用
Ingress Class を使用して、複数のIngressコントローラーをクラスターにデプロイすることができます。
Ingress Classリソースの.metadata.nameに注目してください。
Ingressを作成する際には、IngressオブジェクトでingressClassNameフィールドを指定するために、その名前が必要になります(IngressSpec v1 reference を参照)。
ingressClassNameは古いannotation method の代替品です。
Ingressに対してIngressClassを指定せず、クラスターにはデフォルトとして設定されたIngressClassが1つだけある場合、KubernetesはIngressにクラスターのデフォルトIngressClassを適用 します。
IngressClassのingressclass.kubernetes.io/is-default-classアノテーション"true"に設定することで、デフォルトとしてIngressClassを設定します。
理想的には、すべてのIngressコントローラーはこの仕様を満たすべきですが、いくつかのIngressコントローラーはわずかに異なる動作をします。
備考: Ingressコントローラーのドキュメントを確認して、選択する際の注意点を理解してください。
次の項目
5.5 - EndpointSlice
FEATURE STATE: Kubernetes v1.17 [beta]
EndpointSlice は、Kubernetesクラスター内にあるネットワークエンドポイントを追跡するための単純な手段を提供します。EndpointSliceは、よりスケーラブルでより拡張可能な、Endpointの代わりとなるものです。
動機
Endpoint APIはKubernetes内のネットワークエンドポイントを追跡する単純で直観的な手段を提供してきました。
残念ながら、KubernetesクラスターやService が大規模になり、より多くのトラフィックを処理し、より多くのバックエンドPodに送信するようになるにしたがって、Endpoint APIの限界が明らかになってきました。
最も顕著な問題の1つに、ネットワークエンドポイントの数が大きくなったときのスケーリングの問題があります。
Serviceのすべてのネットワークエンドポイントが単一のEndpointリソースに格納されていたため、リソースのサイズが非常に大きくなる場合がありました。これがKubernetesのコンポーネント(特に、マスターコントロールプレーン)の性能に悪影響を与え、結果として、Endpointに変更があるたびに、大量のネットワークトラフィックと処理が発生するようになってしまいました。EndpointSliceは、この問題を緩和するとともに、トポロジカルルーティングなどの追加機能のための拡張可能なプラットフォームを提供します。
EndpointSliceリソース
Kubernetes内ではEndpointSliceにはネットワークエンドポイントの集合へのリファレンスが含まれます。
コントロールプレーンは、セレクター が指定されているKubernetes ServiceのEndpointSliceを自動的に作成します。
これらのEndpointSliceには、Serviceセレクターに一致するすべてのPodへのリファレンスが含まれています。
EndpointSliceは、プロトコル、ポート番号、およびサービス名の一意の組み合わせによってネットワークエンドポイントをグループ化します。
EndpointSliceオブジェクトの名前は有効なDNSサブドメイン名 である必要があります。
一例として、以下にexampleというKubernetes Serviceに対するサンプルのEndpointSliceリソースを示します。
apiVersion : discovery.k8s.io/v1beta1
kind : EndpointSlice
metadata :
name : example-abc
labels :
kubernetes.io/service-name : example
addressType : IPv4
ports :
- name : http
protocol : TCP
port : 80
endpoints :
- addresses :
- "10.1.2.3"
conditions :
ready : true
hostname : pod-1
topology :
kubernetes.io/hostname : node-1
topology.kubernetes.io/zone : us-west2-a
デフォルトでは、コントロールプレーンはEndpointSliceを作成・管理し、それぞれのエンドポイント数が100以下になるようにします。--max-endpoints-per-slicekube-controller-manager フラグを設定することで、最大1000個まで設定可能です。
EndpointSliceは内部トラフィックのルーティング方法に関して、kube-proxy に対する唯一のソース(source of truth)として振る舞うことができます。EndpointSliceを有効にすれば、非常に多数のエンドポイントを持つServiceに対して性能向上が得られるはずです。
アドレスの種類
EndpointSliceは次の3種類のアドレスをサポートします。
IPv4
IPv6
FQDN (Fully Qualified Domain Name、完全修飾ドメイン名)
トポロジー
EndpointSliceに属する各エンドポイントは、関連するトポロジーの情報を持つことができます。この情報は、エンドポイントの場所を示すために使われ、対応するNode、ゾーン、リージョンに関する情報が含まれます。
値が利用できる場合には、コントロールプレーンはEndpointSliceコントローラーに次のようなTopologyラベルを設定します。
kubernetes.io/hostname - このエンドポイントが存在するNodeの名前。topology.kubernetes.io/zone - このエンドポイントが存在するゾーン。topology.kubernetes.io/region - このエンドポイントが存在するリージョン。
これらのラベルの値はスライス内の各エンドポイントと関連するリソースから継承したものです。hostnameラベルは対応するPod上のNodeNameフィールドの値を表します。zoneとregionラベルは対応するNode上の同じ名前のラベルの値を表します。
管理
ほとんどの場合、コントロールプレーン(具体的には、EndpointSlice コントローラー )は、EndpointSliceオブジェクトを作成および管理します。EndpointSliceには、サービスメッシュの実装など、他のさまざまなユースケースがあり、他のエンティティまたはコントローラーがEndpointSliceの追加セットを管理する可能性があります。
複数のエンティティが互いに干渉することなくEndpointSliceを管理できるようにするために、KubernetesはEndpointSliceを管理するエンティティを示すendpointslice.kubernetes.io/managed-byというラベル を定義します。
EndpointSliceを管理するその他のエンティティも同様に、このラベルにユニークな値を設定する必要があります。
所有権
ほとんどのユースケースでは、EndpointSliceはエンドポイントスライスオブジェクトがエンドポイントを追跡するServiceによって所有されます。
これは、各EndpointSlice上のownerリファレンスとkubernetes.io/service-nameラベルによって示されます。これにより、Serviceに属するすべてのEndpointSliceを簡単に検索できるようになっています。
EndpointSliceのミラーリング
場合によっては、アプリケーションはカスタムEndpointリソースを作成します。これらのアプリケーションがEndpointリソースとEndpointSliceリソースの両方に同時に書き込む必要がないようにするために、クラスターのコントロールプレーンは、ほとんどのEndpointリソースを対応するEndpointSliceにミラーリングします。
コントロールプレーンは、次の場合を除いて、Endpointリソースをミラーリングします。
Endpointリソースのendpointslice.kubernetes.io/skip-mirrorラベルがtrueに設定されています。
Endpointリソースがcontrol-plane.alpha.kubernetes.io/leaderアノテーションを持っています。
対応するServiceリソースが存在しません。
対応するServiceリソースには、nil以外のセレクターがあります。
個々のEndpointリソースは、複数のEndpointSliceに変換される場合があります。これは、Endpointリソースに複数のサブセットがある場合、または複数のIPファミリ(IPv4およびIPv6)を持つエンドポイントが含まれている場合に発生します。サブセットごとに最大1000個のアドレスがEndpointSliceにミラーリングされます。
EndpointSliceの分散
それぞれのEndpointSliceにはポートの集合があり、リソース内のすべてのエンドポイントに適用されます。サービスが名前付きポートを使用した場合、Podが同じ名前のポートに対して、結果的に異なるターゲットポート番号が使用されて、異なるEndpointSliceが必要になる場合があります。これはサービスの部分集合がEndpointにグループ化される場合と同様です。
コントロールプレーンはEndpointSliceをできる限り充填しようとしますが、積極的にリバランスを行うことはありません。コントローラーのロジックは極めて単純で、以下のようになっています。
既存のEndpointSliceをイテレートし、もう必要のないエンドポイントを削除し、変更があったエンドポイントを更新する。
前のステップで変更されたEndpointSliceをイテレートし、追加する必要がある新しいエンドポイントで充填する。
まだ追加するべき新しいエンドポイントが残っていた場合、これまで変更されなかったスライスに追加を試み、その後、新しいスライスを作成する。
ここで重要なのは、3番目のステップでEndpointSliceを完全に分散させることよりも、EndpointSliceの更新を制限することを優先していることです。たとえば、もし新しい追加するべきエンドポイントが10個あり、2つのEndpointSliceにそれぞれ5個の空きがあった場合、このアプローチでは2つの既存のEndpointSliceを充填する代わりに、新しいEndpointSliceが作られます。言い換えれば、1つのEndpointSliceを作成する方が複数のEndpointSliceを更新するよりも好ましいということです。
各Node上で実行されているkube-proxyはEndpointSliceを監視しており、EndpointSliceに加えられた変更はクラスター内のすべてのNodeに送信されるため、比較的コストの高い処理になります。先ほどのアプローチは、たとえ複数のEndpointSliceが充填されない結果となるとしても、すべてのNodeへ送信しなければならない変更の数を抑制することを目的としています。
現実的には、こうしたあまり理想的ではない分散が発生することは稀です。EndpointSliceコントローラーによって処理されるほとんどの変更は、既存のEndpointSliceに収まるほど十分小さくなるためです。そうでなかったとしても、すぐに新しいEndpointSliceが必要になる可能性が高いです。また、Deploymentのローリングアップデートが行われれば、自然な再充填が行われます。Podとそれに対応するエンドポイントがすべて置換されるためです。
エンドポイントの重複
EndpointSliceの変更の性質上、エンドポイントは同時に複数のEndpointSliceで表される場合があります。
これは、さまざまなEndpointSliceオブジェクトへの変更が、さまざまな時間にKubernetesクライアントのウォッチ/キャッシュに到達する可能性があるために自然に発生します。
EndpointSliceを使用する実装では、エンドポイントを複数のスライスに表示できる必要があります。
エンドポイント重複排除を実行する方法のリファレンス実装は、kube-proxyのEndpointSliceCache実装にあります。
次の項目
5.6 - ネットワークポリシー
IPアドレスまたはポートのレベル(OSI参照モデルのレイヤー3または4)でトラフィックフローを制御したい場合、クラスター内の特定のアプリケーションにKubernetesのネットワークポリシーを使用することを検討してください。ネットワークポリシーはアプリケーション中心の構造であり、Pod がネットワークを介して多様な「エンティティ」(「Endpoint」や「Service」のようなKubernetesに含まれる特定の意味を持つ共通の用語との重複を避けるため、ここではエンティティという単語を使用します。)と通信する方法を指定できます。
Podが通信できるエンティティは以下の3つの識別子の組み合わせによって識別されます。
許可されている他のPod(例外: Podはそれ自体へのアクセスをブロックできません)
許可されている名前空間
IPブロック(例外: PodまたはノードのIPアドレスに関係なく、Podが実行されているノードとの間のトラフィックは常に許可されます。)
Podベースもしくは名前空間ベースのネットワークポリシーを定義する場合、セレクター を使用してセレクターに一致するPodとの間で許可されるトラフィックを指定します。
一方でIPベースのネットワークポリシーが作成されると、IPブロック(CIDRの範囲)に基づいてポリシーが定義されます。
前提条件
ネットワークポリシーは、ネットワークプラグイン により実装されます。ネットワークポリシーを使用するには、NetworkPolicyをサポートするネットワークソリューションを使用しなければなりません。ネットワークポリシーを実装したコントローラーを使用せずにNetworkPolicyリソースを作成した場合は、何も効果はありません。
分離されたPodと分離されていないPod
デフォルトでは、Podは分離されていない状態(non-isolated)となるため、すべてのソースからのトラフィックを受信します。
Podを選択するNetworkPolicyが存在すると、Podは分離されるようになります。名前空間内に特定のPodを選択するNetworkPolicyが1つでも存在すると、そのPodはいずれかのNetworkPolicyで許可されていないすべての接続を拒否するようになります。(同じ名前空間内のPodでも、どのNetworkPolicyにも選択されなかった他のPodは、引き続きすべてのトラフィックを許可します。)
ネットワークポリシーは追加式であるため、競合することはありません。複数のポリシーがPodを選択する場合、そのPodに許可されるトラフィックは、それらのポリシーのingress/egressルールの和集合で制限されます。したがって、評価の順序はポリシーの結果には影響がありません。
NetworkPolicyリソース
リソースの完全な定義については、リファレンスのNetworkPolicy のセクションを参照してください。
以下は、NetworkPolicyの一例です。
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : test-network-policy
namespace : default
spec :
podSelector :
matchLabels :
role : db
policyTypes :
- Ingress
- Egress
ingress :
- from :
- ipBlock :
cidr : 172.17.0.0 /16
except :
- 172.17.1.0 /24
- namespaceSelector :
matchLabels :
project : myproject
- podSelector :
matchLabels :
role : frontend
ports :
- protocol : TCP
port : 6379
egress :
- to :
- ipBlock :
cidr : 10.0.0.0 /24
ports :
- protocol : TCP
port : 5978
備考: 選択したネットワークソリューションがネットワークポリシーをサポートしていない場合には、これをクラスターのAPIサーバーにPOSTしても効果はありません。
必須フィールド : 他のKubernetesの設定と同様に、NetworkPolicyにもapiVersion、kind、metadataフィールドが必須です。設定ファイルの扱い方に関する一般的な情報については、ConfigMapを使用してコンテナを構成する とオブジェクト管理 を参照してください。
spec : NetworkPolicyのspec を見ると、指定した名前空間内で特定のネットワークポリシーを定義するのに必要なすべての情報が確認できます。
podSelector : 各NetworkPolicyには、ポリシーを適用するPodのグループを選択するpodSelectorが含まれます。ポリシーの例では、ラベル"role=db"を持つPodを選択しています。podSelectorを空にすると、名前空間内のすべてのPodが選択されます。
policyTypes : 各NetworkPolicyには、policyTypesとして、Ingress、Egress、またはその両方からなるリストが含まれます。policyTypesフィールドでは、指定したポリシーがどの種類のトラフィックに適用されるかを定めます。トラフィックの種類としては、選択したPodへの内向きのトラフィック(Ingress)、選択したPodからの外向きのトラフィック(Egress)、またはその両方を指定します。policyTypesを指定しなかった場合、デフォルトで常に
Ingressが指定され、NetworkPolicyにegressルールが1つでもあればEgressも設定されます。
ingress : 各NetworkPolicyには、許可するingressルールのリストを指定できます。各ルールは、fromおよびportsセクションの両方に一致するトラフィックを許可します。ポリシーの例には1つのルールが含まれ、このルールは、3つのソースのいずれかから送信された1つのポート上のトラフィックに一致します。1つ目のソースはipBlockで、2つ目のソースはnamespaceSelectorで、3つ目のソースはpodSelectorでそれぞれ定められます。
egress : 各NetworkPolicyには、許可するegressルールのリストを指定できます。各ルールは、toおよびportsセクションの両方に一致するトラフィックを許可します。ポリシーの例には1つのルールが含まれ、このルールは、1つのポート上で10.0.0.0/24の範囲内の任意の送信先へ送られるトラフィックに一致します。
したがって、上のNetworkPolicyの例では、次のようにネットワークポリシーを適用します。
"default"名前空間内にある"role=db"のPodを、内向きと外向きのトラフィックに対して分離する(まだ分離されていない場合)
(Ingressルール) "default"名前空間内の"role=db"ラベルが付いたすべてのPodのTCPの6379番ポートへの接続のうち、次の送信元からのものを許可する
"default"名前空間内のラベル"role=frontend"が付いたすべてのPod
ラベル"project=myproject"が付いた名前空間内のすべてのPod
172.17.0.0–172.17.0.255および172.17.2.0–172.17.255.255(言い換えれば、172.17.1.0/24の範囲を除く172.17.0.0/16)の範囲内のすべてのIPアドレス
(Egressルール) "role=db"というラベルが付いた"default"名前空間内のすべてのPodからの、TCPの5978番ポート上でのCIDR 10.0.0.0/24への接続を許可する
追加の例については、ネットワークポリシーを宣言する の説明を参照してください。
toとfromのセレクターの振る舞いingressのfromセクションまたはegressのtoセクションに指定できるセレクターは4種類あります。
podSelector : NetworkPolicyと同じ名前空間内の特定のPodを選択して、ingressの送信元またはegressの送信先を許可します。
namespaceSelector : 特定の名前空間を選択して、その名前空間内のすべてのPodについて、ingressの送信元またはegressの送信先を許可します。
namespaceSelector および podSelector : 1つのtoまたはfromエントリーでnamespaceSelectorとpodSelectorの両方を指定して、特定の名前空間内の特定のPodを選択します。正しいYAMLの構文を使うように気をつけてください。このポリシーの例を以下に示します。
...
ingress :
- from :
- namespaceSelector :
matchLabels :
user : alice
podSelector :
matchLabels :
role : client
...
このポリシーには、1つのfrom要素があり、ラベルuser=aliceの付いた名前空間内にある、ラベルrole=clientの付いたPodからの接続を許可します。しかし、以下の ポリシーには注意が必要です。
...
ingress :
- from :
- namespaceSelector :
matchLabels :
user : alice
- podSelector :
matchLabels :
role : client
...
このポリシーには、from配列の中に2つの要素があります。そのため、ラベルrole=clientの付いた名前空間内にあるすべてのPodからの接続、または 、任意の名前空間内にあるラベルuser=aliceの付いたすべてのPodからの接続を許可します。
正しいルールになっているか自信がないときは、kubectl describeを使用すると、Kubernetesがどのようにポリシーを解釈したのかを確認できます。
ipBlock : 特定のIPのCIDRの範囲を選択して、ingressの送信元またはegressの送信先を許可します。PodのIPは一時的なもので予測できないため、ここにはクラスター外のIPを指定するべきです。
クラスターのingressとegressの仕組みはパケットの送信元IPや送信先IPの書き換えを必要とすることがよくあります。その場合、NetworkPolicyの処理がIPの書き換えの前後どちらで行われるのかは定義されていません。そのため、ネットワークプラグイン、クラウドプロバイダー、Serviceの実装などの組み合わせによっては、動作が異なる可能性があります。
内向きのトラフィックの場合は、実際のオリジナルの送信元IPに基づいてパケットをフィルタリングできる可能性もあれば、NetworkPolicyが対象とする「送信元IP」がLoadBalancerやPodのノードなどのIPになってしまっている可能性もあることになります。
外向きのトラフィックの場合は、クラスター外のIPに書き換えられたPodからServiceのIPへの接続は、ipBlockベースのポリシーの対象になる場合とならない場合があることになります。
デフォルトのポリシー
デフォルトでは、名前空間にポリシーが存在しない場合、その名前空間内のPodの内向きと外向きのトラフィックはすべて許可されます。以下の例を利用すると、その名前空間内でのデフォルトの振る舞いを変更できます。
デフォルトですべての内向きのトラフィックを拒否する
すべてのPodを選択して、そのPodへのすべての内向きのトラフィックを許可しないNetworkPolicyを作成すると、その名前空間に対する「デフォルト」の分離ポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : default-deny-ingress
spec :
podSelector : {}
policyTypes :
- Ingress
このポリシーを利用すれば、他のいかなるNetworkPolicyにも選択されなかったPodでも分離されることを保証できます。このポリシーは、デフォルトの外向きの分離の振る舞いを変更しません。
デフォルトで内向きのすべてのトラフィックを許可する
(たとえPodを「分離されたもの」として扱うポリシーが追加された場合でも)名前空間内のすべてのPodへのすべてのトラフィックを許可したい場合には、その名前空間内のすべてのトラフィックを明示的に許可するポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : allow-all-ingress
spec :
podSelector : {}
ingress :
- {}
policyTypes :
- Ingress
デフォルトで外向きのすべてのトラフィックを拒否する
すべてのPodを選択して、そのPodからのすべての外向きのトラフィックを許可しないNetworkPolicyを作成すると、その名前空間に対する「デフォルト」の外向きの分離ポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : default-deny-egress
spec :
podSelector : {}
policyTypes :
- Egress
このポリシーを利用すれば、他のいかなるNetworkPolicyにも選択されなかったPodでも、外向きのトラフィックが許可されないことを保証できます。このポリシーは、デフォルトの内向きの分離の振る舞いを変更しません。
デフォルトで外向きのすべてのトラフィックを許可する
(たとえPodを「分離されたもの」として扱うポリシーが追加された場合でも)名前空間内のすべてのPodからのすべてのトラフィックを許可したい場合には、その名前空間内のすべての外向きのトラフィックを明示的に許可するポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : allow-all-egress
spec :
podSelector : {}
egress :
- {}
policyTypes :
- Egress
デフォルトで内向きと外向きのすべてのトラフィックを拒否する
名前空間内に以下のNetworkPolicyを作成すると、その名前空間で内向きと外向きのすべてのトラフィックを拒否する「デフォルト」のポリシーを作成できます。
---
apiVersion : networking.k8s.io/v1
kind : NetworkPolicy
metadata :
name : default-deny-all
spec :
podSelector : {}
policyTypes :
- Ingress
- Egress
このポリシーを利用すれば、他のいかなるNetworkPolicyにも選択されなかったPodでも、内向きと外向きのトラフィックが許可されないことを保証できます。
SCTPのサポート
FEATURE STATE: Kubernetes v1.19 [beta]
ベータ版の機能として、これはデフォルトで有効化されます。
クラスターレベルでSCTPを無効化するために、クラスター管理者はAPIサーバーで--feature-gates=SCTPSupport=false,…と指定して、SCTPSupportフィーチャーゲート を無効にする必要があります。
備考: SCTPプロトコルのネットワークポリシーをサポートする
CNI プラグインを使用している必要があります。
ネットワークポリシーでできないこと(少なくともまだ)
Kubernetes1.20現在、ネットワークポリシーAPIに以下の機能は存在しません。
しかし、オペレーティングシステムのコンポーネント(SELinux、OpenVSwitch、IPTablesなど)、レイヤー7の技術(Ingressコントローラー、サービスメッシュ実装)、もしくはアドミッションコントローラーを使用して回避策を実装できる場合があります。
Kubernetesのネットワークセキュリティを初めて使用する場合は、ネットワークポリシーAPIを使用して以下のユーザーストーリーを(まだ)実装できないことに注意してください。これらのユーザーストーリーの一部(全てではありません)は、ネットワークポリシーAPIの将来のリリースで活発に議論されています。
クラスター内トラフィックを強制的に共通ゲートウェイを通過させる(これは、サービスメッシュもしくは他のプロキシで提供するのが最適な場合があります)。
TLS関連のもの(これにはサービスメッシュまたはIngressコントローラーを使用します)。
ノードの固有のポリシー(これらにはCIDR表記を使用できますが、Kubernetesのアイデンティティでノードを指定することはできません)。
名前空間またはサービスを名前で指定する(ただし、Podまたは名前空間をラベル で指定することができます。これは多くの場合で実行可能な回避策です)。
サードパーティによって実行される「ポリシー要求」の作成または管理
全ての名前空間もしくはPodに適用されるデフォルトのポリシー(これを実現できるサードパーティのKubernetesディストリビューションとプロジェクトがいくつか存在します)。
高度なポリシークエリと到達可能性ツール
単一のポリシー宣言でポートの範囲を指定する機能
ネットワークセキュリティイベント(例えばブロックされた接続や受け入れられた接続)をログに記録する機能
ポリシーを明示的に拒否する機能(現在、ネットワークポリシーのモデルはデフォルトで拒否されており、許可ルールを追加する機能のみが存在します)。
ループバックまたは内向きのホストトラフィックを拒否する機能(Podは現在localhostのアクセスやそれらが配置されているノードからのアクセスをブロックすることはできません)。
次の項目
5.7 - ServiceとPodに対するDNS
このページではKubernetesによるDNSサポートについて概観します。
イントロダクション
KubernetesのDNSはクラスター上でDNS PodとServiceをスケジュールし、DNSの名前解決をするために各コンテナに対してDNS ServiceのIPを使うようにKubeletを設定します。
何がDNS名を取得するか
クラスター内(DNSサーバーそれ自体も含む)で定義された全てのServiceはDNS名を割り当てられます。デフォルトでは、クライアントPodのDNSサーチリストはPod自身のネームスペースと、クラスターのデフォルトドメインを含みます。
Kubernetesのbarというネームスペース内でfooという名前のServiceがあると仮定します。barネームスペース内で稼働しているPodは、fooに対してDNSクエリを実行するだけでこのServiceを探すことができます。barとは別のquuxネームスペース内で稼働しているPodは、foo.barに対してDNSクエリを実行するだけでこのServiceを探すことができます。
下記のセクションでは、サポートされているレコードタイプとレイアウトについて詳しくまとめています。
うまく機能する他のレイアウト、名前、またはクエリーは、実装の詳細を考慮し、警告なしに変更されることがあります。KubernetesにおけるDNSベースのServiceディスカバリ を参照ください。
Service
A/AAAAレコード
"通常の"(Headlessでない)Serviceは、my-svc.my-namespace.svc.cluster.localという形式のDNS A(AAAA)レコードを、ServiceのIPバージョンに応じて割り当てられます。このAレコードはそのServiceのClusterIPへと名前解決されます。
"Headless"(ClusterIPなしの)Serviceもまたmy-svc.my-namespace.svc.cluster.localという形式のDNS A(AAAA)レコードを、ServiceのIPバージョンに応じて割り当てられます。通常のServiceとは異なり、このレコードはServiceによって選択されたPodのIPの一覧へと名前解決されます。クライアントはこの一覧のIPを使うか、その一覧から標準のラウンドロビン方式によって選択されたIPを使います。
SRVレコード
SRVレコードは、通常のServiceもしくはHeadless
Services の一部である名前付きポート向けに作成されます。それぞれの名前付きポートに対して、そのSRVレコードは_my-port-name._my-port-protocol.my-svc.my-namespace.svc.cluster.localという形式となります。my-svc.my-namespace.svc.cluster.localという形式のドメイン名とポート番号へ名前解決します。auto-generated-name.my-svc.my-namespace.svc.cluster.localという形式のPodのドメイン名とポート番号を含んだ結果を返します。
Pod
A/AAAAレコード
一般的にPodは下記のDNS解決となります。
pod-ip-address.my-namespace.pod.cluster-domain.example
例えば、defaultネームスペースのpodのIPアドレスが172.17.0.3で、クラスターのドメイン名がcluster.localの場合、PodのDNS名は以下になります。
172-17-0-3.default.pod.cluster.local
DeploymentかDaemonSetに作成され、Serviceに公開されるどのPodも以下のDNS解決が利用できます。
pod-ip-address.deployment-name.my-namespace.svc.cluster-domain.example
Podのhostnameとsubdomainフィールド
現在、Podが作成されたとき、そのPodのホスト名はPodのmetadata.nameフィールドの値となります。
Pod Specは、オプションであるhostnameフィールドを持ち、Podのホスト名を指定するために使うことができます。hostnameが指定されたとき、hostnameはそのPodの名前よりも優先されます。例えば、hostnameフィールドが"my-host"にセットされたPodを考えると、Podはそのhostnameが"my-host"に設定されます。
Pod Specはまた、オプションであるsubdomainフィールドも持ち、Podのサブドメイン名を指定するために使うことができます。例えば、"my-namespace"というネームスペース内でhostnameがfooとセットされていて、subdomainがbarとセットされているPodの場合、そのPodは"foo.bar.my-namespace.svc.cluster.local"という名前の完全修飾ドメイン名(FQDN)を持つことになります。
例:
apiVersion : v1
kind : Service
metadata :
name : default-subdomain
spec :
selector :
name : busybox
clusterIP : None
ports :
- name : foo # 実際は、portは必要ありません。
port : 1234
targetPort : 1234
---
apiVersion : v1
kind : Pod
metadata :
name : busybox1
labels :
name : busybox
spec :
hostname : busybox-1
subdomain : default-subdomain
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
name : busybox
---
apiVersion : v1
kind : Pod
metadata :
name : busybox2
labels :
name : busybox
spec :
hostname : busybox-2
subdomain : default-subdomain
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
name : busybox
もしそのPodと同じネームスペース内で、同じサブドメインを持ったHeadless Serviceが存在していた場合、クラスターのDNSサーバーもまた、そのPodの完全修飾ドメイン名(FQDN)に対するA(AAAA)レコードを返します。
例えば、"busybox-1"というホスト名で、"default-subdomain"というサブドメインを持ったPodと、そのPodと同じネームスペース内にある"default-subdomain"という名前のHeadless Serviceがあると考えると、そのPodは自身の完全修飾ドメイン名(FQDN)を"busybox-1.default-subdomain.my-namespace.svc.cluster.local"として扱います。DNSはそのPodのIPを指し示すA(AAAA)レコードを返します。"busybox1"と"busybox2"の両方のPodはそれぞれ独立したA(AAAA)レコードを持ちます。
そのエンドポイントオブジェクトはそのIPに加えてhostnameを任意のエンドポイントアドレスに対して指定できます。
備考: A(AAAA)レコードはPodの名前に対して作成されないため、hostnameはPodのA(AAAA)レコードが作成されるために必須となります。hostnameを持たないがsubdomainを持つようなPodは、そのPodのIPアドレスを指し示すHeadless Service(default-subdomain.my-namespace.svc.cluster.local)に対するA(AAAA)レコードのみ作成します。
PodのsetHostnameAsFQDNフィールド
FEATURE STATE: Kubernetes v1.19 [alpha]
前提条件 : API Server に対してSetHostnameAsFQDNフィーチャーゲート を有効にする必要があります。
Podが完全修飾ドメイン名(FQDN)を持つように構成されている場合、そのホスト名は短いホスト名です。
例えば、FQDNがbusybox-1.default-subdomain.my-namespace.svc.cluster-domain.exampleのPodがある場合、
デフォルトではそのPod内のhostnameコマンドはbusybox-1を返し、hostname --fqdnコマンドはFQDNを返します。
PodのspecでsetHostnameAsFQDN: trueを設定した場合、そのPodの名前空間に対してkubeletはPodのFQDNをホスト名に書き込みます。
この場合、hostnameとhostname --fqdnの両方がPodのFQDNを返します。
備考: Linuxでは、カーネルのホスト名のフィールド(struct utsnameのnodenameフィールド)は64文字に制限されています。
Podがこの機能を有効にしていて、そのFQDNが64文字より長い場合、Podは起動に失敗します。
PodはPendingステータス(kubectlでみられるContainerCreating)のままになり、「Podのホスト名とクラスタードメインからFQDNを作成できなかった」や、「FQDNlong-FQDNが長すぎる(64文字が最大, 70文字が要求された)」などのエラーイベントが生成されます。
このシナリオのユーザー体験を向上させる1つの方法は、admission webhook controller を作成して、ユーザーがDeploymentなどのトップレベルのオブジェクトを作成するときにFQDNのサイズを制御することです。
PodのDNSポリシー
DNSポリシーはPod毎に設定できます。現在のKubernetesでは次のようなPod固有のDNSポリシーをサポートしています。これらのポリシーはPod SpecのdnsPolicyフィールドで指定されます。
"Default": そのPodはPodが稼働しているNodeから名前解決の設定を継承します。詳細に関しては、関連する議論 を参照してください。
"ClusterFirst": "www.kubernetes.io"のようなクラスタードメインのサフィックスにマッチしないようなDNSクエリーは、Nodeから継承された上流のネームサーバーにフォワーディングされます。クラスター管理者は、追加のstubドメインと上流のDNSサーバーを設定できます。このような場合におけるDNSクエリー処理の詳細に関しては、関連する議論 を参照してください。
"ClusterFirstWithHostNet": hostNetworkによって稼働しているPodに対しては、ユーザーは明示的にDNSポリシーを"ClusterFirstWithHostNet"とセットするべきです。
"None": この設定では、Kubernetesの環境からDNS設定を無視することができます。全てのDNS設定は、Pod Spec内のdnsConfigフィールドを指定して提供することになっています。下記のセクションのPod's DNS config を参照ください。
備考: "Default"は、デフォルトのDNSポリシーではありません。もしdnsPolicyが明示的に指定されていない場合、"ClusterFirst"が使用されます。
下記の例では、hostNetworkフィールドがtrueにセットされているため、dnsPolicyが"ClusterFirstWithHostNet"とセットされているPodを示します。
apiVersion : v1
kind : Pod
metadata :
name : busybox
namespace : default
spec :
containers :
- image : busybox:1.28
command :
- sleep
- "3600"
imagePullPolicy : IfNotPresent
name : busybox
restartPolicy : Always
hostNetwork : true
dnsPolicy : ClusterFirstWithHostNet
PodのDNS設定
PodのDNS設定は、ユーザーがPodに対してそのDNS設定上でさらに制御するための手段を提供します。
dnsConfigフィールドはオプションで、どのような設定のdnsPolicyでも共に機能することができます。しかし、PodのdnsPolicyが"None"にセットされていたとき、dnsConfigフィールドは必ず指定されなくてはなりません。
下記の項目は、ユーザーがdnsConfigフィールドに指定可能なプロパティーとなります。
nameservers: そのPodに対するDNSサーバーとして使われるIPアドレスのリストです。これは最大で3つのIPアドレスを指定することができます。PodのdnsPolicyが"None"に指定されていたとき、そのリストは最低1つのIPアドレスを指定しなければならず、もし指定されていなければ、それ以外のdnsPolicyの値の場合は、このプロパティーはオプションとなります。searches: Pod内のホスト名のルックアップのためのDNSサーチドメインのリストです。このプロパティーはオプションです。指定されていたとき、このリストは選択されたDNSポリシーから生成されたサーチドメイン名のベースとなるリストにマージされます。重複されているドメイン名は削除されます。Kubernetesでは最大6つのサーチドメインの設定を許可しています。options: nameプロパティー(必須)とvalueプロパティー(オプション)を持つような各オプジェクトのリストで、これはオプションです。このプロパティー内の内容は指定されたDNSポリシーから生成されたオプションにマージされます。重複されたエントリーは削除されます。
下記のファイルはカスタムDNS設定を持ったPodの例です。
apiVersion : v1
kind : Pod
metadata :
namespace : default
name : dns-example
spec :
containers :
- name : test
image : nginx
dnsPolicy : "None"
dnsConfig :
nameservers :
- 1.2.3.4
searches :
- ns1.svc.cluster.local
- my.dns.search.suffix
options :
- name : ndots
value : "2"
- name : edns0
上記のPodが作成されたとき、testコンテナは、コンテナ内の/etc/resolv.confファイル内にある下記の内容を取得します。
nameserver 1.2.3.4
search ns1.svc.cluster.local my.dns.search.suffix
options ndots:2 edns0
IPv6用のセットアップのためには、サーチパスとname serverは下記のようにセットアップするべきです。
$ kubectl exec -it dns-example -- cat /etc/resolv.conf
nameserver 2001:db8:30::a
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
DNS機能を利用可用なバージョン
PodのDNS設定と"None"というDNSポリシーの利用可能なバージョンに関しては下記の通りです。
k8s version
Feature support
1.14
ステーブル
1.10
β版 (デフォルトで有効)
1.9
α版
次の項目
DNS設定の管理方法に関しては、DNS Serviceの設定
を確認してください。
5.8 - IPv4/IPv6デュアルスタック
FEATURE STATE: Kubernetes v1.16 [alpha]
IPv4/IPv6デュアルスタックを利用すると、IPv4とIPv6のアドレスの両方をPod およびService に指定できるようになります。
KubernetesクラスターでIPv4/IPv6デュアルスタックのネットワークを有効にすれば、クラスターはIPv4とIPv6のアドレスの両方を同時に割り当てることをサポートするようになります。
サポートされている機能
KubernetesクラスターでIPv4/IPv6デュアルスタックを有効にすると、以下の機能が提供されます。
デュアルスタックのPodネットワーク(PodごとにIPv4とIPv6のアドレスが1つずつ割り当てられます)
IPv4およびIPv6が有効化されたService(各Serviceは1つのアドレスファミリーでなければなりません)
IPv4およびIPv6インターフェースを経由したPodのクラスター外向きの(たとえば、インターネットへの)ルーティング
前提条件
IPv4/IPv6デュアルスタックのKubernetesクラスターを利用するには、以下の前提条件を満たす必要があります。
Kubernetesのバージョンが1.16以降である
プロバイダーがデュアルスタックのネットワークをサポートしている(クラウドプロバイダーなどが、ルーティング可能なIPv4/IPv6ネットワークインターフェースが搭載されたKubernetesを提供可能である)
ネットワークプラグインがデュアルスタックに対応している(KubenetやCalicoなど)
IPv4/IPv6デュアルスタックを有効にする
IPv4/IPv6デュアルスタックを有効にするには、クラスターの関連コンポーネントでIPv6DualStackフィーチャーゲート を有効にして、デュアルスタックのクラスターネットワークの割り当てを以下のように設定します。
kube-apiserver:
--feature-gates="IPv6DualStack=true"--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>
kube-controller-manager:
--feature-gates="IPv6DualStack=true"--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--service-cluster-ip-range=<IPv4 CIDR>,<IPv6 CIDR>--node-cidr-mask-size-ipv4|--node-cidr-mask-size-ipv6 デフォルトのサイズは、IPv4では/24、IPv6では/64です
kubelet:
--feature-gates="IPv6DualStack=true"
kube-proxy:
--cluster-cidr=<IPv4 CIDR>,<IPv6 CIDR>--feature-gates="IPv6DualStack=true"
備考: IPv4 CIDRの例: 10.244.0.0/16 (自分のクラスターのアドレス範囲を指定してください)
IPv6 CIDRの例: fdXY:IJKL:MNOP:15::/64 (これはフォーマットを示すための例であり、有効なアドレスではありません。詳しくはRFC 4193 を参照してください)
Service
クラスターでIPv4/IPv6デュアルスタックのネットワークを有効にした場合、IPv4またはIPv6のいずれかのアドレスを持つService を作成できます。Serviceのcluster IPのアドレスファミリーは、Service上に.spec.ipFamilyフィールドを設定することで選択できます。このフィールドを設定できるのは、新しいServiceの作成時のみです。.spec.ipFamilyフィールドの指定はオプションであり、Service とIngress でIPv4とIPv6を有効にする予定がある場合にのみ使用するべきです。このフィールドの設定は、外向きのトラフィック に対する要件には含まれません。
備考: クラスターのデフォルトのアドレスファミリーは、kube-controller-managerに--service-cluster-ip-rangeフラグで設定した、最初のservice cluster IPの範囲のアドレスファミリーです。
.spec.ipFamilyは、次のいずれかに設定できます。
IPv4: APIサーバーはipv4のservice-cluster-ip-rangeの範囲からIPアドレスを割り当てますIPv6: APIサーバーはipv6のservice-cluster-ip-rangeの範囲からIPアドレスを割り当てます
次のServiceのspecにはipFamilyフィールドが含まれていません。Kubernetesは、最初に設定したservice-cluster-ip-rangeの範囲からこのServiceにIPアドレス(別名「cluster IP」)を割り当てます。
apiVersion : v1
kind : Service
metadata :
name : my-service
labels :
app : MyApp
spec :
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
次のServiceのspecにはipFamilyフィールドが含まれています。Kubernetesは、最初に設定したservice-cluster-ip-rangeの範囲からこのServiceにIPv6のアドレス(別名「cluster IP」)を割り当てます。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
ipFamily : IPv6
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
比較として次のServiceのspecを見ると、このServiceには最初に設定したservice-cluster-ip-rangeの範囲からIPv4のアドレス(別名「cluster IP」)が割り当てられます。
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
ipFamily : IPv4
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
Type LoadBalancer
IPv6が有効になった外部ロードバランサーをサポートしているクラウドプロバイダーでは、typeフィールドにLoadBalancerを指定し、ipFamilyフィールドにIPv6を指定することにより、クラウドロードバランサーをService向けにプロビジョニングできます。
外向きのトラフィック
パブリックおよび非パブリックでのルーティングが可能なIPv6アドレスのブロックを利用するためには、クラスターがベースにしているCNI プロバイダーがIPv6の転送を実装している必要があります。もし非パブリックでのルーティングが可能なIPv6アドレスを使用するPodがあり、そのPodをクラスター外の送信先(例:パブリックインターネット)に到達させたい場合、外向きのトラフィックと応答の受信のためにIPマスカレードを設定する必要があります。ip-masq-agent はデュアルスタックに対応しているため、デュアルスタックのクラスター上でのIPマスカレードにはip-masq-agentが利用できます。
既知の問題
Kubenetは、IPv4,IPv6の順番にIPを報告することを強制します(--cluster-cidr)
次の項目
5.9 - トポロジーを意識したルーティング
Topology Aware Routing は、ネットワークトラフィックを発信元のゾーン内に留めておくのに役立つメカニズムを提供します。クラスター内のPod間で同じゾーンのトラフィックを優先することで、信頼性、パフォーマンス(ネットワークの待ち時間やスループット)の向上、またはコストの削減に役立ちます。
FEATURE STATE: Kubernetes v1.23 [beta]
備考: Kubernetes 1.27より前には、この機能は、Topology Aware Hint として知られていました。
Topology Aware Routing は、トラフィックを発信元のゾーンに維持するようにルーティング動作を調整します。場合によっては、コストを削減したり、ネットワークパフォーマンスを向上させたりすることができます。
動機
Kubernetesクラスターは、マルチゾーン環境で展開されることが多くなっています。
Topology Aware Routing は、トラフィックを発信元のゾーン内に留めておくのに役立つメカニズムを提供します。EndpointSliceコントローラーはService のendpointを計算する際に、各endpointのトポロジー(リージョンとゾーン)を考慮し、ゾーンに割り当てるためのヒントフィールドに値を入力します。kube-proxy のようなクラスターコンポーネントは、次にこれらのヒントを消費し、それらを使用してトラフィックがルーティングされる方法に影響を与えることが可能です(トポロジー的に近いendpointを優先します)。
Topology Aware Routingを有効にする
備考: Kubernetes 1.27より前には、この動作はservice.kubernetes.io/topology-aware-hintsアノテーションを使用して制御されていました。
service.kubernetes.io/topology-modeアノテーションをautoに設定すると、サービスに対してTopology Aware Routingを有効にすることができます。各ゾーンに十分なendpointがある場合、個々のendpointを特定のゾーンに割り当てるために、トポロジーヒントがEndpointSliceに入力され、その結果、トラフィックは発信元の近くにルーティングされます。
最も効果的なとき
この機能は、次の場合に最も効果的に動作します。
1. 受信トラフィックが均等に分散されている
トラフィックの大部分が単一のゾーンから発信されている場合、トラフィックはそのゾーンに割り当てられたendpointのサブセットに過負荷を与える可能性があります。受信トラフィックが単一のゾーンから発信されることが予想される場合、この機能は推奨されません。
2. 1つのゾーンに3つ以上のendpointを持つサービス
3つのゾーンからなるクラスターでは、これは9つ以上のendpointがあることを意味します。ゾーン毎のendpointが3つ未満の場合、EndpointSliceコントローラーはendpointを均等に割り当てることができず、代わりにデフォルトのクラスター全体のルーティングアプローチに戻る可能性が高く(約50%)なります。
使い方
「Auto」ヒューリスティックは、各ゾーンに多数のendpointを比例的に割り当てようとします。このヒューリスティックは、非常に多くのendpointを持つサービスに最適です。
EndpointSliceコントローラー
このヒューリスティックが有効な場合、EndpointSliceコントローラーはEndpointSliceにヒントを設定する役割を担います。コントローラーは、各ゾーンに比例した量のendpointを割り当てます。この割合は、そのゾーンで実行されているノードの割り当て可能な CPUコアを基に決定されます。
たとえば、あるゾーンに2つのCPUコアがあり、別のゾーンに1つのCPUコアしかない場合、コントローラーは2つのCPUコアを持つゾーンに2倍のendpointを割り当てます。
次の例は、ヒントが入力されたときのEndpointSliceの様子を示しています。
apiVersion : discovery.k8s.io/v1
kind : EndpointSlice
metadata :
name : example-hints
labels :
kubernetes.io/service-name : example-svc
addressType : IPv4
ports :
- name : http
protocol : TCP
port : 80
endpoints :
- addresses :
- "10.1.2.3"
conditions :
ready : true
hostname : pod-1
zone : zone-a
hints :
forZones :
- name : "zone-a"
kube-proxy
kube-proxyは、EndpointSliceコントローラーによって設定されたヒントに基づいて、ルーティング先のendpointをフィルター処理します。ほとんどの場合、これはkube-proxyが同じゾーン内のendpointにトラフィックをルーティングできることを意味します。コントローラーが別のゾーンからendpointを割り当てて、ゾーン間でendpointがより均等に分散されるようにする場合があります。これにより、一部のトラフィックが他のゾーンにルーティングされます。
セーフガード
各ノードのKubernetesコントロールプレーンとkube-proxyは、Topology Aware Hintを使用する前に、いくつかのセーフガードルールを適用します。これらがチェックアウトされない場合、kube-proxyは、ゾーンに関係なく、クラスター内のどこからでもendpointを選択します。
endpointの数が不十分です: クラスター内のゾーンよりもendpointが少ない場合、コントローラーはヒントを割り当てません。
バランスの取れた割り当てを実現できません: 場合によっては、ゾーン間でendpointのバランスの取れた割り当てを実現できないことがあります。たとえば、ゾーンaがゾーンbの2倍の大きさであるが、endpointが2つしかない場合、ゾーンaに割り当てられたendpointはゾーンbの2倍のトラフィックを受信する可能性があります。この「予想される過負荷」値が各ゾーンの許容しきい値を下回ることができない場合、コントローラーはヒントを割り当てません。重要なことに、これはリアルタイムのフィードバックに基づいていません。それでも、個々のendpointが過負荷になる可能性があります。
1つ以上のノードの情報が不十分です: ノードにtopology.kubernetes.io/zoneラベルがないか、割り当て可能なCPUの値を報告していない場合、コントロールプレーンはtopology-aware endpoint hintsを設定しないため、kube-proxyはendpointをゾーンでフィルタリングしません。
1つ以上のendpointにゾーンヒントが存在しません: これが発生すると、kube-proxyはTopology Aware Hintから、またはTopology Aware Hintへの移行が進行中であると見なします。この状態のサービスに対してendpointをフィルタリングすることは危険であるため、kube-proxyはすべてのendpointを使用するようにフォールバックします。
ゾーンはヒントで表されません: kube-proxyが、実行中のゾーンをターゲットとするヒントを持つendpointを1つも見つけることができない場合、すべてのゾーンのendpointを使用することになります。これは既存のクラスターに新しいゾーンを追加するときに発生する可能性が最も高くなります。
制約事項
ServiceでexternalTrafficPolicyまたはinternalTrafficPolicyがLocalに設定されている場合、Topology Aware Hintは使用されません。同じServiceではなく、異なるServiceの同じクラスターで両方の機能を使用することができます。
このアプローチは、ゾーンのサブセットから発信されるトラフィックの割合が高いサービスではうまく機能しません。代わりに、これは着信トラフィックが各ゾーンのノードの容量にほぼ比例することを前提としています。
EndpointSliceコントローラーは、各ゾーンの比率を計算するときに、準備ができていないノードを無視します。ノードの大部分の準備ができていない場合、これは意図しない結果をもたらす可能性があります。
EndpointSliceコントローラーは、node-role.kubernetes.io/control-planeまたはnode-role.kubernetes.io/masterラベルが設定されたノードを無視します。それらのノードでワークロードが実行されている場合、これは問題になる可能性があります。
EndpointSliceコントローラーは、各ゾーンの比率を計算するデプロイ時にtoleration を考慮しません。サービスをバックアップするPodがクラスター内のノードのサブセットに制限されている場合、これは考慮されません。
これはオートスケーリングと相性が悪いかもしれません。例えば、多くのトラフィックが1つのゾーンから発信されている場合、そのゾーンに割り当てられたendpointのみがそのトラフィックを処理することになります。その結果、Horizontal Pod Autoscaler がこのイベントを拾えなくなったり、新しく追加されたPodが別のゾーンで開始されたりする可能性があります。
カスタムヒューリスティック
Kubernetesは様々な方法でデブロイされ、endpointをゾーンに割り当てるための単独のヒューリスティックは、すべてのユースケースに通用するわけではありません。
この機能の主な目的は、内蔵のヒューリスティックがユースケースに合わない場合に、カスタムヒューリスティックを開発できるようにすることです。カスタムヒューリスティックを有効にするための最初のステップは、1.27リリースに含まれています。これは限定的な実装であり、関連する妥当と思われる状況をまだカバーしていない可能性があります。
次の項目
5.10 - サービス内部トラフィックポリシー
FEATURE STATE: Kubernetes v1.21 [alpha]
サービス内部トラフィックポリシー を使用すると、内部トラフィック制限により、トラフィックが発信されたノード内のエンドポイントにのみ内部トラフィックをルーティングできます。
ここでの「内部」トラフィックとは、現在のクラスターのPodから発信されたトラフィックを指します。これは、コストを削減し、パフォーマンスを向上させるのに役立ちます。
ServiceInternalTrafficPolicyの使用
ServiceInternalTrafficPolicy フィーチャーゲート を有効にすると、.spec.internalTrafficPolicyをLocalに設定して、Service 内部のみのトラフィックポリシーを有効にすることができます。
これにより、kube-proxyは、クラスター内部トラフィックにノードローカルエンドポイントのみを使用するようになります。
備考: 特定のServiceのエンドポイントがないノード上のPodの場合、Serviceに他のノードのエンドポイントがある場合でも、Serviceは(このノード上のポッドの)エンドポイントがゼロであるかのように動作します。
次の例は、.spec.internalTrafficPolicyをLocalに設定した場合のServiceの様子を示しています:
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
selector :
app : MyApp
ports :
- protocol : TCP
port : 80
targetPort : 9376
internalTrafficPolicy : Local
使い方
kube-proxyは、spec.internalTrafficPolicyの設定に基づいて、ルーティング先のエンドポイントをフィルタリングします。
spec.internalTrafficPolicyがLocalであれば、ノードのローカルエンドポイントにのみルーティングできるようにします。Clusterまたは未設定であればすべてのエンドポイントにルーティングできるようにします。
ServiceInternalTrafficPolicyフィーチャーゲート が有効な場合、spec.internalTrafficPolicyのデフォルトはClusterです。
制約
ServiceでexternalTrafficPolicyがLocalに設定されている場合、サービス内部トラフィックポリシーは使用されません。同じServiceだけではなく、同じクラスター内の異なるServiceで両方の機能を使用することができます。
次の項目
6 - ストレージ
6.1 - ボリューム
コンテナ内のディスク上のファイルは一時的なものであり、コンテナ内で実行する場合、重要なアプリケーションでいくつかの問題が発生します。1つの問題は、コンテナがクラッシュしたときにファイルが失われることです。kubeletはコンテナを再起動しますが、クリーンな状態です。
2番目の問題は、Podで一緒に実行されているコンテナ間でファイルを共有するときに発生します。
Kubernetesボリューム の抽象化は、これらの問題の両方を解決します。
Pod に精通していることをお勧めします。
背景
Dockerにはボリューム の概念がありますが、多少緩く、管理も不十分です。Dockerボリュームは、ディスク上または別のコンテナ内のディレクトリです。Dockerはボリュームドライバーを提供しますが、機能は多少制限されています。
Kubernetesは多くの種類のボリュームをサポートしています。
Pod は任意の数のボリュームタイプを同時に使用できます。
エフェメラルボリュームタイプにはPodの存続期間がありますが、永続ボリュームはPodの存続期間を超えて存在します。
Podが存在しなくなると、Kubernetesはエフェメラルボリュームを破棄します。ただしKubernetesは永続ボリュームを破棄しません。
特定のPod内のあらゆる種類のボリュームについて、データはコンテナの再起動後も保持されます。
コアとなるボリュームはディレクトリであり、Pod内のコンテナからアクセスできるデータが含まれている可能性があります。
ディレクトリがどのように作成されるか、それをバックアップするメディア、およびそのコンテンツは、使用する特定のボリュームタイプによって決まります。
ボリュームを使用するには、.spec.volumesでPodに提供するボリュームを指定し、.spec.containers[*].volumeMountsでそれらのボリュームをコンテナにマウントする場所を宣言します。
コンテナ内のプロセスはコンテナイメージ の初期コンテンツと、コンテナ内にマウントされたボリューム(定義されている場合)で構成されるファイルシステムビューを確認します。
プロセスは、コンテナイメージのコンテンツと最初に一致するルートファイルシステムを確認します。
そのファイルシステム階層内への書き込みは、もし許可されている場合、後続のファイルシステムアクセスを実行するときにそのプロセスが表示する内容に影響します。
ボリュームはイメージ内の指定されたパス へマウントされます。
Pod内で定義されたコンテナごとに、コンテナが使用する各ボリュームをマウントする場所を個別に指定する必要があります。
ボリュームは他のボリューム内にマウントできません(ただし、関連するメカニズムについては、subPathの使用 を参照してください)。
またボリュームには、別のボリューム内の何かへのハードリンクを含めることはできません。
ボリュームの種類
Kubernetesはいくつかのタイプのボリュームをサポートしています。
awsElasticBlockStore
awsElasticBlockStoreボリュームは、Amazon Web Services(AWS)EBSボリューム をPodにマウントします。
Podを削除すると消去されるemptyDirとは異なり、EBSボリュームのコンテンツは保持されたままボリュームはアンマウントされます。
これは、EBSボリュームにデータを事前入力でき、データをPod間で共有できることを意味します。
備考: 使用する前に、aws ec2 create-volumeまたはAWSAPIを使用してEBSボリュームを作成する必要があります。
awsElasticBlockStoreボリュームを使用する場合、いくつかの制限があります。
Podが実行されているノードはAWS EC2インスタンスである必要があります
これらのインスタンスは、EBSボリュームと同じリージョンおよびアベイラビリティーゾーンにある必要があります
EBSは、ボリュームをマウントする単一のEC2インスタンスのみをサポートします
AWS EBSボリュームの作成
PodでEBSボリュームを使用する前に作成する必要があります。
aws ec2 create-volume --availability-zone= eu-west-1a --size= 10 --volume-type= gp2
ゾーンがクラスターを立ち上げたゾーンと一致していることを確認してください。サイズとEBSボリュームタイプが使用に適していることを確認してください。
AWS EBS設定例
apiVersion : v1
kind : Pod
metadata :
name : test-ebs
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-ebs
name : test-volume
volumes :
- name : test-volume
# This AWS EBS volume must already exist.
awsElasticBlockStore :
volumeID : "<volume id>"
fsType : ext4
EBSボリュームがパーティション化されている場合は、オプションのフィールドpartition: "<partition number>"を指定して、マウントするパーティションを指定できます。
AWS EBS CSIの移行
FEATURE STATE: Kubernetes v1.17 [beta]
awsElasticBlockStoreのCSIMigration機能を有効にすると、すべてのプラグイン操作が既存のツリー内プラグインからebs.csi.aws.comContainer Storage Interface(CSI)ドライバーにリダイレクトされます。
この機能を使用するには、AWS EBS CSIドライバー がクラスターにインストールされ、CSIMigrationとCSIMigrationAWSのbeta機能が有効になっている必要があります。
AWS EBS CSIの移行の完了
FEATURE STATE: Kubernetes v1.17 [alpha]
awsElasticBlockStoreストレージプラグインがコントローラーマネージャーとkubeletによって読み込まれないようにするには、InTreePluginAWSUnregisterフラグをtrueに設定します。
azureDisk
azureDiskボリュームタイプは、MicrosoftAzureデータディスク をPodにマウントします。
詳細については、azureDiskボリュームプラグイン
azureDisk CSIの移行
FEATURE STATE: Kubernetes v1.19 [beta]
azureDiskのCSIMigration機能を有効にすると、すべてのプラグイン操作が既存のツリー内プラグインからdisk.csi.azure.comContainer Storage Interface(CSI)ドライバーにリダイレクトされます。
この機能を利用するには、クラスターにAzure Disk CSI Driver をインストールし、CSIMigrationおよびCSIMigrationAzureDisk機能を有効化する必要があります。
azureFile
azureFileボリュームタイプは、Microsoft Azureファイルボリューム(SMB 2.1および3.0)をPodにマウントします。
詳細についてはazureFile volume plugin
azureFile CSIの移行
FEATURE STATE: Kubernetes v1.21 [beta]
zureFileのCSIMigration機能を有効にすると、既存のツリー内プラグインからfile.csi.azure.comContainer Storage Interface(CSI)Driverへすべてのプラグイン操作がリダイレクトされます。
この機能を利用するには、クラスターにAzure File CSI Driver をインストールし、CSIMigrationおよびCSIMigrationAzureFileフィーチャーゲート を有効化する必要があります。
Azure File CSIドライバーは、異なるfsgroupで同じボリュームを使用することをサポートしていません。AzurefileCSIの移行が有効になっている場合、異なるfsgroupで同じボリュームを使用することはまったくサポートされません。
cephfs
cephfsボリュームを使用すると、既存のCephFSボリュームをPodにマウントすることができます。
Podを取り外すと消去されるemptyDirとは異なり、cephfsボリュームは内容を保持したまま単にアンマウントされるだけです。
つまりcephfsボリュームにあらかじめデータを入れておき、そのデータをPod間で共有することができます。
cephfsボリュームは複数の書き込み元によって同時にマウントすることができます。
備考: 事前に共有をエクスポートした状態で、自分のCephサーバーを起動しておく必要があります。
詳細についてはCephFSの例 を参照してください。
cinder
備考: KubernetesはOpenStackクラウドプロバイダーで構成する必要があります。
cinderボリュームタイプは、PodにOpenStackのCinderのボリュームをマウントするために使用されます。
Cinderボリュームの設定例
apiVersion : v1
kind : Pod
metadata :
name : test-cinder
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-cinder-container
volumeMounts :
- mountPath : /test-cinder
name : test-volume
volumes :
- name : test-volume
# This OpenStack volume must already exist.
cinder :
volumeID : "<volume id>"
fsType : ext4
OpenStack CSIの移行
FEATURE STATE: Kubernetes v1.21 [beta]
CinderのCSIMigration機能は、Kubernetes1.21ではデフォルトで有効になっています。
既存のツリー内プラグインからのすべてのプラグイン操作をcinder.csi.openstack.orgContainer Storage Interface(CSI) Driverへリダイレクトします。
OpenStack Cinder CSIドライバー をクラスターにインストールする必要があります。
CSIMigrationOpenStackフィーチャーゲート をfalseに設定すると、クラスターのCinder CSIマイグレーションを無効化することができます。
CSIMigrationOpenStack機能を無効にすると、ツリー内のCinderボリュームプラグインがCinderボリュームのストレージ管理のすべての側面に責任を持つようになります。
configMap
ConfigMap は構成データをPodに挿入する方法を提供します。
ConfigMapに格納されたデータは、タイプconfigMapのボリュームで参照され、Podで実行されているコンテナ化されたアプリケーションによって使用されます。
ConfigMapを参照するときは、ボリューム内のConfigMapの名前を指定します。
ConfigMapの特定のエントリに使用するパスをカスタマイズできます。
次の設定は、log-config ConfigMapをconfigmap-podというPodにマウントする方法を示しています。
apiVersion : v1
kind : Pod
metadata :
name : configmap-pod
spec :
containers :
- name : test
image : busybox
volumeMounts :
- name : config-vol
mountPath : /etc/config
volumes :
- name : config-vol
configMap :
name : log-config
items :
- key : log_level
path : log_level
log-configConfigMapはボリュームとしてマウントされ、そのlog_levelエントリに格納されているすべてのコンテンツは、パス/etc/config/log_levelのPodにマウントされます。
このパスはボリュームのmountPathとlog_levelをキーとするpathから派生することに注意してください。
備考:
使用する前にConfigMap を作成する必要があります。
subPath
テキストデータはUTF-8文字エンコードを使用してファイルとして公開されます。その他の文字エンコードにはbinaryDataを使用します。
downwardAPI
downwardAPIボリュームは、アプリケーションへのdownward APIデータを利用できるようになります。ディレクトリをマウントし、要求されたデータをプレーンテキストファイルに書き込みます。
備考: subPathボリュームマウントとしてdownward APIを使用するコンテナは、downward APIの更新を受け取りません。
詳細についてはdownward API example を参照してください。
emptyDir
emptyDirボリュームはPodがノードに割り当てられたときに最初に作成され、そのPodがそのノードで実行されている限り存在します。
名前が示すようにemptyDirボリュームは最初は空です。
Pod内のすべてのコンテナはemptyDirボリューム内の同じファイルを読み書きできますが、そのボリュームは各コンテナで同じパスまたは異なるパスにマウントされることがあります。
何らかの理由でPodがノードから削除されると、emptyDir内のデータは永久に削除されます。
備考: コンテナがクラッシュしても、ノードからPodが削除されることはありません 。emptyDirボリューム内のデータは、コンテナのクラッシュしても安全です。
emptyDirのいくつかの用途は次の通りです。
ディスクベースのマージソートなどのスクラッチスペース
クラッシュからの回復のための長い計算のチェックポイント
Webサーバーコンテナがデータを提供している間にコンテンツマネージャコンテナがフェッチするファイルを保持する
環境に応じて、emptyDirボリュームは、ディスクやSSD、ネットワークストレージなど、ノードをバックアップするあらゆる媒体に保存されます。
ただし、emptyDir.mediumフィールドを"Memory"に設定すると、Kubernetesは代わりにtmpfs(RAMベースのファイルシステム)をマウントします。
tmpfsは非常に高速ですが、ディスクと違ってノードのリブート時にクリアされ、書き込んだファイルはコンテナのメモリー制限にカウントされることに注意してください。
備考: SizeMemoryBackedVolumesフィーチャーゲート が有効な場合、メモリーバックアップボリュームにサイズを指定することができます。
サイズが指定されていない場合、メモリーでバックアップされたボリュームは、Linuxホストのメモリーの50%のサイズになります。
emptyDirの設定例
apiVersion : v1
kind : Pod
metadata :
name : test-pd
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /cache
name : cache-volume
volumes :
- name : cache-volume
emptyDir : {}
fc (fibre channel)
fcボリュームタイプを使用すると、既存のファイバーチャネルブロックストレージボリュームをPodにマウントできます。
targetWWNsボリューム構成のパラメーターを使用して、単一または複数のターゲットWorld Wide Name(WWN)を指定できます。
複数のWWNが指定されている場合、targetWWNは、それらのWWNがマルチパス接続からのものであると想定します。
備考: Kubernetesホストがアクセスできるように、事前にこれらのLUN(ボリューム)をターゲットWWNに割り当ててマスクするようにFCSANゾーニングを構成する必要があります。
詳細についてはfibre channelの例 を参照してください。
flocker (非推奨)
Flocker はオープンソースのクラスター化されたコンテナデータボリュームマネージャーです。
Flockerは、さまざまなストレージバックエンドに支えられたデータボリュームの管理とオーケストレーションを提供します。
flockerボリュームを使用すると、FlockerデータセットをPodにマウントできます。
もしデータセットがまだFlockerに存在しない場合は、まずFlocker CLIかFlocker APIを使ってデータセットを作成する必要があります。
データセットがすでに存在する場合は、FlockerによってPodがスケジュールされているノードに再アタッチされます。
これは、必要に応じてPod間でデータを共有できることを意味します。
備考: 使用する前に、独自のFlockerインストールを実行する必要があります。
詳細についてはFlocker example を参照してください。
gcePersistentDisk
gcePersistentDiskボリュームは、Google Compute Engine (GCE)の永続ディスク (PD)をPodにマウントします。
Podを取り外すと消去されるemptyDirとは異なり、PDの内容は保持されボリュームは単にアンマウントされるだけです。これはPDにあらかじめデータを入れておくことができ、そのデータをPod間で共有できることを意味します。
備考: gcloudを使用する前に、またはGCE APIまたはUIを使用してPDを作成する必要があります。
gcePersistentDiskを使用する場合、いくつかの制限があります。
Podが実行されているノードはGCE VMである必要があります
これらのVMは、永続ディスクと同じGCEプロジェクトおよびゾーンに存在する必要があります
GCE永続ディスクの機能の1つは、永続ディスクへの同時読み取り専用アクセスです。gcePersistentDiskボリュームを使用すると、複数のコンシューマーが永続ディスクを読み取り専用として同時にマウントできます。
これはPDにデータセットを事前入力してから、必要な数のPodから並行して提供できることを意味します。
残念ながらPDは読み取り/書き込みモードで1つのコンシューマーのみがマウントできます。同時書き込みは許可されていません。
PDが読み取り専用であるか、レプリカ数が0または1でない限り、ReplicaSetによって制御されるPodでGCE永続ディスクを使用すると失敗します。
GCE永続ディスクの作成
PodでGCE永続ディスクを使用する前に、それを作成する必要があります。
gcloud compute disks create --size= 500GB --zone= us-central1-a my-data-disk
GCE永続ディスクの設定例
apiVersion : v1
kind : Pod
metadata :
name : test-pd
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-pd
name : test-volume
volumes :
- name : test-volume
# This GCE PD must already exist.
gcePersistentDisk :
pdName : my-data-disk
fsType : ext4
リージョン永続ディスク
リージョン永続ディスク 機能を使用すると、同じリージョン内の2つのゾーンで使用できる永続ディスクを作成できます。
この機能を使用するには、ボリュームをPersistentVolumeとしてプロビジョニングする必要があります。Podから直接ボリュームを参照することはサポートされていません。
リージョンPD PersistentVolumeを手動でプロビジョニングする
GCE PDのStorageClass を使用して動的プロビジョニングが可能です。
SPDPersistentVolumeを作成する前に、永続ディスクを作成する必要があります。
gcloud compute disks create --size= 500GB my-data-disk
--region us-central1
--replica-zones us-central1-a,us-central1-b
リージョン永続ディスクの設定例
apiVersion : v1
kind : PersistentVolume
metadata :
name : test-volume
spec :
capacity :
storage : 400Gi
accessModes :
- ReadWriteOnce
gcePersistentDisk :
pdName : my-data-disk
fsType : ext4
nodeAffinity :
required :
nodeSelectorTerms :
- matchExpressions :
# failure-domain.beta.kubernetes.io/zone should be used prior to 1.21
- key : topology.kubernetes.io/zone
operator : In
values :
- us-central1-a
- us-central1-b
GCE CSIの移行
FEATURE STATE: Kubernetes v1.17 [beta]
GCE PDのCSIMigration機能を有効にすると、すべてのプラグイン操作が既存のツリー内プラグインからpd.csi.storage.gke.ioContainer Storage Interface (CSI) Driverにリダイレクトされるようになります。
この機能を使用するには、クラスターにGCE PD CSI Driver がインストールされ、CSIMigrationとCSIMigrationGCEのbeta機能が有効になっている必要があります。
GCE CSIの移行の完了
FEATURE STATE: Kubernetes v1.21 [alpha]
gcePersistentDiskストレージプラグインがコントローラーマネージャーとkubeletによって読み込まれないようにするには、InTreePluginGCEUnregisterフラグをtrueに設定します。
gitRepo(非推奨)
警告: gitRepoボリュームタイプは非推奨です。gitリポジトリを使用してコンテナをプロビジョニングするには、Gitを使用してリポジトリのクローンを作成するInitContainerに
EmptyDir をマウントしてから、Podのコンテナに
EmptyDir をマウントします。
gitRepoボリュームは、ボリュームプラグインの一例です。このプラグインは空のディレクトリをマウントし、そのディレクトリにgitリポジトリをクローンしてPodで使えるようにします。
gitRepoボリュームの例を次に示します。
apiVersion : v1
kind : Pod
metadata :
name : server
spec :
containers :
- image : nginx
name : nginx
volumeMounts :
- mountPath : /mypath
name : git-volume
volumes :
- name : git-volume
gitRepo :
repository : "git@somewhere:me/my-git-repository.git"
revision : "22f1d8406d464b0c0874075539c1f2e96c253775"
glusterfs
glusterfsボリュームはGlusterfs (オープンソースのネットワークファイルシステム)ボリュームをPodにマウントできるようにするものです。
Podを取り外すと消去されるemptyDirとは異なり、glusterfsボリュームの内容は保持され、単にアンマウントされるだけです。
これは、glusterfsボリュームにデータを事前に入力でき、データをPod間で共有できることを意味します。
GlusterFSは複数のライターが同時にマウントすることができます。
備考: GlusterFSを使用するためには、事前にGlusterFSのインストールを実行しておく必要があります。
詳細についてはGlusterFSの例 を参照してください。
hostPath
警告: HostPathボリュームには多くのセキュリティリスクがあり、可能な場合はHostPathの使用を避けることがベストプラクティスです。HostPathボリュームを使用する必要がある場合は、必要なファイルまたはディレクトリのみにスコープを設定し、読み取り専用としてマウントする必要があります。
AdmissionPolicyによって特定のディレクトリへのHostPathアクセスを制限する場合、ポリシーを有効にするためにvolumeMountsはreadOnlyマウントを使用するように要求されなければなりません。
hostPathボリュームは、ファイルまたはディレクトリをホストノードのファイルシステムからPodにマウントします。
これはほとんどのPodに必要なものではありませんが、一部のアプリケーションには強力なエスケープハッチを提供します。
たとえばhostPathのいくつかの使用法は次のとおりです。
Dockerの内部にアクセスする必要があるコンテナを実行する場合:hostPathに/var/lib/dockerを使用します。
コンテナ内でcAdvisorを実行する場合:hostPathに/sysを指定します。
Podが実行される前に、与えられたhostPathが存在すべきかどうか、作成すべきかどうか、そして何として存在すべきかを指定できるようにします。
必須のpathプロパティに加えて、オプションでhostPathボリュームにtypeを指定することができます。
フィールドtypeでサポートされている値は次のとおりです。
値
ふるまい
空の文字列(デフォルト)は下位互換性のためです。つまり、hostPathボリュームをマウントする前にチェックは実行されません。
DirectoryOrCreate指定されたパスに何も存在しない場合、必要に応じて、権限を0755に設定し、Kubeletと同じグループと所有権を持つ空のディレクトリが作成されます。
Directory指定されたパスにディレクトリが存在する必要があります。
FileOrCreate指定されたパスに何も存在しない場合、必要に応じて、権限を0644に設定し、Kubeletと同じグループと所有権を持つ空のファイルが作成されます。
File指定されたパスにファイルが存在する必要があります。
SocketUNIXソケットは、指定されたパスに存在する必要があります。
CharDeviceキャラクターデバイスは、指定されたパスに存在する必要があります。
BlockDeviceブロックデバイスは、指定されたパスに存在する必要があります。
このタイプのボリュームを使用するときは、以下の理由のため注意してください。
HostPath は、特権的なシステム認証情報(Kubeletなど)や特権的なAPI(コンテナランタイムソケットなど)を公開する可能性があり、コンテナのエスケープやクラスターの他の部分への攻撃に利用される可能性があります。
同一構成のPod(PodTemplateから作成されたものなど)は、ノード上のファイルが異なるため、ノードごとに動作が異なる場合があります。
ホスト上に作成されたファイルやディレクトリは、rootでしか書き込みができません。特権コンテナ 内でrootとしてプロセスを実行するか、ホスト上のファイルのパーミッションを変更してhostPathボリュームに書き込みができるようにする必要があります。
hostPathの設定例
apiVersion : v1
kind : Pod
metadata :
name : test-pd
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-pd
name : test-volume
volumes :
- name : test-volume
hostPath :
# directory location on host
path : /data
# this field is optional
type : Directory
注意: FileOrCreateモードでは、ファイルの親ディレクトリは作成されません。マウントされたファイルの親ディレクトリが存在しない場合、Podは起動に失敗します。
このモードが確実に機能するようにするには、
FileOrCreate構成に示すように、ディレクトリとファイルを別々にマウントしてみてください。
hostPath FileOrCreateの設定例
apiVersion : v1
kind : Pod
metadata :
name : test-webserver
spec :
containers :
- name : test-webserver
image : registry.k8s.io/test-webserver:latest
volumeMounts :
- mountPath : /var/local/aaa
name : mydir
- mountPath : /var/local/aaa/1.txt
name : myfile
volumes :
- name : mydir
hostPath :
# Ensure the file directory is created.
path : /var/local/aaa
type : DirectoryOrCreate
- name : myfile
hostPath :
path : /var/local/aaa/1.txt
type : FileOrCreate
iscsi
iscsiボリュームは、既存のiSCSI(SCSI over IP)ボリュームをPodにマウントすることができます。
Podを取り外すと消去されるemptyDirとは異なり、iscsiボリュームの内容は保持され、単にアンマウントされるだけです。
つまり、iscsiボリュームにはあらかじめデータを入れておくことができ、そのデータをPod間で共有することができるのです。
備考: 使用する前に、ボリュームを作成したiSCSIサーバーを起動する必要があります。
iSCSIの特徴として、複数のコンシューマーから同時に読み取り専用としてマウントできることが挙げられます。
つまり、ボリュームにあらかじめデータセットを入れておき、必要な数のPodから並行してデータを提供することができます。
残念ながら、iSCSIボリュームは1つのコンシューマによってのみ読み書きモードでマウントすることができます。
同時に書き込みを行うことはできません。
詳細についてはiSCSIの例 を参照してください。
local
localボリュームは、ディスク、パーティション、ディレクトリなど、マウントされたローカルストレージデバイスを表します。
ローカルボリュームは静的に作成されたPersistentVolumeとしてのみ使用できます。動的プロビジョニングはサポートされていません。
hostPathボリュームと比較して、localボリュームは手動でノードにPodをスケジューリングすることなく、耐久性と移植性に優れた方法で使用することができます。
システムはPersistentVolume上のノードアフィニティーを見ることで、ボリュームのノード制約を認識します。
ただし、localボリュームは、基盤となるノードの可用性に左右されるため、すべてのアプリケーションに適しているわけではありません。
ノードが異常になると、Podはlocalボリュームにアクセスできなくなります。
このボリュームを使用しているPodは実行できません。localボリュームを使用するアプリケーションは、基盤となるディスクの耐久性の特性に応じて、この可用性の低下と潜在的なデータ損失に耐えられる必要があります。
次の例では、localボリュームとnodeAffinityを使用したPersistentVolumeを示しています。
apiVersion : v1
kind : PersistentVolume
metadata :
name : example-pv
spec :
capacity :
storage : 100Gi
volumeMode : Filesystem
accessModes :
- ReadWriteOnce
persistentVolumeReclaimPolicy : Delete
storageClassName : local-storage
local :
path : /mnt/disks/ssd1
nodeAffinity :
required :
nodeSelectorTerms :
- matchExpressions :
- key : kubernetes.io/hostname
operator : In
values :
- example-node
ローカルボリュームを使用する場合は、PersistentVolume nodeAffinityを設定する必要があります。
KubernetesのスケジューラはPersistentVolume nodeAffinityを使用して、これらのPodを正しいノードにスケジューリングします。
PersistentVolume volumeModeを(デフォルト値の「Filesystem」ではなく)「Block」に設定して、ローカルボリュームをrawブロックデバイスとして公開できます。
ローカルボリュームを使用する場合、volumeBindingModeをWaitForFirstConsumerに設定したStorageClassを作成することをお勧めします。
詳細については、local StorageClass の例を参照してください。
ボリュームバインディングを遅延させると、PersistentVolumeClaimバインディングの決定が、ノードリソース要件、ノードセレクター、Podアフィニティ、Podアンチアフィニティなど、Podが持つ可能性のある他のノード制約も含めて評価されるようになります。
ローカルボリュームのライフサイクルの管理を改善するために、外部の静的プロビジョナーを個別に実行できます。
このプロビジョナーはまだ動的プロビジョニングをサポートしていないことに注意してください。
外部ローカルプロビジョナーの実行方法の例については、ローカルボリュームプロビジョナーユーザーガイド を参照してください。
備考: ボリュームのライフサイクルを管理するために外部の静的プロビジョナーが使用されていない場合、ローカルのPersistentVolumeは、ユーザーによる手動のクリーンアップと削除を必要とします。
nfs
nfsボリュームは、既存のNFS(Network File System)共有をPodにマウントすることを可能にします。Podを取り外すと消去されるemptyDirとは異なり、nfsボリュームのコンテンツは保存され、単にアンマウントされるだけです。
つまり、NFSボリュームにはあらかじめデータを入れておくことができ、そのデータをPod間で共有することができます。
NFSは複数のライターによって同時にマウントすることができます。
備考: 使用する前に、共有をエクスポートしてNFSサーバーを実行する必要があります。
詳細についてはNFSの例 を参照してください。
persistentVolumeClaim
PersistentVolumeClaimボリュームはPersistentVolume をPodにマウントするために使用されます。
PersistentVolumeClaimは、ユーザが特定のクラウド環境の詳細を知らなくても、耐久性のあるストレージ(GCE永続ディスクやiSCSIボリュームなど)を「要求」するための方法です。
詳細についてはPersistentVolume を参照してください。
portworxVolume
portworxVolumeは、Kubernetesとハイパーコンバージドで動作するエラスティックブロックストレージレイヤーです。
Portworx は、サーバー内のストレージをフィンガープリントを作成し、機能に応じて階層化し、複数のサーバーにまたがって容量を集約します。
Portworxは、仮想マシンまたはベアメタルのLinuxノードでゲスト内動作します。
portworxVolumeはKubernetesを通して動的に作成することができますが、事前にプロビジョニングしてPodの中で参照することもできます。
以下は、事前にプロビジョニングされたPortworxボリュームを参照するPodの例です。
apiVersion : v1
kind : Pod
metadata :
name : test-portworx-volume-pod
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /mnt
name : pxvol
volumes :
- name : pxvol
# This Portworx volume must already exist.
portworxVolume :
volumeID : "pxvol"
fsType : "<fs-type>"
備考: Podで使用する前に、pxvolという名前の既存のPortworxVolumeがあることを確認してください。
詳細についてはPortworxボリューム の例を参照してください。
投影
投影ボリュームは、複数の既存のボリュームソースを同じディレクトリにマッピングします。
詳細については投影ボリューム を参照してください。
quobyte(非推奨)
quobyteボリュームは、既存のQuobyte ボリュームをPodにマウントすることができます。
備考: 使用する前にQuobyteをセットアップして、ボリュームを作成した状態で動作させる必要があります。
CSIは、Kubernetes内部でQuobyteボリュームを使用するための推奨プラグインです。
QuobyteのGitHubプロジェクトには、CSIを使用してQuobyteをデプロイするための手順 と例があります
rbd
rbdボリュームはRados Block Device (RBD)ボリュームをPodにマウントすることを可能にします。
Podを取り外すと消去されるemptyDirとは異なり、rbdボリュームの内容は保存され、ボリュームはアンマウントされます。つまり、RBDボリュームにはあらかじめデータを入れておくことができ、そのデータをPod間で共有することができるのです。
備考: RBDを使用する前に、Cephのインストールが実行されている必要があります。
RBDの特徴として、複数のコンシューマーから同時に読み取り専用としてマウントできることが挙げられます。
つまり、ボリュームにあらかじめデータセットを入れておき、必要な数のPodから並行して提供することができるのです。
残念ながら、RBDボリュームは1つのコンシューマーによってのみ読み書きモードでマウントすることができます。
同時に書き込みを行うことはできません。
詳細についてはRBDの例 を参照してください。
RBD CSIの移行
FEATURE STATE: Kubernetes v1.23 [alpha]
RBDのCSIMigration機能を有効にすると、既存のツリー内プラグインからrbd.csi.ceph.comCSI ドライバーにすべてのプラグイン操作がリダイレクトされます。
この機能を使用するには、クラスターにCeph CSIドライバー をインストールし、CSIMigrationおよびcsiMigrationRBDフィーチャーゲート を有効にしておく必要があります。
備考: ストレージを管理するKubernetesクラスターオペレーターとして、RBD CSIドライバーへの移行を試みる前に完了する必要のある前提条件は次のとおりです。
Ceph CSIドライバー(rbd.csi.ceph.com)v3.5.0以降をKubernetesクラスターにインストールする必要があります。
CSIドライバーの動作に必要なパラメーターとしてclusterIDフィールドがありますが、ツリー内StorageClassにはmonitorsフィールドがあるため、Kubernetesストレージ管理者はCSI config mapでモニターハッシュ(例:#echo -n '<monitors_string>' | md5sum)に基づいたclusterIDを作成し、モニターをこのclusterID設定の下に保持しなければなりません。
また、ツリー内StorageclassのadminIdの値がadminと異なる場合、ツリー内Storageclassに記載されているadminSecretNameにadminIdパラメーター値のbase64値をパッチしなければなりませんが、それ以外はスキップすることが可能です。
secret
secretボリュームは、パスワードなどの機密情報をPodに渡すために使用します。
Kubernetes APIにsecretを格納し、Kubernetesに直接結合することなくPodが使用するファイルとしてマウントすることができます。
secretボリュームはtmpfs(RAM-backed filesystem)によってバックアップされるため、不揮発性ストレージに書き込まれることはありません。
備考: 使用する前にKubernetes APIでSecretを作成する必要があります。
備考: SubPathボリュームマウントとしてSecretを使用しているコンテナは、Secretの更新を受け取りません。
詳細についてはSecretの設定 を参照してください。
storageOS(非推奨)
storageosボリュームを使用すると、既存のStorageOS ボリュームをPodにマウントできます。
StorageOSは、Kubernetes環境内でコンテナとして実行され、Kubernetesクラスター内の任意のノードからローカルストレージまたは接続されたストレージにアクセスできるようにします。
データを複製してノードの障害から保護することができます。シンプロビジョニングと圧縮により使用率を向上させ、コストを削減できます。
根本的にStorageOSは、コンテナにブロックストレージを提供しファイルシステムからアクセスできるようにします。
StorageOS Containerは64ビットLinuxを必要とし、追加の依存関係はありません。
無償の開発者ライセンスが利用可能です。
注意: StorageOSボリュームにアクセスする、またはプールにストレージ容量を提供する各ノードでStorageOSコンテナを実行する必要があります。
インストール手順については、
StorageOSドキュメント を参照してください。
次の例は、StorageOSを使用したPodの設定です。
apiVersion : v1
kind : Pod
metadata :
labels :
name : redis
role : master
name : test-storageos-redis
spec :
containers :
- name : master
image : kubernetes/redis:v1
env :
- name : MASTER
value : "true"
ports :
- containerPort : 6379
volumeMounts :
- mountPath : /redis-master-data
name : redis-data
volumes :
- name : redis-data
storageos :
# The `redis-vol01` volume must already exist within StorageOS in the `default` namespace.
volumeName : redis-vol01
fsType : ext4
StorageOS、動的プロビジョニング、およびPersistentVolumeClaimの詳細については、StorageOSの例 を参照してください。
vsphereVolume
備考: KubernetesvSphereクラウドプロバイダーを設定する必要があります。クラウドプロバイダーの設定については、
vSphere入門ガイド を参照してください。
vsphereVolumeは、vSphereVMDKボリュームをPodにマウントするために使用されます。
ボリュームの内容は、マウント解除されたときに保持されます。VMFSとVSANの両方のデータストアをサポートします。
備考: Podで使用する前に、次のいずれかの方法を使用してvSphereVMDKボリュームを作成する必要があります。
Creating a VMDK volume
次のいずれかの方法を選択して、VMDKを作成します。
最初にESXにSSHで接続し、次に以下のコマンドを使用してVMDKを作成します。
vmkfstools -c 2G /vmfs/volumes/DatastoreName/volumes/myDisk.vmdk
次のコマンドを使用してVMDKを作成します。
vmware-vdiskmanager -c -t 0 -s 40GB -a lsilogic myDisk.vmdk
vSphere VMDKの設定例
apiVersion : v1
kind : Pod
metadata :
name : test-vmdk
spec :
containers :
- image : registry.k8s.io/test-webserver
name : test-container
volumeMounts :
- mountPath : /test-vmdk
name : test-volume
volumes :
- name : test-volume
# This VMDK volume must already exist.
vsphereVolume :
volumePath : "[DatastoreName] volumes/myDisk"
fsType : ext4
詳細についてはvSphereボリューム の例を参照してください。
vSphere CSIの移行
FEATURE STATE: Kubernetes v1.19 [beta]
vsphereVolumeのCSIMigration機能を有効にすると、既存のツリー内プラグインからcsi.vsphere.vmware.comCSI ドライバーにすべてのプラグイン操作がリダイレクトされます。
この機能を使用するには、クラスターにvSphere CSIドライバー がインストールされ、CSIMigrationおよびCSIMigrationvSphereフィーチャーゲート が有効になっていなければなりません。
また、vSphere vCenter/ESXiのバージョンが7.0u1以上、HWのバージョンがVM version 15以上であることが条件です。
備考: 組み込みのvsphereVolumeプラグインの次のStorageClassパラメーターは、vSphere CSIドライバーでサポートされていません。
diskformathostfailurestotolerateforceprovisioningcachereservationdiskstripesobjectspacereservationiopslimit
これらのパラメーターを使用して作成された既存のボリュームはvSphere CSIドライバーに移行されますが、vSphere CSIドライバーで作成された新しいボリュームはこれらのパラメーターに従わないことに注意してください。
vSphere CSIの移行の完了
FEATURE STATE: Kubernetes v1.19 [beta]
vsphereVolumeプラグインがコントローラーマネージャーとkubeletによって読み込まれないようにするには、InTreePluginvSphereUnregister機能フラグをtrueに設定する必要があります。すべてのワーカーノードにcsi.vsphere.vmware.comCSI ドライバーをインストールする必要があります。
Portworx CSIの移行
FEATURE STATE: Kubernetes v1.23 [alpha]
PortworxのCSIMigration機能が追加されましたが、Kubernetes 1.23ではAlpha状態であるため、デフォルトで無効になっています。
すべてのプラグイン操作を既存のツリー内プラグインからpxd.portworx.comContainer Storage Interface(CSI)ドライバーにリダイレクトします。
Portworx CSIドライバー をクラスターにインストールする必要があります。
この機能を有効にするには、kube-controller-managerとkubeletでCSIMigrationPortworx=trueを設定します。
subPathの使用
1つのPodで複数の用途に使用するために1つのボリュームを共有すると便利な場合があります。
volumeMounts[*].subPathプロパティは、ルートではなく、参照されるボリューム内のサブパスを指定します。
次の例は、単一の共有ボリュームを使用してLAMPスタック(Linux Apache MySQL PHP)でPodを構成する方法を示しています。
このサンプルのsubPath構成は、プロダクションでの使用にはお勧めしません。
PHPアプリケーションのコードとアセットはボリュームのhtmlフォルダーにマップされ、MySQLデータベースはボリュームのmysqlフォルダーに保存されます。例えば:
apiVersion : v1
kind : Pod
metadata :
name : my-lamp-site
spec :
containers :
- name : mysql
image : mysql
env :
- name : MYSQL_ROOT_PASSWORD
value : "rootpasswd"
volumeMounts :
- mountPath : /var/lib/mysql
name : site-data
subPath : mysql
- name : php
image : php:7.0-apache
volumeMounts :
- mountPath : /var/www/html
name : site-data
subPath : html
volumes :
- name : site-data
persistentVolumeClaim :
claimName : my-lamp-site-data
拡張された環境変数でのsubPathの使用
FEATURE STATE: Kubernetes v1.17 [stable]
subPathExprフィールドを使用して、downwart API環境変数からsubPathディレクトリ名を作成します。
subPathプロパティとsubPathExprプロパティは相互に排他的です。
この例では、PodがsubPathExprを使用して、hostPathボリューム/var/log/pods内にpod1というディレクトリを作成します。
hostPathボリュームはdownwardAPIからPod名を受け取ります。
ホストディレクトリ/var/log/pods/pod1は、コンテナ内の/logsにマウントされます。
apiVersion : v1
kind : Pod
metadata :
name : pod1
spec :
containers :
- name : container1
env :
- name : POD_NAME
valueFrom :
fieldRef :
apiVersion : v1
fieldPath : metadata.name
image : busybox
command : [ "sh" , "-c" , "while [ true ]; do echo 'Hello'; sleep 10; done | tee -a /logs/hello.txt" ]
volumeMounts :
- name : workdir1
mountPath : /logs
# The variable expansion uses round brackets (not curly brackets).
subPathExpr : $(POD_NAME)
restartPolicy : Never
volumes :
- name : workdir1
hostPath :
path : /var/log/pods
リソース
emptyDirボリュームの記憶媒体(DiskやSSDなど)は、kubeletのルートディレクトリ(通常は/var/lib/kubelet)を保持するファイルシステムの媒体によって決定されます。
emptyDirまたはhostPathボリュームが消費する容量に制限はなく、コンテナ間またはPod間で隔離されることもありません。
リソース仕様を使用したスペースの要求については、リソースの管理方法 を参照してください。
ツリー外のボリュームプラグイン
ツリー外ボリュームプラグインにはContainer Storage Interface (CSI)、およびFlexVolume(非推奨)があります。
これらのプラグインによりストレージベンダーは、プラグインのソースコードをKubernetesリポジトリに追加することなく、カスタムストレージプラグインを作成することができます。
以前は、すべてのボリュームプラグインが「ツリー内」にありました。
「ツリー内」のプラグインは、Kubernetesのコアバイナリとともにビルド、リンク、コンパイルされ、出荷されていました。
つまり、Kubernetesに新しいストレージシステム(ボリュームプラグイン)を追加するには、Kubernetesのコアコードリポジトリにコードをチェックインする必要があったのです。
CSIとFlexVolumeはどちらも、ボリュームプラグインをKubernetesコードベースとは独立して開発し、拡張機能としてKubernetesクラスターにデプロイ(インストール)することを可能にします。
ツリー外のボリュームプラグインの作成を検討しているストレージベンダーについては、ボリュームプラグインのFAQ を参照してください。
csi
Container Storage Interface (CSI)は、コンテナオーケストレーションシステム(Kubernetesなど)の標準インターフェースを定義して、任意のストレージシステムをコンテナワークロードに公開します。
詳細についてはCSI design proposal を参照してください。
備考: CSI仕様バージョン0.2および0.3のサポートは、Kubernetes v1.13で非推奨になり、将来のリリースで削除される予定です。
備考: CSIドライバーは、すべてのKubernetesリリース間で互換性があるとは限りません。各Kubernetesリリースでサポートされているデプロイ手順と互換性マトリックスについては、特定のCSIドライバーのドキュメントを確認してください。
CSI互換のボリュームドライバーがKubernetesクラスター上に展開されると、ユーザーはcsiボリュームタイプを使用して、CSIドライバーによって公開されたボリュームをアタッチまたはマウントすることができます。
csiボリュームはPodで3つの異なる方法によって使用することができます。
ストレージ管理者は、CSI永続ボリュームを構成するために次のフィールドを使用できます。
driver: 使用するボリュームドライバーの名前を指定する文字列。
この値はCSI spec で定義されたCSIドライバーがGetPluginInfoResponseで返す値に対応していなければなりません。
これはKubernetesが呼び出すCSIドライバーを識別するために使用され、CSIドライバーコンポーネントがCSIドライバーに属するPVオブジェクトを識別するために使用されます。volumeHandle: ボリュームを一意に識別する文字列。この値は、CSI spec で定義されたCSIドライバーがCreateVolumeResponseのvolume.idフィールドに返す値に対応していなければなりません。この値はCSIボリュームドライバーのすべての呼び出しで、ボリュームを参照する際にvolume_idとして渡されます。readOnly: ボリュームを読み取り専用として「ControllerPublished」(添付)するかどうかを示すオプションのブール値。デフォルトはfalseです。この値は、ControllerPublishVolumeRequestのreadonlyフィールドを介してCSIドライバーに渡されます。fsType: PVのVolumeModeがFilesystemの場合、このフィールドを使用して、ボリュームのマウントに使用する必要のあるファイルシステムを指定できます。ボリュームがフォーマットされておらず、フォーマットがサポートされている場合、この値はボリュームのフォーマットに使用されます。この値は、ControllerPublishVolumeRequest、NodeStageVolumeRequest、およびNodePublishVolumeRequestのVolumeCapabilityフィールドを介してCSIドライバーに渡されます。volumeAttributes: ボリュームの静的プロパティを指定する、文字列から文字列へのマップ。このマップは、CSI spec で定義されているように、CSIドライバーがCreateVolumeResponseのvolume.attributesフィールドで返すマップと一致しなければなりません。このマップはControllerPublishVolumeRequest,NodeStageVolumeRequest,NodePublishVolumeRequestのvolume_contextフィールドを介してCSIドライバーに渡されます。controllerPublishSecretRef: CSIControllerPublishVolumeおよびControllerUnpublishVolume呼び出しを完了するためにCSIドライバーに渡す機密情報を含むsecretオブジェクトへの参照。このフィールドはオプションで、secretが必要ない場合は空にすることができます。secretに複数のsecretが含まれている場合は、すべてのsecretが渡されます。nodeStageSecretRef: CSINodeStageVolume呼び出しを完了するために、CSIドライバーに渡す機密情報を含むsecretオブジェクトへの参照。このフィールドはオプションで、secretが必要ない場合は空にすることができます。secretに複数のsecretが含まれている場合、すべてのsecretが渡されます。nodePublishSecretRef: CSINodePublishVolume呼び出しを完了するために、CSIドライバーに渡す機密情報を含むsecretオブジェクトへの参照。このフィールドはオプションで、secretが必要ない場合は空にすることができます。secretオブジェクトが複数のsecretを含んでいる場合、すべてのsecretが渡されます。
CSI rawブロックボリュームのサポート
FEATURE STATE: Kubernetes v1.18 [stable]
外部のCSIドライバーを使用するベンダーは、Kubernetesワークロードでrawブロックボリュームサポートを実装できます。
CSI固有の変更を行うことなく、通常どおり、rawブロックボリュームをサポートするPersistentVolume/PersistentVolumeClaim を設定できます。
CSIエフェメラルボリューム
FEATURE STATE: Kubernetes v1.16 [beta]
Pod仕様内でCSIボリュームを直接構成できます。この方法で指定されたボリュームは一時的なものであり、Podを再起動しても持続しません。詳細についてはエフェメラルボリューム を参照してください。
CSIドライバーの開発方法の詳細についてはkubernetes-csiドキュメント を参照してください。
ツリー内プラグインからCSIドライバーへの移行
FEATURE STATE: Kubernetes v1.17 [beta]
CSIMigration機能を有効にすると、既存のツリー内プラグインに対する操作が、対応するCSIプラグイン(インストールおよび構成されていることが期待されます)に転送されます。
その結果、オペレーターは、ツリー内プラグインに取って代わるCSIドライバーに移行するときに、既存のストレージクラス、PersistentVolume、またはPersistentVolumeClaim(ツリー内プラグインを参照)の構成を変更する必要がありません。
サポートされている操作と機能には、プロビジョニング/削除、アタッチ/デタッチ、マウント/アンマウント、およびボリュームのサイズ変更が含まれます。
CSIMigrationをサポートし、対応するCSIドライバーが実装されているツリー内プラグインは、ボリュームのタイプ にリストされています。
flexVolume
FEATURE STATE: Kubernetes v1.23 [deprecated]
FlexVolumeは、ストレージドライバーとのインターフェースにexecベースのモデルを使用するツリー外プラグインインターフェースです。FlexVolumeドライバーのバイナリは、各ノード、場合によってはコントロールプレーンノードにも、あらかじめ定義されたボリュームプラグインパスにインストールする必要があります。
PodはflexVolumeツリー内ボリュームプラグインを通してFlexVolumeドライバーと対話します。
詳細についてはFlexVolumeのREADME を参照してください。
備考: FlexVolumeは非推奨です。ツリー外のCSIドライバーを使用することは、外部ストレージをKubernetesと統合するための推奨される方法です。
FlexVolumeドライバーのメンテナーは、CSIドライバーを実装し、FlexVolumeドライバーのユーザーをCSIに移行するのを支援する必要があります。FlexVolumeのユーザーは、同等のCSIドライバーを使用するようにワークロードを移動する必要があります。
マウントの伝播
マウントの伝播により、コンテナによってマウントされたボリュームを、同じPod内の他のコンテナ、または同じノード上の他のPodに共有できます。
ボリュームのマウント伝播は、containers[*].volumeMountsのmountPropagationフィールドによって制御されます。その値は次のとおりです。
None - このボリュームマウントは、ホストによってこのボリュームまたはそのサブディレクトリにマウントされる後続のマウントを受け取りません。同様に、コンテナによって作成されたマウントはホストに表示されません。これがデフォルトのモードです。
このモードはLinuxカーネルドキュメント で説明されているprivateマウント伝播と同じです。
HostToContainer - このボリュームマウントは、このボリュームまたはそのサブディレクトリのいずれかにマウントされる後続のすべてのマウントを受け取ります。
つまりホストがボリュームマウント内に何かをマウントすると、コンテナはそこにマウントされていることを確認します。
同様に同じボリュームに対してBidirectionalマウント伝搬を持つPodが何かをマウントすると、HostToContainerマウント伝搬を持つコンテナはそれを見ることができます。
このモードはLinuxカーネルドキュメント で説明されているrslaveマウント伝播と同じです。
Bidirectional - このボリュームマウントは、HostToContainerマウントと同じように動作します。さらに、コンテナによって作成されたすべてのボリュームマウントは、ホストと、同じボリュームを使用するすべてのPodのすべてのコンテナに伝播されます。
このモードの一般的な使用例は、FlexVolumeまたはCSIドライバーを備えたPod、またはhostPathボリュームを使用してホストに何かをマウントする必要があるPodです。
このモードはLinuxカーネルドキュメント で説明されているrsharedマウント伝播と同じです。
警告: Bidirectionalマウント伝搬は危険です。ホストオペレーティングシステムにダメージを与える可能性があるため、特権的なコンテナでのみ許可されています。
Linuxカーネルの動作に精通していることが強く推奨されます。
また、Pod内のコンテナによって作成されたボリュームマウントは、終了時にコンテナによって破棄(アンマウント)される必要があります。
構成
一部のデプロイメント(CoreOS、RedHat/Centos、Ubuntu)でマウント伝播が正しく機能する前に、以下に示すように、Dockerでマウント共有を正しく構成する必要があります。
Dockerのsystemdサービスファイルを編集します。以下のようにMountFlagsを設定します。
または、MountFlags=slaveがあれば削除してください。その後、Dockerデーモンを再起動します。
sudo systemctl daemon-reload
sudo systemctl restart docker
次の項目
永続ボリュームを使用してWordPressとMySQLをデプロイする例 に従ってください。
6.2 - 永続ボリューム
このドキュメントではKubernetesの PersistentVolume について説明します。ボリューム を一読することをおすすめします。
概要
ストレージを管理することはインスタンスを管理することとは全くの別物です。PersistentVolumeサブシステムは、ストレージが何から提供されているか、どのように消費されているかをユーザーと管理者から抽象化するAPIを提供します。これを実現するためのPersistentVolumeとPersistentVolumeClaimという2つの新しいAPIリソースを紹介します。
PersistentVolume (PV)はストレージクラス を使って管理者もしくは動的にプロビジョニングされるクラスターのストレージの一部です。これはNodeと同じようにクラスターリソースの一部です。PVはVolumeのようなボリュームプラグインですが、PVを使う個別のPodとは独立したライフサイクルを持っています。このAPIオブジェクトはNFS、iSCSIやクラウドプロバイダー固有のストレージシステムの実装の詳細を捕捉します。
PersistentVolumeClaim (PVC)はユーザーによって要求されるストレージです。これはPodと似ています。PodはNodeリソースを消費し、PVCはPVリソースを消費します。Podは特定レベルのCPUとメモリーリソースを要求することができます。クレームは特定のサイズやアクセスモード(例えば、ReadWriteOnce、ReadOnlyMany、ReadWriteManyにマウントできます。詳しくはアクセスモード を参照してください)を要求することができます。
PersistentVolumeClaimはユーザーに抽象化されたストレージリソースの消費を許可する一方、ユーザーは色々な問題に対処するためにパフォーマンスといった様々なプロパティを持ったPersistentVolumeを必要とすることは一般的なことです。クラスター管理者はユーザーに様々なボリュームがどのように実装されているかを表に出すことなく、サイズやアクセスモードだけではない色々な点で異なった、様々なPersistentVolumeを提供できる必要があります。これらのニーズに応えるために StorageClass リソースがあります。
実例を含む詳細なチュートリアル を参照して下さい。
ボリュームと要求のライフサイクル
PVはクラスター内のリソースです。PVCはこれらのリソースの要求でありまた、クレームのチェックとしても機能します。PVとPVCの相互作用はこのライフサイクルに従います。
プロビジョニング
PVは静的か動的どちらかでプロビジョニングされます。
静的
クラスター管理者は多数のPVを作成します。それらはクラスターのユーザーが使うことのできる実際のストレージの詳細を保持します。それらはKubernetes APIに存在し、利用できます。
動的
ユーザーのPersistentVolumeClaimが管理者の作成したいずれの静的PVにも一致しない場合、クラスターはPVC用にボリュームを動的にプロビジョニングしようとする場合があります。
このプロビジョニングはStorageClassに基づいています。PVCはストレージクラス の要求が必要であり、管理者は動的プロビジョニングを行うためにストレージクラスの作成・設定が必要です。ストレージクラスを""にしたストレージ要求は、自身の動的プロビジョニングを事実上無効にします。
ストレージクラスに基づいたストレージの動的プロビジョニングを有効化するには、クラスター管理者がDefaultStorageClassアドミッションコントローラー をAPIサーバーで有効化する必要があります。
これは例えば、DefaultStorageClassがAPIサーバーコンポーネントの--enable-admission-pluginsフラグのコンマ区切りの順序付きリストの中に含まれているかで確認できます。
APIサーバーのコマンドラインフラグの詳細についてはkube-apiserver のドキュメントを参照してください。
バインディング
ユーザは、特定のサイズのストレージとアクセスモードを指定した上でPersistentVolumeClaimを作成します(動的プロビジョニングの場合は、すでに作られています)。マスター内のコントロールループは、新しく作られるPVCをウォッチして、それにマッチするPVが見つかったときに、それらを紐付けます。PVが新しいPVC用に動的プロビジョニングされた場合、コントロールループは常にPVをそのPVCに紐付けます。そうでない場合、ユーザーは常に少なくとも要求したサイズ以上のボリュームを取得しますが、ボリュームは要求されたサイズを超えている可能性があります。一度紐付けされると、どのように紐付けられたかに関係なくPersistentVolumeClaimの紐付けは排他的(決められた特定のPVとしか結びつかない状態)になります。PVCからPVへの紐付けは、PersistentVolumeとPersistentVolumeClaim間の双方向の紐付けであるClaimRefを使用した1対1のマッピングになっています。
一致するボリュームが存在しない場合、クレームはいつまでも紐付けされないままになります。一致するボリュームが利用可能になると、クレームがバインドされます。たとえば、50GiのPVがいくつもプロビジョニングされているクラスターだとしても、100Giを要求するPVCとは一致しません。100GiのPVがクラスターに追加されると、PVCを紐付けできます。
使用
Podは要求をボリュームとして使用します。クラスターは、要求を検査して紐付けられたボリュームを見つけそのボリュームをPodにマウントします。複数のアクセスモードをサポートするボリュームの場合、ユーザーはPodのボリュームとしてクレームを使う時にどのモードを希望するかを指定します。
ユーザーがクレームを取得し、そのクレームがバインドされると、バインドされたPVは必要な限りそのユーザーに属します。ユーザーはPodをスケジュールし、PodのvolumesブロックにpersistentVolumeClaimを含めることで、バインドされたクレームのPVにアクセスします。
書式の詳細はこちらを確認して下さい。
使用中のストレージオブジェクトの保護
使用中のストレージオブジェクト保護機能の目的はデータ損失を防ぐために、Podによって実際に使用されている永続ボリュームクレーム(PVC)と、PVCにバインドされている永続ボリューム(PV)がシステムから削除されないようにすることです。
備考: PVCを使用しているPodオブジェクトが存在する場合、PVCはPodによって実際に使用されています。
ユーザーがPodによって実際に使用されているPVCを削除しても、そのPVCはすぐには削除されません。PVCの削除は、PVCがPodで使用されなくなるまで延期されます。また、管理者がPVCに紐付けられているPVを削除しても、PVはすぐには削除されません。PVがPVCに紐付けられなくなるまで、PVの削除は延期されます。
PVCの削除が保護されているかは、PVCのステータスがTerminatingになっていて、そしてFinalizersのリストにkubernetes.io/pvc-protectionが含まれているかで確認できます。
kubectl describe pvc hostpath
Name: hostpath
Namespace: default
StorageClass: example-hostpath
Status: Terminating
Volume:
Labels: <none>
Annotations: volume.beta.kubernetes.io/storage-class= example-hostpath
volume.beta.kubernetes.io/storage-provisioner= example.com/hostpath
Finalizers: [ kubernetes.io/pvc-protection]
同様にPVの削除が保護されているかは、PVのステータスがTerminatingになっていて、そしてFinalizersのリストにkubernetes.io/pv-protectionが含まれているかで確認できます。
kubectl describe pv task-pv-volume
Name: task-pv-volume
Labels: type = local
Annotations: <none>
Finalizers: [ kubernetes.io/pv-protection]
StorageClass: standard
Status: Terminating
Claim:
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1Gi
Message:
Source:
Type: HostPath ( bare host directory volume)
Path: /tmp/data
HostPathType:
Events: <none>
再クレーム
ユーザーは、ボリュームの使用が完了したら、リソースの再クレームを許可するAPIからPVCオブジェクトを削除できます。PersistentVolumeの再クレームポリシーはそのクレームが解放された後のボリュームの処理をクラスターに指示します。現在、ボリュームは保持、リサイクル、または削除できます。
保持
Retainという再クレームポリシーはリソースを手動で再クレームすることができます。PersistentVolumeClaimが削除される時、PersistentVolumeは依然として存在はしますが、ボリュームは解放済みです。ただし、以前のクレームデータはボリューム上に残っているため、別のクレームにはまだ使用できません。管理者は次の手順でボリュームを手動で再クレームできます。
PersistentVolumeを削除します。PVが削除された後も、外部インフラストラクチャー(AWS EBS、GCE PD、Azure Disk、Cinderボリュームなど)に関連付けられたストレージアセットは依然として残ります。
ストレージアセットに関連するのデータを手動で適切にクリーンアップします。
関連するストレージアセットを手動で削除するか、同じストレージアセットを再利用したい場合、新しいストレージアセット定義と共にPersistentVolumeを作成します。
削除
Delete再クレームポリシーをサポートするボリュームプラグインの場合、削除するとPersistentVolumeオブジェクトがKubernetesから削除されるだけでなく、AWS EBS、GCE PD、Azure Disk、Cinderボリュームなどの外部インフラストラクチャーの関連ストレージアセットも削除されます。動的にプロビジョニングされたボリュームは、StorageClassの再クレームポリシー を継承します。これはデフォルトで削除です。管理者は、ユーザーの需要に応じてStorageClassを構成する必要があります。そうでない場合、PVは作成後に編集またはパッチを適用する必要があります。PersistentVolumeの再クレームポリシーの変更 を参照してください。
リサイクル
警告: Recycle再クレームポリシーは非推奨になりました。代わりに、動的プロビジョニングを使用することをおすすめします。
基盤となるボリュームプラグインでサポートされている場合、Recycle再クレームポリシーはボリュームに対して基本的な削除(rm -rf /thevolume/*)を実行し、新しいクレームに対して再び利用できるようにします。
管理者はreference で説明するように、Kubernetesコントローラーマネージャーのコマンドライン引数を使用して、カスタムリサイクラーPodテンプレートを構成できます。カスタムリサイクラーPodテンプレートには、次の例に示すように、volumes仕様が含まれている必要があります。
apiVersion : v1
kind : Pod
metadata :
name : pv-recycler
namespace : default
spec :
restartPolicy : Never
volumes :
- name : vol
hostPath :
path : /any/path/it/will/be/replaced
containers :
- name : pv-recycler
image : "registry.k8s.io/busybox"
command : ["/bin/sh" , "-c" , "test -e /scrub && rm -rf /scrub/..?* /scrub/.[!.]* /scrub/* && test -z \"$(ls -A /scrub)\" || exit 1" ]
volumeMounts :
- name : vol
mountPath : /scrub
ただし、カスタムリサイクラーPodテンプレートのvolumesパート内で指定された特定のパスは、リサイクルされるボリュームの特定のパスに置き換えられます。
永続ボリュームの予約
コントロールプレーンは、永続ボリュームクレームをクラスター内の一致する永続ボリュームにバインド できます。
ただし、永続ボリュームクレームを特定の永続ボリュームにバインドする場合、それらを事前にバインドする必要があります。
永続ボリュームクレームで永続ボリュームを指定することにより、その特定の永続ボリュームと永続ボリュームクレームの間のバインディングを宣言します。
永続ボリュームが存在し、そのclaimRefフィールドで永続ボリュームクレームを予約していない場合に永続ボリュームと永続ボリュームクレームがバインドされます。
バインディングは、ノードアフィニティを含むいくつかのボリュームの一致基準に関係なく発生します。
コントロールプレーンは、依然としてストレージクラス 、アクセスモード、および要求されたストレージサイズが有効であることをチェックします。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : foo-pvc
namespace : foo
spec :
storageClassName : "" # 空の文字列を明示的に指定する必要があります。そうしないとデフォルトのストレージクラスが設定されてしまいます。
volumeName : foo-pv
...
この方法は、永続ボリュームへのバインド特権を保証するものではありません。
他の永続ボリュームクレームが指定した永続ボリュームを使用できる場合、最初にそのストレージボリュームを予約する必要があります。
永続ボリュームのclaimRefフィールドに関連する永続ボリュームクレームを指定して、他の永続ボリュームクレームがその永続ボリュームにバインドできないようにしてください。
apiVersion : v1
kind : PersistentVolume
metadata :
name : foo-pv
spec :
storageClassName : ""
claimRef :
name : foo-pvc
namespace : foo
...
これは、既存の永続ボリュームを再利用する場合など、claimPolicyがRetainに設定されている永続ボリュームを使用する場合に役立ちます。
永続ボリュームクレームの拡大
FEATURE STATE: Kubernetes v1.24 [stable]
PersistentVolumeClaim(PVC)の拡大はデフォルトで有効です。次のボリュームの種類で拡大できます。
gcePersistentDisk
awsElasticBlockStore
Cinder
glusterfs
rbd
Azure File
Azure Disk
Portworx
FlexVolumes
CSI
そのストレージクラスのallowVolumeExpansionフィールドがtrueとなっている場合のみ、PVCを拡大できます。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : gluster-vol-default
provisioner : kubernetes.io/glusterfs
parameters :
resturl : "http://192.168.10.100:8080"
restuser : ""
secretNamespace : ""
secretName : ""
allowVolumeExpansion : true
PVCに対してさらに大きなボリュームを要求するには、PVCオブジェクトを編集してより大きなサイズを指定します。これによりPersistentVolumeを受け持つ基盤にボリュームの拡大がトリガーされます。クレームを満たすため新しくPersistentVolumeが作成されることはありません。代わりに既存のボリュームがリサイズされます。
CSIボリュームの拡張
FEATURE STATE: Kubernetes v1.24 [stable]
CSIボリュームの拡張のサポートはデフォルトで有効になっていますが、ボリューム拡張をサポートするにはボリューム拡張を利用できるCSIドライバーも必要です。詳細については、それぞれのCSIドライバーのドキュメントを参照してください。
ファイルシステムを含むボリュームのリサイズ
ファイルシステムがXFS、Ext3、またはExt4の場合にのみ、ファイルシステムを含むボリュームのサイズを変更できます。
ボリュームにファイルシステムが含まれる場合、新しいPodがPersistentVolumeClaimでReadWriteモードを使用している場合にのみ、ファイルシステムのサイズが変更されます。ファイルシステムの拡張は、Podの起動時、もしくはPodの実行時で基盤となるファイルシステムがオンラインの拡張をサポートする場合に行われます。
FlexVolumesでは、ドライバのRequiresFSResize機能がtrueに設定されている場合、サイズを変更できます。
FlexVolumeは、Podの再起動時にサイズ変更できます。
使用中の永続ボリュームクレームのリサイズ
FEATURE STATE: Kubernetes v1.15 [beta]
備考: 使用中のPVCの拡張は、Kubernetes 1.15以降のベータ版と、1.11以降のアルファ版として利用可能です。
ExpandInUsePersistentVolume機能を有効化する必要があります。これはベータ機能のため多くのクラスターで自動的に行われます。詳細については、
フィーチャーゲート のドキュメントを参照してください。
この場合、既存のPVCを使用しているPodまたはDeploymentを削除して再作成する必要はありません。使用中のPVCは、ファイルシステムが拡張されるとすぐにPodで自動的に使用可能になります。この機能は、PodまたはDeploymentで使用されていないPVCには影響しません。拡張を完了する前に、PVCを使用するPodを作成する必要があります。
他のボリュームタイプと同様、FlexVolumeボリュームは、Podによって使用されている最中でも拡張できます。
備考: FlexVolumeのリサイズは、基盤となるドライバーがリサイズをサポートしている場合のみ可能です。
備考: EBSの拡張は時間がかかる操作です。また変更は、ボリュームごとに6時間に1回までというクォータもあります。
ボリューム拡張時の障害からの復旧
基盤ストレージの拡張に失敗した際には、クラスターの管理者はPersistent Volume Claim (PVC)の状態を手動で復旧し、リサイズ要求をキャンセルします。それをしない限り、リサイズ要求は管理者の介入なしにコントローラーによって継続的に再試行されます。
PersistentVolumeClaim(PVC)にバインドされているPersistentVolume(PV)をRetain再クレームポリシーとしてマークします。
PVCを削除します。PVはRetain再クレームポリシーを持っているため、PVCを再び作成したときにいかなるデータも失うことはありません。
claimRefエントリーをPVスペックから削除して、新しいPVCがそれにバインドできるようにします。これによりPVはAvailableになります。PVより小さいサイズでPVCを再作成し、PVCのvolumeNameフィールドをPVの名前に設定します。これにより新しいPVCを既存のPVにバインドします。
PVを再クレームポリシーを復旧することを忘れずに行ってください。
永続ボリュームの種類
PersistentVolumeの種類はプラグインとして実装されます。Kubernetesは現在次のプラグインに対応しています。
awsElasticBlockStoreazureDiskazureFilecephfscinder非推奨 )csifcflexVolumeflockergcePersistentDiskglusterfshostPathlocalボリュームを利用することを検討してください。)iscsilocalnfsphotonPersistentDisk - Photon controller persistent disk
(対応するクラウドプロバイダーが削除されたため、このボリュームタイプは機能しなくなりました。)portworxVolumequobyterbdscaleIO非推奨 )storageosvsphereVolume
永続ボリューム
各PVには、仕様とボリュームのステータスが含まれているspecとstatusが含まれています。
PersistentVolumeオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
apiVersion : v1
kind : PersistentVolume
metadata :
name : pv0003
spec :
capacity :
storage : 5Gi
volumeMode : Filesystem
accessModes :
- ReadWriteOnce
persistentVolumeReclaimPolicy : Recycle
storageClassName : slow
mountOptions :
- hard
- nfsvers=4.1
nfs :
path : /tmp
server : 172.17.0.2
備考: クラスター内でPersistentVolumeを使用するには、ボリュームタイプに関連するヘルパープログラムが必要な場合があります。
この例では、PersistentVolumeはNFSタイプで、NFSファイルシステムのマウントをサポートするためにヘルパープログラム/sbin/mount.nfsが必要になります。
容量
通常、PVには特定のストレージ容量があります。これはPVのcapacity属性を使用して設定されます。容量によって期待される単位を理解するためには、Kubernetesのリソースモデル を参照してください。
現在、設定または要求できるのはストレージサイズのみです。将来の属性には、IOPS、スループットなどが含まれます。
ボリュームモード
FEATURE STATE: Kubernetes v1.18 [stable]
KubernetesはPersistentVolumesの2つのvolumeModesをサポートしています: FilesystemとBlockです。volumeModeは任意のAPIパラメーターです。FilesystemはvolumeModeパラメーターが省略されたときに使用されるデフォルトのモードです。
volumeMode: FilesystemであるボリュームはPodにマウント されてディレクトリになります。 ボリュームがブロックデバイスでデバイスが空の時、Kubernetesは初めてそれにマウントされる前にデバイスのファイルシステムを作成します。
volumeModeの値をBlockに設定してボリュームをRAWブロックデバイスとして使用します。volumeMode: Blockとともにボリュームを使用する例としては、Raw Block Volume Support を参照してください。
アクセスモード
PersistentVolumeは、リソースプロバイダーがサポートする方法でホストにマウントできます。次の表に示すように、プロバイダーにはさまざまな機能があり、各PVのアクセスモードは、その特定のボリュームでサポートされる特定のモードに設定されます。たとえば、NFSは複数の読み取り/書き込みクライアントをサポートできますが、特定のNFSのPVはサーバー上で読み取り専用としてエクスポートされる場合があります。各PVは、その特定のPVの機能を記述する独自のアクセスモードのセットを取得します。
アクセスモードは次の通りです。
ReadWriteOnceボリュームは単一のNodeで読み取り/書き込みとしてマウントできます
ReadOnlyManyボリュームは多数のNodeで読み取り専用としてマウントできます
ReadWriteManyボリュームは多数のNodeで読み取り/書き込みとしてマウントできます
ReadWriteOncePodボリュームは、単一のPodで読み取り/書き込みとしてマウントできます。クラスター全体で1つのPodのみがそのPVCの読み取りまたは書き込みを行えるようにする場合は、ReadWriteOncePodアクセスモードを使用します。これは、CSIボリュームとKubernetesバージョン1.22以降でのみサポートされます。
これについてはブログIntroducing Single Pod Access Mode for PersistentVolumes に詳細が記載されています。
CLIではアクセスモードは次のように略されます。
RWO - ReadWriteOnce
ROX - ReadOnlyMany
RWX - ReadWriteMany
Important! ボリュームは、多数のモードをサポートしていても、一度に1つのアクセスモードでしかマウントできません。たとえば、GCEPersistentDiskは、単一NodeではReadWriteOnceとして、または多数のNodeではReadOnlyManyとしてマウントできますが、同時にマウントすることはできません。
ボリュームプラグイン
ReadWriteOnce
ReadOnlyMany
ReadWriteMany
AWSElasticBlockStore
✓
-
-
AzureFile
✓
✓
✓
AzureDisk
✓
-
-
CephFS
✓
✓
✓
Cinder
✓
-
-
CSI
ドライバーに依存
ドライバーに依存
ドライバーに依存
FC
✓
✓
-
FlexVolume
✓
✓
ドライバーに依存
Flocker
✓
-
-
GCEPersistentDisk
✓
✓
-
Glusterfs
✓
✓
✓
HostPath
✓
-
-
iSCSI
✓
✓
-
Quobyte
✓
✓
✓
NFS
✓
✓
✓
RBD
✓
✓
-
VsphereVolume
✓
-
- (Podが連結されている場合のみ)
PortworxVolume
✓
-
✓
ScaleIO
✓
✓
-
StorageOS
✓
-
-
Class
PVはクラスを持つことができます。これはstorageClassName属性をストレージクラス の名前に設定することで指定されます。特定のクラスのPVは、そのクラスを要求するPVCにのみバインドできます。storageClassNameにクラスがないPVは、特定のクラスを要求しないPVCにのみバインドできます。
以前volume.beta.kubernetes.io/storage-classアノテーションは、storageClassName属性の代わりに使用されていました。このアノテーションはまだ機能しています。ただし、将来のKubernetesリリースでは完全に非推奨です。
再クレームポリシー
現在の再クレームポリシーは次のとおりです。
保持 -- 手動再クレーム
リサイクル -- 基本的な削除 (rm -rf /thevolume/*)
削除 -- AWS EBS、GCE PD、Azure Disk、もしくはOpenStack Cinderボリュームに関連するストレージアセットを削除
現在、NFSとHostPathのみがリサイクルをサポートしています。AWS EBS、GCE PD、Azure Disk、およびCinder volumeは削除をサポートしています。
マウントオプション
Kubernetes管理者は永続ボリュームがNodeにマウントされるときの追加マウントオプションを指定できます。
備考: すべての永続ボリュームタイプがすべてのマウントオプションをサポートするわけではありません。
次のボリュームタイプがマウントオプションをサポートしています。
AWSElasticBlockStore
AzureDisk
AzureFile
CephFS
Cinder (OpenStackブロックストレージ)
GCEPersistentDisk
Glusterfs
NFS
Quobyte Volumes
RBD (Ceph Block Device)
StorageOS
VsphereVolume
iSCSI
マウントオプションは検証されないため、不正だった場合マウントは失敗します。
以前volume.beta.kubernetes.io/mount-optionsアノテーションがmountOptions属性の代わりに使われていました。このアノテーションはまだ機能しています。ただし、将来のKubernetesリリースでは完全に非推奨です。
ノードアフィニティ
PVはノードアフィニティ を指定して、このボリュームにアクセスできるNodeを制限する制約を定義できます。PVを使用するPodは、ノードアフィニティによって選択されたNodeにのみスケジュールされます。
フェーズ
ボリュームは次のフェーズのいずれかです。
利用可能 -- まだクレームに紐付いていない自由なリソース
バウンド -- クレームに紐付いている
リリース済み -- クレームが削除されたが、クラスターにまだクレームされている
失敗 -- 自動再クレームに失敗
CLIにはPVに紐付いているPVCの名前が表示されます。
永続ボリューム要求
各PVCにはspecとステータスが含まれます。これは、仕様とクレームのステータスです。
PersistentVolumeClaimオブジェクトの名前は、有効な
DNSサブドメイン名 である必要があります。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : myclaim
spec :
accessModes :
- ReadWriteOnce
volumeMode : Filesystem
resources :
requests :
storage : 8Gi
storageClassName : slow
selector :
matchLabels :
release : "stable"
matchExpressions :
- {key: environment, operator: In, values : [dev]}
アクセスモード
クレームは、特定のアクセスモードでストレージを要求するときにボリュームと同じ規則を使用します。
ボリュームモード
クレームは、ボリュームと同じ規則を使用して、ファイルシステムまたはブロックデバイスとしてのボリュームの消費を示します。
リソース
Podと同様に、クレームは特定の量のリソースを要求できます。この場合、要求はストレージ用です。同じリソースモデル がボリュームとクレームの両方に適用されます。
セレクター
クレームでは、ラベルセレクター を指定して、ボリュームセットをさらにフィルター処理できます。ラベルがセレクターに一致するボリュームのみがクレームにバインドできます。セレクターは2つのフィールドで構成できます。
matchLabels - ボリュームはこの値のラベルが必要ですmatchExpressions - キー、値のリスト、およびキーと値を関連付ける演算子を指定することによって作成された要件のリスト。有効な演算子は、In、NotIn、ExistsおよびDoesNotExistです。
matchLabelsとmatchExpressionsの両方からのすべての要件はANDで結合されます。一致するには、すべてが一致する必要があります。
クラス
クレームは、storageClassName属性を使用してストレージクラス の名前を指定することにより、特定のクラスを要求できます。PVCにバインドできるのは、PVCと同じstorageClassNameを持つ、要求されたクラスのPVのみです。
PVCは必ずしもクラスをリクエストする必要はありません。storageClassNameが""に設定されているPVCは、クラスのないPVを要求していると常に解釈されるため、クラスのないPVにのみバインドできます(アノテーションがないか、""に等しい1つのセット)。storageClassNameのないPVCはまったく同じではなく、DefaultStorageClassアドミッションプラグイン
アドミッションプラグインがオンになっている場合、管理者はデフォルトのStorageClassを指定できます。storageClassNameを持たないすべてのPVCは、そのデフォルトのPVにのみバインドできます。デフォルトのStorageClassの指定は、StorageClassオブジェクトでstorageclass.kubernetes.io/is-default-classアノテーションをtrueに設定することにより行われます。管理者がデフォルトを指定しない場合、クラスターは、アドミッションプラグインがオフになっているかのようにPVC作成をレスポンスします。複数のデフォルトが指定されている場合、アドミッションプラグインはすべてのPVCの作成を禁止します。
アドミッションプラグインがオフになっている場合、デフォルトのStorageClassの概念はありません。storageClassNameを持たないすべてのPVCは、クラスを持たないPVにのみバインドできます。この場合、storageClassNameを持たないPVCは、storageClassNameが""に設定されているPVCと同じように扱われます。
インストール方法によっては、インストール時にアドオンマネージャーによってデフォルトのストレージクラスがKubernetesクラスターにデプロイされる場合があります。
PVCがselectorを要求することに加えてStorageClassを指定する場合、要件はANDで一緒に結合されます。要求されたクラスのPVと要求されたラベルのみがPVCにバインドされます。
備考: 現在、selectorが空ではないPVCは、PVを動的にプロビジョニングできません。
以前は、storageClassName属性の代わりにvolume.beta.kubernetes.io/storage-classアノテーションが使用されていました。このアノテーションはまだ機能しています。ただし、今後のKubernetesリリースではサポートされません。
ボリュームとしてのクレーム
Podは、クレームをボリュームとして使用してストレージにアクセスします。クレームは、そのクレームを使用するPodと同じ名前空間に存在する必要があります。クラスターは、Podの名前空間でクレームを見つけ、それを使用してクレームを支援しているPersistentVolumeを取得します。次に、ボリュームがホストとPodにマウントされます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : myfrontend
image : nginx
volumeMounts :
- mountPath : "/var/www/html"
name : mypd
volumes :
- name : mypd
persistentVolumeClaim :
claimName : myclaim
名前空間に関する注意
PersistentVolumeバインドは排他的であり、PersistentVolumeClaimは名前空間オブジェクトであるため、"多"モード(ROX、RWX)でクレームをマウントすることは1つの名前空間内でのみ可能です。
Rawブロックボリュームのサポート
FEATURE STATE: Kubernetes v1.18 [stable]
次のボリュームプラグインは、必要に応じて動的プロビジョニングを含むrawブロックボリュームをサポートします。
AWSElasticBlockStore
AzureDisk
CSI
FC (Fibre Channel)
GCEPersistentDisk
iSCSI
Local volume
OpenStack Cinder
RBD (Ceph Block Device)
VsphereVolume
Rawブロックボリュームを使用した永続ボリューム
apiVersion : v1
kind : PersistentVolume
metadata :
name : block-pv
spec :
capacity :
storage : 10Gi
accessModes :
- ReadWriteOnce
volumeMode : Block
persistentVolumeReclaimPolicy : Retain
fc :
targetWWNs : ["50060e801049cfd1" ]
lun : 0
readOnly : false
Rawブロックボリュームを要求する永続ボリュームクレーム
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : block-pvc
spec :
accessModes :
- ReadWriteOnce
volumeMode : Block
resources :
requests :
storage : 10Gi
コンテナにRawブロックデバイスパスを追加するPod仕様
apiVersion : v1
kind : Pod
metadata :
name : pod-with-block-volume
spec :
containers :
- name : fc-container
image : fedora:26
command : ["/bin/sh" , "-c" ]
args : [ "tail -f /dev/null" ]
volumeDevices :
- name : data
devicePath : /dev/xvda
volumes :
- name : data
persistentVolumeClaim :
claimName : block-pvc
備考: Podにrawブロックデバイスを追加する場合は、マウントパスの代わりにコンテナでデバイスパスを指定します。
ブロックボリュームのバインド
ユーザーがPersistentVolumeClaim specのvolumeModeフィールドを使用してrawブロックボリュームの要求を示す場合、バインディングルールは、このモードをspecの一部として考慮しなかった以前のリリースとわずかに異なります。表にリストされているのは、ユーザーと管理者がrawブロックデバイスを要求するために指定可能な組み合わせの表です。この表は、ボリュームがバインドされるか、組み合わせが与えられないかを示します。静的にプロビジョニングされたボリュームのボリュームバインディングマトリクスはこちらです。
PVボリュームモード
PVCボリュームモード
結果
未定義
未定義
バインド
未定義
ブロック
バインドなし
未定義
ファイルシステム
バインド
ブロック
未定義
バインドなし
ブロック
ブロック
バインド
ブロック
ファイルシステム
バインドなし
ファイルシステム
ファイルシステム
バインド
ファイルシステム
ブロック
バインドなし
ファイルシステム
未定義
バインド
備考: アルファリリースでは、静的にプロビジョニングされたボリュームのみがサポートされます。管理者は、rawブロックデバイスを使用する場合、これらの値を考慮するように注意する必要があります。
ボリュームのスナップショットとスナップショットからのボリュームの復元のサポート
FEATURE STATE: Kubernetes v1.17 [beta]
ボリュームスナップショット機能は、CSIボリュームプラグインのみをサポートするために追加されました。詳細については、ボリュームのスナップショット を参照してください。
ボリュームスナップショットのデータソースからボリュームを復元する機能を有効にするには、apiserverおよびcontroller-managerでVolumeSnapshotDataSourceフィーチャーゲートを有効にします。
ボリュームスナップショットから永続ボリュームクレームを作成する
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : restore-pvc
spec :
storageClassName : csi-hostpath-sc
dataSource :
name : new-snapshot-test
kind : VolumeSnapshot
apiGroup : snapshot.storage.k8s.io
accessModes :
- ReadWriteOnce
resources :
requests :
storage : 10Gi
ボリュームの複製
ボリュームの複製 はCSIボリュームプラグインにのみ利用可能です。
PVCデータソースからのボリューム複製機能を有効にするには、apiserverおよびcontroller-managerでVolumeSnapshotDataSourceフィーチャーゲートを有効にします。
既存のPVCからの永続ボリュームクレーム作成
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : cloned-pvc
spec :
storageClassName : my-csi-plugin
dataSource :
name : existing-src-pvc-name
kind : PersistentVolumeClaim
accessModes :
- ReadWriteOnce
resources :
requests :
storage : 10Gi
可搬性の高い設定の作成
もし幅広いクラスターで実行され、永続ボリュームが必要となる構成テンプレートやサンプルを作成している場合は、次のパターンを使用することをお勧めします。
構成にPersistentVolumeClaimオブジェクトを含める(DeploymentやConfigMapと共に)
ユーザーが設定をインスタンス化する際にPersistentVolumeを作成する権限がない場合があるため、設定にPersistentVolumeオブジェクトを含めない。
テンプレートをインスタンス化する時にストレージクラス名を指定する選択肢をユーザーに与える
ユーザーがストレージクラス名を指定する場合、persistentVolumeClaim.storageClassName フィールドにその値を入力する。これにより、クラスターが管理者によって有効にされたストレージクラスを持っている場合、PVCは正しいストレージクラスと一致する。
ユーザーがストレージクラス名を指定しない場合、persistentVolumeClaim.storageClassNameフィールドはnilのままにする。これにより、PVはユーザーにクラスターのデフォルトストレージクラスで自動的にプロビジョニングされる。多くのクラスター環境ではデフォルトのストレージクラスがインストールされているが、管理者は独自のデフォルトストレージクラスを作成することができる。
ツールがPVCを監視し、しばらくしてもバインドされないことをユーザーに表示する。これはクラスターが動的ストレージをサポートしない(この場合ユーザーは対応するPVを作成するべき)、もしくはクラスターがストレージシステムを持っていない(この場合ユーザーはPVCを必要とする設定をデプロイできない)可能性があることを示す。
次の項目
リファレンス
6.3 - 投影ボリューム
このドキュメントでは、Kubernetesの投影ボリューム について説明します。ボリューム に精通していることをお勧めします。
概要
ボリュームは、いくつかの既存の投影ボリュームソースを同じディレクトリにマップします。
現在、次のタイプのボリュームソースを投影できます。
すべてのソースは、Podと同じnamespaceにある必要があります。詳細はall-in-one volume デザインドキュメントを参照してください。
secret、downwardAPI、およびconfigMapを使用した構成例
apiVersion : v1
kind : Pod
metadata :
name : volume-test
spec :
containers :
- name : container-test
image : busybox
volumeMounts :
- name : all-in-one
mountPath : "/projected-volume"
readOnly : true
volumes :
- name : all-in-one
projected :
sources :
- secret :
name : mysecret
items :
- key : username
path : my-group/my-username
- downwardAPI :
items :
- path : "labels"
fieldRef :
fieldPath : metadata.labels
- path : "cpu_limit"
resourceFieldRef :
containerName : container-test
resource : limits.cpu
- configMap :
name : myconfigmap
items :
- key : config
path : my-group/my-config
構成例:デフォルト以外のアクセス許可モードが設定されたsecret
apiVersion : v1
kind : Pod
metadata :
name : volume-test
spec :
containers :
- name : container-test
image : busybox
volumeMounts :
- name : all-in-one
mountPath : "/projected-volume"
readOnly : true
volumes :
- name : all-in-one
projected :
sources :
- secret :
name : mysecret
items :
- key : username
path : my-group/my-username
- secret :
name : mysecret2
items :
- key : password
path : my-group/my-password
mode : 511
各投影ボリュームソースは、specのsourcesにリストされています。パラメーターは、2つの例外を除いてほぼ同じです。
secretについて、ConfigMapの命名と一致するようにsecretNameフィールドがnameに変更されました。
defaultModeはprojectedレベルでのみ指定でき、各ボリュームソースには指定できません。ただし上に示したように、個々の投影ごとにmodeを明示的に設定できます。
TokenRequestProjection機能が有効になっている場合、現在のサービスアカウントトークン を指定されたパスのPodに挿入できます。例えば:
apiVersion : v1
kind : Pod
metadata :
name : sa-token-test
spec :
containers :
- name : container-test
image : busybox
volumeMounts :
- name : token-vol
mountPath : "/service-account"
readOnly : true
serviceAccountName : default
volumes :
- name : token-vol
projected :
sources :
- serviceAccountToken :
audience : api
expirationSeconds : 3600
path : token
この例のPodには、挿入されたサービスアカウントトークンを含む投影ボリュームがあります。このトークンはPodのコンテナがKubernetes APIサーバーにアクセスするために使用できます。このaudienceフィールドにはトークンの受信対象者が含まれています。トークンの受信者は、トークンのaudienceフィールドで指定された識別子で自分自身であるかを識別します。そうでない場合はトークンを拒否します。このフィールドはオプションで、デフォルトではAPIサーバーの識別子が指定されます。
expirationSecondsはサービスアカウントトークンが有効であると予想される期間です。
デフォルトは1時間で、最低でも10分(600秒)でなければなりません。
管理者は、APIサーバーに--service-account-max-token-expirationオプションを指定することで、その最大値を制限することも可能です。
pathフィールドは、投影ボリュームのマウントポイントへの相対パスを指定します。
備考: 投影ボリュームソースを
subPathボリュームマウントとして使用しているコンテナは、それらのボリュームソースの更新を受信しません。
SecurityContextの相互作用
サービスアカウントの投影ボリューム拡張でのファイル権限処理の提案 により、正しい所有者権限が設定された投影ファイルが導入されました。
Linux
投影ボリュームがあり、PodのSecurityContextRunAsUserが設定されているLinux Podでは、投影されたファイルには、コンテナユーザーの所有権を含む正しい所有権が設定されます。
Windows
投影ボリュームを持ち、PodのSecurityContextでRunAsUsernameを設定したWindows Podでは、Windowsのユーザーアカウント管理方法により所有権が強制されません。
Windowsは、ローカルユーザーとグループアカウントをセキュリティアカウントマネージャー(SAM)と呼ばれるデータベースファイルに保存し、管理します。
各コンテナはSAMデータベースの独自のインスタンスを維持し、コンテナの実行中はホストはそのインスタンスを見ることができません。
Windowsコンテナは、OSのユーザーモード部分をホストから分離して実行するように設計されており、そのため仮想SAMデータベースを維持することになります。
そのため、ホスト上で動作するkubeletには、仮想化されたコンテナアカウントのホストファイル所有権を動的に設定する機能がありません。
ホストマシン上のファイルをコンテナと共有する場合は、C:\以外の独自のボリュームマウントに配置することをお勧めします。
デフォルトでは、投影ボリュームファイルの例に示されているように、投影されたファイルには次の所有権があります。
PS C:\> Get-Acl C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061 \ca.crt | Format-List
Path : Microsoft.PowerShell.Core\FileSystem::C:\var\run\secrets\kubernetes.io\serviceaccount\..2021_08_31_22_22_18.318230061 \ca.crt
Owner : BUILTIN\Administrators
Group : NT AUTHORITY\SYSTEM
Access : NT AUTHORITY\SYSTEM Allow FullControl
BUILTIN\Administrators Allow FullControl
BUILTIN\Users Allow ReadAndExecute, Synchronize
Audit :
Sddl : O:BAG: SYD: AI(A;ID;FA;;;SY)(A;ID;FA;;;BA)(A;ID;0x1200a9;;;BU)
これは、ContainerAdministratorのようなすべての管理者ユーザーが読み取り、書き込み、および実行アクセス権を持ち、非管理者ユーザーが読み取りおよび実行アクセス権を持つことを意味します。
備考: 一般に、コンテナにホストへのアクセスを許可することは、潜在的なセキュリティの悪用への扉を開く可能性があるため、お勧めできません。
Windows PodのSecurityContextにRunAsUserを指定して作成すると、PodはContainerCreatingで永久に固まります。したがって、Windows PodでLinux専用のRunAsUserオプションを使用しないことをお勧めします。
6.4 - エフェメラルボリューム
このドキュメントでは、Kubernetesのエフェメラルボリューム について説明します。ボリューム 、特にPersistentVolumeClaimとPersistentVolumeに精通していることをお勧めします。
一部のアプリケーションでは追加のストレージが必要ですが、そのデータが再起動後も永続的に保存されるかどうかは気にしません。
たとえば、キャッシュサービスは多くの場合メモリサイズによって制限されており、使用頻度の低いデータを、全体的なパフォーマンスにほとんど影響を与えずに、メモリよりも低速なストレージに移動できます。
他のアプリケーションは、構成データや秘密鍵など、読み取り専用の入力データがファイルに存在することを想定しています。
エフェメラルボリューム は、これらのユースケース向けに設計されています。
ボリュームはPodの存続期間に従い、Podとともに作成および削除されるため、Podは、永続ボリュームが利用可能な場所に制限されることなく停止および再起動できます。
エフェメラルボリュームはPod仕様でインライン で指定されているため、アプリケーションの展開と管理が簡素化されます。
エフェメラルボリュームのタイプ
Kubernetesは、さまざまな目的のためにいくつかの異なる種類のエフェメラルボリュームをサポートしています。
emptyDir、configMap、downwardAPI、secretはローカルエフェメラルストレージ として提供されます。
これらは、各ノードのkubeletによって管理されます。
CSIエフェメラルボリュームは、サードパーティーのCSIストレージドライバーによって提供される必要があります 。
汎用エフェメラルボリュームは、サードパーティーのCSIストレージドライバーによって提供される可能性があります が、動的プロビジョニングをサポートする他のストレージドライバーによって提供されることもあります。一部のCSIドライバーは、CSIエフェメラルボリューム用に特別に作成されており、動的プロビジョニングをサポートしていません。これらは汎用エフェメラルボリュームには使用できません。
サードパーティー製ドライバーを使用する利点は、Kubernetes自体がサポートしていない機能を提供できることです。たとえば、kubeletによって管理されるディスクとは異なるパフォーマンス特性を持つストレージや、異なるデータの挿入などです。
CSIエフェメラルボリューム
FEATURE STATE: Kubernetes v1.25 [stable]
備考: CSIエフェメラルボリュームは、CSIドライバーのサブセットによってのみサポートされます。
Kubernetes CSI
ドライバーリスト には、エフェメラルボリュームをサポートするドライバーが表示されます。
概念的には、CSIエフェメラルボリュームはconfigMap、downwardAPI、およびsecretボリュームタイプに似ています。
ストレージは各ノードでローカルに管理され、Podがノードにスケジュールされた後に他のローカルリソースと一緒に作成されます。Kubernetesには、この段階でPodを再スケジュールするという概念はもうありません。
ボリュームの作成は、失敗する可能性が低くなければなりません。さもないと、Podの起動が停止します。
特に、ストレージ容量を考慮したPodスケジューリング は、これらのボリュームではサポートされていません 。
これらは現在、Podのストレージリソースの使用制限の対象外です。これは、kubeletが管理するストレージに対してのみ強制できるものであるためです。
CSIエフェメラルストレージを使用するPodのマニフェストの例を次に示します。
kind : Pod
apiVersion : v1
metadata :
name : my-csi-app
spec :
containers :
- name : my-frontend
image : busybox:1.28
volumeMounts :
- mountPath : "/data"
name : my-csi-inline-vol
command : [ "sleep" , "1000000" ]
volumes :
- name : my-csi-inline-vol
csi :
driver : inline.storage.kubernetes.io
volumeAttributes :
foo : bar
volumeAttributesは、ドライバーによって準備されるボリュームを決定します。これらの属性は各ドライバーに固有のものであり、標準化されていません。詳細な手順については、各CSIドライバーのドキュメントを参照してください。
CSIドライバーの制限事項
CSIエフェメラルボリュームを使用すると、ユーザーはPod仕様の一部としてvolumeAttributesをCSIドライバーに直接提供できます。
通常は管理者に制限されているvolumeAttributesを許可するCSIドライバーは、インラインエフェメラルボリュームでの使用には適していません。
たとえば、通常StorageClassで定義されるパラメーターは、インラインエフェメラルボリュームを使用してユーザーに公開しないでください。
Pod仕様内でインラインボリュームとして使用できるCSIドライバーを制限する必要があるクラスター管理者は、次の方法で行うことができます。
CSIドライバー仕様のvolumeLifecycleModesからEphemeralを削除します。これにより、ドライバーをインラインエフェメラルボリュームとして使用できなくなります。
admission webhook を使用して、このドライバーの使用方法を制限します。
汎用エフェメラルボリューム
FEATURE STATE: Kubernetes v1.23 [stable]
汎用エフェメラルボリュームは、プロビジョニング後に通常は空であるスクラッチデータ用のPodごとのディレクトリを提供するという意味で、emptyDirボリュームに似ています。ただし、追加の機能がある場合もあります。
ストレージは、ローカルまたはネットワークに接続できます。
ボリュームは、Podが超えることができない固定サイズを持つことができます。
ボリュームには、ドライバーとパラメーターによっては、いくつかの初期データがある場合があります。
スナップショット 、クローン作成 、サイズ変更 、ストレージ容量の追跡 などボリュームに対する一般的な操作は、ドライバーがそれらをサポートしていることを前提としてサポートされています。
例:
kind : Pod
apiVersion : v1
metadata :
name : my-app
spec :
containers :
- name : my-frontend
image : busybox:1.28
volumeMounts :
- mountPath : "/scratch"
name : scratch-volume
command : [ "sleep" , "1000000" ]
volumes :
- name : scratch-volume
ephemeral :
volumeClaimTemplate :
metadata :
labels :
type : my-frontend-volume
spec :
accessModes : [ "ReadWriteOnce" ]
storageClassName : "scratch-storage-class"
resources :
requests :
storage : 1Gi
LifecycleとPersistentVolumeClaim
設計上の重要なアイデアは、ボリュームクレームのパラメーター がPodのボリュームソース内で許可されることです。
PersistentVolumeClaimのラベル、アノテーション、および一連のフィールド全体がサポートされています。
そのようなPodが作成されると、エフェメラルボリュームコントローラーは、Podと同じ名前空間に実際のPersistentVolumeClaimオブジェクトを作成し、Podが削除されたときにPersistentVolumeClaimが確実に削除されるようにします。
これにより、ボリュームバインディングおよび/またはプロビジョニングがトリガーされます。
これは、StorageClass が即時ボリュームバインディングを使用する場合、またはPodが一時的にノードにスケジュールされている場合(WaitForFirstConsumerボリュームバインディングモード)のいずれかです。
後者は、スケジューラーがPodに適したノードを自由に選択できるため、一般的なエフェメラルボリュームに推奨されます。即時バインディングでは、ボリュームが利用可能になった時点で、ボリュームにアクセスできるノードをスケジューラーが選択する必要があります。
リソースの所有権 に関して、一般的なエフェメラルストレージを持つPodは、そのエフェメラルストレージを提供するPersistentVolumeClaimの所有者です。Podが削除されると、KubernetesガベージコレクターがPVCを削除します。これにより、通常、ボリュームの削除がトリガーされます。これは、ストレージクラスのデフォルトの再利用ポリシーがボリュームを削除することであるためです。retainの再利用ポリシーを持つStorageClassを使用して、準エフェメラルなローカルストレージを作成できます。ストレージはPodよりも長く存続します。この場合、ボリュームのクリーンアップが個別に行われるようにする必要があります。
これらのPVCは存在しますが、他のPVCと同様に使用できます。特に、ボリュームのクローン作成またはスナップショットでデータソースとして参照できます。PVCオブジェクトは、ボリュームの現在のステータスも保持します。
PersistentVolumeClaimの命名
自動的に作成されたPVCの命名は決定論的です。名前はPod名とボリューム名を組み合わせたもので、途中にハイフン(-)があります。上記の例では、PVC名はmy-app-scratch-volumeになります。この決定論的な命名により、Pod名とボリューム名が分かればPVCを検索する必要がないため、PVCとの対話が容易になります。
また、決定論的な命名では、異なるPod間、およびPodと手動で作成されたPVCの間で競合が発生する可能性があります(ボリュームが"scratch"のPod"pod-a"と、名前が"pod"でボリュームが"a-scratch"の別のPodは、どちらも同じPVC名"pod-a-scratch")。
次のような競合が検出されます。Pod用に作成された場合、PVCはエフェメラルボリュームにのみ使用されます。このチェックは、所有関係に基づいています。既存のPVCは上書きまたは変更されません。ただし、適切なPVCがないとPodを起動できないため、これでは競合が解決されません。
注意: これらの競合が発生しないように、同じ名前空間内でPodとボリュームに名前を付けるときは注意してください。
セキュリティ
GenericEphemeralVolume機能を有効にすると、ユーザーは、PVCを直接作成する権限がなくても、Podを作成できる場合、間接的にPVCを作成できます。クラスター管理者はこれを認識している必要があります。これがセキュリティモデルに適合しない場合は、一般的なエフェメラルボリュームを持つPodなどのオブジェクトを拒否するadmission webhook を使用する必要があります。
通常のPVCの名前空間割り当て は引き続き適用されるため、ユーザーがこの新しいメカニズムの使用を許可されたとしても、他のポリシーを回避するために使用することはできません。
次の項目
kubeletによって管理されるエフェメラルボリューム
ローカルエフェメラルボリューム を参照してください。
CSIエフェメラルボリューム
汎用エフェメラルボリューム
6.5 - ストレージクラス
このドキュメントでは、KubernetesにおけるStorageClassの概念について説明します。ボリューム と永続ボリューム に精通していることをお勧めします。
概要
StorageClassは、管理者が提供するストレージの「クラス」を記述する方法を提供します。さまざまなクラスが、サービス品質レベル、バックアップポリシー、またはクラスター管理者によって決定された任意のポリシーにマップされる場合があります。Kubernetes自体は、クラスが何を表すかについて意見を持っていません。この概念は、他のストレージシステムでは「プロファイル」と呼ばれることがあります。
StorageClassリソース
各StorageClassには、クラスに属するPersistentVolumeを動的にプロビジョニングする必要がある場合に使用されるフィールドprovisioner、parameters、およびreclaimPolicyが含まれています。
StorageClassオブジェクトの名前は重要であり、ユーザーが特定のクラスを要求する方法です。管理者は、最初にStorageClassオブジェクトを作成するときにクラスの名前とその他のパラメーターを設定します。オブジェクトは、作成後に更新することはできません。
管理者は、バインドする特定のクラスを要求しないPVCに対してのみ、デフォルトのStorageClassを指定できます。詳細については、PersistentVolumeClaimセクション を参照してください。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : standard
provisioner : kubernetes.io/aws-ebs
parameters :
type : gp2
reclaimPolicy : Retain
allowVolumeExpansion : true
mountOptions :
- debug
volumeBindingMode : Immediate
プロビジョナー
各StorageClassには、PVのプロビジョニングに使用するボリュームプラグインを決定するプロビジョナーがあります。このフィールドを指定する必要があります。
ここにリストされている「内部」プロビジョナー(名前には「kubernetes.io」というプレフィックスが付いており、Kubernetesと共に出荷されます)を指定することに制限はありません。Kubernetesによって定義された仕様 に従う独立したプログラムである外部プロビジョナーを実行して指定することもできます。外部プロビジョナーの作成者は、コードの保存場所、プロビジョナーの出荷方法、実行方法、使用するボリュームプラグイン(Flexを含む)などについて完全な裁量権を持っています。リポジトリkubernetes-sigs/sig-storage-lib-external-provisioner には、仕様の大部分を実装する外部プロビジョナーを作成するためのライブラリが含まれています。一部の外部プロビジョナーは、リポジトリkubernetes-sigs/sig-storage-lib-external-provisioner の下にリストされています。
たとえば、NFSは内部プロビジョナーを提供しませんが、外部プロビジョナーを使用できます。サードパーティのストレージベンダーが独自の外部プロビジョナーを提供する場合もあります。
再利用ポリシー
StorageClassによって動的に作成されるPersistentVolumeには、クラスのreclaimPolicyフィールドで指定された再利用ポリシーがあり、DeleteまたはRetainのいずれかになります。StorageClassオブジェクトの作成時にreclaimPolicyが指定されていない場合、デフォルトでDeleteになります。
手動で作成され、StorageClassを介して管理されるPersistentVolumeには、作成時に割り当てられた再利用ポリシーが適用されます。
ボリューム拡張の許可
FEATURE STATE: Kubernetes v1.11 [beta]
PersistentVolumeは、拡張可能になるように構成できます。この機能をtrueに設定すると、ユーザーは対応するPVCオブジェクトを編集してボリュームのサイズを変更できます。
次のタイプのボリュームは、基になるStorageClassのフィールドallowVolumeExpansionがtrueに設定されている場合に、ボリュームの拡張をサポートします。
Table of Volume types and the version of Kubernetes they require
Volume type
Required Kubernetes version
gcePersistentDisk
1.11
awsElasticBlockStore
1.11
Cinder
1.11
glusterfs
1.11
rbd
1.11
Azure File
1.11
Azure Disk
1.11
Portworx
1.11
FlexVolume
1.13
CSI
1.14 (alpha), 1.16 (beta)
備考: ボリューム拡張機能を使用してボリュームを拡張することはできますが、縮小することはできません。
マウントオプション
StorageClassによって動的に作成されるPersistentVolumeには、クラスのmountOptionsフィールドで指定されたマウントオプションがあります。
ボリュームプラグインがマウントオプションをサポートしていないにもかかわらず、マウントオプションが指定されている場合、プロビジョニングは失敗します。マウントオプションは、クラスまたはPVのいずれでも検証されません。マウントオプションが無効な場合、PVマウントは失敗します。
ボリュームバインディングモード
volumeBindingModeフィールドは、ボリュームバインディングと動的プロビジョニング が発生するタイミングを制御します。設定を解除すると、デフォルトで"Immediate"モードが使用されます。
Immediateモードは、PersistentVolumeClaimが作成されると、ボリュームバインディングと動的プロビジョニングが発生することを示します。トポロジに制約があり、クラスター内のすべてのノードからグローバルにアクセスできないストレージバックエンドの場合、PersistentVolumeはPodのスケジューリング要件を知らなくてもバインドまたはプロビジョニングされます。これにより、Podがスケジュール不能になる可能性があります。
クラスター管理者は、PersistentVolumeClaimを使用するPodが作成されるまでPersistentVolumeのバインドとプロビジョニングを遅らせるWaitForFirstConsumerモードを指定することで、この問題に対処できます。
PersistentVolumeは、Podのスケジュール制約によって指定されたトポロジに準拠して選択またはプロビジョニングされます。これらには、リソース要件 、ノードセレクター 、ポッドアフィニティとアンチアフィニティ 、およびtaints and tolerations が含まれますが、これらに限定されません。
次のプラグインは、動的プロビジョニングでWaitForFirstConsumerをサポートしています。
次のプラグインは、事前に作成されたPersistentVolumeバインディングでWaitForFirstConsumerをサポートします。
FEATURE STATE: Kubernetes v1.17 [stable]
CSIボリューム も動的プロビジョニングと事前作成されたPVでサポートされていますが、サポートされているトポロジーキーと例を確認するには、特定のCSIドライバーのドキュメントを参照する必要があります。
備考: WaitForFirstConsumerの使用を選択した場合は、Pod仕様でnodeNameを使用してノードアフィニティを指定しないでください。この場合にnodeNameを使用すると、スケジューラはバイパスされ、PVCは保留状態のままになります。
代わりに、以下に示すように、この場合はホスト名にノードセレクターを使用できます。
apiVersion : v1
kind : Pod
metadata :
name : task-pv-pod
spec :
nodeSelector :
kubernetes.io/hostname : kube-01
volumes :
- name : task-pv-storage
persistentVolumeClaim :
claimName : task-pv-claim
containers :
- name : task-pv-container
image : nginx
ports :
- containerPort : 80
name : "http-server"
volumeMounts :
- mountPath : "/usr/share/nginx/html"
name : task-pv-storage
許可されたトポロジー
クラスターオペレーターがWaitForFirstConsumerボリュームバインディングモードを指定すると、ほとんどの状況でプロビジョニングを特定のトポロジに制限する必要がなくなります。ただし、それでも必要な場合は、allowedTopologiesを指定できます。
この例は、プロビジョニングされたボリュームのトポロジを特定のゾーンに制限する方法を示しており、サポートされているプラグインのzoneおよびzonesパラメーターの代わりとして使用する必要があります。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : standard
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-standard
volumeBindingMode : WaitForFirstConsumer
allowedTopologies :
matchLabelExpressions :
- key : failure-domain.beta.kubernetes.io/zone
values :
- us-central-1a
- us-central-1b
パラメーター
ストレージクラスには、ストレージクラスに属するボリュームを記述するパラメーターがあります。プロビジョナーに応じて、異なるパラメーターが受け入れられる場合があります。たとえば、パラメーターtypeの値io1とパラメーターiopsPerGBはEBSに固有です。パラメーターを省略すると、デフォルトが使用されます。
StorageClassに定義できるパラメーターは最大512個です。
キーと値を含むパラメーターオブジェクトの合計の長さは、256KiBを超えることはできません。
AWS EBS
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/aws-ebs
parameters :
type : io1
iopsPerGB : "10"
fsType : ext4
type:io1、gp2、sc1、st1。詳細については、AWSドキュメント を参照してください。デフォルト:gp2。zone(非推奨):AWS zone。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。zones(非推奨):AWS zoneのコンマ区切りリスト。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。iopsPerGB:io1ボリュームのみ。GiBごとの1秒あたりのI/O操作。AWSボリュームプラグインは、これを要求されたボリュームのサイズで乗算して、ボリュームのIOPSを計算し、上限を20,000IOPSに設定します(AWSでサポートされる最大値については、AWSドキュメント を参照してください)。ここでは文字列が必要です。つまり、10ではなく"10"です。fsType:kubernetesでサポートされているfsType。デフォルト:"ext4"。encrypted:EBSボリュームを暗号化するかどうかを示します。有効な値は"true"または"false"です。ここでは文字列が必要です。つまり、trueではなく"true"です。kmsKeyId:オプション。ボリュームを暗号化するときに使用するキーの完全なAmazonリソースネーム。何も指定されていなくてもencryptedがtrueの場合、AWSによってキーが生成されます。有効なARN値については、AWSドキュメントを参照してください。
GCE PD
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-standard
fstype : ext4
replication-type : none
type:pd-standardまたはpd-ssd。デフォルト:pd-standardzone(非推奨):GCE zone。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。zones(非推奨):GCE zoneのコンマ区切りリスト。zoneもzonesも指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。zoneパラメーターとzonesパラメーターを同時に使用することはできません。fstype:ext4またはxfs。デフォルト:ext4。定義されたファイルシステムタイプは、ホストオペレーティングシステムでサポートされている必要があります。replication-type:noneまたはregional-pd。デフォルト:none。
replication-typeがnoneに設定されている場合、通常の(ゾーン)PDがプロビジョニングされます。
replication-typeがregional-pdに設定されている場合、Regional Persistent Disk がプロビジョニングされます。volumeBindingMode: WaitForFirstConsumerを設定することを強くお勧めします。この場合、このStorageClassを使用するPersistentVolumeClaimを使用するPodを作成すると、Regional Persistent Diskが2つのゾーンでプロビジョニングされます。1つのゾーンは、Podがスケジュールされているゾーンと同じです。もう1つのゾーンは、クラスターで使用可能なゾーンからランダムに選択されます。ディスクゾーンは、allowedTopologiesを使用してさらに制限できます。
Glusterfs(非推奨)
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/glusterfs
parameters :
resturl : "http://127.0.0.1:8081"
clusterid : "630372ccdc720a92c681fb928f27b53f"
restauthenabled : "true"
restuser : "admin"
secretNamespace : "default"
secretName : "heketi-secret"
gidMin : "40000"
gidMax : "50000"
volumetype : "replicate:3"
resturl:glusterボリュームをオンデマンドでプロビジョニングするGluster RESTサービス/HeketiサービスのURL。一般的な形式はIPaddress:Portである必要があり、これはGlusterFS動的プロビジョナーの必須パラメーターです。Heketiサービスがopenshift/kubernetesセットアップでルーティング可能なサービスとして公開されている場合、これはhttp://heketi-storage-project.cloudapps.mystorage.comのような形式になる可能性があります。ここで、fqdnは解決可能なHeketiサービスURLです。
restauthenabled:RESTサーバーへの認証を有効にするGluster RESTサービス認証ブール値。この値が"true"の場合、restuserとrestuserkeyまたはsecretNamespace+secretNameを入力する必要があります。このオプションは非推奨です。restuser、restuserkey、secretName、またはsecretNamespaceのいずれかが指定されている場合、認証が有効になります。
restuser:Gluster Trusted Poolでボリュームを作成するためのアクセス権を持つGluster RESTサービス/Heketiユーザー。
restuserkey:RESTサーバーへの認証に使用されるGluster RESTサービス/Heketiユーザーのパスワード。このパラメーターは、secretNamespace+secretNameを優先されて廃止されました。
secretNamespace、secretName:Gluster RESTサービスと通信するときに使用するユーザーパスワードを含むSecretインスタンスの識別。これらのパラメーターはオプションです。secretNamespaceとsecretNameの両方が省略された場合、空のパスワードが使用されます。提供されたシークレットには、タイプkubernetes.io/glusterfsが必要です。たとえば、次のように作成されます。
kubectl create secret generic heketi-secret \
--type="kubernetes.io/glusterfs" --from-literal=key='opensesame' \
--namespace=default
シークレットの例はglusterfs-provisioning-secret.yaml にあります。
clusterid:630372ccdc720a92c681fb928f27b53fは、ボリュームのプロビジョニング時にHeketiによって使用されるクラスターのIDです。また、クラスターIDのリストにすることもできます。これはオプションのパラメーターです。
gidMin、gidMax:StorageClassのGID範囲の最小値と最大値。この範囲内の一意の値(GID)(gidMin-gidMax)が、動的にプロビジョニングされたボリュームに使用されます。これらはオプションの値です。指定しない場合、ボリュームは、それぞれgidMinとgidMaxのデフォルトである2000から2147483647の間の値でプロビジョニングされます。
volumetype:ボリュームタイプとそのパラメーターは、このオプションの値で構成できます。ボリュームタイプが記載されていない場合、プロビジョニング担当者がボリュームタイプを決定します。
例えば、
レプリカボリューム:volumetype: replica:3ここで、'3'はレプリカ数です。
Disperse/ECボリューム:volumetype: disperse:4:2ここで、'4'はデータ、'2'は冗長数です。
ボリュームの分配:volumetype: none
利用可能なボリュームタイプと管理オプションについては、管理ガイド を参照してください。
詳細な参考情報については、Heketiの設定方法 を参照してください。
永続ボリュームが動的にプロビジョニングされると、Glusterプラグインはエンドポイントとヘッドレスサービスをgluster-dynamic-<claimname>という名前で自動的に作成します。永続ボリューム要求が削除されると、動的エンドポイントとサービスは自動的に削除されます。
NFS
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : example-nfs
provisioner : example.com/external-nfs
parameters :
server : nfs-server.example.com
path : /share
readOnly : "false"
server:サーバーは、NFSサーバーのホスト名またはIPアドレスです。path:NFSサーバーによってエクスポートされるパス。readOnly:ストレージが読み取り専用としてマウントされるかどうかを示すフラグ(デフォルトはfalse)。
Kubernetesには、内部NFSプロビジョナーは含まれていません。NFS用のStorageClassを作成するには、外部プロビジョナーを使用する必要があります。
ここではいくつかの例を示します。
OpenStack Cinder
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : gold
provisioner : kubernetes.io/cinder
parameters :
availability : nova
availability:アベイラビリティゾーン。指定されていない場合、ボリュームは通常、Kubernetesクラスターにノードがあるすべてのアクティブなゾーンにわたってラウンドロビン方式で処理されます。
vSphere
vSphereストレージクラスのプロビジョナーには2つのタイプがあります。
インツリープロビジョナーは非推奨です 。CSIプロビジョナーの詳細については、Kubernetes vSphere CSIドライバー およびvSphereVolume CSI移行 を参照してください。
CSIプロビジョナー
vSphere CSI StorageClassプロビジョナーは、Tanzu Kubernetesクラスターと連携します。例については、vSphere CSIリポジトリ を参照してください。
vCPプロビジョナー
次の例では、VMware Cloud Provider(vCP) StorageClassプロビジョナーを使用しています。
ユーザー指定のディスク形式でStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/vsphere-volume
parameters :
diskformat : zeroedthick
diskformat:thin、zeroedthick、eagerzeroedthick。デフォルト:"thin".
ユーザー指定のデータストアにディスクフォーマットのStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/vsphere-volume
parameters :
diskformat : zeroedthick
datastore : VSANDatastore
datastore:ユーザーはStorageClassでデータストアを指定することもできます。
ボリュームは、StorageClassで指定されたデータストア(この場合はVSANDatastore)に作成されます。このフィールドはオプションです。データストアが指定されていない場合、vSphere Cloud Providerの初期化に使用されるvSphere構成ファイルで指定されたデータストアにボリュームが作成されます。
kubernetes内のストレージポリシー管理
既存のvCenter SPBMポリシーを使用
vSphere for Storage Managementの最も重要な機能の1つは、ポリシーベースの管理です。Storage Policy Based Management(SPBM)は、幅広いデータサービスとストレージソリューションにわたって単一の統合コントロールプレーンを提供するストレージポリシーフレームワークです。SPBMにより、vSphere管理者は、キャパシティプランニング、差別化されたサービスレベル、キャパシティヘッドルームの管理など、事前のストレージプロビジョニングの課題を克服できます。SPBMポリシーは、storagePolicyNameパラメーターを使用してStorageClassで指定できます。
Kubernetes内でのVirtual SANポリシーのサポート
Vsphere Infrastructure(VI)管理者は、動的ボリュームプロビジョニング中にカスタムVirtual SANストレージ機能を指定できます。動的なボリュームプロビジョニング時に、パフォーマンスや可用性などのストレージ要件をストレージ機能の形で定義できるようになりました。ストレージ機能の要件はVirtual SANポリシーに変換され、永続ボリューム(仮想ディスク)の作成時にVirtual SANレイヤーにプッシュダウンされます。仮想ディスクは、要件を満たすためにVirtual SANデータストア全体に分散されます。
永続的なボリューム管理にストレージポリシーを使用する方法の詳細については、ボリュームの動的プロビジョニングのためのストレージポリシーベースの管理 を参照してください。
vSphereの例 では、Kubernetes for vSphere内で永続的なボリューム管理を試すことができます。
Ceph RBD
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/rbd
parameters :
monitors : 10.16.153.105 :6789
adminId : kube
adminSecretName : ceph-secret
adminSecretNamespace : kube-system
pool : kube
userId : kube
userSecretName : ceph-secret-user
userSecretNamespace : default
fsType : ext4
imageFormat : "2"
imageFeatures : "layering"
monitors:カンマ区切りのCephモニター。このパラメーターは必須です。
adminId:プールにイメージを作成できるCephクライアントID。デフォルトは"admin"です。
adminSecretName:adminIdのシークレット名。このパラメーターは必須です。指定されたシークレットのタイプは"kubernetes.io/rbd"である必要があります。
adminSecretNamespace:adminSecretNameの名前空間。デフォルトは"default"です。
pool:Ceph RBDプール。デフォルトは"rbd"です。
userId:RBDイメージのマッピングに使用されるCephクライアントID。デフォルトはadminIdと同じです。
userSecretName:RBDイメージをマップするためのuserIdのCephシークレットの名前。PVCと同じ名前空間に存在する必要があります。このパラメーターは必須です。提供されたシークレットのタイプは"kubernetes.io/rbd"である必要があります。たとえば、次のように作成されます。
kubectl create secret generic ceph-secret --type= "kubernetes.io/rbd" \
= key = 'QVFEQ1pMdFhPUnQrSmhBQUFYaERWNHJsZ3BsMmNjcDR6RFZST0E9PQ==' \
= kube-system
userSecretNamespace:userSecretNameの名前空間。
fsType:kubernetesでサポートされているfsType。デフォルト:"ext4"。
imageFormat:Ceph RBDイメージ形式、"1"または"2"。デフォルトは"2"です。
imageFeatures:このパラメーターはオプションであり、imageFormatを"2"に設定した場合にのみ使用する必要があります。現在サポートされている機能はlayeringのみです。デフォルトは""で、オンになっている機能はありません。
Azure Disk
Azure Unmanaged Disk storage class
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/azure-disk
parameters :
skuName : Standard_LRS
location : eastus
storageAccount : azure_storage_account_name
skuName:AzureストレージアカウントのSku層。デフォルトは空です。location:Azureストレージアカウントの場所。デフォルトは空です。storageAccount:Azureストレージアカウント名。ストレージアカウントを指定する場合、それはクラスターと同じリソースグループに存在する必要があり、locationは無視されます。ストレージアカウントが指定されていない場合、クラスターと同じリソースグループに新しいストレージアカウントが作成されます。
Azure Disk storage class (starting from v1.7.2)
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/azure-disk
parameters :
storageaccounttype : Standard_LRS
kind : managed
storageaccounttype:AzureストレージアカウントのSku層。デフォルトは空です。kind:可能な値は、shared、dedicated、およびmanaged(デフォルト)です。kindがsharedの場合、すべてのアンマネージドディスクは、クラスターと同じリソースグループ内のいくつかの共有ストレージアカウントに作成されます。kindがdedicatedの場合、新しい専用ストレージアカウントが、クラスターと同じリソースグループ内の新しいアンマネージドディスク用に作成されます。kindがmanagedの場合、すべてのマネージドディスクはクラスターと同じリソースグループに作成されます。resourceGroup:Azureディスクが作成されるリソースグループを指定します。これは、既存のリソースグループ名である必要があります。指定しない場合、ディスクは現在のKubernetesクラスターと同じリソースグループに配置されます。
Premium VMはStandard_LRSディスクとPremium_LRSディスクの両方を接続できますが、Standard VMはStandard_LRSディスクのみを接続できます。
マネージドVMはマネージドディスクのみをアタッチでき、アンマネージドVMはアンマネージドディスクのみをアタッチできます。
Azure File
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : azurefile
provisioner : kubernetes.io/azure-file
parameters :
skuName : Standard_LRS
location : eastus
storageAccount : azure_storage_account_name
skuName:AzureストレージアカウントのSku層。デフォルトは空です。location:Azureストレージアカウントの場所。デフォルトは空です。storageAccount:Azureストレージアカウント名。デフォルトは空です。ストレージアカウントが指定されていない場合は、リソースグループに関連付けられているすべてのストレージアカウントが検索され、skuNameとlocationに一致するものが見つかります。ストレージアカウントを指定する場合は、クラスターと同じリソースグループに存在する必要があり、skuNameとlocationは無視されます。secretNamespace:Azureストレージアカウント名とキーを含むシークレットの名前空間。デフォルトはPodと同じです。secretName:Azureストレージアカウント名とキーを含むシークレットの名前。デフォルトはazure-storage-account-<accountName>-secretですreadOnly:ストレージが読み取り専用としてマウントされるかどうかを示すフラグ。デフォルトはfalseで、読み取り/書き込みマウントを意味します。この設定は、VolumeMountsのReadOnly設定にも影響します。
ストレージのプロビジョニング中に、secretNameという名前のシークレットがマウント資格証明用に作成されます。クラスターでRBAC とController Roles の両方が有効になっている場合は、追加します。clusterrolesystem:controller:persistent-volume-binderに対するリソースsecretのcreateパーミッション。
マルチテナンシーコンテキストでは、secretNamespaceの値を明示的に設定することを強くお勧めします。そうしないと、ストレージアカウントの資格情報が他のユーザーに読み取られる可能性があります。
Portworx Volume
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : portworx-io-priority-high
provisioner : kubernetes.io/portworx-volume
parameters :
repl : "1"
snap_interval : "70"
priority_io : "high"
fs:配置するファイルシステム:none/xfs/ext4(デフォルト:ext4)。block_size:キロバイト単位のブロックサイズ(デフォルト:32)。repl:レプリケーション係数1..3の形式で提供される同期レプリカの数(デフォルト:1)。ここでは文字列が期待されます。つまり、1ではなく"1"です。priority_io:ボリュームがパフォーマンスの高いストレージから作成されるか、優先度の低いストレージhigh/medium/low(デフォルト:low)から作成されるかを決定します。snap_interval:スナップショットをトリガーするクロック/時間間隔(分単位)。スナップショットは、前のスナップショットとの差分に基づいて増分されます。0はスナップを無効にします(デフォルト:0)。ここでは文字列が必要です。つまり、70ではなく"70"です。aggregation_level:ボリュームが分散されるチャンクの数を指定します。0は非集約ボリュームを示します(デフォルト:0)。ここには文字列が必要です。つまり、0ではなく"0"です。ephemeral:アンマウント後にボリュームをクリーンアップするか、永続化するかを指定します。emptyDirユースケースではこの値をtrueに設定でき、Cassandraなどのデータベースのようなpersistent volumesユースケースではfalse、true/false(デフォルトはfalse)に設定する必要があります。ここでは文字列が必要です。つまり、trueではなく"true"です。
Local
FEATURE STATE: Kubernetes v1.14 [stable]
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : local-storage
provisioner : kubernetes.io/no-provisioner
volumeBindingMode : WaitForFirstConsumer
ローカルボリュームは現在、動的プロビジョニングをサポートしていませんが、Podのスケジューリングまでボリュームバインドを遅らせるには、引き続きStorageClassを作成する必要があります。これは、WaitForFirstConsumerボリュームバインディングモードによって指定されます。
ボリュームバインディングを遅延させると、PersistentVolumeClaimに適切なPersistentVolumeを選択するときに、スケジューラはPodのスケジューリング制約をすべて考慮することができます。
6.6 - ボリュームの動的プロビジョニング(Dynamic Volume Provisioning)
ボリュームの動的プロビジョニングにより、ストレージ用のボリュームをオンデマンドに作成することができます。
動的プロビジョニングなしでは、クラスター管理者はクラウドプロバイダーまたはストレージプロバイダーに対して新規のストレージ用のボリュームとPersistentVolumeオブジェクト
バックグラウンド
ボリュームの動的プロビジョニングの実装はstorage.k8s.ioというAPIグループ内のStorageClassというAPIオブジェクトに基づいています。クラスター管理者はStorageClassオブジェクトを必要に応じていくつでも定義でき、各オブジェクトはボリュームをプロビジョンするVolumeプラグイン (別名プロビジョナー )と、プロビジョンされるときにプロビジョナーに渡されるパラメーターを指定します。
クラスター管理者はクラスター内で複数の種類のストレージ(同一または異なるストレージシステム)を定義し、さらには公開でき、それらのストレージはパラメーターのカスタムセットを持ちます。この仕組みにおいて、エンドユーザーはストレージがどのようにプロビジョンされるか心配する必要がなく、それでいて複数のストレージオプションから選択できることを保証します。
StorageClassに関するさらなる情報はStorage Class を参照ください。
動的プロビジョニングを有効にする
動的プロビジョニングを有効にするために、クラスター管理者はユーザーのために1つまたはそれ以上のStorageClassを事前に作成する必要があります。StorageClassオブジェクトは、動的プロビジョニングが実行されるときに、どのプロビジョナーが使用されるべきか、またどのようなパラメーターをプロビジョナーに渡すべきか定義します。StorageClassオブジェクトの名前は、有効なDNSサブドメイン名 である必要があります。
下記のマニフェストでは標準的な永続化ディスクをプロビジョンする"slow"というStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : slow
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-standard
下記のマニフェストではSSDを使った永続化ディスクをプロビジョンする"fast"というStorageClassを作成します。
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : fast
provisioner : kubernetes.io/gce-pd
parameters :
type : pd-ssd
動的プロビジョニングの使用
ユーザーはPersistentVolumeClaimリソース内でStorageClassを含むことで、動的にプロビジョンされたStorageをリクエストできます。Kubernetes v1.6以前では、この機能はvolume.beta.kubernetes.io/storage-classアノテーションを介して使うことができました。しかしこのアノテーションはv1.9から非推奨になりました。その代わりユーザーは現在ではPersistentVolumeClaimオブジェクトのstorageClassNameを使う必要があります。このフィールドの値は、管理者によって設定されたStorageClassの名前と一致しなければなりません(下記 のセクションも参照ください)。
"fast"というStorageClassを選択するために、例としてユーザーは下記のPersistentVolumeClaimを作成します。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : claim1
spec :
accessModes :
- ReadWriteOnce
storageClassName : fast
resources :
requests :
storage : 30Gi
このリソースによってSSDのような永続化ディスクが自動的にプロビジョンされます。このリソースが削除された時、そのボリュームは削除されます。
デフォルトの挙動
動的プロビジョニングは、もしStorageClassが1つも指定されていないときに全てのPersistentVolumeClaimが動的にプロビジョンされるようにクラスター上で有効にできます。クラスター管理者は、下記を行うことによりこのふるまいを有効にできます。
管理者はStorageClassに対してstorageclass.kubernetes.io/is-default-classアノテーションをつけることで、デフォルトのStorageClassとしてマーキングできます。
デフォルトのStorageClassがクラスター内で存在し、かつユーザーがPersistentVolumeClaimリソースでstorageClassNameを指定しなかった場合、DefaultStorageClassという管理コントローラーはstorageClassNameフィールドの値をデフォルトのStorageClassを指し示すように自動で追加します。
注意点として、クラスター上では最大1つしかデフォルト のStorageClassが指定できず、storageClassNameを明示的に指定しないPersistentVolumeClaimは作成することもできません。
トポロジーに関する注意
マルチゾーン クラスター内では、Podは単一のリージョン内のゾーンをまたいでしか稼働できません。シングルゾーンのStorageバックエンドはPodがスケジュールされるゾーン内でプロビジョンされる必要があります。これはVolume割り当てモード を設定することにより可能となります。
6.7 - ボリュームのスナップショット
Kubernetesでは、VolumeSnapshot はストレージシステム上のボリュームのスナップショットを表します。このドキュメントは、Kubernetes永続ボリューム に既に精通していることを前提としています。
概要
APIリソースPersistentVolumeとPersistentVolumeClaimを使用してユーザーと管理者にボリュームをプロビジョニングする方法と同様に、VolumeSnapshotContentとVolumeSnapshotAPIリソースは、ユーザーと管理者のボリュームスナップショットを作成するために提供されます。
VolumeSnapshotContentは、管理者によってプロビジョニングされたクラスター内のボリュームから取得されたスナップショットです。PersistentVolumeがクラスターリソースであるように、これはクラスターのリソースです。
VolumeSnapshotは、ユーザーによるボリュームのスナップショットの要求です。PersistentVolumeClaimに似ています。
VolumeSnapshotClassを使用すると、VolumeSnapshotに属するさまざまな属性を指定できます。これらの属性は、ストレージシステム上の同じボリュームから取得されたスナップショット間で異なる場合があるため、PersistentVolumeClaimの同じStorageClassを使用して表現することはできません。
ボリュームスナップショットは、完全に新しいボリュームを作成することなく、特定の時点でボリュームの内容をコピーするための標準化された方法をKubernetesユーザーに提供します。この機能により、たとえばデータベース管理者は、編集または削除の変更を実行する前にデータベースをバックアップできます。
この機能を使用する場合、ユーザーは次のことに注意する必要があります。
APIオブジェクトVolumeSnapshot、VolumeSnapshotContent、およびVolumeSnapshotClassはCRD であり、コアAPIの一部ではありません。
VolumeSnapshotのサポートは、CSIドライバーでのみ利用できます。VolumeSnapshotの展開プロセスの一環として、Kubernetesチームは、コントロールプレーンに展開されるスナップショットコントローラーと、CSIドライバーと共に展開されるcsi-snapshotterと呼ばれるサイドカーヘルパーコンテナを提供します。スナップショットコントローラーは、VolumeSnapshotおよびVolumeSnapshotContentオブジェクトを管理し、VolumeSnapshotContentオブジェクトの作成と削除を担当します。サイドカーcsi-snapshotterは、VolumeSnapshotContentオブジェクトを監視し、CSIエンドポイントに対してCreateSnapshotおよびDeleteSnapshot操作をトリガーします。スナップショットオブジェクトの厳密な検証を提供するvalidation Webhookサーバーもあります。これは、CSIドライバーではなく、スナップショットコントローラーおよびCRDと共にKubernetesディストリビューションによってインストールする必要があります。スナップショット機能が有効になっているすべてのKubernetesクラスターにインストールする必要があります。
CSIドライバーは、ボリュームスナップショット機能を実装している場合と実装していない場合があります。ボリュームスナップショットのサポートを提供するCSIドライバーは、csi-snapshotterを使用する可能性があります。詳細については、CSIドライバーのドキュメント を参照してください。
CRDとスナップショットコントローラーのインストールは、Kubernetesディストリビューションの責任です。
ボリュームスナップショットとボリュームスナップショットのコンテンツのライフサイクル
VolumeSnapshotContentsはクラスター内のリソースです。VolumeSnapshotsは、これらのリソースに対するリクエストです。VolumeSnapshotContentsとVolumeSnapshotsの間の相互作用は、次のライフサイクルに従います。
プロビジョニングボリュームのスナップショット
スナップショットをプロビジョニングするには、事前プロビジョニングと動的プロビジョニングの2つの方法があります。
事前プロビジョニング
クラスター管理者は、多数のVolumeSnapshotContentsを作成します。それらは、クラスターユーザーが使用できるストレージシステム上の実際のボリュームスナップショットの詳細を保持します。それらはKubernetesAPIに存在し、消費することができます。
動的プロビジョニング
既存のスナップショットを使用する代わりに、スナップショットをPersistentVolumeClaimから動的に取得するように要求できます。VolumeSnapshotClass は、スナップショットを作成するときに使用するストレージプロバイダー固有のパラメーターを指定します。
バインディング
スナップショットコントローラーは、事前プロビジョニングされたシナリオと動的にプロビジョニングされたシナリオの両方で、適切なVolumeSnapshotContentオブジェクトを使用したVolumeSnapshotオブジェクトのバインディングを処理します。バインディングは1対1のマッピングです。
事前プロビジョニングされたバインディングの場合、要求されたVolumeSnapshotContentオブジェクトが作成されるまで、VolumeSnapshotはバインドされないままになります。
スナップショットソース保護としてのPersistentVolumeClaim
この保護の目的は、スナップショットがシステムから取得されている間、使用中のPersistentVolumeClaim APIオブジェクトがシステムから削除されないようにすることです(これにより、データが失われる可能性があります)。
PersistentVolumeClaimのスナップショットが作成されている間、そのPersistentVolumeClaimは使用中です。スナップショットソースとしてアクティブに使用されているPersistentVolumeClaim APIオブジェクトを削除しても、PersistentVolumeClaimオブジェクトはすぐには削除されません。代わりに、PersistentVolumeClaimオブジェクトの削除は、スナップショットがReadyToUseになるか中止されるまで延期されます。
削除
削除はVolumeSnapshotオブジェクトの削除によってトリガーされ、DeletionPolicyに従います。DeletionPolicyがDeleteの場合、基になるストレージスナップショットはVolumeSnapshotContentオブジェクトとともに削除されます。DeletionPolicyがRetainの場合、基になるスナップショットとVolumeSnapshotContentの両方が残ります。
ボリュームスナップショット
各VolumeSnapshotには、仕様とステータスが含まれています。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshot
metadata :
name : new-snapshot-test
spec :
volumeSnapshotClassName : csi-hostpath-snapclass
source :
persistentVolumeClaimName : pvc-test
persistentVolumeClaimNameは、スナップショットのPersistentVolumeClaimデータソースの名前です。このフィールドは、スナップショットを動的にプロビジョニングするために必要です。
ボリュームスナップショットは、属性volumeSnapshotClassNameを使用してVolumeSnapshotClass の名前を指定することにより、特定のクラスを要求できます。何も設定されていない場合、利用可能な場合はデフォルトのクラスが使用されます。
事前プロビジョニングされたスナップショットの場合、次の例に示すように、スナップショットのソースとしてvolumeSnapshotContentNameを指定する必要があります。事前プロビジョニングされたスナップショットには、volumeSnapshotContentNameソースフィールドが必要です。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshot
metadata :
name : test-snapshot
spec :
source :
volumeSnapshotContentName : test-content
ボリュームスナップショットコンテンツ
各VolumeSnapshotContentには、仕様とステータスが含まれています。動的プロビジョニングでは、スナップショット共通コントローラーがVolumeSnapshotContentオブジェクトを作成します。以下に例を示します。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshotContent
metadata :
name : snapcontent-72d9a349-aacd-42d2-a240-d775650d2455
spec :
deletionPolicy : Delete
driver : hostpath.csi.k8s.io
source :
volumeHandle : ee0cfb94-f8d4-11e9-b2d8-0242ac110002
sourceVolumeMode : Filesystem
volumeSnapshotClassName : csi-hostpath-snapclass
volumeSnapshotRef :
name : new-snapshot-test
namespace : default
uid : 72d9a349-aacd-42d2-a240-d775650d2455
volumeHandleは、ストレージバックエンドで作成され、ボリュームの作成中にCSIドライバーによって返されるボリュームの一意の識別子です。このフィールドは、スナップショットを動的にプロビジョニングするために必要です。これは、スナップショットのボリュームソースを指定します。
事前プロビジョニングされたスナップショットの場合、(クラスター管理者として)次のようにVolumeSnapshotContentオブジェクトを作成する必要があります。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshotContent
metadata :
name : new-snapshot-content-test
spec :
deletionPolicy : Delete
driver : hostpath.csi.k8s.io
source :
snapshotHandle : 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode : Filesystem
volumeSnapshotRef :
name : new-snapshot-test
namespace : default
snapshotHandleは、ストレージバックエンドで作成されたボリュームスナップショットの一意の識別子です。このフィールドは、事前プロビジョニングされたスナップショットに必要です。このVolumeSnapshotContentが表すストレージシステムのCSIスナップショットIDを指定します。
sourceVolumeModeは、スナップショットが作成されるボリュームのモードです。sourceVolumeModeフィールドの値は、FilesystemまたはBlockのいずれかです。ソースボリュームモードが指定されていない場合、Kubernetesはスナップショットをソースボリュームのモードが不明であるかのように扱います。
volumeSnapshotRefは、対応するVolumeSnapshotの参照です。VolumeSnapshotContentが事前プロビジョニングされたスナップショットとして作成されている場合、volumeSnapshotRefで参照されるVolumeSnapshotがまだ存在しない可能性があることに注意してください。
スナップショットのボリュームモードの変換
クラスターにインストールされているVolumeSnapshotsAPIがsourceVolumeModeフィールドをサポートしている場合、APIには、権限のないユーザーがボリュームのモードを変換するのを防ぐ機能があります。
クラスターにこの機能の機能があるかどうかを確認するには、次のコマンドを実行します。
$ kubectl get crd volumesnapshotcontent -o yaml
ユーザーが既存のVolumeSnapshotからPersistentVolumeClaimを作成できるようにしたいが、ソースとは異なるボリュームモードを使用する場合は、VolumeSnapshotに対応するVolumeSnapshotContentにアノテーションsnapshot.storage.kubernetes.io/allow-volume-mode-change: "true"を追加する必要があります。
事前プロビジョニングされたスナップショットの場合、クラスター管理者がspec.sourceVolumeModeを入力する必要があります。
この機能を有効にしたVolumeSnapshotContentリソースの例は次のようになります。
apiVersion : snapshot.storage.k8s.io/v1
kind : VolumeSnapshotContent
metadata :
name : new-snapshot-content-test
annotations :
- snapshot.storage.kubernetes.io/allow-volume-mode-change : "true"
spec :
deletionPolicy : Delete
driver : hostpath.csi.k8s.io
source :
snapshotHandle : 7bdd0de3-aaeb-11e8-9aae-0242ac110002
sourceVolumeMode : Filesystem
volumeSnapshotRef :
name : new-snapshot-test
namespace : default
スナップショットからのボリュームのプロビジョニング
PersistentVolumeClaimオブジェクトのdataSource フィールドを使用して、スナップショットからのデータが事前に取り込まれた新しいボリュームをプロビジョニングできます。
詳細については、ボリュームのスナップショットとスナップショットからのボリュームの復元 を参照してください。
6.8 - VolumeSnapshotClass
このドキュメントでは、KubernetesにおけるVolumeSnapshotClassのコンセプトについて説明します。Volumeのスナップショット とストレージクラス も参照してください。
イントロダクション
StorageClassはVolumeをプロビジョンするときに、ストレージの"クラス"に関する情報を記述する方法を提供します。それと同様に、VolumeSnapshotClassではVolumeSnapshotをプロビジョンするときに、ストレージの"クラス"に関する情報を記述する方法を提供します。
VolumeSnapshotClass リソース
各VolumeSnapshotClassはdriver、deletionPolicyとparametersフィールドを含み、それらは、そのクラスに属するVolumeSnapshotが動的にプロビジョンされるときに使われます。
VolumeSnapshotClassオブジェクトの名前は重要であり、それはユーザーがどのように特定のクラスをリクエストできるかを示したものです。管理者は初めてVolumeSnapshotClassオブジェクトを作成するときに、その名前と他のパラメーターをセットし、そのオブジェクトは一度作成されるとそのあと更新することができません。
管理者は、バインド対象のクラスを1つもリクエストしないようなVolumeSnapshotのために、デフォルトのVolumeSnapshotClassを指定することができます。
apiVersion : snapshot.storage.k8s.io/v1beta1
kind : VolumeSnapshotClass
metadata :
name : csi-hostpath-snapclass
driver : hostpath.csi.k8s.io
deletionPolicy : Delete
parameters :
Driver
VolumeSnapshotClassは、VolumeSnapshotをプロビジョンするときに何のCSIボリュームプラグインを使うか決定するためのdriverフィールドを持っています。このフィールドは必須となります。
DeletionPolicy
VolumeSnapshotClassにはdeletionPolicyがあります。これにより、バインドされている VolumeSnapshotオブジェクトが削除されるときに、VolumeSnapshotContentがどうなるかを設定することができます。VolumeSnapshotのdeletionPolicyは、RetainまたはDeleteのいずれかです。このフィールドは指定しなければなりません。
deletionPolicyがDeleteの場合、元となるストレージスナップショットは VolumeSnapshotContentオブジェクトとともに削除されます。deletionPolicyがRetainの場合、元となるスナップショットとVolumeSnapshotContentの両方が残ります。
Parameters
VolumeSnapshotClassは、そのクラスに属するVolumeSnapshotを指定するパラメーターを持っています。
driverに応じて様々なパラメーターを使用できます。
6.9 - CSI Volume Cloning
このドキュメントではKubernetesで既存のCSIボリュームの複製についてのコンセプトを説明します。このページを読む前にあらかじめボリューム についてよく理解していることが望ましいです。
イントロダクション
CSI のボリューム複製機能は、ユーザーがボリューム の複製を作成することを示すdataSourceフィールドで既存のPVC を指定するためのサポートを追加します。
複製は既存のKubernetesボリュームの複製として定義され、標準のボリュームと同じように使用できます。唯一の違いは、プロビジョニング時に「新しい」空のボリュームを作成するのではなく、バックエンドデバイスが指定されたボリュームの正確な複製を作成することです。
複製の実装は、Kubernetes APIの観点からは新しいPVCの作成時に既存のPVCをdataSourceとして指定する機能を追加するだけです。ソースPVCはバインドされており、使用可能でなければなりません(使用中ではありません)。
この機能を使用する場合、ユーザーは次のことに注意する必要があります:
複製のサポート(VolumePVCDataSource)はCSIドライバーのみです。
複製のサポートは動的プロビジョニングのみです。
CSIドライバーはボリューム複製機能を実装している場合としていない場合があります。
PVCは複製先のPVCと同じ名前空間に存在する場合にのみ複製できます(複製元と複製先は同じ名前空間になければなりません)。
複製は同じストレージクラス内でのみサポートされます。
宛先ボリュームは、ソースと同じストレージクラスである必要があります。
デフォルトのストレージクラスを使用でき、仕様ではstorageClassNameを省略できます。
複製は同じVolumeMode設定を使用する2つのボリューム間でのみ実行できます(ブロックモードのボリュームを要求する場合、ソースもブロックモードである必要があります)。
プロビジョニング
複製は同じ名前空間内の既存のPVCを参照するdataSourceを追加すること以外は他のPVCと同様にプロビジョニングされます。
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : clone-of-pvc-1
namespace : myns
spec :
accessModes :
- ReadWriteOnce
storageClassName : cloning
resources :
requests :
storage : 5Gi
dataSource :
kind : PersistentVolumeClaim
name : pvc-1
備考: spec.resources.requests.storageに容量の値を指定する必要があります。指定する値は、ソースボリュームの容量と同じかそれ以上である必要があります。
このyamlの作成結果は指定された複製元であるpvc-1と全く同じデータを持つclone-of-pvc-1という名前の新しいPVCです。
使い方
新しいPVCが使用可能になると、複製されたPVCは他のPVCと同じように利用されます。またこの時点で新しく作成されたPVCは独立したオブジェクトであることが期待されます。元のdataSource PVCを考慮せず個別に利用、複製、スナップショット、削除できます。これはまた複製元が新しく作成された複製にリンクされておらず、新しく作成された複製に影響を与えずに変更または削除できることを意味します。
6.10 - ストレージ容量
ストレージ容量は、Podが実行されるノードごとに制限があったり、大きさが異なる可能性があります。たとえば、NASがすべてのノードからはアクセスできなかったり、初めからストレージがノードローカルでしか利用できない可能性があります。
FEATURE STATE: Kubernetes v1.19 [alpha]
このページでは、Kubernetesがストレージ容量を追跡し続ける方法と、スケジューラーがその情報を利用して、残りの未作成のボリュームのために十分なストレージ容量へアクセスできるノード上にどのようにPodをスケジューリングするかについて説明します。もしストレージ容量の追跡がなければ、スケジューラーは、ボリュームをプロビジョニングするために十分な容量のないノードを選択してしまい、スケジューリングの再試行が複数回行われてしまう恐れがあります。
ストレージ容量の追跡は、Container Storage Interface (CSI)向けにサポートされており、CSIドライバーのインストール時に有効にする必要があります 。
API
この機能には、以下の2つのAPI拡張があります。
スケジューリング
ストレージ容量の情報がKubernetesのスケジューラーで利用されるのは、以下のすべての条件を満たす場合です。
CSIStorageCapacityフィーチャーゲートがtrueであるPodがまだ作成されていないボリュームを使用する時
そのボリュームが、CSIドライバーを参照し、volume binding mode にWaitForFirstConsumerを使うStorageClass を使用している
ドライバーに対するCSIDriverオブジェクトのStorageCapacityがtrueに設定されている
その場合、スケジューラーはPodに対して、十分なストレージ容量が利用できるノードだけを考慮するようになります。このチェックは非常に単純で、ボリュームのサイズと、CSIStorageCapacityオブジェクトに一覧された容量を、ノードを含むトポロジーで比較するだけです。
volume binding modeがImmediateのボリュームの場合、ストレージドライバーはボリュームを使用するPodとは関係なく、ボリュームを作成する場所を決定します。次に、スケジューラーはボリュームが作成された後、Podをボリュームが利用できるノードにスケジューリングします。
CSI ephemeral volumes の場合、スケジューリングは常にストレージ容量を考慮せずに行われます。このような動作になっているのは、このボリュームタイプはノードローカルな特別なCSIドライバーでのみ使用され、そこでは特に大きなリソースが必要になることはない、という想定に基づいています。
再スケジューリング
WaitForFirstConsumerボリュームがあるPodに対してノードが選択された場合は、その決定はまだ一時的なものです。次のステップで、CSIストレージドライバーに対して、選択されたノード上でボリュームが利用可能になることが予定されているというヒントを使用してボリュームの作成を要求します。
Kubernetesは古い容量の情報をもとにノードを選択する場合があるため、実際にはボリュームが作成できないという可能性が存在します。その場合、ノードの選択がリセットされ、KubernetesスケジューラーはPodに割り当てるノードを再び探します。
制限
ストレージ容量を追跡することで、1回目の試行でスケジューリングが成功する可能性が高くなります。しかし、スケジューラーは潜在的に古い情報に基づいて決定を行う可能性があるため、成功を保証することはできません。通常、ストレージ容量の情報が存在しないスケジューリングと同様のリトライの仕組みによって、スケジューリングの失敗に対処します。
スケジューリングが永続的に失敗する状況の1つは、Podが複数のボリュームを使用する場合で、あるトポロジーのセグメントで1つのボリュームがすでに作成された後、もう1つのボリュームのために十分な容量が残っていないような場合です。この状況から回復するには、たとえば、容量を増加させたり、すでに作成されたボリュームを削除するなどの手動での対応が必要です。この問題に自動的に対処するためには、まだ追加の作業 が必要となっています。
ストレージ容量の追跡を有効にする
ストレージ容量の追跡はアルファ機能 であり、CSIStorageCapacityフィーチャーゲート とstorage.k8s.io/v1alpha1 API group を有効にした場合にのみ、有効化されます。詳細については、--feature-gatesおよび--runtime-config kube-apiserverパラメーター を参照してください。
Kubernetesクラスターがこの機能をサポートしているか簡単に確認するには、以下のコマンドを実行して、CSIStorageCapacityオブジェクトを一覧表示します。
kubectl get csistoragecapacities --all-namespaces
クラスターがCSIStorageCapacityをサポートしていれば、CSIStorageCapacityのリストが表示されるか、次のメッセージが表示されます。
No resources found
もしサポートされていなければ、代わりに次のエラーが表示されます。
error: the server doesn't have a resource type "csistoragecapacities"
クラスター内で機能を有効化することに加えて、CSIドライバーもこの機能をサポートしている必要があります。詳細については、各ドライバーのドキュメントを参照してください。
次の項目
6.11 - ノード固有のボリューム制限
このページでは、さまざまなクラウドプロバイダーのノードに接続できるボリュームの最大数について説明します。
通常、Google、Amazon、Microsoftなどのクラウドプロバイダーには、ノードに接続できるボリュームの数に制限があります。Kubernetesがこれらの制限を尊重することが重要です。
そうしないと、ノードでスケジュールされたPodが、ボリュームが接続されるのを待ってスタックする可能性があります。
Kubernetesのデフォルトの制限
Kubernetesスケジューラーには、ノードに接続できるボリュームの数にデフォルトの制限があります。
カスタム制限
これらの制限を変更するには、KUBE_MAX_PD_VOLS環境変数の値を設定し、スケジューラーを開始します。CSIドライバーの手順は異なる場合があります。制限をカスタマイズする方法については、CSIドライバーのドキュメントを参照してください。
デフォルトの制限よりも高い制限を設定する場合は注意してください。クラウドプロバイダーのドキュメントを参照して、設定した制限をノードが実際にサポートしていることを確認してください。
制限はクラスター全体に適用されるため、すべてのノードに影響します。
動的ボリューム制限
FEATURE STATE: Kubernetes v1.17 [stable]
動的ボリューム制限は、次のボリュームタイプでサポートされています。
Amazon EBS
Google Persistent Disk
Azure Disk
CSI
ツリー内のボリュームプラグインによって管理されるボリュームの場合、Kubernetesはノードタイプを自動的に決定し、ノードに適切なボリュームの最大数を適用します。例えば:
Google Compute Engine 上ではノードタイプ に応じて、最大127個のボリュームをノードに接続できます。
M5、C5、R5、T3、およびZ1DインスタンスタイプのAmazon EBSディスクの場合、Kubernetesは25ボリュームのみをノードにアタッチできます。Amazon Elastic Compute Cloud (EC2) の他のインスタンスタイプの場合、Kubernetesでは39個のボリュームをノードに接続できます。
Azureでは、ノードの種類に応じて、最大64個のディスクをノードに接続できます。詳細については、Azureの仮想マシンのサイズ を参照してください。
CSIストレージドライバーが(NodeGetInfoを使用して)ノードの最大ボリューム数をアドバタイズする場合、kube-scheduler はその制限を尊重します。詳細については、CSIの仕様 を参照してください。
CSIドライバーに移行されたツリー内プラグインによって管理されるボリュームの場合、ボリュームの最大数はCSIドライバーによって報告される数になります。
6.12 - ボリュームヘルスモニタリング
FEATURE STATE: Kubernetes v1.21 [alpha]
CSI ボリュームヘルスモニタリングにより、CSIドライバーは、基盤となるストレージシステムから異常なボリューム状態を検出し、それらをPVC またはPod のイベントとして報告できます。
ボリュームヘルスモニタリング
Kubernetes volume health monitoring は、KubernetesがContainerStorageInterface(CSI)を実装する方法の一部です。ボリュームヘルスモニタリング機能は、外部のヘルスモニターコントローラーとkubelet の2つのコンポーネントで実装されます。
CSIドライバーがコントローラー側からのボリュームヘルスモニタリング機能をサポートしている場合、CSIボリュームで異常なボリューム状態が検出されると、関連するPersistentVolumeClaim (PVC)でイベントが報告されます。
外部ヘルスモニターコントローラー も、ノード障害イベントを監視します。enable-node-watcherフラグをtrueに設定することで、ノード障害の監視を有効にできます。外部ヘルスモニターがノード障害イベントを検出すると、コントローラーは、このPVCを使用するポッドが障害ノード上にあることを示すために、PVCでイベントが報告されることを報告します。
CSIドライバーがノード側からのボリュームヘルスモニタリング機能をサポートしている場合、CSIボリュームで異常なボリューム状態が検出されると、PVCを使用するすべてのPodでイベントが報告されます。さらに、ボリュームヘルス情報はKubelet VolumeStatsメトリクスとして公開されます。新しいメトリックkubelet_volume_stats_health_status_abnormalが追加されました。このメトリックにはnamespaceとpersistentvolumeclaimの2つのラベルが含まれます。カウントは1または0です。1はボリュームが異常であることを示し、0はボリュームが正常であることを示します。詳細については、KEP を確認してください。
備考: ノード側からこの機能を使用するには、
CSIVolumeHealthfeature gate を有効にする必要があります。
次の項目
CSIドライバーのドキュメント を参照して、この機能を実装しているCSIドライバーを確認してください。
7 - 設定
7.1 - 設定のベストプラクティス
このドキュメントでは、ユーザーガイド、入門マニュアル、および例を通して紹介されている設定のベストプラクティスを中心に説明します。
このドキュメントは生ものです。このリストには載っていないが他の人に役立つかもしれない何かについて考えている場合、IssueまたはPRを遠慮なく作成してください。
一般的な設定のTips
構成を定義する際には、最新の安定したAPIバージョンを指定してください。
設定ファイルは、クラスターに反映される前にバージョン管理システムに保存されるべきです。これによって、必要に応じて設定変更を迅速にロールバックできます。また、クラスターの再作成や復元時にも役立ちます。
JSONではなくYAMLを使って設定ファイルを書いてください。これらのフォーマットはほとんどすべてのシナリオで互換的に使用できますが、YAMLはよりユーザーフレンドリーになる傾向があります。
意味がある場合は常に、関連オブジェクトを単一ファイルにグループ化します。多くの場合、1つのファイルの方が管理が簡単です。例としてguestbook-all-in-one.yaml ファイルを参照してください。
多くのkubectlコマンドがディレクトリに対しても呼び出せることも覚えておきましょう。たとえば、設定ファイルのディレクトリで kubectl applyを呼び出すことができます。
不必要にデフォルト値を指定しないでください。シンプルかつ最小限の設定のほうがエラーが発生しにくくなります。
よりよいイントロスペクションのために、オブジェクトの説明をアノテーションに入れましょう。
"真っ裸"のPod に対する ReplicaSet、Deployment、およびJob
可能な限り、"真っ裸"のPod(ReplicaSet やDeployment にバインドされていないPod)は使わないでください。Nodeに障害が発生した場合、これらのPodは再スケジュールされません。
明示的にrestartPolicy: NeverJob のほうが適切な場合もあるかもしれません。
Service
対応するバックエンドワークロード(DeploymentまたはReplicaSet)の前、およびそれにアクセスする必要があるワークロードの前にService を作成します。Kubernetesがコンテナを起動すると、コンテナ起動時に実行されていたすべてのServiceを指す環境変数が提供されます。たとえば、fooという名前のServiceが存在する場合、すべてのコンテナは初期環境で次の変数を取得します。
FOO_SERVICE_HOST = <the host the Service is running on>
FOO_SERVICE_PORT = <the port the Service is running on>
これは順序付けの必要性を意味します - PodがアクセスしたいServiceはPod自身の前に作らなければならず、そうしないと環境変数は注入されません。DNSにはこの制限はありません。
(強くお勧めしますが)クラスターアドオン の1つの選択肢はDNSサーバーです。DNSサーバーは、新しいServiceについてKubernetes APIを監視し、それぞれに対して一連のDNSレコードを作成します。クラスター全体でDNSが有効になっている場合は、すべてのPodが自動的にServicesの名前解決を行えるはずです。
どうしても必要な場合以外は、PodにhostPortを指定しないでください。PodをhostPortにバインドすると、Podがスケジュールできる場所の数を制限します、それぞれの<hostIP、 hostPort、protocol>の組み合わせはユニークでなければならないからです。hostIPとprotocolを明示的に指定しないと、KubernetesはデフォルトのhostIPとして0.0.0.0を、デフォルトの protocolとしてTCPを使います。
デバッグ目的でのみポートにアクセスする必要がある場合は、apiserver proxy またはkubectl port-forward
ノード上でPodのポートを明示的に公開する必要がある場合は、hostPortに頼る前にNodePort の使用を検討してください。
hostPortの理由と同じくして、hostNetworkの使用はできるだけ避けてください。
kube-proxyのロードバランシングが不要な場合は、headless Service (ClusterIPがNone)を使用してServiceを簡単に検出できます。
ラベルの使用
{ app: myapp, tier: frontend, phase: test, deployment: v3 }のように、アプリケーションまたはデプロイメントの セマンティック属性 を識別するラベル を定義して使いましょう。これらのラベルを使用して、他のリソースに適切なPodを選択できます。例えば、すべてのtier:frontendを持つPodを選択するServiceや、app:myappに属するすべてのphase:testコンポーネント、などです。このアプローチの例を知るには、ゲストブック アプリも合わせてご覧ください。
セレクターからリリース固有のラベルを省略することで、Serviceを複数のDeploymentにまたがるように作成できます。 Deployment により、ダウンタイムなしで実行中のサービスを簡単に更新できます。
オブジェクトの望ましい状態はDeploymentによって記述され、その仕様への変更が 適用 されると、Deploymentコントローラーは制御された速度で実際の状態を望ましい状態に変更します。
デバッグ用にラベルを操作できます。Kubernetesコントローラー(ReplicaSetなど)とServiceはセレクターラベルを使用してPodとマッチするため、Podから関連ラベルを削除すると、コントローラーによって考慮されたり、Serviceによってトラフィックを処理されたりすることがなくなります。既存のPodのラベルを削除すると、そのコントローラーはその代わりに新しいPodを作成します。これは、「隔離」環境で以前の「ライブ」Podをデバッグするのに便利な方法です。対話的にラベルを削除または追加するには、kubectl label
コンテナイメージ
imagePullPolicy とイメージのタグは、kubelet が特定のイメージをpullしようとしたときに作用します。
imagePullPolicy: IfNotPresent: ローカルでイメージが見つからない場合にのみイメージをpullします。
imagePullPolicy: Always: kubeletがコンテナを起動する度に、kubeletはコンテナイメージレジストリに問い合わせて、イメージのダイジェストの名前解決を行います。もし、kubeletが同じダイジェストのコンテナイメージをローカルにキャッシュしていたら、kubeletはそのキャッシュされたイメージを利用します。そうでなければ、kubeletは解決されたダイジェストのイメージをダウンロードし、そのイメージを利用してコンテナを起動します。
imagePullPolicy のタグが省略されていて、利用してるイメージのタグが:latestの場合や省略されている場合、Alwaysが適用されます。
imagePullPolicy のタグが省略されていて、利用してるイメージのタグはあるが:latestでない場合、IfNotPresentが適用されます。
imagePullPolicy: Never: 常にローカルでイメージを探そうとします。ない場合にもイメージはpullしません。
備考: コンテナが常に同じバージョンのイメージを使用するようにするためには、そのコンテナイメージの
ダイジェスト を指定することができます。
<image-name>:<tag>を
<image-name>@<digest>で置き換えます(例:
image@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2)。このダイジェストはイメージの特定のバージョンを一意に識別するため、ダイジェスト値を変更しない限り、Kubernetesによって更新されることはありません。
備考: どのバージョンのイメージが実行されているのかを追跡するのが難しく、適切にロールバックするのが難しいため、本番環境でコンテナをデプロイするときは :latestタグを使用しないでください。
備考: ベースイメージのプロバイダーのキャッシュセマンティクスにより、imagePullPolicy:Alwaysもより効率的になります。たとえば、Dockerでは、イメージがすでに存在する場合すべてのイメージレイヤーがキャッシュされ、イメージのダウンロードが不要であるため、pullが高速になります。
kubectlの使い方
kubectl apply -f <directory>を使いましょう。これを使うと、ディレクトリ内のすべての.yaml、.yml、および.jsonファイルがapplyに渡されます。
getやdeleteを行う際は、特定のオブジェクト名を指定するのではなくラベルセレクターを使いましょう。ラベルセレクター とラベルの効果的な使い方 のセクションを参照してください。
単一コンテナのDeploymentやServiceを素早く作成するなら、kubectl create deploymentやkubectl exposeを使いましょう。一例として、Serviceを利用したクラスター内のアプリケーションへのアクセス を参照してください。
7.2 - ConfigMap
ConfigMapは、 機密性のないデータをキーと値のペアで保存するために使用されるAPIオブジェクトです。Pod は、環境変数、コマンドライン引数、またはボリューム 内の設定ファイルとしてConfigMapを使用できます。
ConfigMapを使用すると、環境固有の設定をコンテナイメージ から分離できるため、アプリケーションを簡単に移植できるようになります。
注意: ConfigMapは機密性や暗号化を提供しません。保存したいデータが機密情報である場合は、ConfigMapの代わりに
Secret を使用するか、追加の(サードパーティー)ツールを使用してデータが非公開になるようにしてください。
動機
アプリケーションのコードとは別に設定データを設定するには、ConfigMapを使用します。
たとえば、アプリケーションを開発していて、(開発用時には)自分のコンピューター上と、(実際のトラフィックをハンドルするときは)クラウド上とで実行することを想像してみてください。あなたは、DATABASE_HOSTという名前の環境変数を使用するコードを書きます。ローカルでは、この変数をlocalhostに設定します。クラウド上では、データベースコンポーネントをクラスター内に公開するKubernetesのService を指すように設定します。
こうすることで、必要であればクラウド上で実行しているコンテナイメージを取得することで、ローカルでも完全に同じコードを使ってデバッグができるようになります。
ConfigMapは、大量のデータを保持するようには設計されていません。ConfigMapに保存されるデータは1MiBを超えることはできません。この制限を超える設定を保存する必要がある場合は、ボリュームのマウントを検討するか、別のデータベースまたはファイルサービスを使用することを検討してください。
ConfigMapオブジェクト
ConfigMapは、他のオブジェクトが使うための設定を保存できるAPIオブジェクト です。ほとんどのKubernetesオブジェクトにspecセクションがあるのとは違い、ConfigMapにはdataおよびbinaryDataフィールドがあります。これらのフィールドは、キーとバリューのペアを値として受け入れます。dataフィールドとbinaryDataフィールドはどちらもオプションです。dataフィールドはUTF-8バイトシーケンスを含むように設計されていますが、binaryDataフィールドはバイナリデータを含むように設計されています。
ConfigMapの名前は、有効なDNSのサブドメイン名 でなければなりません。
dataまたはbinaryDataフィールドの各キーは、英数字、-、_、または.で構成されている必要があります。dataに格納されているキーは、binaryDataフィールドのキーと重複することはできません。
v1.19以降、ConfigMapの定義にimmutableフィールドを追加して、イミュータブルなConfigMap を作成できます。
ConfigMapとPod
ConfigMapを参照して、ConfigMap内のデータを元にしてPod内のコンテナの設定をするPodのspecを書くことができます。このとき、PodとConfigMapは同じ名前空間 内に存在する必要があります。
以下に、ConfigMapの例を示します。単一の値を持つキーと、Configuration形式のデータ片のような値を持つキーがあります。
apiVersion : v1
kind : ConfigMap
metadata :
name : game-demo
data :
# プロパティーに似たキー。各キーは単純な値にマッピングされている
player_initial_lives : "3"
ui_properties_file_name : "user-interface.properties"
# ファイルに似たキー
game.properties : |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties : |
color.good=purple
color.bad=yellow
allow.textmode=true
ConfigMapを利用してPod内のコンテナを設定する方法には、次の4種類があります。
コンテナ内のコマンドと引数
環境変数をコンテナに渡す
読み取り専用のボリューム内にファイルを追加し、アプリケーションがそのファイルを読み取る
Kubernetes APIを使用してConfigMapを読み込むコードを書き、そのコードをPod内で実行する
これらのさまざまな方法は、利用するデータをモデル化するのに役立ちます。最初の3つの方法では、kubelet がPodのコンテナを起動する時にConfigMapのデータを使用します。
4番目の方法では、ConfigMapとそのデータを読み込むためのコードを自分自身で書く必要があります。しかし、Kubernetes APIを直接使用するため、アプリケーションはConfigMapがいつ変更されても更新イベントを受信でき、変更が発生したときにすぐに反応できます。この手法では、Kubernetes APIに直接アクセスすることで、別の名前空間にあるConfigMapにもアクセスできます。
以下に、Podを設定するためにgame-demoから値を使用するPodの例を示します。
apiVersion : v1
kind : Pod
metadata :
name : configmap-demo-pod
spec :
containers :
- name : demo
image : alpine
command : ["sleep" , "3600" ]
env :
# 環境変数を定義します。
- name : PLAYER_INITIAL_LIVES # ここではConfigMap内のキーの名前とは違い
# 大文字が使われていることに着目してください。
valueFrom :
configMapKeyRef :
name : game-demo # この値を取得するConfigMap。
key : player_initial_lives # 取得するキー。
- name : UI_PROPERTIES_FILE_NAME
valueFrom :
configMapKeyRef :
name : game-demo
key : ui_properties_file_name
volumeMounts :
- name : config
mountPath : "/config"
readOnly : true
volumes :
# Podレベルでボリュームを設定し、Pod内のコンテナにマウントします。
- name : config
configMap :
# マウントしたいConfigMapの名前を指定します。
name : game-demo
# ファイルとして作成するConfigMapのキーの配列
items :
- key : "game.properties"
path : "game.properties"
- key : "user-interface.properties"
path : "user-interface.properties"
ConfigMapは1行のプロパティの値と複数行のファイルに似た形式の値を区別しません。問題となるのは、Podや他のオブジェクトによる値の使用方法です。
この例では、ボリュームを定義して、demoコンテナの内部で/configにマウントしています。これにより、ConfigMap内には4つのキーがあるにもかかわらず、2つのファイル/config/game.propertiesおよび/config/user-interface.propertiesだけが作成されます。
これは、Podの定義がvolumesセクションでitemsという配列を指定しているためです。もしitemsの配列を完全に省略すれば、ConfigMap内の各キーがキーと同じ名前のファイルになり、4つのファイルが作成されます。
ConfigMapを使う
ConfigMapは、データボリュームとしてマウントできます。ConfigMapは、Podへ直接公開せずにシステムの他の部品として使うこともできます。たとえば、ConfigMapには、システムの他の一部が設定のために使用するデータを保存できます。
ConfigMapの最も一般的な使い方では、同じ名前空間にあるPod内で実行されているコンテナに設定を構成します。ConfigMapを独立して使用することもできます。
たとえば、ConfigMapに基づいて動作を調整するアドオン やオペレーター を見かけることがあるかもしれません。
ConfigMapをPodからファイルとして使う
ConfigMapをPod内のボリュームで使用するには、次のようにします。
ConfigMapを作成するか、既存のConfigMapを使用します。複数のPodから同じConfigMapを参照することもできます。
Podの定義を修正して、.spec.volumes[]以下にボリュームを追加します。ボリュームに任意の名前を付け、.spec.volumes[].configMap.nameフィールドにConfigMapオブジェクトへの参照を設定します。
ConfigMapが必要な各コンテナに.spec.containers[].volumeMounts[]を追加します。.spec.containers[].volumeMounts[].readOnly = trueを指定して、.spec.containers[].volumeMounts[].mountPathには、ConfigMapのデータを表示したい未使用のディレクトリ名を指定します。
イメージまたはコマンドラインを修正して、プログラムがそのディレクトリ内のファイルを読み込むように設定します。ConfigMapのdataマップ内の各キーが、mountPath以下のファイル名になります。
以下は、ボリューム内にConfigMapをマウントするPodの例です。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
readOnly : true
volumes :
- name : foo
configMap :
name : myconfigmap
使用したいそれぞれのConfigMapごとに、.spec.volumes内で参照する必要があります。
Pod内に複数のコンテナが存在する場合、各コンテナにそれぞれ別のvolumeMountsのブロックが必要ですが、.spec.volumesはConfigMapごとに1つしか必要ありません。
マウントしたConfigMapの自動的な更新
ボリューム内で現在使用中のConfigMapが更新されると、射影されたキーも最終的に(eventually)更新されます。kubeletは定期的な同期のたびにマウントされたConfigMapが新しいかどうか確認します。しかし、kubeletが現在のConfigMapの値を取得するときにはローカルキャッシュを使用します。キャッシュの種類は、KubeletConfiguration構造体 の中のConfigMapAndSecretChangeDetectionStrategyフィールドで設定可能です。ConfigMapは、監視(デフォルト)、ttlベース、またはすべてのリクエストを直接APIサーバーへ単純にリダイレクトする方法のいずれかによって伝搬されます。その結果、ConfigMapが更新された瞬間から、新しいキーがPodに射影されるまでの遅延の合計は、最長でkubeletの同期期間+キャッシュの伝搬遅延になります。ここで、キャッシュの伝搬遅延は選択したキャッシュの種類に依存します(監視の伝搬遅延、キャッシュのttl、または0に等しくなります)。
環境変数として使用されるConfigMapは自動的に更新されないため、ポッドを再起動する必要があります。
イミュータブルなConfigMap
FEATURE STATE: Kubernetes v1.19 [beta]
Kubernetesのベータ版の機能である イミュータブルなSecretおよびConfigMap は、個別のSecretやConfigMapをイミュータブルに設定するオプションを提供します。ConfigMapを広範に使用している(少なくとも数万のConfigMapがPodにマウントされている)クラスターでは、データの変更を防ぐことにより、以下のような利点が得られます。
アプリケーションの停止を引き起こす可能性のある予想外の(または望まない)変更を防ぐことができる
ConfigMapをイミュータブルにマークして監視を停止することにより、kube-apiserverへの負荷を大幅に削減し、クラスターの性能が向上する
この機能は、ImmutableEmphemeralVolumesフィーチャーゲート によって管理されます。immutableフィールドをtrueに設定することで、イミュータブルなConfigMapを作成できます。次に例を示します。
apiVersion : v1
kind : ConfigMap
metadata :
...
data :
...
immutable : true
一度ConfigMapがイミュータブルに設定されると、この変更を元に戻したり、dataまたはbinaryDataフィールドのコンテンツを変更することはできません 。ConfigMapの削除と再作成のみ可能です。既存のPodは削除されたConfigMapのマウントポイントを保持するため、こうしたPodは再作成することをおすすめします。
次の項目
7.3 - Secret
Secretとは、パスワードやトークン、キーなどの少量の機密データを含むオブジェクトのことです。
このような情報は、Secretを用いないとPod の定義やコンテナイメージ に直接記載することになってしまうかもしれません。
Secretを使用すれば、アプリケーションコードに機密データを含める必要がなくなります。
なぜなら、Secretは、それを使用するPodとは独立して作成することができ、
Podの作成、閲覧、編集といったワークフローの中でSecret(およびそのデータ)が漏洩する危険性が低くなるためです。
また、Kubernetesやクラスター内で動作するアプリケーションは、不揮発性ストレージに機密データを書き込まないようにするなど、Secretで追加の予防措置を取ることができます。
Secretsは、ConfigMaps に似ていますが、機密データを保持するために用います。
注意: KubernetesのSecretは、デフォルトでは、APIサーバーの基礎となるデータストア(etcd)に暗号化されずに保存されます。APIにアクセスできる人は誰でもSecretを取得または変更でき、etcdにアクセスできる人も同様です。
さらに、名前空間でPodを作成する権限を持つ人は、そのアクセスを使用して、その名前空間のあらゆるSecretを読むことができます。これには、Deploymentを作成する能力などの間接的なアクセスも含まれます。
Secretsを安全に使用するには、以下の手順を推奨します。
Secretsを安全に暗号化する
Secretsのデータの読み取りを制限するRBACルール の有効化または設定
適切な場合には、RBACなどのメカニズムを使用して、どの原則が新しいSecretの作成や既存のSecretの置き換えを許可されるかを制限します。
Secretの概要
Secretを使うには、PodはSecretを参照することが必要です。
PodがSecretを使う方法は3種類あります。
KubernetesのコントロールプレーンでもSecretsは使われています。例えば、bootstrap token Secrets は、ノード登録を自動化するための仕組みです。
Secretオブジェクトの名称は正当なDNSサブドメイン名 である必要があります。
シークレットの構成ファイルを作成するときに、dataおよび/またはstringDataフィールドを指定できます。dataフィールドとstringDataフィールドはオプションです。
dataフィールドのすべてのキーの値は、base64でエンコードされた文字列である必要があります。
base64文字列への変換が望ましくない場合は、代わりにstringDataフィールドを指定することを選択できます。これは任意の文字列を値として受け入れます。
dataとstringDataのキーは、英数字、-、_、または.で構成されている必要があります。
stringDataフィールドのすべてのキーと値のペアは、内部でdataフィールドにマージされます。
キーがdataフィールドとstringDataフィールドの両方に表示される場合、stringDataフィールドで指定された値が優先されます。
Secretの種類
Secretを作成するときは、Secrettypeフィールド、または特定の同等のkubectlコマンドラインフラグ(使用可能な場合)を使用して、その型を指定できます。
Secret型は、Secret dataのプログラムによる処理を容易にするために使用されます。
Kubernetesは、いくつかの一般的な使用シナリオに対応するいくつかの組み込み型を提供します。
これらの型は、実行される検証とKubernetesが課す制約の点で異なります。
Builtin Type
Usage
Opaquearbitrary user-defined data
kubernetes.io/service-account-tokenservice account token
kubernetes.io/dockercfgserialized ~/.dockercfg file
kubernetes.io/dockerconfigjsonserialized ~/.docker/config.json file
kubernetes.io/basic-authcredentials for basic authentication
kubernetes.io/ssh-authcredentials for SSH authentication
kubernetes.io/tlsdata for a TLS client or server
bootstrap.kubernetes.io/tokenbootstrap token data
Secretオブジェクトのtype値として空でない文字列を割り当てることにより、独自のSecret型を定義して使用できます。空の文字列はOpaque型として扱われます。Kubernetesは型名に制約を課しません。ただし、組み込み型の1つを使用している場合は、その型に定義されているすべての要件を満たす必要があります。
Opaque secrets
Opaqueは、Secret構成ファイルから省略された場合のデフォルトのSecret型です。
kubectlを使用してSecretを作成する場合、genericサブコマンドを使用してOpaqueSecret型を示します。 たとえば、次のコマンドは、Opaque型の空のSecretを作成します。
kubectl create secret generic empty-secret
kubectl get secret empty-secret
出力は次のようになります。
NAME TYPE DATA AGE
empty-secret Opaque 0 2m6s
DATA列には、Secretに保存されているデータ項目の数が表示されます。
この場合、0は空のSecretを作成したことを意味します。
Service account token Secrets
kubernetes.io/service-account-token型のSecretは、サービスアカウントを識別するトークンを格納するために使用されます。 このSecret型を使用する場合は、kubernetes.io/service-account.nameアノテーションが既存のサービスアカウント名に設定されていることを確認する必要があります。Kubernetesコントローラーは、kubernetes.io/service-account.uidアノテーションや実際のトークンコンテンツに設定されたdataフィールドのtokenキーなど、他のいくつかのフィールドに入力します。
apiVersion : v1
kind : Secret
metadata :
name : secret-sa-sample
annotations :
kubernetes.io/service-account.name : "sa-name"
type : kubernetes.io/service-account-token
data :
# You can include additional key value pairs as you do with Opaque Secrets
extra : YmFyCg==
Podを作成すると、Kubernetesはservice account Secretを自動的に作成し、このSecretを使用するようにPodを自動的に変更します。service account token Secretには、APIにアクセスするための資格情報が含まれています。
API証明の自動作成と使用は、必要に応じて無効にするか、上書きすることができます。 ただし、API Serverに安全にアクセスするだけの場合は、これが推奨されるワークフローです。
ServiceAccountの動作の詳細については、ServiceAccount のドキュメントを参照してください。
PodからServiceAccountを参照する方法については、PodautomountServiceAccountTokenフィールドとserviceAccountNameフィールドを確認することもできます。
Docker config Secrets
次のtype値のいずれかを使用して、イメージのDockerレジストリにアクセスするための資格情報を格納するSecretを作成できます。
kubernetes.io/dockercfgkubernetes.io/dockerconfigjson
kubernetes.io/dockercfg型は、Dockerコマンドラインを構成するためのレガシー形式であるシリアル化された~/.dockercfgを保存するために予約されています。
このSecret型を使用する場合は、Secretのdataフィールドに.dockercfgキーが含まれていることを確認する必要があります。このキーの値は、base64形式でエンコードされた~/.dockercfgファイルの内容です。
kubernetes.io/dockerconfigjson型は、~/.dockercfgの新しいフォーマットである~/.docker/config.jsonファイルと同じフォーマットルールに従うシリアル化されたJSONを保存するために設計されています。
このSecret型を使用する場合、Secretオブジェクトのdataフィールドには.dockerconfigjsonキーが含まれている必要があります。このキーでは、~/.docker/config.jsonファイルのコンテンツがbase64でエンコードされた文字列として提供されます。
以下は、kubernetes.io/dockercfg型のSecretの例です。
apiVersion : v1
kind : Secret
name : secret-dockercfg
type : kubernetes.io/dockercfg
data :
.dockercfg : |
"<base64 encoded ~/.dockercfg file>"
備考: base64エンコーディングを実行したくない場合は、代わりにstringDataフィールドを使用することを選択できます。
マニフェストを使用してこれらの型のSecretを作成すると、APIserverは期待されるキーがdataフィールドに存在するかどうかを確認し、提供された値を有効なJSONとして解析できるかどうかを確認します。APIサーバーは、JSONが実際にDocker configファイルであるかどうかを検証しません。
Docker configファイルがない場合、またはkubectlを使用してDockerレジストリSecretを作成する場合は、次の操作を実行できます。
kubectl create secret docker-registry secret-tiger-docker \
= tiger \
= pass113 \
= tiger@acme.com \
= my-registry.example:5000
このコマンドは、kubernetes.io/dockerconfigjson型のSecretを作成します。
dataフィールドから.dockerconfigjsonコンテンツをダンプすると、その場で作成された有効なDocker configである次のJSONコンテンツを取得します。
{
"apiVersion" : "v1" ,
"data" : {
".dockerconfigjson" : "eyJhdXRocyI6eyJteS1yZWdpc3RyeTo1MDAwIjp7InVzZXJuYW1lIjoidGlnZXIiLCJwYXNzd29yZCI6InBhc3MxMTMiLCJlbWFpbCI6InRpZ2VyQGFjbWUuY29tIiwiYXV0aCI6ImRHbG5aWEk2Y0dGemN6RXhNdz09In19fQ=="
},
"kind" : "Secret" ,
"metadata" : {
"creationTimestamp" : "2021-07-01T07:30:59Z" ,
"name" : "secret-tiger-docker" ,
"namespace" : "default" ,
"resourceVersion" : "566718" ,
"uid" : "e15c1d7b-9071-4100-8681-f3a7a2ce89ca"
},
"type" : "kubernetes.io/dockerconfigjson"
}
Basic authentication Secret
kubernetes.io/basic-auth型は、Basic認証に必要な認証を保存するために提供されています。このSecret型を使用する場合、Secretのdataフィールドには次の2つのキーが含まれている必要があります。
username: 認証のためのユーザー名password: 認証のためのパスワードかトークン
上記の2つのキーの両方の値は、base64でエンコードされた文字列です。もちろん、Secretの作成にstringDataを使用してクリアテキストコンテンツを提供することもできます。
次のYAMLは、Basic authentication Secretの設定例です。
apiVersion : v1
kind : Secret
metadata :
name : secret-basic-auth
type : kubernetes.io/basic-auth
stringData :
username : admin
password : t0p-Secret
Basic認証Secret型は、ユーザーの便宜のためにのみ提供されています。Basic認証に使用される資格情報のOpaqueを作成できます。
ただし、組み込みのSecret型を使用すると、認証の形式を統一するのに役立ち、APIserverは必要なキーがSecret configurationで提供されているかどうかを確認します。
SSH authentication secrets
組み込みのタイプkubernetes.io/ssh-authは、SSH認証で使用されるデータを保存するために提供されています。このSecret型を使用する場合、使用するSSH認証としてdata(またはstringData)フィールドにssh-privatekeyキーと値のペアを指定する必要があります。
次のYAMLはSSH authentication Secretの設定例です:
apiVersion : v1
kind : Secret
metadata :
name : secret-ssh-auth
type : kubernetes.io/ssh-auth
data :
# the data is abbreviated in this example
ssh-privatekey : |
MIIEpQIBAAKCAQEAulqb/Y ...
SSH authentication Secret型は、ユーザーの便宜のためにのみ提供されています。
SSH認証に使用される資格情報のOpaqueを作成できます。
ただし、組み込みのSecret型を使用すると、認証の形式を統一するのに役立ち、APIserverは必要なキーがSecret configurationで提供されているかどうかを確認します。
TLS secrets
Kubernetesは、TLSに通常使用される証明書とそれに関連付けられたキーを保存するための組み込みのSecret型kubernetes.io/tlsを提供します。このデータは、主にIngressリソースのTLS terminationで使用されますが、他のリソースで使用されることも、ワークロードによって直接使用されることもあります。
このSecret型を使用する場合、APIサーバーは各キーの値を実際には検証しませんが、tls.keyおよびtls.crtキーをSecret configurationのdata(またはstringData)フィールドに指定する必要があります。
次のYAMLはTLS Secretの設定例です:
apiVersion : v1
kind : Secret
metadata :
name : secret-tls
type : kubernetes.io/tls
data :
# the data is abbreviated in this example
tls.crt : |
MIIC2DCCAcCgAwIBAgIBATANBgkqh ...
tls.key : |
MIIEpgIBAAKCAQEA7yn3bRHQ5FHMQ ...
TLS Secret型は、ユーザーの便宜のために提供されています。 TLSサーバーやクライアントに使用される資格情報のOpaqueを作成できます。ただし、組み込みのSecret型を使用すると、プロジェクトでSecret形式の一貫性を確保できます。APIserverは、必要なキーがSecret configurationで提供されているかどうかを確認します。
kubectlを使用してTLS Secretを作成する場合、次の例に示すようにtlsサブコマンドを使用できます。
kubectl create secret tls my-tls-secret \
= path/to/cert/file \
= path/to/key/file
公開鍵と秘密鍵のペアは、事前に存在している必要があります。--certの公開鍵証明書は.PEMエンコード(Base64エンコードDER形式)であり、--keyの指定された秘密鍵と一致する必要があります。
秘密鍵は、一般にPEM秘密鍵形式と呼ばれる暗号化されていない形式である必要があります。どちらの場合も、PEMの最初と最後の行(たとえば、-------- BEGIN CERTIFICATE -----と------- END CERTIFICATE ----)は含まれていません 。
Bootstrap token Secrets
Bootstrap token Secretは、Secretのtypeをbootstrap.kubernetes.io/tokenに明示的に指定することで作成できます。このタイプのSecretは、ノードのブートストラッププロセス中に使用されるトークン用に設計されています。よく知られているConfigMapに署名するために使用されるトークンを格納します。
Bootstrap token Secretは通常、kube-systemnamespaceで作成されbootstrap-token-<token-id>の形式で名前が付けられます。ここで<token-id>はトークンIDの6文字の文字列です。
Kubernetesマニフェストとして、Bootstrap token Secretは次のようになります。
apiVersion : v1
kind : Secret
metadata :
name : bootstrap-token-5emitj
namespace : kube-system
type : bootstrap.kubernetes.io/token
data :
auth-extra-groups : c3lzdGVtOmJvb3RzdHJhcHBlcnM6a3ViZWFkbTpkZWZhdWx0LW5vZGUtdG9rZW4=
expiration : MjAyMC0wOS0xM1QwNDozOToxMFo=
token-id : NWVtaXRq
token-secret : a3E0Z2lodnN6emduMXAwcg==
usage-bootstrap-authentication : dHJ1ZQ==
usage-bootstrap-signing : dHJ1ZQ==
Bootstrap type Secretには、dataで指定された次のキーがあります。
token_id:トークン識別子としてのランダムな6文字の文字列。必須。token-secret:実際のtoken secretとしてのランダムな16文字の文字列。必須。description:トークンの使用目的を説明する人間が読める文字列。オプション。expiration:トークンの有効期限を指定するRFC3339 を使用した絶対UTC時間。オプション。usage-bootstrap-<usage>:Bootstrap tokenの追加の使用法を示すブールフラグ。auth-extra-groups:system:bootstrappersグループに加えて認証されるグループ名のコンマ区切りのリスト。
上記のYAMLは、値がすべてbase64でエンコードされた文字列であるため、分かりづらく見えるかもしれません。実際には、次のYAMLを使用して同一のSecretを作成できます。
apiVersion : v1
kind : Secret
metadata :
# Note how the Secret is named
name : bootstrap-token-5emitj
# A bootstrap token Secret usually resides in the kube-system namespace
namespace : kube-system
type : bootstrap.kubernetes.io/token
stringData :
auth-extra-groups : "system:bootstrappers:kubeadm:default-node-token"
expiration : "2020-09-13T04:39:10Z"
# This token ID is used in the name
token-id : "5emitj"
token-secret : "kq4gihvszzgn1p0r"
# This token can be used for authentication
usage-bootstrap-authentication : "true"
# and it can be used for signing
usage-bootstrap-signing : "true"
Secretの作成
Secretを作成するには、いくつかのオプションがあります。
Secretの編集
既存のSecretは次のコマンドで編集することができます。
kubectl edit secrets mysecret
デフォルトに設定されたエディターが開かれ、dataフィールドのBase64でエンコードされたSecretの値を編集することができます。
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion : v1
data :
username : YWRtaW4=
password : MWYyZDFlMmU2N2Rm
kind : Secret
metadata :
annotations :
kubectl.kubernetes.io/last-applied-configuration : { ... }
creationTimestamp : 2016-01-22T18:41:56Z
name : mysecret
namespace : default
resourceVersion : "164619"
uid : cfee02d6-c137-11e5-8d73-42010af00002
type : Opaque
Secretの使用
Podの中のコンテナがSecretを使うために、データボリュームとしてマウントしたり、環境変数 として値を参照できるようにできます。
Secretは直接Podが参照できるようにはされず、システムの別の部分に使われることもあります。
例えば、Secretはあなたに代わってシステムの他の部分が外部のシステムとやりとりするために使う機密情報を保持することもあります。
SecretをファイルとしてPodから利用する
PodのボリュームとしてSecretを使うには、
Secretを作成するか既存のものを使用します。複数のPodが同一のSecretを参照することができます。
ボリュームを追加するため、Podの定義の.spec.volumes[]以下を書き換えます。ボリュームに命名し、.spec.volumes[].secret.secretNameフィールドはSecretオブジェクトの名称と同一にします。
Secretを必要とするそれぞれのコンテナに.spec.containers[].volumeMounts[]を追加します。.spec.containers[].volumeMounts[].readOnly = trueを指定して.spec.containers[].volumeMounts[].mountPathをSecretをマウントする未使用のディレクトリ名にします。
イメージやコマンドラインを変更し、プログラムがそのディレクトリを参照するようにします。連想配列dataのキーはmountPath以下のファイル名になります。
これはSecretをボリュームとしてマウントするPodの例です。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
readOnly : true
volumes :
- name : foo
secret :
secretName : mysecret
使用したいSecretはそれぞれ.spec.volumesの中で参照されている必要があります。
Podに複数のコンテナがある場合、それぞれのコンテナがvolumeMountsブロックを必要としますが、.spec.volumesはSecret1つあたり1つで十分です。
多くのファイルを一つのSecretにまとめることも、多くのSecretを使うことも、便利な方を採ることができます。
Secretのキーの特定のパスへの割り当て
Secretのキーが割り当てられるパスを制御することができます。
それぞれのキーがターゲットとするパスは.spec.volumes[].secret.itemsフィールドによって指定できます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
readOnly : true
volumes :
- name : foo
secret :
secretName : mysecret
items :
- key : username
path : my-group/my-username
次のような挙動をします。
usernameは/etc/foo/usernameの代わりに/etc/foo/my-group/my-usernameの元に格納されます。passwordは現れません。
.spec.volumes[].secret.itemsが使われるときは、itemsの中で指定されたキーのみが現れます。
Secretの中の全てのキーを使用したい場合は、itemsフィールドに全て列挙する必要があります。
列挙されたキーは対応するSecretに存在する必要があり、そうでなければボリュームは生成されません。
Secretファイルのパーミッション
単一のSecretキーに対して、ファイルアクセスパーミッションビットを指定することができます。
パーミッションを指定しない場合、デフォルトで0644が使われます。
Secretボリューム全体のデフォルトモードを指定し、必要に応じてキー単位で上書きすることもできます。
例えば、次のようにしてデフォルトモードを指定できます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
volumes :
- name : foo
secret :
secretName : mysecret
defaultMode : 0400
Secretは/etc/fooにマウントされ、Secretボリュームが生成する全てのファイルはパーミッション0400に設定されます。
JSONの仕様は8進数の記述に対応していないため、パーミッション0400を示す値として256を使用することに注意が必要です。
Podの定義にJSONではなくYAMLを使う場合は、パーミッションを指定するためにより自然な8進表記を使うことができます。
kubectl execを使ってPodに入るときは、期待したファイルモードを知るためにシンボリックリンクを辿る必要があることに注意してください。
例として、PodのSecretのファイルモードを確認します。
kubectl exec mypod -it sh
cd /etc/foo
ls -l
出力は次のようになります。
total 0
lrwxrwxrwx 1 root root 15 May 18 00:18 password -> ..data/password
lrwxrwxrwx 1 root root 15 May 18 00:18 username -> ..data/username
正しいファイルモードを知るためにシンボリックリンクを辿ります。
cd /etc/foo/..data
ls -l
出力は次のようになります。
total 8
-r-------- 1 root root 12 May 18 00:18 password
-r-------- 1 root root 5 May 18 00:18 username
前の例のようにマッピングを使い、ファイルごとに異なるパーミッションを指定することができます。
apiVersion : v1
kind : Pod
metadata :
name : mypod
spec :
containers :
- name : mypod
image : redis
volumeMounts :
- name : foo
mountPath : "/etc/foo"
volumes :
- name : foo
secret :
secretName : mysecret
items :
- key : username
path : my-group/my-username
mode : 0777
この例では、ファイル/etc/foo/my-group/my-usernameのパーミッションは0777になります。
JSONを使う場合は、JSONの制約により10進表記の511と記述する必要があります。
後で参照する場合、このパーミッションの値は10進表記で表示されることがあることに注意してください。
Secretの値のボリュームによる利用
Secretのボリュームがマウントされたコンテナからは、Secretのキーはファイル名として、Secretの値はBase64デコードされ、それらのファイルに格納されます。
上記の例のコンテナの中でコマンドを実行した結果を示します。
出力は次のようになります。
username
password
出力は次のようになります。
admin
出力は次のようになります。
1f2d1e2e67df
コンテナ内のプログラムはファイルからSecretの内容を読み取る責務を持ちます。
マウントされたSecretの自動更新
ボリュームとして使用されているSecretが更新されると、やがて割り当てられたキーも同様に更新されます。
kubeletは定期的な同期のたびにマウントされたSecretが新しいかどうかを確認します。
しかしながら、kubeletはSecretの現在の値の取得にローカルキャッシュを使用します。
このキャッシュはKubeletConfiguration struct 内のConfigMapAndSecretChangeDetectionStrategyフィールドによって設定可能です。
Secretはwatch(デフォルト)、TTLベース、単に全てのリクエストをAPIサーバーへリダイレクトすることのいずれかによって伝搬します。
結果として、Secretが更新された時点からPodに新しいキーが反映されるまでの遅延時間の合計は、kubeletの同期間隔 + キャッシュの伝搬遅延となります。
キャッシュの遅延は、キャッシュの種別により、それぞれwatchの伝搬遅延、キャッシュのTTL、0になります。
備考: Secretを
subPath を指定してボリュームにマウントしているコンテナには、Secretの更新が反映されません。
Secretを環境変数として使用する
SecretをPodの環境変数 として使用するには、
Secretを作成するか既存のものを使います。複数のPodが同一のSecretを参照することができます。
Podの定義を変更し、Secretを使用したいコンテナごとにSecretのキーと割り当てたい環境変数を指定します。Secretキーを利用する環境変数はenv[].valueFrom.secretKeyRefにSecretの名前とキーを指定すべきです。
イメージまたはコマンドライン(もしくはその両方)を変更し、プログラムが指定した環境変数を参照するようにします。
Secretを環境変数で参照するPodの例を示します。
apiVersion : v1
kind : Pod
metadata :
name : secret-env-pod
spec :
containers :
- name : mycontainer
image : redis
env :
- name : SECRET_USERNAME
valueFrom :
secretKeyRef :
name : mysecret
key : username
- name : SECRET_PASSWORD
valueFrom :
secretKeyRef :
name : mysecret
key : password
restartPolicy : Never
環境変数からのSecretの値の利用
Secretを環境変数として利用するコンテナの内部では、Secretのキーは一般の環境変数名として現れ、値はBase64デコードされた状態で保持されます。
上記の例のコンテナの内部でコマンドを実行した結果の例を示します。
出力は次のようになります。
admin
出力は次のようになります。
1f2d1e2e67df
Immutable Secrets
FEATURE STATE: Kubernetes v1.19 [beta]
Kubernetesベータ機能ImmutableSecrets and ConfigMaps は、個々のSecretsとConfigMapsをimutableとして設定するオプションを提供します。Secret(少なくとも数万の、SecretからPodへの一意のマウント)を広範囲に使用するクラスターの場合、データの変更を防ぐことには次の利点があります。
アプリケーションの停止を引き起こす可能性のある偶発的な(または不要な)更新からユーザーを保護します
imutableとしてマークされたSecretのウォッチを閉じることで、kube-apiserverの負荷を大幅に削減することができ、クラスターのパフォーマンスを向上させます。
この機能は、ImmutableEphemeralVolumesfeature gate によって制御されます。これは、v1.19以降デフォルトで有効になっています。immutableフィールドをtrueに設定することで、imutableのSecretを作成できます。例えば、
apiVersion : v1
kind : Secret
metadata :
...
data :
...
immutable : true
備考: SecretまたはConfigMapがimutableとしてマークされると、この変更を元に戻したり、dataフィールドの内容を変更したりすることはできません 。Secretを削除して再作成することしかできません。
既存のPodは、削除されたSecretへのマウントポイントを維持します。これらのPodを再作成することをお勧めします。
imagePullSecretsを使用する
imagePullSecretsフィールドは同一のネームスペース内のSecretの参照のリストです。
kubeletにDockerやその他のイメージレジストリのパスワードを渡すために、imagePullSecretsにそれを含むSecretを指定することができます。
kubeletはこの情報をPodのためにプライベートイメージをpullするために使います。
imagePullSecretsの詳細はPodSpec API を参照してください。
imagePullSecretを手動で指定する
ImagePullSecretsの指定の方法はコンテナイメージのドキュメント に記載されています。
imagePullSecretsが自動的にアタッチされるようにする
imagePullSecretsを手動で作成し、サービスアカウントから参照することができます。
サービスアカウントが指定されるまたはデフォルトでサービスアカウントが設定されたPodは、サービスアカウントが持つimagePullSecretsフィールドを得ます。
詳細な手順の説明はサービスアカウントへのImagePullSecretsの追加 を参照してください。
手動で作成されたSecretの自動的なマウント
手動で作成されたSecret(例えばGitHubアカウントへのアクセスに使うトークンを含む)はサービスアカウントを基に自動的にアタッチすることができます。
詳細な説明はPodPresetを使ったPodへの情報の注入 を参照してください。
詳細
制限事項
Secretボリュームは指定されたオブジェクト参照が実際に存在するSecretオブジェクトを指していることを保証するため検証されます。
そのため、Secretはそれを必要とするPodよりも先に作成する必要があります。
Secretリソースはnamespace に属します。
Secretは同一のnamespaceに属するPodからのみ参照することができます。
各Secretは1MiBの容量制限があります。
これはAPIサーバーやkubeletのメモリーを枯渇するような非常に大きなSecretを作成することを避けるためです。
しかしながら、小さなSecretを多数作成することも同様にメモリーを枯渇させます。
Secretに起因するメモリー使用量をより網羅的に制限することは、将来計画されています。
kubeletがPodに対してSecretを使用するとき、APIサーバーから取得されたSecretのみをサポートします。
これにはkubectlを利用して、またはレプリケーションコントローラーによって間接的に作成されたPodが含まれます。
kubeletの--manifest-urlフラグ、--configフラグ、またはREST APIにより生成されたPodは含まれません
(これらはPodを生成するための一般的な方法ではありません)。
環境変数として使われるSecretは任意と指定されていない限り、それを使用するPodよりも先に作成される必要があります。
存在しないSecretへの参照はPodの起動を妨げます。
Secretに存在しないキーへの参照(secretKeyRefフィールド)はPodの起動を妨げます。
SecretをenvFromフィールドによって環境変数へ設定する場合、環境変数の名称として不適切なキーは飛ばされます。
Podは起動することを認められます。
このとき、reasonがInvalidVariableNamesであるイベントが発生し、メッセージに飛ばされたキーのリストが含まれます。
この例では、Podは2つの不適切なキー1badkeyと2alsobadを含むdefault/mysecretを参照しています。
出力は次のようになります。
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON
0s 0s 1 dapi-test-pod Pod Warning InvalidEnvironmentVariableNames kubelet, 127.0.0.1 Keys [1badkey, 2alsobad] from the EnvFrom secret default/mysecret were skipped since they are considered invalid environment variable names.
SecretとPodの相互作用
Kubernetes APIがコールされてPodが生成されるとき、参照するSecretの存在は確認されません。
Podがスケジューリングされると、kubeletはSecretの値を取得しようとします。
Secretが存在しない、または一時的にAPIサーバーへの接続が途絶えたことにより取得できない場合、kubeletは定期的にリトライします。
kubeletはPodがまだ起動できない理由に関するイベントを報告します。
Secretが取得されると、kubeletはそのボリュームを作成しマウントします。
Podのボリュームが全てマウントされるまでは、Podのコンテナは起動することはありません。
ユースケース
ユースケース: コンテナの環境変数として
Secretの作成
apiVersion : v1
kind : Secret
metadata :
name : mysecret
type : Opaque
data :
USER_NAME : YWRtaW4=
PASSWORD : MWYyZDFlMmU2N2Rm
kubectl apply -f mysecret.yaml
envFromを使ってSecretの全てのデータをコンテナの環境変数として定義します。
SecretのキーはPod内の環境変数の名称になります。
apiVersion : v1
kind : Pod
metadata :
name : secret-test-pod
spec :
containers :
- name : test-container
image : registry.k8s.io/busybox
command : [ "/bin/sh" , "-c" , "env" ]
envFrom :
- secretRef :
name : mysecret
restartPolicy : Never
ユースケース: SSH鍵を持つPod
SSH鍵を含むSecretを作成します。
kubectl create secret generic ssh-key-secret --from-file= ssh-privatekey= /path/to/.ssh/id_rsa --from-file= ssh-publickey= /path/to/.ssh/id_rsa.pub
出力は次のようになります。
secret "ssh-key-secret" created
SSH鍵を含むsecretGeneratorフィールドを持つkustomization.yamlを作成することもできます。
注意: 自身のSSH鍵を送る前に慎重に検討してください。クラスターの他のユーザーがSecretにアクセスできる可能性があります。
Kubernetesクラスターを共有しているユーザー全員がアクセスできるようにサービスアカウントを使用し、ユーザーが安全でない状態になったらアカウントを無効化することができます。
SSH鍵のSecretを参照し、ボリュームとして使用するPodを作成することができます。
apiVersion : v1
kind : Pod
metadata :
name : secret-test-pod
labels :
name : secret-test
spec :
volumes :
- name : secret-volume
secret :
secretName : ssh-key-secret
containers :
- name : ssh-test-container
image : mySshImage
volumeMounts :
- name : secret-volume
readOnly : true
mountPath : "/etc/secret-volume"
コンテナのコマンドを実行するときは、下記のパスにて鍵が利用可能です。
/etc/secret-volume/ssh-publickey
/etc/secret-volume/ssh-privatekey
コンテナはSecretのデータをSSH接続を確立するために使用することができます。
ユースケース: 本番、テスト用の認証情報を持つPod
あるPodは本番の認証情報のSecretを使用し、別のPodはテスト環境の認証情報のSecretを使用する例を示します。
secretGeneratorフィールドを持つkustomization.yamlを作成するか、kubectl create secretを実行します。
kubectl create secret generic prod-db-secret --from-literal= username = produser --from-literal= password = Y4nys7f11
出力は次のようになります。
secret "prod-db-secret" created
kubectl create secret generic test-db-secret --from-literal= username = testuser --from-literal= password = iluvtests
出力は次のようになります。
secret "test-db-secret" created
備考: $、\、*、=、!のような特殊文字はシェル に解釈されるので、エスケープする必要があります。
ほとんどのシェルではパスワードをエスケープする最も簡単な方法はシングルクォート(')で囲むことです。
例えば、実際のパスワードがS!B\*d$zDsb=だとすると、実行すべきコマンドは下記のようになります。
kubectl create secret generic dev-db-secret --from-literal= username = devuser --from-literal= password = 'S!B\*d$zDsb='
--from-fileによってファイルを指定する場合は、そのパスワードに含まれる特殊文字をエスケープする必要はありません。
Podを作成します。
cat <<EOF > pod.yaml
apiVersion: v1
kind: List
items:
- kind: Pod
apiVersion: v1
metadata:
name: prod-db-client-pod
labels:
name: prod-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: prod-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
- kind: Pod
apiVersion: v1
metadata:
name: test-db-client-pod
labels:
name: test-db-client
spec:
volumes:
- name: secret-volume
secret:
secretName: test-db-secret
containers:
- name: db-client-container
image: myClientImage
volumeMounts:
- name: secret-volume
readOnly: true
mountPath: "/etc/secret-volume"
EOF
同じkustomization.yamlにPodを追記します。
cat <<EOF >> kustomization.yaml
resources:
- pod.yaml
EOF
下記のコマンドを実行して、APIサーバーにこれらのオブジェクト群を適用します。
両方のコンテナはそれぞれのファイルシステムに下記に示すファイルを持ちます。ファイルの値はそれぞれのコンテナの環境ごとに異なります。
/etc/secret-volume/username
/etc/secret-volume/password
2つのPodの仕様の差分は1つのフィールドのみである点に留意してください。
これは共通のPodテンプレートから異なる能力を持つPodを作成することを容易にします。
2つのサービスアカウントを使用すると、ベースのPod仕様をさらに単純にすることができます。
prod-userとprod-db-secrettest-userとtest-db-secret
簡略化されたPod仕様は次のようになります。
apiVersion : v1
kind : Pod
metadata :
name : prod-db-client-pod
labels :
name : prod-db-client
spec :
serviceAccount : prod-db-client
containers :
- name : db-client-container
image : myClientImage
ユースケース: Secretボリューム内のdotfile
キーをドットから始めることで、データを「隠す」ことができます。
このキーはdotfileまたは「隠し」ファイルを示します。例えば、次のSecretはsecret-volumeボリュームにマウントされます。
apiVersion : v1
kind : Secret
metadata :
name : dotfile-secret
data :
.secret-file : dmFsdWUtMg0KDQo=
---
apiVersion : v1
kind : Pod
metadata :
name : secret-dotfiles-pod
spec :
volumes :
- name : secret-volume
secret :
secretName : dotfile-secret
containers :
- name : dotfile-test-container
image : registry.k8s.io/busybox
command :
- ls
- "-l"
- "/etc/secret-volume"
volumeMounts :
- name : secret-volume
readOnly : true
mountPath : "/etc/secret-volume"
このボリュームは.secret-fileという単一のファイルを含み、dotfile-test-containerはこのファイルを/etc/secret-volume/.secret-fileのパスに持ちます。
備考: ドットから始まるファイルはls -lの出力では隠されるため、ディレクトリの内容を参照するときにはls -laを使わなければなりません。
ユースケース: Podの中の単一コンテナのみが参照できるSecret
HTTPリクエストを扱い、複雑なビジネスロジックを処理し、メッセージにHMACによる認証コードを付与する必要のあるプログラムを考えます。
複雑なアプリケーションロジックを持つため、サーバーにリモートのファイルを読み出せる未知の脆弱性がある可能性があり、この脆弱性は攻撃者に秘密鍵を晒してしまいます。
このプログラムは2つのコンテナに含まれる2つのプロセスへと分割することができます。
フロントエンドのコンテナはユーザーとのやりとりやビジネスロジックを扱い、秘密鍵を参照することはできません。
署名コンテナは秘密鍵を参照することができて、単にフロントエンドからの署名リクエストに応答します。例えば、localhostの通信によって行います。
この分割する手法によって、攻撃者はアプリケーションサーバーを騙して任意の処理を実行させる必要があるため、ファイルの内容を読み出すより困難になります。
ベストプラクティス
Secret APIを使用するクライアント
Secret APIとやりとりするアプリケーションをデプロイするときには、RBAC のような認可ポリシー を使用して、アクセスを制限すべきです。
Secretは様々な種類の重要な値を保持することが多く、サービスアカウントのトークンのようにKubernetes内部や、外部のシステムで昇格できるものも多くあります。個々のアプリケーションが、Secretの能力について推論することができたとしても、同じネームスペースの別のアプリケーションがその推定を覆すこともあります。
これらの理由により、ネームスペース内のSecretに対するwatchやlistリクエストはかなり強力な能力であり、避けるべきです。Secretのリストを取得することはクライアントにネームスペース内の全てのSecretの値を調べさせることを認めるからです。クラスター内の全てのSecretに対するwatch、list権限は最も特権的な、システムレベルのコンポーネントに限って認めるべきです。
Secret APIへのアクセスが必要なアプリケーションは、必要なSecretに対するgetリクエストを発行すべきです。管理者は全てのSecretに対するアクセスは制限しつつ、アプリケーションが必要とする個々のインスタンスに対するアクセス許可 を与えることができます。
getリクエストの繰り返しに対するパフォーマンスを向上するために、クライアントはSecretを参照するリソースを設計し、それをwatchして、参照が変更されたときにSecretを再度リクエストすることができます。加えて、個々のリソースをwatchすることのできる"bulk watch" API が提案されており、将来のKubernetesリリースにて利用可能になる可能性があります。
セキュリティ特性
保護
Secretはそれを使用するPodとは独立に作成されるので、Podを作ったり、参照したり、編集したりするワークフローにおいてSecretが晒されるリスクは軽減されています。
システムは、可能であればSecretの内容をディスクに書き込まないような、Secretについて追加の考慮も行っています。
Secretはノード上のPodが必要とした場合のみ送られます。
kubeletはSecretがディスクストレージに書き込まれないよう、tmpfsに保存します。
Secretを必要とするPodが削除されると、kubeletはSecretのローカルコピーも同様に削除します。
同一のノードにいくつかのPodに対する複数のSecretが存在することもあります。
しかし、コンテナから参照できるのはPodが要求したSecretのみです。
そのため、あるPodが他のPodのためのSecretにアクセスすることはできません。
Podに複数のコンテナが含まれることもあります。しかし、Podの各コンテナはコンテナ内からSecretを参照するためにvolumeMountsによってSecretボリュームを要求する必要があります。
これはPodレベルでのセキュリティ分離 を実装するのに便利です。
ほとんどのKubernetesディストリビューションにおいては、ユーザーとAPIサーバー間やAPIサーバーからkubelet間の通信はSSL/TLSで保護されています。
そのような経路で伝送される場合、Secretは保護されています。
FEATURE STATE: Kubernetes v1.13 [beta]
保存データの暗号化 を有効にして、Secretがetcd に平文で保存されないようにすることができます。
リスク
APIサーバーでは、機密情報はetcd に保存されます。
そのため、
管理者はクラスターデータの保存データの暗号化を有効にすべきです(v1.13以降が必要)。
管理者はetcdへのアクセスを管理ユーザに限定すべきです。
管理者はetcdで使用していたディスクを使用しなくなったときにはそれをワイプするか完全消去したくなるでしょう。
クラスターの中でetcdが動いている場合、管理者はetcdのピアツーピア通信がSSL/TLSを利用していることを確認すべきです。
Secretをマニフェストファイル(JSONまたはYAML)を介して設定する場合、それはBase64エンコードされた機密情報を含んでいるので、ファイルを共有したりソースリポジトリに入れることは秘密が侵害されることを意味します。Base64エンコーディングは暗号化手段では なく 、平文と同様であると判断すべきです。
アプリケーションはボリュームからSecretの値を読み取った後も、その値を保護する必要があります。例えば意図せずログに出力する、信用できない相手に送信するようなことがないようにです。
Secretを利用するPodを作成できるユーザーはSecretの値を見ることができます。たとえAPIサーバーのポリシーがユーザーにSecretの読み取りを許可していなくても、ユーザーはSecretを晒すPodを実行することができます。
現在、任意のノードでルート権限を持つ人は誰でも、kubeletに偽装することで 任意の SecretをAPIサーバーから読み取ることができます。
単一のノードのルート権限を不正に取得された場合の影響を抑えるため、実際に必要としているノードに対してのみSecretを送る機能が計画されています。
次の項目
7.4 - Liveness、ReadinessおよびStartup Probe
Kubernetesは様々な種類のProbeがあります。
Liveness Probe
コンテナの再起動を判断するためにLiveness Probeを使用します。
例えば、Liveness Probeはアプリケーションは起動しているが、処理が継続できないデッドロックを検知することができます。
コンテナがLiveness Probeを繰り返し失敗するとkubeletはコンテナを再起動します。
Liveness ProbeはReadiness Probeの成功を待ちません。Liveness Probeの実行を待つためには、initialDelaySecondsを定義するか、Startup Probe を使用してください。
Readiness Probe
Readiness Probeはコンテナがトラフィックを受け入れる準備ができたかを決定します。ネットワーク接続の確立、ファイルの読み込み、キャッシュのウォームアップなどの時間のかかる初期タスクを実行するアプリケーションを待つ場合に有用です。
Readiness Probeが失敗状態を返す場合、KubernetesはそのPodをすべての一致するサービスエンドポイントから取り除きます。
Readiness Probeはコンテナのライフサイクル全体にわたって実行されます。
Startup Probe
Startup Probeはコンテナ内のアプリケーションが起動されたかどうかを検証します。起動が遅いコンテナに対して起動されたかどうかチェックを取り入れるために使用され、kubeletによって起動や実行する前に終了されるのを防ぎます。
Startup Probeが設定された場合、成功するまでLiveness ProbeとReadiness Probeのチェックを無効にします。
定期的に実行されるReadiness Probeとは異なり、Startup Probeは起動時のみ実行されます。
7.5 - コンテナのリソース管理
Pod を指定する際に、コンテナ が必要とする各リソースの量をオプションで指定することができます。
指定する最も一般的なリソースはCPUとメモリ(RAM)ですが、他にもあります。
Pod内のコンテナのリソース要求 を指定すると、スケジューラはこの情報を使用して、どのNodeにPodを配置するかを決定します。コンテナに制限 ソースを指定すると、kubeletはその制限を適用し、実行中のコンテナが設定した制限を超えてリソースを使用することができないようにします。また、kubeletは、少なくともそのシステムリソースのうち、要求 の量を、そのコンテナが使用するために特別に確保します。
要求と制限
Podが動作しているNodeに利用可能なリソースが十分にある場合、そのリソースの要求が指定するよりも多くのリソースをコンテナが使用することが許可されます
ただし、コンテナはそのリソースの制限を超えて使用することはできません。
たとえば、コンテナに256MiBのメモリー要求を設定し、そのコンテナが8GiBのメモリーを持つNodeにスケジュールされたPod内に存在し、他のPodが存在しない場合、コンテナはより多くのRAMを使用しようとする可能性があります。
そのコンテナに4GiBのメモリー制限を設定すると、kubelet(およびコンテナランタイム ) が制限を適用します。ランタイムは、コンテナが設定済みのリソース制限を超えて使用するのを防ぎます。例えば、コンテナ内のプロセスが、許容量を超えるメモリを消費しようとすると、システムカーネルは、メモリ不足(OOM)エラーで、割り当てを試みたプロセスを終了します。
制限は、違反が検出されるとシステムが介入するように事後的に、またはコンテナが制限を超えないようにシステムが防ぐように強制的に、実装できます。
異なるランタイムは、同じ制限を実装するために異なる方法をとることができます。
備考: コンテナが自身のメモリー制限を指定しているが、メモリー要求を指定していない場合、Kubernetesは制限に一致するメモリー要求を自動的に割り当てます。同様に、コンテナが自身のCPU制限を指定しているが、CPU要求を指定していない場合、Kubernetesは制限に一致するCPU要求を自動的に割り当てます。
リソースタイプ
CPU とメモリー はいずれもリソースタイプ です。リソースタイプには基本単位があります。
CPUは計算処理を表し、Kubernetes CPUs の単位で指定されます。
メモリはバイト単位で指定されます。
Kubernetes v1.14以降を使用している場合は、huge page リソースを指定することができます。
Huge PageはLinux固有の機能であり、Nodeのカーネルはデフォルトのページサイズよりもはるかに大きいメモリブロックを割り当てます。
たとえば、デフォルトのページサイズが4KiBのシステムでは、hugepages-2Mi: 80Miという制限を指定できます。
コンテナが40を超える2MiBの巨大ページ(合計80 MiB)を割り当てようとすると、その割り当ては失敗します。
備考: hugepages-*リソースをオーバーコミットすることはできません。
これはmemoryやcpuリソースとは異なります。
CPUとメモリーは、まとめてコンピュートリソース または単にリソース と呼ばれます。
コンピューティングリソースは、要求され、割り当てられ、消費され得る測定可能な量です。
それらはAPI resources とは異なります。
PodやServices などのAPIリソースは、Kubernetes APIサーバーを介して読み取りおよび変更できるオブジェクトです。
Podとコンテナのリソース要求と制限
Podの各コンテナは、次の1つ以上を指定できます。
spec.containers[].resources.limits.cpuspec.containers[].resources.limits.memoryspec.containers[].resources.limits.hugepages-<size>spec.containers[].resources.requests.cpuspec.containers[].resources.requests.memoryspec.containers[].resources.requests.hugepages-<size>
要求と制限はそれぞれのコンテナでのみ指定できますが、このPodリソースの要求と制限の関係性について理解すると便利です。
特定のリソースタイプのPodリソース要求/制限 は、Pod内の各コンテナに対するそのタイプのリソース要求/制限の合計です。
Kubernetesにおけるリソースの単位
CPUの意味
CPUリソースの制限と要求は、cpu 単位で測定されます。
Kuberenetesにおける1つのCPUは、クラウドプロバイダーの1 vCPU/コア およびベアメタルのインテルプロセッサーの1 ハイパースレッド に相当します。
要求を少数で指定することもできます。
spec.containers[].resources.requests.cpuが0.5のコンテナは、1CPUを要求するコンテナの半分のCPUが保証されます。
0.1という表現は100mという表現と同等であり、100ミリCPUと読み替えることができます。
100ミリコアという表現も、同じことを意味しています。
0.1のような小数点のある要求はAPIによって100mに変換され、1mより細かい精度は許可されません。
このため、100mの形式が推奨されます。
CPUは常に相対量としてではなく、絶対量として要求されます。
0.1は、シングルコア、デュアルコア、あるいは48コアマシンのどのCPUに対してでも、同一の量を要求します。
メモリーの意味
メモリーの制限と要求はバイト単位で測定されます。
E、P、T、G、M、Kのいずれかのサフィックスを使用して、メモリーを整数または固定小数点数として表すことができます。
また、Ei、Pi、Ti、Gi、Mi、Kiのような2の累乗の値を使用することもできます。
たとえば、以下はほぼ同じ値を表しています。
128974848, 129e6, 129M, 123Mi
例を見てみましょう。
次のPodには2つのコンテナがあります。
各コンテナには、0.25cpuおよび64MiB(226 バイト)のメモリー要求と、0.5cpuおよび128MiBのメモリー制限があります
Podには0.5cpuと128MiBのメモリー要求があり、1cpuと256MiBのメモリ制限があると言えます。
apiVersion : v1
kind : Pod
metadata :
name : frontend
spec :
containers :
- name : app
image : images.my-company.example/app:v4
resources :
requests :
memory : "64Mi"
cpu : "250m"
limits :
memory : "128Mi"
cpu : "500m"
- name : log-aggregator
image : images.my-company.example/log-aggregator:v6
resources :
requests :
memory : "64Mi"
cpu : "250m"
limits :
memory : "128Mi"
cpu : "500m"
リソース要求を含むPodがどのようにスケジュールされるか
Podを作成すると、KubernetesスケジューラーはPodを実行するNodeを選択します。
各Nodeには、リソースタイプごとに最大容量があります。それは、Podに提供できるCPUとメモリの量です。
スケジューラーは、リソースタイプごとに、スケジュールされたコンテナのリソース要求の合計がNodeの容量より少ないことを確認します。
Node上の実際のメモリーまたはCPUリソースの使用率は非常に低いですが、容量チェックが失敗した場合、スケジューラーはNodeにPodを配置しないことに注意してください。
これにより、例えば日々のリソース要求のピーク時など、リソース利用が増加したときに、Nodeのリソース不足から保護されます。
リソース制限のあるPodがどのように実行されるか
kubeletがPodのコンテナを開始すると、CPUとメモリーの制限がコンテナランタイムに渡されます。
Dockerを使用する場合:
spec.containers[].resources.requests.cpuは、潜在的に小数であるコア値に変換され、1024倍されます。
docker runコマンドの--cpu-shares
spec.containers[].resources.limits.cpuはミリコアの値に変換され、100倍されます。
結果の値は、コンテナが100ミリ秒ごとに使用できるCPU時間の合計です。
コンテナは、この間隔の間、CPU時間の占有率を超えて使用することはできません。
備考: デフォルトのクォータ期間は100ミリ秒です。
CPUクォータの最小分解能は1ミリ秒です。
spec.containers[].resources.limits.memoryは整数に変換され、docker runコマンドの--memory
コンテナがメモリー制限を超過すると、終了する場合があります。
コンテナが再起動可能である場合、kubeletは他のタイプのランタイム障害と同様にコンテナを再起動します。
コンテナがメモリー要求を超過すると、Nodeのメモリーが不足するたびにそのPodが排出される可能性があります。
コンテナは、長時間にわたってCPU制限を超えることが許可される場合と許可されない場合があります。
ただし、CPUの使用量が多すぎるために、コンテナが強制終了されることはありません。
コンテナをスケジュールできないか、リソース制限が原因で強制終了されているかどうかを確認するには、トラブルシューティング のセクションを参照してください。
コンピュートリソースとメモリーリソースの使用量を監視する
Podのリソース使用量は、Podのステータスの一部として報告されます。
オプションの監視ツール がクラスターにおいて利用可能な場合、Podのリソース使用量はメトリクスAPI から直接、もしくは監視ツールから取得できます。
ローカルのエフェメラルストレージ
FEATURE STATE: Kubernetes v1.10 [beta]
Nodeには、ローカルに接続された書き込み可能なデバイス、または場合によってはRAMによってサポートされるローカルのエフェメラルストレージがあります。
"エフェメラル"とは、耐久性について長期的な保証がないことを意味します。
Podは、スクラッチ領域、キャッシュ、ログ用にエフェメラルなローカルストレージを使用しています。
kubeletは、ローカルのエフェメラルストレージを使用して、Podにスクラッチ領域を提供し、emptyDirボリューム をコンテナにマウントできます。
また、kubeletはこの種類のストレージを使用して、Nodeレベルのコンテナログ 、コンテナイメージ、実行中のコンテナの書き込み可能なレイヤーを保持します。
注意: Nodeに障害が発生すると、そのエフェメラルストレージ内のデータが失われる可能性があります。
アプリケーションは、ローカルのエフェメラルストレージにパフォーマンスのサービス品質保証(ディスクのIOPSなど)を期待することはできません。
ベータ版の機能として、Kubernetesでは、Podが消費するローカルのエフェメラルストレージの量を追跡、予約、制限することができます。
ローカルエフェメラルストレージの設定
Kubernetesは、Node上のローカルエフェメラルストレージを構成する2つの方法をサポートしています。
この構成では、さまざまな種類のローカルのエフェメラルデータ(emptyDirボリュームや、書き込み可能なレイヤー、コンテナイメージ、ログなど)をすべて1つのファイルシステムに配置します。
kubeletを構成する最も効果的な方法は、このファイルシステムをKubernetes(kubelet)データ専用にすることです。
kubeletはNodeレベルのコンテナログ も書き込み、これらをエフェメラルなローカルストレージと同様に扱います。
kubeletは、設定されたログディレクトリ(デフォルトでは/var/log)内のファイルにログを書き出し、ローカルに保存された他のデータのベースディレクトリ(デフォルトでは/var/lib/kubelet)を持ちます。
通常、/var/lib/kubeletと/var/logはどちらもシステムルートファイルシステムにあり、kubeletはそのレイアウトを考慮して設計されています。
Nodeには、Kubernetesに使用されていない他のファイルシステムを好きなだけ持つことができます。
Node上にファイルシステムがありますが、このファイルシステムは、ログやemptyDirボリュームなど、実行中のPodの一時的なデータに使用されます。
このファイルシステムは、例えばKubernetesに関連しないシステムログなどの他のデータに使用することができ、ルートファイルシステムとすることさえ可能です。
また、kubeletはノードレベルのコンテナログ を最初のファイルシステムに書き込み、これらをエフェメラルなローカルストレージと同様に扱います。
また、別の論理ストレージデバイスでバックアップされた別のファイルシステムを使用することもできます。
この設定では、コンテナイメージレイヤーと書き込み可能なレイヤーを配置するようにkubeletに指示するディレクトリは、この2番目のファイルシステム上にあります。
最初のファイルシステムは、コンテナイメージレイヤーや書き込み可能なレイヤーを保持していません。
Nodeには、Kubernetesに使用されていない他のファイルシステムを好きなだけ持つことができます。
kubeletは、ローカルストレージの使用量を測定できます。
これは、以下の条件で提供されます。
LocalStorageCapacityIsolationフィーチャーゲート が有効になっています。(デフォルトでオンになっています。)そして、ローカルのエフェメラルストレージ用にサポートされている構成の1つを使用してNodeをセットアップします。
別の構成を使用している場合、kubeletはローカルのエフェメラルストレージにリソース制限を適用しません。
備考: kubeletは、tmpfsのemptyDirボリュームをローカルのエフェメラルストレージとしてではなく、コンテナメモリーとして追跡します。
ローカルのエフェメラルストレージの要求と制限設定
ローカルのエフェメラルストレージを管理するためには ephemeral-storage パラメーターを利用することができます。
Podの各コンテナは、次の1つ以上を指定できます。
spec.containers[].resources.limits.ephemeral-storagespec.containers[].resources.requests.ephemeral-storage
ephemeral-storageの制限と要求はバイト単位で記します。
ストレージは、次のいずれかの接尾辞を使用して、通常の整数または固定小数点数として表すことができます。
E、P、T、G、M、K。Ei、Pi、Ti、Gi、Mi、Kiの2のべき乗を使用することもできます。
たとえば、以下はほぼ同じ値を表しています。
128974848, 129e6, 129M, 123Mi
次の例では、Podに2つのコンテナがあります。
各コンテナには、2GiBのローカルのエフェメラルストレージ要求があります。
各コンテナには、4GiBのローカルのエフェメラルストレージ制限があります。
したがって、Podには4GiBのローカルのエフェメラルストレージの要求と、8GiBのローカルのエフェメラルストレージ制限があります。
apiVersion : v1
kind : Pod
metadata :
name : frontend
spec :
containers :
- name : app
image : images.my-company.example/app:v4
resources :
requests :
ephemeral-storage : "2Gi"
limits :
ephemeral-storage : "4Gi"
volumeMounts :
- name : ephemeral
mountPath : "/tmp"
- name : log-aggregator
image : images.my-company.example/log-aggregator:v6
resources :
requests :
ephemeral-storage : "2Gi"
limits :
ephemeral-storage : "4Gi"
volumeMounts :
- name : ephemeral
mountPath : "/tmp"
volumes :
- name : ephemeral
emptyDir : {}
エフェメラルストレージを要求するPodのスケジュール方法
Podを作成すると、KubernetesスケジューラーはPodを実行するNodeを選択します。
各Nodeには、Podに提供できるローカルのエフェメラルストレージの上限があります。
詳細については、Node割り当て可能 を参照してください。
スケジューラーは、スケジュールされたコンテナのリソース要求の合計がNodeの容量より少なくなるようにします。
エフェメラルストレージの消費管理
kubeletがローカルのエフェメラルストレージをリソースとして管理している場合、kubeletはストレージの使用量を測定します
tmpfs emptyDirボリュームを除くemptyDirボリュームNodeレベルのログを保持するディレクトリ
書き込み可能なコンテナレイヤー
Podが許可するよりも多くのエフェメラルストレージを使用している場合、kubeletはPodの排出をトリガーするシグナルを設定します。
コンテナレベルの分離の場合、コンテナの書き込み可能なレイヤーとログ使用量がストレージの制限を超えると、kubeletはPodに排出のマークを付けます。
Podレベルの分離の場合、kubeletはPod内のコンテナの制限を合計し、Podの全体的なストレージ制限を計算します。
このケースでは、すべてのコンテナからのローカルのエフェメラルストレージの使用量とPodのemptyDirボリュームの合計がPod全体のストレージ制限を超過する場合、
kubeletはPodをまた排出対象としてマークします。
注意: kubeletがローカルのエフェメラルストレージを測定していない場合、ローカルストレージの制限を超えるPodは、ローカルストレージのリソース制限に違反しても排出されません。
ただし、書き込み可能なコンテナレイヤー、Nodeレベルのログ、またはemptyDirボリュームのファイルシステムスペースが少なくなると、Nodeはローカルストレージが不足していると汚染taints し、この汚染は、汚染を特に許容しないPodの排出をトリガーします。
ローカルのエフェメラルストレージについては、サポートされている設定 をご覧ください。
kubeletはPodストレージの使用状況を測定するさまざまな方法をサポートしています
kubeletは、emptyDirボリューム、コンテナログディレクトリ、書き込み可能なコンテナレイヤーをスキャンする定期的なスケジュールチェックを実行します。
スキャンは、使用されているスペースの量を測定します。
備考: このモードでは、kubeletは削除されたファイルのために、開いているファイルディスクリプタを追跡しません。
あなた(またはコンテナ)がemptyDirボリューム内にファイルを作成した後、何かがそのファイルを開き、そのファイルが開かれたままの状態でファイルを削除した場合、削除されたファイルのinodeはそのファイルを閉じるまで残りますが、kubeletはそのスペースを使用中として分類しません。
FEATURE STATE: Kubernetes v1.15 [alpha]
プロジェクトクォータは、ファイルシステム上のストレージ使用量を管理するためのオペレーティングシステムレベルの機能です。
Kubernetesでは、プロジェクトクォータを有効にしてストレージの使用状況を監視することができます。
ノード上のemptyDirボリュームをバックアップしているファイルシステムがプロジェクトクォータをサポートしていることを確認してください。
例えば、XFSやext4fsはプロジェクトクォータを提供しています。
備考: プロジェクトクォータはストレージの使用状況を監視しますが、制限を強制するものではありません。
Kubernetesでは、1048576から始まるプロジェクトIDを使用します。
使用するプロジェクトIDは/etc/projectsと/etc/projidに登録されます。
この範囲のプロジェクトIDをシステム上で別の目的で使用する場合は、それらのプロジェクトIDを/etc/projectsと/etc/projidに登録し、
Kubernetesが使用しないようにする必要があります。
クォータはディレクトリスキャンよりも高速で正確です。
ディレクトリがプロジェクトに割り当てられると、ディレクトリ配下に作成されたファイルはすべてそのプロジェクト内に作成され、カーネルはそのプロジェクト内のファイルによって使用されているブロックの数を追跡するだけです。
ファイルが作成されて削除されても、開いているファイルディスクリプタがあれば、スペースを消費し続けます。
クォータトラッキングはそのスペースを正確に記録しますが、ディレクトリスキャンは削除されたファイルが使用するストレージを見落としてしまいます。
プロジェクトクォータを使用する場合は、次のことを行う必要があります。
kubelet設定で、LocalocalStorpactionCapactionIsolationFSQuotaMonitoring=trueフィーチャーゲート を有効にします。
ルートファイルシステム(またはオプションのランタイムファイルシステム))がプロジェクトクォータを有効にしていることを確認してください。
すべてのXFSファイルシステムはプロジェクトクォータをサポートしています。
ext4ファイルシステムでは、ファイルシステムがマウントされていない間は、プロジェクトクォータ追跡機能を有効にする必要があります。
# ext4の場合、/dev/block-deviceがマウントされていません
sudo tune2fs -O project -Q prjquota /dev/block-device
ルートファイルシステム(またはオプションのランタイムファイルシステム)がプロジェクトクォータを有効にしてマウントされていることを確認してください。
XFSとext4fsの両方で、マウントオプションはprjquotaという名前になっています。
拡張リソース
拡張リソースはkubernetes.ioドメインの外で完全に修飾されたリソース名です。
これにより、クラスターオペレーターはKubernetesに組み込まれていないリソースをアドバタイズし、ユーザはそれを利用することができるようになります。
拡張リソースを使用するためには、2つのステップが必要です。
第一に、クラスターオペレーターは拡張リソースをアドバタイズする必要があります。
第二に、ユーザーはPodで拡張リソースを要求する必要があります。
拡張リソースの管理
Nodeレベルの拡張リソース
Nodeレベルの拡張リソースはNodeに関連付けられています。
デバイスプラグイン管理のリソース
各Nodeにデバイスプラグインで管理されているリソースをアドバタイズする方法については、デバイスプラグイン を参照してください。
その他のリソース
新しいNodeレベルの拡張リソースをアドバタイズするには、クラスターオペレーターはAPIサーバにPATCHHTTPリクエストを送信し、クラスター内のNodeのstatus.capacityに利用可能な量を指定します。
この操作の後、ノードのstatus.capacityには新しいリソースが含まれます。
status.allocatableフィールドは、kubeletによって非同期的に新しいリソースで自動的に更新されます。
スケジューラはPodの適合性を評価する際にNodeのstatus.allocatable値を使用するため、Nodeの容量に新しいリソースを追加してから、そのNodeでリソースのスケジューリングを要求する最初のPodが現れるまでには、短い遅延が生じる可能性があることに注意してください。
例:
以下は、curlを使用して、Masterがk8s-masterであるNodek8s-node-1で5つのexample.com/fooリソースを示すHTTPリクエストを作成する方法を示す例です。
curl --header "Content-Type: application/json-patch+json" \
\
'[{"op": "add", "path": "/status/capacity/example.com~1foo", "value": "5"}]' \
備考: 上記のリクエストでは、
~1はパッチパス内の文字
/のエンコーディングです。
JSON-Patchの操作パス値は、JSON-Pointerとして解釈されます。
詳細については、
IETF RFC 6901, section 3 を参照してください。
クラスターレベルの拡張リソース
クラスターレベルの拡張リソースはノードに関連付けられていません。
これらは通常、リソース消費とリソースクォータを処理するスケジューラー拡張機能によって管理されます。
スケジューラーポリシー構成 では。スケジューラー拡張機能によって扱われる拡張リソースを指定できます。
例:
次のスケジューラーポリシーの構成は、クラスターレベルの拡張リソース"example.com/foo"がスケジューラー拡張機能によって処理されることを示しています。
スケジューラーは、Podが"example.com/foo"を要求した場合にのみ、Podをスケジューラー拡張機能に送信します。
ignoredBySchedulerフィールドは、スケジューラがそのPodFitsResources述語で"example.com/foo"リソースをチェックしないことを指定します。
{
"kind" : "Policy" ,
"apiVersion" : "v1" ,
"extenders" : [
{
"urlPrefix" :"<extender-endpoint>" ,
"bindVerb" : "bind" ,
"managedResources" : [
{
"name" : "example.com/foo" ,
"ignoredByScheduler" : true
}
]
}
]
}
拡張リソースの消費
ユーザーは、CPUやメモリのようにPodのスペックで拡張されたリソースを消費できます。
利用可能な量以上のリソースが同時にPodに割り当てられないように、スケジューラーがリソースアカウンティングを行います。
APIサーバーは、拡張リソースの量を整数の値で制限します。
有効な数量の例は、3、3000m、3Kiです。
無効な数量の例は、0.5、1500mです。
備考: 拡張リソースは不透明な整数リソースを置き換えます。
ユーザーは、予約済みのkubernetes.io以外のドメイン名プレフィックスを使用できます。
Podで拡張リソースを消費するには、コンテナ名のspec.containers[].resources.limitsマップにキーとしてリソース名を含めます。
備考: 拡張リソースはオーバーコミットできないので、コンテナスペックに要求と制限の両方が存在する場合は等しくなければなりません。
Podは、CPU、メモリ、拡張リソースを含むすべてのリソース要求が満たされた場合にのみスケジュールされます。
リソース要求が満たされない限り、PodはPENDING状態のままです。
例:
下のPodはCPUを2つ、"example.com/foo"(拡張リソース)を1つ要求しています。
apiVersion : v1
kind : Pod
metadata :
name : my-pod
spec :
containers :
- name : my-container
image : myimage
resources :
requests :
cpu : 2
example.com/foo : 1
limits :
example.com/foo : 1
トラブルシューティング
failedSchedulingイベントメッセージが表示され、Podが保留中になる
スケジューラーがPodが収容されるNodeを見つけられない場合、場所が見つかるまでPodはスケジュールされないままになります。
スケジューラーがPodの場所を見つけられないたびに、次のようなイベントが生成されます。
kubectl describe pod frontend | grep -A 3 Events
Events:
FirstSeen LastSeen Count From Subobject PathReason Message
36s 5s 6 {scheduler } FailedScheduling Failed for reason PodExceedsFreeCPU and possibly others
前述の例では、"frontend"という名前のPodは、Node上のCPUリソースが不足しているためにスケジューリングに失敗しています。
同様のエラーメッセージは、メモリー不足による失敗を示唆することもあります(PodExceedsFreeMemory)。
一般的に、このタイプのメッセージでPodが保留されている場合は、いくつか試すべきことがあります。
クラスターにNodeを追加します。
不要なポッドを終了して、保留中のPodのためのスペースを空けます。
PodがすべてのNodeよりも大きくないことを確認してください。
例えば、すべてのNodeがcpu: 1の容量を持っている場合、cpu: 1.1を要求するPodは決してスケジューリングされません。
Nodeの容量や割り当て量はkubectl describe nodesコマンドで調べることができる。
例えば、以下のようになる。
kubectl describe nodes e2e-test-node-pool-4lw4
Name: e2e-test-node-pool-4lw4
[ ... lines removed for clarity ...]
Capacity:
cpu: 2
memory: 7679792Ki
pods: 110
Allocatable:
cpu: 1800m
memory: 7474992Ki
pods: 110
[ ... lines removed for clarity ...]
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
kube-system fluentd-gcp-v1.38-28bv1 100m (5%) 0 (0%) 200Mi (2%) 200Mi (2%)
kube-system kube-dns-3297075139-61lj3 260m (13%) 0 (0%) 100Mi (1%) 170Mi (2%)
kube-system kube-proxy-e2e-test-... 100m (5%) 0 (0%) 0 (0%) 0 (0%)
kube-system monitoring-influxdb-grafana-v4-z1m12 200m (10%) 200m (10%) 600Mi (8%) 600Mi (8%)
kube-system node-problem-detector-v0.1-fj7m3 20m (1%) 200m (10%) 20Mi (0%) 100Mi (1%)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
680m (34%) 400m (20%) 920Mi (12%) 1070Mi (14%)
前述の出力では、Podが1120m以上のCPUや6.23Gi以上のメモリーを要求した場合、そのPodはNodeに収まらないことがわかります。
Podsセクションを見れば、どのPodがNode上でスペースを占有しているかがわかります。
システムデーモンが利用可能なリソースの一部を使用しているため、Podに利用可能なリソースの量はNodeの容量よりも少なくなっています。
allocatableフィールドNodeStatus は、Podに利用可能なリソースの量を与えます。
詳細については、ノード割り当て可能なリソース を参照してください。
リソースクォータ 機能は、消費できるリソースの総量を制限するように設定することができます。
名前空間と組み合わせて使用すると、1つのチームがすべてのリソースを占有するのを防ぐことができます。
コンテナが終了した
コンテナはリソース不足のため、終了する可能性があります。
コンテナがリソース制限に達したために強制終了されているかどうかを確認するには、対象のPodでkubectl describe podを呼び出します。
kubectl describe pod simmemleak-hra99
Name: simmemleak-hra99
Namespace: default
Image(s): saadali/simmemleak
Node: kubernetes-node-tf0f/10.240.216.66
Labels: name=simmemleak
Status: Running
Reason:
Message:
IP: 10.244.2.75
Replication Controllers: simmemleak (1/1 replicas created)
Containers:
simmemleak:
Image: saadali/simmemleak
Limits:
cpu: 100m
memory: 50Mi
State: Running
Started: Tue, 07 Jul 2015 12:54:41 -0700
Last Termination State: Terminated
Exit Code: 1
Started: Fri, 07 Jul 2015 12:54:30 -0700
Finished: Fri, 07 Jul 2015 12:54:33 -0700
Ready: False
Restart Count: 5
Conditions:
Type Status
Ready False
Events:
FirstSeen LastSeen Count From SubobjectPath Reason Message
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {scheduler } scheduled Successfully assigned simmemleak-hra99 to kubernetes-node-tf0f
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD pulled Pod container image "registry.k8s.io/pause:0.8.0" already present on machine
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD created Created with docker id 6a41280f516d
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} implicitly required container POD started Started with docker id 6a41280f516d
Tue, 07 Jul 2015 12:53:51 -0700 Tue, 07 Jul 2015 12:53:51 -0700 1 {kubelet kubernetes-node-tf0f} spec.containers{simmemleak} created Created with docker id 87348f12526a
上記の例では、Restart Count:5はPodのsimmemleakコンテナが終了して、5回再起動したことを示しています。
-o go-template=...オプションを指定して、kubectl get podを呼び出し、以前に終了したコンテナのステータスを取得できます。
kubectl get pod -o go-template= '{{range.status.containerStatuses}}{{"Container Name: "}}{{.name}}{{"\r\nLastState: "}}{{.lastState}}{{end}}' simmemleak-hra99
Container Name: simmemleak
LastState: map[terminated:map[exitCode:137 reason:OOM Killed startedAt:2015-07-07T20:58:43Z finishedAt:2015-07-07T20:58:43Z containerID:docker://0e4095bba1feccdfe7ef9fb6ebffe972b4b14285d5acdec6f0d3ae8a22fad8b2]]
reason:OOM Killedが原因でコンテナが終了したことがわかります。OOMはメモリー不足を表します。
次の項目
7.6 - kubeconfigファイルを使用してクラスターアクセスを組織する
kubeconfigを使用すると、クラスターに、ユーザー、名前空間、認証の仕組みに関する情報を組織できます。kubectlコマンドラインツールはkubeconfigファイルを使用してクラスターを選択するために必要な情報を見つけ、クラスターのAPIサーバーと通信します。
備考: クラスターへのアクセスを設定するために使われるファイルはkubeconfigファイル と呼ばれます。これは設定ファイルを指すために使われる一般的な方法です。kubeconfigという名前を持つファイルが存在するという意味ではありません。
警告: 信頼できるソースからのkubeconfigファイルのみを使用してください。特別に細工されたkubeconfigファイルを使用すると、悪意のあるコードの実行やファイルの公開につながる可能性があります。
信頼できないkubeconfigファイルを使用しなければならない場合は、シェルスクリプトを使用するのと同じように、まず最初に慎重に検査してください。
デフォルトでは、kubectlは$HOME/.kubeディレクトリ内にあるconfigという名前のファイルを探します。KUBECONFIG環境変数を設定するか、--kubeconfig
kubeconfigファイルの作成と指定に関するステップバイステップの手順を知りたいときは、複数のクラスターへのアクセスを設定する を参照してください。
複数のクラスター、ユーザ、認証の仕組みのサポート
複数のクラスターを持っていて、ユーザーやコンポーネントがさまざまな方法で認証を行う次のような状況を考えてみます。
実行中のkubeletが証明書を使用して認証を行う可能性がある。
ユーザーがトークンを使用して認証を行う可能性がある。
管理者が個別のユーザに提供する複数の証明書を持っている可能性がある。
kubeconfigファイルを使用すると、クラスター、ユーザー、名前空間を組織化することができます。また、contextを定義することで、複数のクラスターや名前空間を素早く簡単に切り替えられます。
Context
kubeconfigファイルのcontext 要素は、アクセスパラメーターを使いやすい名前でグループ化するために使われます。各contextは3つのパラメーター、cluster、namespace、userを持ちます。デフォルトでは、kubectlコマンドラインツールはクラスターとの通信にcurrent context のパラメーターを使用します。
current contextを選択するには、以下のコマンドを使用します。
kubectl config use-context
KUBECONFIG環境変数
KUBECONFIG環境変数には、kubeconfigファイルのリストを指定できます。LinuxとMacでは、リストはコロン区切りです。Windowsでは、セミコロン区切りです。KUBECONFIG環境変数は必須ではありません。KUBECONFIG環境変数が存在しない場合は、kubectlはデフォルトのkubeconfigファイルである$HOME/.kube/configを使用します。
KUBECONFIG環境変数が存在する場合は、kubectlはKUBECONFIG環境変数にリストされているファイルをマージした結果を有効な設定として使用します。
kubeconfigファイルのマージ
設定ファイルを確認するには、以下のコマンドを実行します。
上で説明したように、出力は1つのkubeconfigファイルから作られる場合も、複数のkubeconfigファイルをマージした結果となる場合もあります。
kubectlがkubeconfigファイルをマージするときに使用するルールを以下に示します。
もし--kubeconfigフラグが設定されていた場合、指定したファイルだけが使用されます。マージは行いません。このフラグに指定できるのは1つのファイルだけです。
そうでない場合、KUBECONFIG環境変数が設定されていた場合には、それをマージするべきファイルのリストとして使用します。KUBECONFIG環境変数にリストされたファイルのマージは、次のようなルールに従って行われます。
空のファイルを無視する。
デシリアライズできない内容のファイルに対してエラーを出す。
特定の値やmapのキーを設定する最初のファイルが勝つ。
値やmapのキーは決して変更しない。
例: 最初のファイルが指定したcurrent-contextを保持する。
例: 2つのファイルがred-userを指定した場合、1つ目のファイルのred-userだけを使用する。もし2つ目のファイルのred-user以下に競合しないエントリーがあったとしても、それらは破棄する。
KUBECONFIG環境変数を設定する例については、KUBECONFIG環境変数を設定する を参照してください。
それ以外の場合は、デフォルトのkubeconfigファイル$HOME/.kube/configをマージせずに使用します。
以下のチェーンで最初に見つかったものをもとにして、使用するcontextを決定する。
--contextコマンドラインフラグが存在すれば、それを使用する。マージしたkubeconrfigファイルからcurrent-contextを使用する。
この時点では、空のcontextも許容されます。
クラスターとユーザーを決定する。この時点では、contextである場合もそうでない場合もあります。以下のチェーンで最初に見つかったものをもとにして、クラスターとユーザーを決定します。この手順はユーザーとクラスターについてそれぞれ1回ずつ、合わせて2回実行されます。
もし存在すれば、コマンドラインフラグ--userまたは--clusterを使用する。
もしcontextが空でなければ、contextからユーザーまたはクラスターを取得する。
この時点では、ユーザーとクラスターは空である可能性があります。
使用する実際のクラスター情報を決定する。この時点では、クラスター情報は存在しない可能性があります。以下のチェーンで最初に見つかったものをもとにして、クラスター情報の各パーツをそれぞれを構築します。
もし存在すれば、--server、--certificate-authority、--insecure-skip-tls-verifyコマンドラインフラグを使用する。
もしマージしたkubeconfigファイルにクラスター情報の属性が存在すれば、それを使用する。
もしサーバーの場所が存在しなければ、マージは失敗する。
使用する実際のユーザー情報を決定する。クラスター情報の場合と同じルールを使用して、ユーザー情報を構築します。ただし、ユーザーごとに許可される認証方法は1つだけです。
もし存在すれば、--client-certificate、--client-key、--username、--password、--tokenコマンドラインフラグを使用する。
マージしたkubeconfigファイルのuserフィールドを使用する。
もし2つの競合する方法が存在する場合、マージは失敗する。
もし何らかの情報がまだ不足していれば、デフォルトの値を使用し、認証情報については場合によってはプロンプトを表示する。
ファイルリファレンス
kubeconfigファイル内のファイルとパスのリファレンスは、kubeconfigファイルの位置からの相対パスで指定します。コマンドライン上のファイルのリファレンスは、現在のワーキングディレクトリからの相対パスです。$HOME/.kube/config内では、相対パスは相対のまま、絶対パスは絶対のまま保存されます。
プロキシ
kubeconfigファイルでproxy-urlを使用すると、以下のようにクラスターごとにプロキシを使用するようにkubectlを設定することができます。
apiVersion : v1
kind : Config
clusters :
cluster :
proxy-url : http://proxy.example.org:3128
server : https://k8s.example.org/k8s/clusters/c-xxyyzz
name : development
users :
name : developer
contexts :
context :
name : development
次の項目
8 - セキュリティ
クラウドネイティブなワークロードをセキュアに維持するための概念
8.1 - クラウドネイティブセキュリティの概要
この概要では、クラウドネイティブセキュリティにおけるKubernetesのセキュリティを考えるためのモデルを定義します。
警告: コンテナセキュリティモデルは、実証済の情報セキュリティポリシーではなく提案を提供します。
クラウドネイティブセキュリティの4C
セキュリティは階層で考えることができます。クラウドネイティブの4Cは、クラウド、クラスター、コンテナ、そしてコードです。
備考: 階層化されたアプローチは、セキュリティに対する
多層防御 のアプローチを強化します。これはソフトウェアシステムを保護するベストプラクティスとして幅広く認知されています。
クラウドネイティブセキュリティの4C
クラウドネイティブセキュリティモデルの各レイヤーは次の最も外側のレイヤー上に構築します。コードレイヤーは、強固な基盤(クラウド、クラスター、コンテナ)セキュリティレイヤーから恩恵を受けます。コードレベルのセキュリティに対応しても基盤レイヤーが低い水準のセキュリティでは守ることができません。
クラウド
いろいろな意味でも、クラウド(または同じ場所に設置されたサーバー、企業のデータセンター)はKubernetesクラスターのトラステッド・コンピューティング・ベース です。クラウドレイヤーが脆弱な(または脆弱な方法で構成されている)場合、この基盤の上に構築されたコンポーネントが安全であるという保証はありません。各クラウドプロバイダーは、それぞれの環境でワークロードを安全に実行させるためのセキュリティの推奨事項を作成しています。
クラウドプロバイダーのセキュリティ
Kubernetesクラスターを所有しているハードウェアや様々なクラウドプロバイダー上で実行している場合、セキュリティのベストプラクティスに関するドキュメントを参考にしてください。ここでは人気のあるクラウドプロバイダーのセキュリティドキュメントの一部のリンクを紹介します。
インフラのセキュリティ
Kubernetesクラスターのインフラを保護するための提案です。
Infrastructure security
Kubernetesインフラに関する懸念事項
推奨事項
API Server(コントロールプレーン)へのネットワークアクセス
Kubernetesコントロールプレーンへのすべてのアクセスは、インターネット上での一般公開は許されず、クラスター管理に必要なIPアドレスに制限するネットワークアクセス制御リストによって制御されます。
Nodeへのネットワークアクセス
Nodeはコントロールプレーンの特定ポート のみ 接続(ネットワークアクセス制御リストを介して)を受け入れるよう設定し、NodePortとLoadBalancerタイプのKubernetesのServiceに関する接続を受け入れるよう設定する必要があります。可能であれば、それらのNodeはパブリックなインターネットに完全公開しないでください。
KubernetesからのクラウドプロバイダーAPIへのアクセス
各クラウドプロバイダーはKubernetesコントロールプレーンとNodeに異なる権限を与える必要があります。最小権限の原則 に従い、管理に必要なリソースに対してクラウドプロバイダーへのアクセスをクラスターに提供するのが最善です。Kopsドキュメント にはIAMのポリシーとロールについての情報が記載されています。
etcdへのアクセス
etcd(Kubernetesのデータストア)へのアクセスはコントロールプレーンのみに制限すべきです。設定によっては、TLS経由でetcdを利用する必要があります。詳細な情報はetcdドキュメント を参照してください。
etcdの暗号化
可能な限り、保存時に全ドライブを暗号化することは良いプラクティスですが、etcdはクラスター全体(Secretを含む)の状態を保持しているため、そのディスクは特に暗号化する必要があります。
クラスター
Kubernetesを保護する為には2つの懸念事項があります。
設定可能なクラスターコンポーネントの保護
クラスターで実行されるアプリケーションの保護
クラスターのコンポーネント
想定外または悪意のあるアクセスからクラスターを保護して適切なプラクティスを採用したい場合、クラスターの保護 に関するアドバイスを読み従ってください。
クラスター内のコンポーネント(アプリケーション)
アプリケーションを対象にした攻撃に応じて、セキュリティの特定側面に焦点をあてたい場合があります。例:他のリソースとの連携で重要なサービス(サービスA)と、リソース枯渇攻撃に対して脆弱な別のワークロード(サービスB)が実行されている場合、サービスBのリソースを制限していないとサービスAが危険にさらされるリスクが高くなります。次の表はセキュリティの懸念事項とKubernetesで実行されるワークロードを保護するための推奨事項を示しています。
コンテナ
コンテナセキュリティは本ガイドの範囲外になります。このトピックを検索するために一般的な推奨事項とリンクを以下に示します。
コンテナに関する懸念事項
推奨事項
コンテナの脆弱性スキャンとOS依存のセキュリティ
イメージをビルドする手順の一部として、既知の脆弱性がないかコンテナをスキャンする必要があります。
イメージの署名と実施
コンテナイメージを署名し、コンテナの中身に関する信頼性を維持します。
特権ユーザーを許可しない
コンテナの構成時に、コンテナの目的を実行するために必要最低限なOS特権を持ったユーザーをコンテナ内部に作成する方法のドキュメントを参考にしてください。
コード
アプリケーションコードは、あなたが最も制御できる主要な攻撃対象のひとつです。アプリケーションコードを保護することはKubernetesのセキュリティトピックの範囲外ですが、アプリケーションコードを保護するための推奨事項を以下に示します。
コードセキュリティ
Code security
コードに関する懸念事項
推奨事項
TLS経由のアクセスのみ
コードがTCP通信を必要とする場合は、事前にクライアントとのTLSハンドシェイクを実行してください。 いくつかの例外を除いて、全ての通信を暗号化してください。さらに一歩すすめて、サービス間のネットワークトラフィックを暗号化することはよい考えです。これは、サービスを特定した2つの証明書で通信の両端を検証する相互認証、またはmTLS して知られているプロセスを通じて実行できます。
通信ポートの範囲制限
この推奨事項は一目瞭然かもしれませんが、可能なかぎり、通信とメトリクス収集に必要不可欠なサービスのポートのみを公開します。
サードパティに依存するセキュリティ
既知の脆弱性についてアプリケーションのサードパーティ製ライブラリーを定期的にスキャンすることを推奨します。それぞれの言語は自動でこのチェックを実行するツールを持っています。
静的コード解析
ほとんどの言語ではコードのスニペットを解析して、安全でない可能性のあるコーディングを分析する方法が提供しています。可能な限り、コードベースでスキャンして、よく起こるセキュリティエラーを検出できる自動ツールを使用してチェックを実行すべきです。一部のツールはここで紹介されています。 https://owasp.org/www-community/Source_Code_Analysis_Tools
動的プロービング攻撃
よく知られているいくつかのサービス攻撃をサービスに対して試すことができる自動ツールがいくつかあります。これにはSQLインジェクション、CSRF、そしてXSSが含まれます。よく知られている動的解析ツールはOWASP Zed Attack proxy toolです。
次の項目
関連するKubernetesセキュリティについて学びます。
8.2 - Podセキュリティの標準
Podに対するセキュリティの設定は通常Security Context を使用して適用されます。Security ContextはPod単位での特権やアクセスコントロールの定義を実現します。
クラスターにおけるSecurity Contextの強制やポリシーベースの定義はPod Security Policy によって実現されてきました。
Pod Security Policy はクラスターレベルのリソースで、Pod定義のセキュリティに関する設定を制御します。
しかし、PodSecurityPolicyを拡張したり代替する、ポリシーを強制するための多くの方法が生まれてきました。
このページの意図は、推奨されるPodのセキュリティプロファイルを特定の実装から切り離して詳しく説明することです。
ポリシーの種別
まず、幅広いセキュリティの範囲をカバーできる、基礎となるポリシーの定義が必要です。
それらは強く制限をかけるものから自由度の高いものまでをカバーすべきです。
特権 ベースライン、デフォルト 制限
ポリシー
特権
特権ポリシーは意図的に開放されていて、完全に制限がかけられていません。この種のポリシーは通常、特権ユーザーまたは信頼されたユーザーが管理する、システムまたはインフラレベルのワークロードに対して適用されることを意図しています。
特権ポリシーは制限がないことと定義されます。gatekeeperのようにデフォルトで許可される仕組みでは、特権プロファイルはポリシーを設定せず、何も制限を適用しないことにあたります。
一方で、Pod Security Policyのようにデフォルトで拒否される仕組みでは、特権ポリシーでは全ての制限を無効化してコントロールできるようにする必要があります。
ベースライン、デフォルト
ベースライン、デフォルトのプロファイルは一般的なコンテナ化されたランタイムに適用しやすく、かつ既知の特権昇格を防ぐことを意図しています。
このポリシーはクリティカルではないアプリケーションの運用者または開発者を対象にしています。
次の項目は強制、または無効化すべきです。
ベースラインポリシーの定義
項目 ポリシー
ホストのプロセス
Windows Podは、Windowsノードへの特権的なアクセスを可能にするHostProcess コンテナを実行する機能を提供します。ベースラインポリシーでは、ホストへの特権的なアクセスは禁止されています。HostProcess Podは、Kubernetes v1.22時点ではアルファ版の機能です。
ホストのネームスペースの共有は無効化すべきです。
制限されるフィールド
spec.securityContext.windowsOptions.hostProcessspec.containers[*].securityContext.windowsOptions.hostProcessspec.initContainers[*].securityContext.windowsOptions.hostProcessspec.ephemeralContainers[*].securityContext.windowsOptions.hostProcess
認められる値
ホストのネームスペース
ホストのネームスペースの共有は無効化すべきです。制限されるフィールド: 認められる値: false, Undefined/nil
特権コンテナ
特権を持つPodはほとんどのセキュリティ機構を無効化できるので、禁止すべきです。制限されるフィールド: 認められる値: false, undefined/nil
ケーパビリティー
デフォルト よりも多くのケーパビリティーを与えることは禁止すべきです。制限されるフィールド: 認められる値:
Undefined/nil
HostPathボリューム
HostPathボリュームは禁止すべきです。制限されるフィールド: 認められる値: undefined/nil
ホストのポート
HostPortは禁止するか、最小限の既知のリストに限定すべきです。制限されるフィールド: 認められる値: 0, undefined (または既知のリストに限定)
AppArmor(任意)
サポートされるホストでは、AppArmorの'runtime/default'プロファイルがデフォルトで適用されます。デフォルトのポリシーはポリシーの上書きや無効化を防ぎ、許可されたポリシーのセットを上書きできないよう制限すべきです。制限されるフィールド: 認められる値: 'runtime/default', undefined, localhost/*
SELinux (任意)
SELinuxのオプションをカスタムで設定することは禁止すべきです。制限されるフィールド: 認められる値: undefined/nil制限されるフィールド: 認められる値: undefined/nil
/procマウントタイプ
攻撃対象を縮小するため/procのマスクを設定し、必須とすべきです。制限されるフィールド: 認められる値: undefined/nil, 'Default'
Seccomp
Seccompプロファイルを明示的にUnconfinedに設定することはできません。
Restricted Fields
spec.securityContext.seccompProfile.typespec.containers[*].securityContext.seccompProfile.typespec.initContainers[*].securityContext.seccompProfile.typespec.ephemeralContainers[*].securityContext.seccompProfile.type
Allowed Values
Undefined/nil
RuntimeDefaultLocalhost
Sysctl
Sysctlはセキュリティ機構を無効化したり、ホストの全てのコンテナに影響を与えたりすることが可能なので、「安全」なサブネットを除いては禁止すべきです。
コンテナまたはPodの中にsysctlがありネームスペースが分離されていて、同じノードの別のPodやプロセスから分離されている場合はsysctlは安全だと考えられます。制限されるフィールド: 認められる値:
制限
制限ポリシーはいくらかの互換性を犠牲にして、Podを強化するためのベストプラクティスを強制することを意図しています。
セキュリティ上クリティカルなアプリケーションの運用者や開発者、また信頼度の低いユーザーも対象にしています。
下記の項目を強制、無効化すべきです。
制限ポリシーの定義
項目 ポリシー
デフォルトプロファイルにある項目全て
Volumeタイプ
HostPathボリュームの制限に加え、制限プロファイルではコアでない種類のボリュームの利用をPersistentVolumeにより定義されたものに限定します。制限されるフィールド: 認められる値: undefined/nil
特権昇格
特権昇格(ファイルモードのset-user-IDまたはset-group-IDのような方法による)は禁止すべきです。制限されるフィールド: 認められる値: false
root以外での実行
コンテナはroot以外のユーザーで実行する必要があります。制限されるフィールド: 認められる値: true
root以外のグループ (任意)
コンテナをrootのプライマリまたは補助GIDで実行することを禁止すべきです。制限されるフィールド: 認められる値:
Seccomp
SeccompのRuntimeDefaultを必須とする、または特定の追加プロファイルを許可することが必要です。制限されるフィールド: 認められる値:
Capabilities (v1.22+)
コンテナはすべてのケイパビリティを削除する必要があり、NET_BIND_SERVICEケイパビリティを追加することだけが許可されています。
Restricted Fields
spec.containers[*].securityContext.capabilities.dropspec.initContainers[*].securityContext.capabilities.dropspec.ephemeralContainers[*].securityContext.capabilities.drop
Allowed Values
Any list of capabilities that includes ALL
Restricted Fields
spec.containers[*].securityContext.capabilities.addspec.initContainers[*].securityContext.capabilities.addspec.ephemeralContainers[*].securityContext.capabilities.add
Allowed Values
Undefined/nil
NET_BIND_SERVICE
ポリシーの実例
ポリシーの定義とポリシーの実装を切り離すことによって、ポリシーを強制する機構とは独立して、汎用的な理解や複数のクラスターにわたる共通言語とすることができます。
機構が成熟してきたら、ポリシーごとに下記に定義されます。それぞれのポリシーを強制する方法についてはここでは定義しません。
PodSecurityPolicy
FAQ
特権とデフォルトの間のプロファイルがないのはどうしてですか?
ここで定義されている3つのプロファイルは最も安全(制限)から最も安全ではない(特権)まで、直線的に段階が設定されており、幅広いワークロードをカバーしています。
ベースラインを超える特権が必要な場合、その多くはアプリケーションに特化しているため、その限られた要求に対して標準的なプロファイルを提供することはできません。
これは、このような場合に必ず特権プロファイルを使用すべきだという意味ではなく、場合に応じてポリシーを定義する必要があります。
将来、他のプロファイルの必要性が明らかになった場合、SIG Authはこの方針について再考する可能性があります。
セキュリティポリシーとセキュリティコンテキストの違いは何ですか?
Security Context は実行時のコンテナやPodを設定するものです。
Security ContextはPodのマニフェストの中でPodやコンテナの仕様の一部として定義され、コンテナランタイムへ渡されるパラメーターを示します。
セキュリティポリシーはコントロールプレーンの機構で、Security Contextとそれ以外も含め、特定の設定を強制するものです。
2020年2月時点では、ネイティブにサポートされているポリシー強制の機構はPod Security
Policy です。これはクラスター全体にわたってセキュリティポリシーを中央集権的に強制するものです。
セキュリティポリシーを強制する他の手段もKubernetesのエコシステムでは開発が進められています。例えばOPA
Gatekeeper があります。
WindowsのPodにはどのプロファイルを適用すればよいですか?
Kubernetesでは、Linuxベースのワークロードと比べてWindowsの使用は制限や差異があります。
特に、PodのSecurityContextフィールドはWindows環境では効果がありません 。
したがって、現段階では標準化されたセキュリティポリシーは存在しません。
Windows Podに制限付きプロファイルを適用すると、実行時にPodに影響が出る場合があります。
制限付きプロファイルでは、Linux固有の制限(seccompプロファイルや特権昇格の不許可など)を適用する必要があります。
kubeletおよび/またはそのコンテナランタイムがこれらのLinux固有の値を無視した場合、Windows Podは制限付きプロファイル内で正常に動作します。
ただし、強制力がないため、Windows コンテナを使用するPodについては、ベースラインプロファイルと比較して追加の制限はありません。
HostProcess Podを作成するためのHostProcessフラグの使用は、特権的なポリシーに沿ってのみ行われるべきです。
Windows HostProcess Podの作成は、ベースラインおよび制限されたポリシーの下でブロックされているため、いかなるHostProcess Podも特権的であるとみなされるべきです。
サンドボックス化されたPodはどのように扱えばよいでしょうか?
現在のところ、Podがサンドボックス化されていると見なされるかどうかを制御できるAPI標準はありません。
サンドボックス化されたPodはサンドボックス化されたランタイム(例えばgVisorやKata Containers)の使用により特定することは可能ですが、サンドボックス化されたランタイムの標準的な定義は存在しません。
サンドボックス化されたランタイムに対して必要な保護は、それ以外に対するものとは異なります。
例えば、ワークロードがその基になるカーネルと分離されている場合、特権を制限する必要性は小さくなります。
これにより、強い権限を必要とするワークロードが隔離された状態を維持できます。
加えて、サンドボックス化されたワークロードの保護はサンドボックス化の実装に強く依存します。
したがって、全てのサンドボックス化されたワークロードに推奨される単一のポリシーは存在しません。
8.3 - Podのセキュリティアドミッション
FEATURE STATE: Kubernetes v1.23 [beta]
KubernetesのPodセキュリティの標準 はPodに対して異なる分離レベルを定義します。
これらの標準によって、Podの動作をどのように制限したいかを、明確かつ一貫した方法で定義することができます。
ベータ版機能として、KubernetesはPodSecurityPolicy の後継である組み込みの Pod Security アドミッションコントローラー を提供しています。
Podセキュリティの制限は、Pod作成時に名前空間 レベルで適用されます。
備考: PodSecurityPolicy APIは非推奨であり、v1.25でKubernetesから
削除 される予定です。
PodSecurityアドミッションプラグインの有効化v1.23において、PodSecurityのフィーチャーゲート はベータ版の機能で、デフォルトで有効化されています。
v1.22において、PodSecurityのフィーチャーゲート はアルファ版の機能で、組み込みのアドミッションプラグインを使用するには、kube-apiserverで有効にする必要があります。
--feature-gates= "...,PodSecurity=true"
代替案:PodSecurityアドミッションwebhookのインストール
クラスターがv1.22より古い、あるいはPodSecurity機能を有効にできないなどの理由で、ビルトインのPodSecurityアドミッションプラグインが使えない環境では、PodSecurityはアドミッションロジックはベータ版のvalidating admission webhook としても提供されています。
ビルド前のコンテナイメージ、証明書生成スクリプト、マニフェストの例は、https://git.k8s.io/pod-security-admission/webhook で入手可能です。
インストール方法:
git clone git@github.com:kubernetes/pod-security-admission.git
cd pod-security-admission/webhook
make certs
kubectl apply -k .
備考: 生成された証明書の有効期限は2年間です。有効期限が切れる前に、証明書を再生成するか、内蔵のアドミッションプラグインを使用してWebhookを削除してください。
Podのセキュリティレベル
Podのセキュリティアドミッションは、PodのSecurity Context とその他の関連フィールドに、Podセキュリティの標準 で定義された3つのレベル、privileged、baseline、restrictedに従って要件を設定するものです。
これらの要件の詳細については、Podセキュリティの標準 のページを参照してください。
Podの名前空間に対するセキュリティアドミッションラベル
この機能を有効にするか、Webhookをインストールすると、名前空間を設定して、各名前空間でPodセキュリティに使用したいadmission controlモードを定義できます。
Kubernetesは、名前空間に使用したい定義済みのPodセキュリティの標準レベルのいずれかを適用するために設定できるラベル のセットを用意しています。
選択したラベルは、以下のように違反の可能性が検出された場合にコントロールプレーン が取るアクションを定義します。
Podのセキュリティアドミッションのモード
モード
説明
enforce ポリシーに違反した場合、Podは拒否されます。
audit ポリシー違反は、監査ログ に記録されるイベントに監査アノテーションを追加するトリガーとなりますが、それ以外は許可されます。
warn ポリシーに違反した場合は、ユーザーへの警告がトリガーされますが、それ以外は許可されます。
名前空間は、任意のまたはすべてのモードを設定することができ、異なるモードに対して異なるレベルを設定することもできます。
各モードには、使用するポリシーを決定する2つのラベルがあります。
# モードごとのレベルラベルは、そのモードに適用するポリシーレベルを示す。
#
# MODEは`enforce`、`audit`、`warn`のいずれかでなければならない。
# LEVELは`privileged`、`baseline`、`restricted`のいずれかでなければならない。
pod-security.kubernetes.io/<MODE> : <LEVEL>
# オプション: モードごとのバージョンラベルは、Kubernetesのマイナーバージョンに同梱される
# バージョンにポリシーを固定するために使用できる(例えばv1.31など)。
#
# MODEは`enforce`、`audit`、`warn`のいずれかでなければならない。
# VERSIONは有効なKubernetesのマイナーバージョンか`latest`でなければならない。
pod-security.kubernetes.io/<MODE>-version : <VERSION>
名前空間ラベルでのPodセキュリティの標準の適用 で使用例を確認できます。
WorkloadのリソースとPodテンプレート
Podは、Deployment やJob のようなワークロードオブジェクト を作成することによって、しばしば間接的に生成されます。
ワークロードオブジェクトは_Pod template_を定義し、ワークロードリソースのコントローラー はそのテンプレートに基づきPodを作成します。
違反の早期発見を支援するために、auditモードとwarningモードは、ワークロードリソースに適用されます。
ただし、enforceモードはワークロードリソースには適用されず 、結果としてのPodオブジェクトにのみ適用されます。
適用除外(Exemption)
Podセキュリティの施行から exemptions を定義することで、特定の名前空間に関連するポリシーのために禁止されていたPodの作成を許可することができます。
Exemptionはアドミッションコントローラーの設定 で静的に設定することができます。
Exemptionは明示的に列挙する必要があります。
Exemptionを満たしたリクエストは、アドミッションコントローラーによって 無視 されます(enforce、audit、warnのすべての動作がスキップされます)。Exemptionの次元は以下の通りです。
Usernames: 認証されていない(あるいは偽装された)ユーザー名を持つユーザーからの要求は無視されます。RuntimeClassNames: Podとワークロードリソース で指定された除外ランタイムクラス名は、無視されます。Namespaces: 除外された名前空間のPodとワークロードリソース は、無視されます。
注意: ほとんどのPodは、
ワークロードリソース に対応してコントローラーが作成します。つまり、エンドユーザーを適用除外にするのはPodを直接作成する場合のみで、ワークロードリソースを作成する場合は適用除外になりません。
コントローラーサービスアカウント(
system:serviceaccount:kube-system:replicaset-controllerなど)は通常、除外してはいけません。そうした場合、対応するワークロードリソースを作成できるすべてのユーザーを暗黙的に除外してしまうためです。
以下のPodフィールドに対する更新は、ポリシーチェックの対象外となります。つまり、Podの更新要求がこれらのフィールドを変更するだけであれば、Podが現在のポリシーレベルに違反していても拒否されることはありません。
すべてのメタデータの更新(seccompまたはAppArmorアノテーションへの変更を除く )
seccomp.security.alpha.kubernetes.io/pod(非推奨)container.seccomp.security.alpha.kubernetes.io/*(非推奨)container.apparmor.security.beta.kubernetes.io/*
.spec.activeDeadlineSecondsに対する有効な更新.spec.tolerationsに対する有効な更新
次の項目
8.4 - Kubernetes APIへのアクセスコントロール
このページではKubernetes APIへのアクセスコントロールの概要を説明します。
Kubernetes API にはkubectlやクライアントライブラリ、あるいはRESTリクエストを用いてアクセスします。
APIアクセスには、人間のユーザーとKubernetesサービスアカウント の両方が認証可能です。
リクエストがAPIに到達すると、次の図のようにいくつかの段階を経ます。
トランスポート層のセキュリティ
一般的なKubernetesクラスターでは、APIはTLSで保護された443番ポートで提供されます。
APIサーバーは証明書を提示します。
この証明書は、プライベート認証局(CA)を用いて署名することも、一般に認知されているCAと連携した公開鍵基盤に基づき署名することも可能です。
クラスターがプライベート認証局を使用している場合、接続を信頼し、傍受されていないと確信できるように、クライアント上の~/.kube/configに設定されたそのCA証明書のコピーが必要です。
クライアントは、この段階でTLSクライアント証明書を提示することができます。
認証
TLSが確立されると、HTTPリクエストは認証のステップに移行します。
これは図中のステップ1 に該当します。
クラスター作成スクリプトまたはクラスター管理者は、1つまたは複数のAuthenticatorモジュールを実行するようにAPIサーバーを設定します。
Authenticatorについては、認証 で詳しく説明されています。
認証ステップへの入力はHTTPリクエスト全体ですが、通常はヘッダとクライアント証明書の両方、またはどちらかを調べます。
認証モジュールには、クライアント証明書、パスワード、プレーントークン、ブートストラップトークン、JSON Web Tokens(サービスアカウントに使用)などがあります。
複数の認証モジュールを指定することができ、その場合、1つの認証モジュールが成功するまで、それぞれを順番に試行します。
認証できない場合、HTTPステータスコード401で拒否されます。
そうでなければ、ユーザーは特定のusernameとして認証され、そのユーザー名は後続のステップでの判断に使用できるようになります。
また、ユーザーのグループメンバーシップを提供する認証機関と、提供しない認証機関があります。
Kubernetesはアクセスコントロールの決定やリクエストログにユーザー名を使用しますが、Userオブジェクトを持たず、ユーザー名やその他のユーザーに関する情報をAPIはに保存しません。
認可
リクエストが特定のユーザーからのものであると認証された後、そのリクエストは認可される必要があります。
これは図のステップ2 に該当します。
リクエストには、リクエスト者のユーザー名、リクエストされたアクション、そのアクションによって影響を受けるオブジェクトを含める必要があります。
既存のポリシーで、ユーザーが要求されたアクションを完了するための権限を持っていると宣言されている場合、リクエストは承認されます。
例えば、Bobが以下のようなポリシーを持っている場合、彼は名前空間projectCaribou内のPodのみを読むことができます。
{
"apiVersion" : "abac.authorization.kubernetes.io/v1beta1" ,
"kind" : "Policy" ,
"spec" : {
"user" : "bob" ,
"namespace" : "projectCaribou" ,
"resource" : "pods" ,
"readonly" : true
}
}
Bobが次のようなリクエストをした場合、Bobは名前空間projectCaribouのオブジェクトを読むことが許可されているので、このリクエストは認可されます。
{
"apiVersion" : "authorization.k8s.io/v1beta1" ,
"kind" : "SubjectAccessReview" ,
"spec" : {
"resourceAttributes" : {
"namespace" : "projectCaribou" ,
"verb" : "get" ,
"group" : "unicorn.example.org" ,
"resource" : "pods"
}
}
}
Bobが名前空間projectCaribouのオブジェクトに書き込み(createまたはupdate)のリクエストをした場合、承認は拒否されます。
また、もしBobがprojectFishのような別の名前空間にあるオブジェクトを読み込む(get)リクエストをした場合も、承認は拒否されます。
Kubernetesの認可では、組織全体またはクラウドプロバイダー全体の既存のアクセスコントロールシステムと対話するために、共通のREST属性を使用する必要があります。
これらのコントロールシステムは、Kubernetes API以外のAPIとやり取りする可能性があるため、REST形式を使用することが重要です。
Kubernetesは、ABACモード、RBACモード、Webhookモードなど、複数の認可モジュールをサポートしています。
管理者はクラスターを作成する際に、APIサーバーで使用する認証モジュールを設定します。
複数の認可モジュールが設定されている場合、Kubernetesは各モジュールをチェックし、いずれかのモジュールがリクエストを認可した場合、リクエストを続行することができます。
すべてのモジュールがリクエストを拒否した場合、リクエストは拒否されます(HTTPステータスコード403)。
サポートされている認可モジュールを使用したポリシー作成の詳細を含む、Kubernetesの認可については、認可 を参照してください。
アドミッションコントロール
アドミッションコントロールモジュールは、リクエストを変更したり拒否したりすることができるソフトウェアモジュールです。
認可モジュールが利用できる属性に加えて、アドミッションコントロールモジュールは、作成または修正されるオブジェクトのコンテンツにアクセスすることができます。
アドミッションコントローラーは、オブジェクトの作成、変更、削除、または接続(プロキシ)を行うリクエストに対して動作します。
アドミッションコントローラーは、単にオブジェクトを読み取るだけのリクエストには動作しません。
複数のアドミッションコントローラーが設定されている場合は、順番に呼び出されます。
これは図中のステップ3 に該当します。
認証・認可モジュールとは異なり、いずれかのアドミッションコントローラーモジュールが拒否した場合、リクエストは即座に拒否されます。
オブジェクトを拒否するだけでなく、アドミッションコントローラーは、フィールドに複雑なデフォルトを設定することもできます。
利用可能なアドミッションコントロールモジュールは、アドミッションコントローラー に記載されています。
リクエストがすべてのアドミッションコントローラーを通過すると、対応するAPIオブジェクトの検証ルーチンを使って検証され、オブジェクトストアに書き込まれます(図のステップ4 に該当します)。
監査
Kubernetesの監査は、クラスター内の一連のアクションを文書化した、セキュリティに関連する時系列の記録を提供します。
クラスターは、ユーザー、Kubernetes APIを使用するアプリケーション、およびコントロールプレーン自身によって生成されるアクティビティを監査します。
詳しくは監査 をご覧ください。
APIサーバーのIPとポート
これまでの説明は、APIサーバーのセキュアポートに送信されるリクエストに適用されます(典型的なケース)。
APIサーバーは、実際には2つのポートでサービスを提供することができます。
デフォルトでは、Kubernetes APIサーバーは2つのポートでHTTPを提供します。
localhostポート:
テストとブートストラップ用で、マスターノードの他のコンポーネント(スケジューラー、コントローラーマネージャー)がAPIと通信するためのものです。
TLSは使用しません。
デフォルトポートは8080です。
デフォルトのIPはlocalhostですが、--insecure-bind-addressフラグで変更することができます。
リクエストは認証と認可のモジュールをバイパス します。
リクエストは、アドミッションコントロールモジュールによって処理されます。
ホストにアクセスする必要があるため、保護されています。
“セキュアポート”:
可能な限りこちらを使用してください。
TLSを使用します。証明書は--tls-cert-fileフラグで、鍵は--tls-private-key-fileフラグで設定します。
デフォルトポートは6443です。--secure-portフラグで変更することができます。
デフォルトのIPは、最初の非localhostのネットワークインターフェースです。--bind-addressフラグで変更することができます。
リクエストは、認証・認可モジュールによって処理されます。
リクエストは、アドミッションコントロールモジュールによって処理されます。
認証・認可モジュールが実行されます。
次の項目
認証、認可、APIアクセスコントロールに関する詳しいドキュメントはこちらをご覧ください。
以下についても知ることができます。
PodがAPIクレデンシャルを取得するためにSecrets を使用する方法について。
8.5 - Kubernetes Secretの適切な使用方法
クラスター管理者とアプリケーション開発者向けの適切なSecret管理の原則と実践方法。
Kubernetesでは、Secretは次のようなオブジェクトです。 パスワードやOAuthトークン、SSHキーのような機密の情報を保持します。
Secretは、機密情報の使用方法をより管理しやすくし、偶発的な漏洩のリスクを減らすことができます。Secretの値はbase64文字列としてエンコードされ、デフォルトでは暗号化されずに保存されますが、保存時に暗号化 するように設定することもできます。
Pod は、ボリュームマウントや環境変数など、さまざまな方法でSecretを参照できます。Secretは機密データ用に設計されており、ConfigMap は非機密データ用に設計されています。
以下の適切な使用方法は、クラスター管理者とアプリケーション開発者の両方を対象としています。
これらのガイドラインに従って、Secretオブジェクト内の機密情報のセキュリティを向上させ、Secretの効果的な管理を行ってください。
クラスター管理者
このセクションでは、クラスター管理者がクラスター内の機密情報のセキュリティを強化するために使用できる適切な方法を提供します。
データ保存時の暗号化を構成する
デフォルトでは、Secretオブジェクトはetcd 内で暗号化されていない状態で保存されます。
etcd内のSecretデータを暗号化するように構成する必要があります。
手順については、機密データ保存時の暗号化 を参照してください。
Secretへの最小特権アクセスを構成する
Kubernetesのロールベースアクセス制御 (RBAC) などのアクセス制御メカニズムを計画する際、Secretオブジェクトへのアクセスに関する以下のガイドラインを考慮してください。
また、RBACの適切な使用方法 の他のガイドラインにも従ってください。
コンポーネント : watchまたはlistアクセスを、最上位の特権を持つシステムレベルのコンポーネントのみに制限してください。コンポーネントの通常の動作が必要とする場合にのみ、Secretへのgetアクセスを許可してください。ユーザー : Secretへのget、watch、listアクセスを制限してください。etcdへのアクセスはクラスター管理者にのみ許可し、読み取り専用アクセスも許可してください。特定の注釈を持つSecretへのアクセスを制限するなど、より複雑なアクセス制御については、サードパーティの認証メカニズムを検討してください。
注意: Secretへのlistアクセスを暗黙的に許可すると、サブジェクトがSecretの内容を取得できるようになります。
Secretを使用するPodを作成できるユーザーは、そのSecretの値も見ることができます。
クラスターのポリシーがユーザーにSecretを直接読むことを許可しない場合でも、同じユーザーがSecretを公開するPodを実行するアクセスを持つかもしれません。
このようなアクセスを持つユーザーによるSecretデータの意図的または偶発的な公開の影響を検出または制限することができます。
いくつかの推奨事項には以下があります:
短寿命のSecretを使用する
特定のイベントに対してアラートを出す監査ルールを実装する(例:単一ユーザーによる複数のSecretの同時読み取り)
etcdの管理ポリシーを改善する
使用しなくなった場合には、etcdが使用する永続ストレージを削除するかシュレッダーで処理してください。
複数のetcdインスタンスがある場合、インスタンス間の通信を暗号化されたSSL/TLS通信に設定して、転送中のSecretデータを保護してください。
外部Secretへのアクセスを構成する
備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 外部のSecretストアプロバイダーを使用して機密データをクラスターの外部に保存し、その情報にアクセスするようにPodを構成できます。
Kubernetes Secrets Store CSI Driver は、kubeletが外部ストアからSecretを取得し、データにアクセスすることを許可された特定のPodにSecretをボリュームとしてマウントするDaemonSetです。
サポートされているプロバイダーの一覧については、Secret Store CSI Driverのプロバイダー を参照してください。
開発者
このセクションでは、Kubernetesリソースの作成と展開時に機密データのセキュリティを向上させるための開発者向けの適切な使用方法を提供します。
特定のコンテナへのSecretアクセスを制限する
Pod内で複数のコンテナを定義し、そのうち1つのコンテナだけがSecretへのアクセスを必要とする場合、他のコンテナがそのSecretにアクセスできないようにボリュームマウントや環境変数の設定を行ってください。
読み取り後にSecretデータを保護する
アプリケーションは、環境変数やボリュームから機密情報を読み取った後も、その値を保護する必要があります。
例えば、アプリケーションは機密情報を平文でログに記録したり、信頼できない第三者に送信したりしないようにする必要があります。
Secretマニフェストの共有を避ける
Secretをマニフェスト を介して設定し、秘密データをBase64でエンコードしている場合、このファイルを共有したりソースリポジトリにチェックインしたりすると、その秘密はマニフェストを読むことのできる全員に公開されます。
注意: Base64エンコードは暗号化方法ではなく、平文と同じく機密性を提供しません。
9 - ポリシー
9.1 - Limit Range
デフォルトでは、コンテナは、Kubernetesクラスター上の計算リソース の消費を制限されずに実行されます。リソースクォータを利用すれば、クラスター管理者はリソースの消費と作成を名前空間 ベースで制限することができます。名前空間内では、Podやコンテナは名前空間のリソースクォータで定義された範囲内でできるだけ多くのCPUとメモリーを消費できてしまうため、1つのPodまたはコンテナが利用可能なすべてのリソースを専有してしまう恐れがあります。LimitRangeを利用すれば、このような名前空間内での(Podやコンテナへの)リソースの割り当てを制限するポリシーを定めることができます。
LimitRange を利用すると、次のような制約を課せるようになります。
名前空間内のPodまたはコンテナごとに、計算リソースの使用量の最小値と最大値を強制する。
名前空間内のPersistentVolumeClaimごとに、ストレージリクエストの最小値と最大値を強制する。
名前空間内で、リソースのrequestとlimitの割合を強制する。
名前空間内の計算リソースのデフォルトのrequest/limitの値を設定して、実行時にコンテナに自動的に注入する。
LimitRangeを有効にする
Kubernetes 1.10以降では、LimitRangeのサポートはデフォルトで有効になりました。
LimitRangeが特定の名前空間内で強制されるのは、その名前空間内にLimitRangeオブジェクトが存在する場合です。
LimitRangeオブジェクトの名前は、有効なDNSサブドメイン名 でなければなりません。
Limit Rangeの概要
管理者は、1つの名前空間に1つのLimitRangeを作成します。
ユーザーは、Pod、コンテナ、PersistentVolumeClaimのようなリソースを名前空間内に作成します。
LimitRangerアドミッションコントローラーは、計算リソース要求が設定されていないすべてのPodとコンテナに対して、デフォルト値と制限値を強制します。そして、リソースの使用量を追跡し、名前空間内に存在するすべてのLimitRangeで定義された最小値、最大値、割合を外れないことを保証します。LimitRangeの制約を破るようなリソース(Pod、コンテナ、PersistentVolumeClaim)の作成や更新を行うと、APIサーバーへのリクエストがHTTPステータスコード403 FORBIDDENで失敗し、破られた制約を説明するメッセージが返されます。
名前空間内でLimitRangeがcpuやmemoryなどの計算リソースに対して有効になっている場合、ユーザーはrequestsやlimitsに値を指定しなければなりません。指定しなかった場合、システムはPodの作成を拒否する可能性があります。
LimitRangeの検証は、Podのアドミッションステージでのみ発生し、実行中のPodでは発生しません。
以下は、LimitRangeを使用して作成できるポリシーの例です。
8GiBのRAMと16コアのCPUの容量がある2ノードのクラスター上で、名前空間内のPodに対して、CPUには100mのrequestと最大500mのlimitの制約を課し、メモリーには200Miのrequestと600Miのlimitの制約を課す。
Spec内のrequestsにcpuやmemoryを指定せずに起動したコンテナに対して、CPUにはデフォルトで150mのlimitとrequestを、メモリーにはデフォルトで300Miのrequestをそれぞれ定義する。
名前空間のlimitの合計が、Podやコンテナのlimitの合計よりも小さくなる場合、リソースの競合が起こる可能性があります。その場合、コンテナやPodは作成されません。
LimitRangeに対する競合や変更は、すでに作成済みのリソースに対しては影響しません。
次の項目
より詳しい情報は、LimitRangerの設計ドキュメント を参照してください。
制限の使用例については、以下のページを読んでください。
9.2 - リソースクォータ
複数のユーザーやチームが決められた数のノードを持つクラスターを共有しているとき、1つのチームが公平に使えるリソース量を超えて使用するといった問題が出てきます。
リソースクォータはこの問題に対処するための管理者向けツールです。
ResourceQuotaオブジェクトによって定義されるリソースクォータは、名前空間ごとの総リソース消費を制限するための制約を提供します。リソースクォータは同じ名前空間のクラスター内でタイプごとに作成できるオブジェクト数や、名前空間内のリソースによって消費されるコンピュートリソースの総量を制限できます。
リソースクォータは下記のように働きます。
異なる名前空間で異なるチームが存在するとき。現時点ではこれは自主的なものですが、将来的にはACLsを介してリソースクォータの設定を強制するように計画されています。
管理者は各名前空間で1つのResourceQuotaを作成します。
ユーザーが名前空間内でリソース(Pod、Serviceなど)を作成し、クォータシステムがResourceQuotaによって定義されたハードリソースリミットを超えないことを保証するために、リソースの使用量をトラッキングします。
リソースの作成や更新がクォータの制約に違反しているとき、そのリクエストはHTTPステータスコード403 FORBIDDENで失敗し、違反した制約を説明するメッセージが表示されます。
cpuやmemoryといったコンピューターリソースに対するクォータが名前空間内で有効になっているとき、ユーザーはそれらの値に対するrequestsやlimitsを設定する必要があります。設定しないとクォータシステムがPodの作成を拒否します。 ヒント: コンピュートリソースの要求を設定しないPodに対してデフォルト値を強制するために、LimitRangerアドミッションコントローラーを使用してください。この問題を解決する例はwalkthrough で参照できます。
備考:
cpuおよびmemoryリソースに関しては、ResourceQuotaはlimitを設定している名前空間内の全ての (新しい)Podに対して当該リソースのlimitの設定を強制します。名前空間内のcpuまたはmemoryどちらかに対してリソースクォータを適用する場合、ユーザーやクライアントは全ての新しいPodごとに、そのリソースのrequestsあるいはlimitsを指定しなければなりません 。そうでない場合、コントロールプレーンがそのPodの作成を拒否する可能性があります。その他のリソースに関して: ResourceQuotaはリソースのlimitまたはrequestを設定していないPodでも機能します。これは、名前空間内のリソースクォータにおいてエフェメラルストレージのlimitを設定している場合、エフェメラルストレージのlimit/requestsを設定していないPodでも新規作成できることを意味します。LimitRange を使うことで、リソースに対して自動的にデフォルト要求を設定することができます。
ResourceQuotaのオブジェクト名は、有効なDNSサブドメイン名 である必要があります.
名前空間とクォータを使用して作成できるポリシーの例は以下の通りです。
32GiB RAM、16コアのキャパシティーを持つクラスターで、Aチームに20GiB、10コアを割り当て、Bチームに10GiB、4コアを割り当て、将来の割り当てのために2GiB、2コアを予約しておく。
"testing"という名前空間に対して1コア、1GiB RAMの使用制限をかけ、"production"という名前空間には制限をかけない。
クラスターの総キャパシティーが、その名前空間のクォータの合計より少ない場合、リソースの競合が発生する場合があります。このとき、リソースの先着順で処理されます。
リソースの競合もクォータの変更も、作成済みのリソースには影響しません。
リソースクォータを有効にする
多くのKubernetesディストリビューションにおいてリソースクォータはデフォルトで有効になっています。APIサーバーで--enable-admission-plugins=の値にResourceQuotaが含まれるときに有効になります。
特定の名前空間にResourceQuotaがあるとき、そのリソースクォータはその名前空間に適用されます。
コンピュートリソースクォータ
特定の名前空間において、コンピュートリソース の合計に上限を設定できます。
下記のリソースタイプがサポートされています。
リソース名
説明
limits.cpu停止していない状態の全てのPodで、CPUリミットの合計がこの値を超えることができません。
limits.memory停止していない状態の全てのPodで、メモリーの合計がこの値を超えることができません。
requests.cpu停止していない状態の全てのPodで、CPUリクエストの合計がこの値を超えることができません。
requests.memory停止していない状態の全てのPodで、メモリーリクエストの合計がこの値を超えることができません。
hugepages-<size>停止していない状態の全てのPodで, 指定されたサイズのHuge Pageリクエスト数がこの値を超えることができません。
cpurequests.cpuと同じ。
memoryrequests.memoryと同じ。
拡張リソースのためのリソースクォータ
上記で取り上げたリソースに加えて、Kubernetes v1.10において、拡張リソース のためのリソースクォータのサポートが追加されました。
拡張リソースに対するオーバーコミットが禁止されているのと同様に、リソースクォータで拡張リソース用にrequestsとlimitsの両方を指定しても意味がありません。現在、拡張リソースに対してはrequests.というプレフィックスのついたクォータアイテムのみ設定できます。
GPUリソースを例にすると、もしリソース名がnvidia.com/gpuで、ユーザーが名前空間内でリクエストされるGPUの上限を4に指定するとき、下記のようにリソースクォータを定義します。
requests.nvidia.com/gpu: 4
さらなる詳細はクォータの確認と設定 を参照してください。
ストレージのリソースクォータ
特定の名前空間においてストレージリソース の総数に上限をかけることができます。
さらに、関連するストレージクラスに基づいて、ストレージリソースの消費量に上限をかけることもできます。
リソース名
説明
requests.storage全てのPersistentVolumeClaimにおいて、ストレージのリクエストの合計がこの値を超えないようにします。
persistentvolumeclaims特定の名前空間内で作成可能なPersistentVolumeClaim の総数。
<storage-class-name>.storageclass.storage.k8s.io/requests.storageストレージクラス名<storage-class-name>に関連する全てのPersistentVolumeClaimにおいて、ストレージリクエストの合計がこの値を超えないようにします。
<storage-class-name>.storageclass.storage.k8s.io/persistentvolumeclaimsストレージクラス名<storage-class-name>に関連する全てのPersistentVolumeClaimにおいて、特定の名前空間内で作成可能なPersistentVolumeClaim の総数。
例えば、もし管理者がgoldストレージクラスをbronzeストレージクラスと分けてリソースクォータを設定するとき、管理者はリソースクォータを下記のように指定できます。
gold.storageclass.storage.k8s.io/requests.storage: 500Gibronze.storageclass.storage.k8s.io/requests.storage: 100Gi
Kubernetes v1.8において、ローカルのエフェメラルストレージに対するリソースクォータのサポートがα版の機能として追加されました。
リソース名
説明
requests.ephemeral-storage名前空間内の全てのPodで、ローカルのエフェメラルストレージのリクエストの合計がこの値を超えないようにします。
limits.ephemeral-storage名前空間内の全てのPodで、ローカルのエフェメラルストレージのリミットの合計がこの値を超えないようにします。
ephemeral-storagerequests.ephemeral-storageと同じ。
オブジェクト数に対するクォータ
下記のシンタックスを使用して、名前空間に紐づいた全ての標準であるリソースタイプの中の特定のリソースの総数に対するリソースクォータを設定できます。
count/<resource>.<group> コアでないグループのリソース用count/<resource> コアグループのリソース用
オブジェクト数に対するクォータでユーザーが設定するリソースの例は下記の通りです。
count/persistentvolumeclaimscount/servicescount/secretscount/configmapscount/replicationcontrollerscount/deployments.appscount/replicasets.appscount/statefulsets.appscount/jobs.batchcount/cronjobs.batch
カスタムリソースに対して同じシンタックスを使用できます。例えば、example.comというAPIグループ内のwidgetsというカスタムリソースのリソースクォータを設定するにはcount/widgets.example.comと記述します。
count/*リソースクォータの使用において、オブジェクトがサーバーストレージに存在するときオブジェクトはクォータの計算対象となります。このようなタイプのリソースクォータはストレージリソース浪費の防止に有効です。例えば、もしSecretが大量に存在するとき、そのSecretリソースの総数に対してリソースクォータの制限をかけたい場合です。クラスター内でSecretが大量にあると、サーバーとコントローラーの起動を妨げることになります。適切に設定されていないCronJobから保護するためにジョブのクォータを設定できます。名前空間内で大量のJobを作成するCronJobは、サービスを利用不可能にする可能性があります。
また、限定されたリソースのセットにおいて汎用オブジェクトカウントのリソースクォータを実行可能です。
下記のタイプのリソースがサポートされています。
リソース名
説明
configmaps名前空間内で存在可能なConfigMapの総数。
persistentvolumeclaims名前空間内で存在可能なPersistentVolumeClaim の総数。
pods名前空間内で存在可能な停止していないPodの総数。.status.phase in (Failed, Succeeded)がtrueのとき、Podは停止状態にあります。
replicationcontrollers名前空間内で存在可能なReplicationControlerの総数。
resourcequotas名前空間内で存在可能なResourceQuotaの総数。
services名前空間内で存在可能なServiceの総数。
services.loadbalancers名前空間内で存在可能なtype:LoadBalancerであるServiceの総数。
services.nodeports名前空間内で存在可能なtype:NodePortであるServiceの総数。
secrets名前空間内で存在可能なSecretの総数。
例えば、podsのリソースクォータはPodの総数をカウントし、特定の名前空間内で作成されたPodの総数の最大数を設定します。またユーザーが多くのPodを作成し、クラスターのPodのIPが枯渇する状況を避けるためにpodsのリソースクォータを名前空間に設定したい場合があります。
クォータのスコープについて
各リソースクォータには関連するscopeのセットを関連づけることができます。クォータは、列挙されたscopeの共通部分と一致する場合にのみリソースの使用量を計測します。
スコープがクォータに追加されると、サポートするリソースの数がスコープに関連するリソースに制限されます。許可されたセット以外のクォータ上でリソースを指定するとバリデーションエラーになります。
スコープ
説明
Terminating.spec.activeDeadlineSeconds >= 0であるPodに一致します。
NotTerminating.spec.activeDeadlineSecondsがnilであるPodに一致します。
BestEffortベストエフォート型のサービス品質のPodに一致します。
NotBestEffortベストエフォート型のサービス品質でないPodに一致します。
PriorityClass指定された優先度クラス と関連付いているPodに一致します。
BestEffortスコープはリソースクォータを次のリソースに対するトラッキングのみに制限します:
Terminating、NotTerminating、NotBestEffort、PriorityClassスコープは、リソースクォータを次のリソースに対するトラッキングのみに制限します:
podscpumemoryrequests.cpurequests.memorylimits.cpulimits.memory
同じクォータでTerminatingとNotTerminatingの両方のスコープを指定することはできず、また同じクォータでBestEffortとNotBestEffortの両方のスコープを指定することもできないことに注意してください。
scopeSelectorはoperator フィールドにおいて下記の値をサポートしています。:
InNotInExistsDoesNotExist
scopeSelectorの定義においてscopeNameに下記のいずれかの値を使用する場合、operatorにExistsを指定してください。
TerminatingNotTerminatingBestEffortNotBestEffort
operatorがInまたはNotInの場合、valuesフィールドには少なくとも1つの値が必要です。例えば以下のように記述します:
scopeSelector :
matchExpressions :
- scopeName : PriorityClass
operator : In
values :
- middle
operatorがExistsまたはDoesNotExistの場合、valuesフィールドは指定しないでください 。
PriorityClass毎のリソースクォータ
FEATURE STATE: Kubernetes v1.17 [stable]
Podは特定の優先度 で作成されます。リソースクォータのSpec内にあるscopeSelectorフィールドを使用して、Podの優先度に基づいてPodのシステムリソースの消費をコントロールできます。
リソースクォータのSpec内のscopeSelectorによってPodが選択されたときのみ、そのリソースクォータが一致し、消費されます。
リソースクォータがscopeSelectorフィールドを使用して優先度クラスに対してスコープされる場合、リソースクォータのオプジェクトは、次のリソースのみトラッキングするように制限されます:
podscpumemoryephemeral-storagelimits.cpulimits.memorylimits.ephemeral-storagerequests.cpurequests.memoryrequests.ephemeral-storage
この例ではリソースクォータのオブジェクトを作成し、特定の優先度を持つPodに一致させます。この例は下記のように動作します。
クラスター内のPodは"low"、"medium"、"high"の3つの優先度クラスのうち1つをもちます。
1つのリソースクォータのオブジェクトは優先度毎に作成されます。
下記のYAMLをquota.ymlというファイルに保存します。
apiVersion : v1
kind : List
items :
apiVersion : v1
kind : ResourceQuota
metadata :
name : pods-high
spec :
hard :
cpu : "1000"
memory : 200Gi
pods : "10"
scopeSelector :
matchExpressions :
- operator : In
scopeName : PriorityClass
values : ["high" ]
apiVersion : v1
kind : ResourceQuota
metadata :
name : pods-medium
spec :
hard :
cpu : "10"
memory : 20Gi
pods : "10"
scopeSelector :
matchExpressions :
- operator : In
scopeName : PriorityClass
values : ["medium" ]
apiVersion : v1
kind : ResourceQuota
metadata :
name : pods-low
spec :
hard :
cpu : "5"
memory : 10Gi
pods : "10"
scopeSelector :
matchExpressions :
- operator : In
scopeName : PriorityClass
values : ["low" ]
kubectl createを実行してYAMLの内容を適用します。
kubectl create -f ./quota.yml
resourcequota/pods-high created
resourcequota/pods-medium created
resourcequota/pods-low created
kubectl describe quotaを実行してUsedクォータが0であることを確認します。
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 1k
memory 0 200Gi
pods 0 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
プライオリティーが"high"であるPodを作成します。下記の内容をhigh-priority-pod.ymlというファイルに保存します。
apiVersion : v1
kind : Pod
metadata :
name : high-priority
spec :
containers :
- name : high-priority
image : ubuntu
command : ["/bin/sh" ]
args : ["-c" , "while true; do echo hello; sleep 10;done" ]
resources :
requests :
memory : "10Gi"
cpu : "500m"
limits :
memory : "10Gi"
cpu : "500m"
priorityClassName : high
kubectl createでマニフェストを適用します。
kubectl create -f ./high-priority-pod.yml
pods-highという名前のプライオリティーが"high"のクォータにおける"Used"項目の値が変更され、それ以外の2つの値は変更されていないことを確認してください。
Name: pods-high
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 500m 1k
memory 10Gi 200Gi
pods 1 10
Name: pods-low
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 5
memory 0 10Gi
pods 0 10
Name: pods-medium
Namespace: default
Resource Used Hard
-------- ---- ----
cpu 0 10
memory 0 20Gi
pods 0 10
リクエスト vs リミット
コンピュートリソースを分配する際に、各コンテナはCPUとメモリーそれぞれのリクエストとリミット値を指定します。クォータはそれぞれの値を設定できます。
クォータにrequests.cpuやrequests.memoryの値が指定されている場合は、コンテナはそれらのリソースに対する明示的な要求を行います。同様に、クォータにlimits.cpuやlimits.memoryの値が指定されている場合は、コンテナはそれらのリソースに対する明示的な制限を行います。
クォータの確認と設定
kubectlでは、クォータの作成、更新、確認をサポートしています。
kubectl create namespace myspace
cat <<EOF > compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
requests.nvidia.com/gpu: 4
EOF
kubectl create -f ./compute-resources.yaml --namespace= myspace
cat <<EOF > object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
spec:
hard:
configmaps: "10"
persistentvolumeclaims: "4"
pods: "4"
replicationcontrollers: "20"
secrets: "10"
services: "10"
services.loadbalancers: "2"
EOF
kubectl create -f ./object-counts.yaml --namespace= myspace
kubectl get quota --namespace= myspace
NAME AGE
compute-resources 30s
object-counts 32s
kubectl describe quota compute-resources --namespace= myspace
Name: compute-resources
Namespace: myspace
Resource Used Hard
-------- ---- ----
limits.cpu 0 2
limits.memory 0 2Gi
requests.cpu 0 1
requests.memory 0 1Gi
requests.nvidia.com/gpu 0 4
kubectl describe quota object-counts --namespace= myspace
Name: object-counts
Namespace: myspace
Resource Used Hard
-------- ---- ----
configmaps 0 10
persistentvolumeclaims 0 4
pods 0 4
replicationcontrollers 0 20
secrets 1 10
services 0 10
services.loadbalancers 0 2
また、kubectlはcount/<resource>.<group>というシンタックスを用いることにより、名前空間に依存した全ての主要なリソースに対するオブジェクト数のクォータをサポートしています。
kubectl create namespace myspace
kubectl create quota test --hard= count/deployments.apps= 2,count/replicasets.apps= 4,count/pods= 3,count/secrets= 4 --namespace= myspace
kubectl create deployment nginx --image= nginx --namespace= myspace --replicas= 2
kubectl describe quota --namespace= myspace
Name: test
Namespace: myspace
Resource Used Hard
-------- ---- ----
count/deployments.apps 1 2
count/pods 2 3
count/replicasets.apps 1 4
count/secrets 1 4
クォータとクラスター容量
ResourceQuotaはクラスター容量に依存しません。またユニット数の絶対値で表されます。そのためクラスターにノードを追加したことにより、各名前空間が自動的により多くのリソースを消費するような機能が提供されるわけではありません 。
下記のようなより複雑なポリシーが必要な状況があります。
複数チーム間でクラスターリソースの総量を分けあう。
各テナントが必要な時にリソース使用量を増やせるようにするが、偶発的なリソースの枯渇を防ぐために上限を設定する。
1つの名前空間に対してリソース消費の需要を検出し、ノードを追加し、クォータを増加させる。
このようなポリシーは、クォータの使用量の監視と、他のシグナルにしたがってクォータのハードの制限を調整する"コントローラー"を記述することにより、ResourceQuotaをビルディングブロックのように使用して実装できます。
リソースクォータは集約されたクラスターリソースを分割しますが、ノードに対しては何の制限も行わないことに注意して下さい。例: 複数の名前空間のPodは同一のノード上で稼働する可能性があります。
デフォルトで優先度クラスの消費を制限する
例えば"cluster-services"のように、条件に一致するクォータオブジェクトが存在する場合に限り、特定の優先度のPodを名前空間で許可することが望ましい場合があります。
このメカニズムにより、オペレーターは特定の高優先度クラスの使用を限られた数の名前空間に制限することができ、全ての名前空間でこれらの優先度クラスをデフォルトで使用することはできなくなります。
これを実施するには、kube-apiserverの--admission-control-config-fileというフラグを使い、下記の設定ファイルに対してパスを渡す必要がります。
apiVersion : apiserver.config.k8s.io/v1
kind : AdmissionConfiguration
plugins :
name : "ResourceQuota"
configuration :
apiVersion : apiserver.config.k8s.io/v1
kind : ResourceQuotaConfiguration
limitedResources :
- resource : pods
matchScopes :
- scopeName : PriorityClass
operator : In
values : ["cluster-services" ]
なお、"cluster-services"Podは、条件に一致するscopeSelectorを持つクォータオブジェクトが存在する名前空間でのみ許可されます。
scopeSelector :
matchExpressions :
- scopeName : PriorityClass
operator : In
values : ["cluster-services" ]
次の項目
9.3 - ノードリソースマネージャー
レイテンシーが致命的なワークロードや高スループットのワークロードをサポートするために、Kubernetesは一連のリソースマネージャーを提供します。リソースマネージャーはCPUやデバイス、メモリ(hugepages)などのリソースの特定の要件が設定されたPodのためにノードリソースの調整と最適化を目指しています。
メインのマネージャーであるトポロジーマネージャーはポリシー に沿って全体のリソース管理プロセスを調整するKubeletコンポーネントです。
個々のマネージャーの設定は下記のドキュメントで詳しく説明されてます。
10 - スケジューリング、プリエンプションと退避
Kubernetesにおいてスケジューリングとは、稼働させたいPodをノードにマッチさせ、kubeletが実行できるようにすることを指します。 プリエンプションは、優先度の低いPodを終了させて、より優先度の高いPodがノード上でスケジュールできるようにするプロセスです。 退避(eviction)とは、リソース不足のノードで1つ以上のPodを積極的に終了させるプロセスです。
Kubernetesにおいてスケジューリングとは、稼働させたいPod をノード にマッチさせ、kubelet が実行できるようにすることを指します。
プリエンプションは、優先度 の低いPodを終了させて、より優先度の高いPodがノード上でスケジュールできるようにするプロセスです。
退避とは、リソース不足のノードで1つ以上のPodを積極的に終了させるプロセスです。
スケジューリング
Pod Disruption
10.1 - Kubernetesのスケジューラー
Kubernetesにおいて、スケジューリング とは、Kubelet がPod を稼働させるためにNode に割り当てることを意味します。
スケジューリングの概要
スケジューラーは新規に作成されたPodで、Nodeに割り当てられていないものを監視します。スケジューラーは発見した各Podのために、稼働させるべき最適なNodeを見つけ出す責務を担っています。そのスケジューラーは下記で説明するスケジューリングの原理を考慮に入れて、NodeへのPodの割り当てを行います。
Podが特定のNodeに割り当てられる理由を理解したい場合や、カスタムスケジューラーを自身で作ろうと考えている場合、このページはスケジューリングに関して学ぶのに役立ちます。
kube-scheduler
kube-scheduler はKubernetesにおけるデフォルトのスケジューラーで、コントロールプレーン の一部分として稼働します。
kube-schedulerは、もし希望するのであれば自分自身でスケジューリングのコンポーネントを実装でき、それを代わりに使用できるように設計されています。
kube-schedulerは、新規に作成された各Podや他のスケジューリングされていないPodを稼働させるために最適なNodeを選択します。
しかし、Pod内の各コンテナにはそれぞれ異なるリソースの要件があり、各Pod自体にもそれぞれ異なる要件があります。そのため、既存のNodeは特定のスケジューリング要求によってフィルターされる必要があります。
クラスター内でPodに対する割り当て要求を満たしたNodeは 割り当て可能 なNodeと呼ばれます。
もし適切なNodeが一つもない場合、スケジューラーがNodeを割り当てることができるまで、そのPodはスケジュールされずに残ります。
スケジューラーはPodに対する割り当て可能なNodeをみつけ、それらの割り当て可能なNodeにスコアをつけます。その中から最も高いスコアのNodeを選択し、Podに割り当てるためのいくつかの関数を実行します。
スケジューラーは binding と呼ばれる処理中において、APIサーバーに対して割り当てが決まったNodeの情報を通知します。
スケジューリングを決定する上で考慮が必要な要素としては、個別または複数のリソース要求や、ハードウェア/ソフトウェアのポリシー制約、affinityやanti-affinityの設定、データの局所性や、ワークロード間での干渉などが挙げられます。
kube-schedulerによるスケジューリング
kube-schedulerは2ステップの操作によってPodに割り当てるNodeを選択します。
フィルタリング
スコアリング
フィルタリング ステップでは、Podに割り当て可能なNodeのセットを探します。例えばPodFitsResourcesフィルターは、Podのリソース要求を満たすのに十分なリソースをもつNodeがどれかをチェックします。このステップの後、候補のNodeのリストは、要求を満たすNodeを含みます。
たいてい、リストの要素は複数となります。もしこのリストが空の場合、そのPodはスケジュール可能な状態とはなりません。
スコアリング ステップでは、Podを割り当てるのに最も適したNodeを選択するために、スケジューラーはリストの中のNodeをランク付けします。
スケジューラーは、フィルタリングによって選ばれた各Nodeに対してスコアを付けます。このスコアはアクティブなスコア付けのルールに基づいています。
最後に、kube-schedulerは最も高いランクのNodeに対してPodを割り当てます。もし同一のスコアのNodeが複数ある場合は、kube-schedulerがランダムに1つ選択します。
スケジューラーのフィルタリングとスコアリングの動作に関する設定には2つのサポートされた手法があります。
スケジューリングポリシー は、フィルタリングのための Predicates とスコアリングのための Priorities の設定することができます。スケジューリングプロファイル は、QueueSort、 Filter、 Score、 Bind、 Reserve、 Permitやその他を含む異なるスケジューリングの段階を実装するプラグインを設定することができます。kube-schedulerを異なるプロファイルを実行するように設定することもできます。
次の項目
10.2 - ノード上へのPodのスケジューリング
Pod を特定のノード で実行するように 制限 したり、特定のノードで実行することを 優先 させたりといった制約をかけることができます。
これを実現するためにはいくつかの方法がありますが、推奨されている方法は、すべてラベルセレクター を使用して選択を容易にすることです。
多くの場合、このような制約を設定する必要はなく、スケジューラー が自動的に妥当な配置を行います(例えば、Podを複数のノードに分散させ、空きリソースが十分でないノードにPodを配置しないようにすることができます)。
しかし、例えばSSDが接続されているノードにPodが配置されるようにしたり、多くの通信を行う2つの異なるサービスのPodを同じアベイラビリティーゾーンに配置したりする等、どのノードに配置するかを制御したい状況もあります。
Kubernetesが特定のPodの配置場所を選択するために、以下の方法があります:
ノードラベル
他の多くのKubernetesオブジェクトと同様に、ノードにもラベル があります。手動でラベルを付ける ことができます。
また、Kubernetesはクラスター内のすべてのノードに対し、いくつかの標準ラベルを付けます。ノードラベルの一覧についてはよく使われるラベル、アノテーションとtaint を参照してください。
備考: これらのラベルの値はクラウドプロバイダー固有のもので、信頼性を保証できません。
例えば、kubernetes.io/hostnameの値はある環境ではノード名と同じになり、他の環境では異なる値になることがあります。
ノードの分離/制限
ノードにラベルを追加することで、Podを特定のノードまたはノードグループ上でのスケジューリングの対象にすることができます。この機能を使用すると、特定のPodが一定の独立性、安全性、または規制といった属性を持ったノード上でのみ実行されるようにすることができます。
ノード分離するのにラベルを使用する場合、kubelet が修正できないラベルキーを選択してください。
これにより、侵害されたノードが自身でそれらのラベルを設定することで、スケジューラーがそのノードにワークロードをスケジュールしてしまうのを防ぐことができます。
NodeRestrictionアドミッションプラグインnode-restriction.kubernetes.io/というプレフィックスを持つラベルを設定または変更するのを防ぎます。
ラベルプレフィックスをNode分離に利用するには:
ノード認可 を使用していることと、NodeRestriction アドミッションプラグインが 有効 になっていることを確認します。node-restriction.kubernetes.io/プレフィックスを持つラベルをノードに追加し、 nodeSelector でそれらのラベルを使用します。
例えば、example.com.node-restriction.kubernetes.io/fips=trueやexample.com.node-restriction.kubernetes.io/pci-dss=trueなどです。
nodeSelector
nodeSelectorは、ノード選択制約の中で最もシンプルな推奨形式です。
Podのspec(仕様)にnodeSelectorフィールドを追加することで、ターゲットノードが持つべきノードラベル を指定できます。
Kubernetesは指定された各ラベルを持つノードにのみ、Podをスケジューリングします。
詳しい情報についてはPodをノードに割り当てる を参照してください。
アフィニティとアンチアフィニティ
nodeSelectorはPodを特定のラベルが付与されたノードに制限する最も簡単な方法です。
アフィニティとアンチアフィニティでは、定義できる制約の種類が拡張されています。
アフィニティとアンチアフィニティのメリットは以下の通りです。
アフィニティとアンチアフィニティで使われる言語は、より表現力が豊かです。nodeSelectorは指定されたラベルを全て持つノードを選択するだけです。アフィニティとアンチアフィニティは選択ロジックをより細かく制御することができます。
ルールが柔軟 であったり優先 での指定ができたりするため、一致するノードが見つからない場合でも、スケジューラーはPodをスケジュールします。
ノード自体のラベルではなく、ノード(または他のトポロジカルドメイン)上で稼働している他のPodのラベルを使ってPodを制約することができます。これにより、ノード上にどのPodを共存させるかのルールを定義することができます。
アフィニティ機能は、2種類のアフィニティで構成されています:
ノードアフィニティ はnodeSelectorフィールドと同様に機能しますが、より表現力が豊かで、より柔軟にルールを指定することができます。Pod間アフィニティとアンチアフィニティ は、他のPodのラベルを元に、Podを制約することができます。
ノードアフィニティ
ノードアフィニティは概念的には、ノードのラベルによってPodがどのノードにスケジュールされるかを制限するnodeSelectorと同様です。
ノードアフィニティには2種類あります:
requiredDuringSchedulingIgnoredDuringExecution:
スケジューラーは、ルールが満たされない限り、Podをスケジュールすることができません。これはnodeSelectorと同じように機能しますが、より表現力豊かな構文になっています。preferredDuringSchedulingIgnoredDuringExecution:
スケジューラーは、対応するルールを満たすノードを探そうとします。 一致するノードが見つからなくても、スケジューラーはPodをスケジュールします。
備考: 上記の2種類にあるIgnoredDuringExecutionは、KubernetesがPodをスケジュールした後にノードラベルが変更されても、Podは実行し続けることを意味します。
Podのspec(仕様)にある.spec.affinity.nodeAffinityフィールドを使用して、ノードアフィニティを指定することができます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:
apiVersion : v1
kind : Pod
metadata :
name : with-node-affinity
spec :
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : topology.kubernetes.io/zone
operator : In
values :
- antarctica-east1
- antarctica-west1
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 1
preference :
matchExpressions :
- key : another-node-label-key
operator : In
values :
- another-node-label-value
containers :
- name : with-node-affinity
image : registry.k8s.io/pause:2.0
この例では、以下のルールが適用されます:
ノードにはtopology.kubernetes.io/zoneをキーとするラベルが必要 で、そのラベルの値はantarctica-east1またはantarctica-west1のいずれかでなければなりません。
ノードにはキー名がanother-node-label-keyで、値がanother-node-label-valueのラベルを持つことが望ましい です。
operatorフィールドを使用して、Kubernetesがルールを解釈する際に使用できる論理演算子を指定することができます。In、NotIn、Exists、DoesNotExist、Gt、Ltが使用できます。
NotInとDoesNotExistを使って、ノードのアンチアフィニティ動作を定義することができます。また、ノードのTaint を使用して、特定のノードからPodをはじくこともできます。
備考: nodeSelectorとnodeAffinityの両方を指定した場合、両方の 条件を満たさないとPodはノードにスケジュールされません。
nodeAffinityタイプに関連付けられたnodeSelectorTerms内に、複数の条件を指定した場合、Podは指定した条件のいずれかを満たしたノードへスケジュールされます(条件はORされます)。
nodeSelectorTerms内の条件に関連付けられた1つのmatchExpressionsフィールド内に、複数の条件を指定した場合、Podは全ての条件を満たしたノードへスケジュールされます(条件はANDされます)。
詳細についてはノードアフィニティを利用してPodをノードに割り当てる を参照してください。
ノードアフィニティの重み
preferredDuringSchedulingIgnoredDuringExecutionアフィニティタイプの各インスタンスに、1から100の範囲のweightを指定できます。
Podの他のスケジューリング要件をすべて満たすノードを見つけると、スケジューラーはそのノードが満たすすべての優先ルールを繰り返し実行し、対応する式のweight値を合計に加算します。
最終的な合計は、そのノードの他の優先度関数のスコアに加算されます。合計スコアが最も高いノードが、スケジューラーがPodのスケジューリングを決定する際に優先されます。
例えば、次のようなPodのspec(仕様)を考えてみましょう:
apiVersion : v1
kind : Pod
metadata :
name : with-affinity-anti-affinity
spec :
affinity :
nodeAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : kubernetes.io/os
operator : In
values :
- linux
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 1
preference :
matchExpressions :
- key : label-1
operator : In
values :
- key-1
- weight : 50
preference :
matchExpressions :
- key : label-2
operator : In
values :
- key-2
containers :
- name : with-node-affinity
image : registry.k8s.io/pause:2.0
preferredDuringSchedulingIgnoredDuringExecutionルールにマッチするノードとして、一つはlabel-1:key-1ラベル、もう一つはlabel-2:key-2ラベルの2つの候補がある場合、スケジューラーは各ノードのweightを考慮し、その重みとノードの他のスコアを加え、最終スコアが最も高いノードにPodをスケジューリングします。
備考: この例でKubernetesにPodを正常にスケジュールさせるには、kubernetes.io/os=linuxラベルを持つ既存のノードが必要です。
スケジューリングプロファイルごとのノードアフィニティ
FEATURE STATE: Kubernetes v1.20 [beta]
複数のスケジューリングプロファイル を設定する場合、プロファイルにノードアフィニティを関連付けることができます。これは、プロファイルが特定のノード群にのみ適用される場合に便利です。スケジューラーの設定 にあるNodeAffinityプラグインargsフィールドにaddedAffinityを追加すると実現できます。例えば:
apiVersion : kubescheduler.config.k8s.io/v1beta3
kind : KubeSchedulerConfiguration
profiles :
- schedulerName : default-scheduler
- schedulerName : foo-scheduler
pluginConfig :
- name : NodeAffinity
args :
addedAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
nodeSelectorTerms :
- matchExpressions :
- key : scheduler-profile
operator : In
values :
- foo
addedAffinityは、Podの仕様(spec)で指定されたノードアフィニティに加え、.spec.schedulerNameをfoo-schedulerに設定したすべてのPodに適用されます。つまり、Podにマッチするためには、ノードはaddedAffinityとPodの.spec.NodeAffinityを満たす必要があるのです。
addedAffinityはエンドユーザーには見えないので、その動作はエンドユーザーにとって予期しないものになる可能性があります。スケジューラープロファイル名と明確な相関関係のあるノードラベルを使用すべきです。
備考: DaemonSetのPodを作成する DaemonSetコントローラーは、スケジューリングプロファイルをサポートしていません。DaemonSetコントローラーがPodを作成すると、デフォルトのKubernetesスケジューラーがそれらのPodを配置し、DaemonSetコントローラーの
nodeAffinityルールに優先して従います。
Pod間のアフィニティとアンチアフィニティ
Pod間のアフィニティとアンチアフィニティは、ノードのラベルではなく、すでにノード上で稼働しているPod のラベルに従って、Podがどのノードにスケジュールされるかを制限できます。
Xはノードや、ラック、クラウドプロバイダーのゾーンやリージョン等を表すトポロジードメインで、YはKubernetesが満たそうとするルールである場合、Pod間のアフィニティとアンチアフィニティのルールは、"XにてルールYを満たすPodがすでに稼働している場合、このPodもXで実行すべき(アンチアフィニティの場合はすべきではない)"という形式です。
これらのルール(Y)は、オプションの関連する名前空間のリストを持つラベルセレクター で表現されます。PodはKubernetesの名前空間オブジェクトであるため、Podラベルも暗黙的に名前空間を持ちます。Kubernetesが指定された名前空間でラベルを探すため、Podラベルのラベルセレクターは、名前空間を指定する必要があります。
トポロジードメイン(X)はtopologyKeyで表現され、システムがドメインを示すために使用するノードラベルのキーになります。具体例はよく知られたラベル、アノテーションとTaint を参照してください。
備考: Pod間アフィニティとアンチアフィニティはかなりの処理量を必要とするため、大規模クラスターでのスケジューリングが大幅に遅くなる可能性があります
そのため、数百台以上のノードから成るクラスターでの使用は推奨されません。
備考: Podのアンチアフィニティは、ノードに必ず一貫性の持つラベルが付与されている必要があります。
言い換えると、クラスターの全てのノードが、topologyKeyに合致する適切なラベルが必要になります。
一部、または全部のノードにtopologyKeyラベルが指定されていない場合、意図しない挙動に繋がる可能性があります。
Pod間のアフィニティとアンチアフィニティの種類
ノードアフィニティ と同様に、Podアフィニティとアンチアフィニティにも下記の2種類があります:
requiredDuringSchedulingIgnoredDuringExecutionpreferredDuringSchedulingIgnoredDuringExecution
例えば、requiredDuringSchedulingIgnoredDuringExecutionアフィニティを使用して、2つのサービスのPodはお互いのやり取りが多いため、同じクラウドプロバイダーゾーンに併置するようにスケジューラーに指示することができます。
同様に、preferredDuringSchedulingIgnoredDuringExecutionアンチアフィニティを使用して、あるサービスのPodを複数のクラウドプロバイダーゾーンに分散させることができます。
Pod間アフィニティを使用するには、Pod仕様(spec)のaffinity.podAffinityフィールドで指定します。Pod間アンチアフィニティを使用するには、Pod仕様(spec)のaffinity.podAntiAffinityフィールドで指定します。
Podアフィニティ使用例
次のようなPod仕様(spec)を考えてみましょう:
apiVersion : v1
kind : Pod
metadata :
name : with-pod-affinity
spec :
affinity :
podAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : security
operator : In
values :
- S1
topologyKey : topology.kubernetes.io/zone
podAntiAffinity :
preferredDuringSchedulingIgnoredDuringExecution :
- weight : 100
podAffinityTerm :
labelSelector :
matchExpressions :
- key : security
operator : In
values :
- S2
topologyKey : topology.kubernetes.io/zone
containers :
- name : with-pod-affinity
image : registry.k8s.io/pause:2.0
この例では、PodアフィニティルールとPodアンチアフィニティルールを1つずつ定義しています。
Podアフィニティルールは"ハード"なrequiredDuringSchedulingIgnoredDuringExecutionを使用し、アンチアフィニティルールは"ソフト"なpreferredDuringSchedulingIgnoredDuringExecutionを使用しています。
アフィニティルールは、スケジューラーがノードにPodをスケジュールできるのは、そのノードが、security=S1ラベルを持つ1つ以上の既存のPodと同じゾーンにある場合のみであることを示しています。より正確には、現在Podラベルsecurity=S1を持つPodが1つ以上あるノードが、そのゾーン内に少なくとも1つ存在する限り、スケジューラーはtopology.kubernetes.io/zone=Vラベルを持つノードにPodを配置しなければなりません。
アンチアフィニティルールは、security=S2ラベルを持つ1つ以上のPodと同じゾーンにあるノードには、スケジューラーがPodをスケジュールしないようにすることを示しています。より正確には、PodラベルSecurity=S2を持つPodが稼働している他のノードが、同じゾーン内に存在する場合、スケジューラーはtopology.kubernetes.io/zone=Rラベルを持つノードにはPodを配置しないようにしなければなりません。
Podアフィニティとアンチアフィニティの使用例についてもっと知りたい方はデザイン案 を参照してください。
Podアフィニティとアンチアフィニティのoperatorフィールドで使用できるのは、In、NotIn、 Exists、 DoesNotExistです。
原則として、topologyKeyには任意のラベルキーが指定できますが、パフォーマンスやセキュリティの観点から、以下の例外があります:
Podアフィニティとアンチアフィニティでは、requiredDuringSchedulingIgnoredDuringExecutionとpreferredDuringSchedulingIgnoredDuringExecution内のどちらも、topologyKeyフィールドが空であることは許可されていません。
PodアンチアフィニティルールのrequiredDuringSchedulingIgnoredDuringExecutionでは、アドミッションコントローラーLimitPodHardAntiAffinityTopologyがtopologyKeyをkubernetes.io/hostnameに制限しています。アドミッションコントローラーを修正または無効化すると、トポロジーのカスタマイズができるようになります。
labelSelectorとtopologyKeyに加え、labelSelectorとtopologyKeyと同じレベルのnamespacesフィールドを使用して、labelSelectorが合致すべき名前空間のリストを任意に指定することができます。省略または空の場合、namespacesがデフォルトで、アフィニティとアンチアフィニティが定義されたPodの名前空間に設定されます。
名前空間セレクター
FEATURE STATE: Kubernetes v1.24 [stable]
namespaceSelectorを使用し、ラベルで名前空間の集合に対して検索することによって、名前空間を選択することができます。
アフィニティ項はnamespaceSelectorとnamespacesフィールドによって選択された名前空間に適用されます。
要注意なのは、空のnamespaceSelector({})はすべての名前空間にマッチし、nullまたは空のnamespacesリストとnullのnamespaceSelectorは、ルールが定義されているPodの名前空間にマッチします。
実践的なユースケース
Pod間アフィニティとアンチアフィニティは、ReplicaSet、StatefulSet、Deploymentなどのより高レベルなコレクションと併せて使用するとさらに有用です。これらのルールにより、ワークロードのセットが同じ定義されたトポロジーに併置されるように設定できます。たとえば、2つの関連するPodを同じノードに配置することが好ましい場合です。
例えば、3つのノードで構成されるクラスターを想像してください。そのクラスターを使用してウェブアプリケーションを実行し、さらにインメモリーキャッシュ(Redisなど)を使用します。この例では、ウェブアプリケーションとメモリーキャッシュの間のレイテンシーは実用的な範囲の低さも想定しています。Pod間アフィニティやアンチアフィニティを使って、ウェブサーバーとキャッシュをなるべく同じ場所に配置することができます。
以下のRedisキャッシュのDeploymentの例では、各レプリカはラベルapp=storeが付与されています。podAntiAffinityルールは、app=storeラベルを持つ複数のレプリカを単一ノードに配置しないよう、スケジューラーに指示します。これにより、各キャッシュが別々のノードに作成されます。
apiVersion : apps/v1
kind : Deployment
metadata :
name : redis-cache
spec :
selector :
matchLabels :
app : store
replicas : 3
template :
metadata :
labels :
app : store
spec :
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- store
topologyKey : "kubernetes.io/hostname"
containers :
- name : redis-server
image : redis:3.2-alpine
次のウェブサーバーのDeployment例では、app=web-storeラベルが付与されたレプリカを作成します。Podアフィニティルールは、各レプリカを、app=storeラベルが付与されたPodを持つノードに配置するようスケジューラーに指示します。Podアンチアフィニティルールは、1つのノードに複数のapp=web-storeサーバーを配置しないようにスケジューラーに指示します。
apiVersion : apps/v1
kind : Deployment
metadata :
name : web-server
spec :
selector :
matchLabels :
app : web-store
replicas : 3
template :
metadata :
labels :
app : web-store
spec :
affinity :
podAntiAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- web-store
topologyKey : "kubernetes.io/hostname"
podAffinity :
requiredDuringSchedulingIgnoredDuringExecution :
- labelSelector :
matchExpressions :
- key : app
operator : In
values :
- store
topologyKey : "kubernetes.io/hostname"
containers :
- name : web-app
image : nginx:1.16-alpine
上記2つのDeploymentが生成されると、以下のようなクラスター構成になり、各ウェブサーバーはキャッシュと同位置に、3つの別々のノードに配置されます。
node-1
node-2
node-3
webserver-1 webserver-2 webserver-3
cache-1 cache-2 cache-3
全体的な効果として、各キャッシュインスタンスは、同じノード上で実行している単一のクライアントによってアクセスされる可能性が高いです。この方法は、スキュー(負荷の偏り)とレイテンシーの両方を最小化することを目的としています。
Podアンチアフィニティを使用する理由は他にもあります。
この例と同様の方法で、アンチアフィニティを用いて高可用性を実現したStatefulSetの使用例はZooKeeperチュートリアル を参照してください。
nodeName
nodeNameはアフィニティやnodeSelectorよりも直接的なノード選択形式になります。nodeNameはPod仕様(spec)内のフィールドです。nodeNameフィールドが空でない場合、スケジューラーはPodを考慮せずに、指定されたノードにあるkubeletがそのノードにPodを配置しようとします。nodeNameを使用すると、nodeSelectorやアフィニティおよびアンチアフィニティルールを使用するよりも優先されます。
nodeNameを使ってノードを選択する場合の制約は以下の通りです:
指定されたノードが存在しない場合、Podは実行されず、場合によっては自動的に削除されることがあります。
指定されたノードがPodを収容するためのリソースを持っていない場合、Podの起動は失敗し、OutOfmemoryやOutOfcpuなどの理由が表示されます。
クラウド環境におけるノード名は、常に予測可能で安定したものではありません。
備考: nodeNameは、カスタムスケジューラーや、設定済みのスケジューラーをバイパスする必要がある高度なユースケースで使用することを目的としています。
スケジューラーをバイパスすると、割り当てられたノードに過剰なPodの配置をしようとした場合には、Podの起動に失敗することがあります。
ノードアフィニティ または
nodeSelectorフィールドを使用すれば、スケジューラーをバイパスせずに、特定のノードにPodを割り当てることができます。
以下は、nodeNameフィールドを使用したPod仕様(spec)の例になります:
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
containers :
- name : nginx
image : nginx
nodeName : kube-01
上記のPodはkube-01というNodeでのみ実行されます。
Podトポロジー分散制約
トポロジー分散制約 を使って、リージョン、ゾーン、ノードなどの障害ドメイン間、または定義したその他のトポロジードメイン間で、クラスター全体にどのようにPod を分散させるかを制御することができます。これにより、パフォーマンス、予想される可用性、または全体的な使用率を向上させることができます。
詳しい仕組みについては、トポロジー分散制約 を参照してください。
次の項目
10.3 - Podのオーバーヘッド
FEATURE STATE: Kubernetes v1.24 [stable]
PodをNode上で実行する時に、Pod自身は大量のシステムリソースを消費します。これらのリソースは、Pod内のコンテナ(群)を実行するために必要なリソースとして追加されます。Podのオーバーヘッドは、コンテナの要求と制限に加えて、Podのインフラストラクチャで消費されるリソースを計算するための機能です。
Kubernetesでは、PodのRuntimeClass に関連するオーバーヘッドに応じて、アドミッション 時にPodのオーバーヘッドが設定されます。
Podのオーバーヘッドを有効にした場合、Podのスケジューリング時にコンテナのリソース要求の合計に加えて、オーバーヘッドも考慮されます。同様に、Kubeletは、Podのcgroupのサイズ決定時およびPodの退役の順位付け時に、Podのオーバーヘッドを含めます。
Podのオーバーヘッドの有効化
クラスター全体でPodOverheadのフィーチャーゲート が有効になっていること(1.18時点ではデフォルトでオンになっています)と、overheadフィールドを定義するRuntimeClassが利用されていることを確認する必要があります。
使用例
Podのオーバーヘッド機能を使用するためには、overheadフィールドが定義されたRuntimeClassが必要です。例として、仮想マシンとゲストOSにPodあたり約120MiBを使用する仮想化コンテナランタイムで、次のようなRuntimeClassを定義できます。
apiVersion : node.k8s.io/v1
kind : RuntimeClass
metadata :
name : kata-fc
handler : kata-fc
overhead :
podFixed :
memory : "120Mi"
cpu : "250m"
kata-fcRuntimeClassハンドラーを指定して作成されたワークロードは、リソースクォータの計算や、Nodeのスケジューリング、およびPodのcgroupのサイズ決定にメモリーとCPUのオーバーヘッドが考慮されます。
次のtest-podのワークロードの例を実行するとします。
apiVersion : v1
kind : Pod
metadata :
name : test-pod
spec :
runtimeClassName : kata-fc
containers :
- name : busybox-ctr
image : busybox:1.28
stdin : true
tty : true
resources :
limits :
cpu : 500m
memory : 100Mi
- name : nginx-ctr
image : nginx
resources :
limits :
cpu : 1500m
memory : 100Mi
アドミッション時、RuntimeClassアドミッションコントローラー は、RuntimeClass内に記述されたオーバーヘッドを含むようにワークロードのPodSpecを更新します。もし既にPodSpec内にこのフィールドが定義済みの場合、そのPodは拒否されます。この例では、RuntimeClassの名前しか指定されていないため、アドミッションコントローラーはオーバーヘッドを含むようにPodを変更します。
RuntimeClassのアドミッションコントローラーの後、更新されたPodSpecを確認できます。
kubectl get pod test-pod -o jsonpath = '{.spec.overhead}'
出力は次の通りです:
map[cpu:250m memory:120Mi]
ResourceQuotaが定義されている場合、コンテナ要求の合計とオーバーヘッドフィールドがカウントされます。
kube-schedulerが新しいPodを実行すべきNodeを決定する際、スケジューラーはそのPodのオーバーヘッドと、そのPodに対するコンテナ要求の合計を考慮します。この例だと、スケジューラーは、要求とオーバーヘッドを追加し、2.25CPUと320MiBのメモリを持つNodeを探します。
PodがNodeにスケジュールされると、そのNodeのkubeletはPodのために新しいcgroup を生成します。基盤となるコンテナランタイムがコンテナを作成するのは、このPod内です。
リソースにコンテナごとの制限が定義されている場合(制限が定義されているGuaranteed QoSまたはBustrable QoS)、kubeletはそのリソース(CPUはcpu.cfs_quota_us、メモリはmemory.limit_in_bytes)に関連するPodのcgroupの上限を設定します。この上限は、コンテナの制限とPodSpecで定義されたオーバーヘッドの合計に基づきます。
CPUについては、PodがGuaranteedまたはBurstable QoSの場合、kubeletはコンテナの要求の合計とPodSpecに定義されたオーバーヘッドに基づいてcpu.shareを設定します。
次の例より、ワークロードに対するコンテナの要求を確認できます。
kubectl get pod test-pod -o jsonpath = '{.spec.containers[*].resources.limits}'
コンテナの要求の合計は、CPUは2000m、メモリーは200MiBです。
map[cpu: 500m memory:100Mi] map[cpu:1500m memory:100Mi]
Nodeで観測される値と比較してみましょう。
kubectl describe node | grep test-pod -B2
出力では、2250mのCPUと320MiBのメモリーが要求されており、Podのオーバーヘッドが含まれていることが分かります。
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
default test-pod 2250m (56%) 2250m (56%) 320Mi (1%) 320Mi (1%) 36m
Podのcgroupの制限を確認
ワークロードで実行中のNode上にある、Podのメモリーのcgroupを確認します。次に示す例では、CRI互換のコンテナランタイムのCLIを提供するNodeでcrictl
まず、特定のNodeで、Podの識別子を決定します。
# PodがスケジュールされているNodeで実行
POD_ID = " $( sudo crictl pods --name test-pod -q) "
ここから、Podのcgroupのパスが決定します。
# PodがスケジュールされているNodeで実行
sudo crictl inspectp -o= json $POD_ID | grep cgroupsPath
結果のcgroupパスにはPodのポーズ中コンテナも含まれます。Podレベルのcgroupは1つ上のディレクトリです。
"cgroupsPath": "/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/7ccf55aee35dd16aca4189c952d83487297f3cd760f1bbf09620e206e7d0c27a"
今回のケースでは、Podのcgroupパスは、kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2となります。メモリーのPodレベルのcgroupの設定を確認しましょう。
# PodがスケジュールされているNodeで実行
# また、Podに割り当てられたcgroupと同じ名前に変更
cat /sys/fs/cgroup/memory/kubepods/podd7f4b509-cf94-4951-9417-d1087c92a5b2/memory.limit_in_bytes
予想通り320MiBです。
335544320
Observability
Podのオーバヘッドが利用されているタイミングを特定し、定義されたオーバーヘッドで実行されているワークロードの安定性を観察するため、kube-state-metrics にはkube_pod_overheadというメトリクスが用意されています。この機能はv1.9のkube-state-metricsでは利用できませんが、次のリリースで期待されています。それまでは、kube-state-metricsをソースからビルドする必要があります。
次の項目
10.4 - TaintとToleration
ノードアフィニティ Pod の属性であり、あるノード 群を引きつけます (優先条件または必須条件)。反対に taint はノードがある種のPodを排除できるようにします。
toleration はPodに適用され、一致するtaintが付与されたノードへPodがスケジューリングされることを認めるものです。ただしそのノードへ必ずスケジューリングされるとは限りません。
taintとtolerationは組になって機能し、Podが不適切なノードへスケジューリングされないことを保証します。taintはノードに一つまたは複数個付与することができます。これはそのノードがtaintを許容しないPodを受け入れるべきではないことを示します。
コンセプト
ノードにtaintを付与するにはkubectl taint コマンドを使用します。
例えば、次のコマンドは
kubectl taint nodes node1 key1 = value1:NoSchedule
node1にtaintを設定します。このtaintのキーはkey1、値はvalue1、taintの効果はNoScheduleです。
これはnode1にはPodに合致するtolerationがなければスケジューリングされないことを意味します。
上記のコマンドで付与したtaintを外すには、下記のコマンドを使います。
kubectl taint nodes node1 key1 = value1:NoSchedule-
PodのtolerationはPodSpecの中に指定します。下記のtolerationはどちらも、上記のkubectl taintコマンドで追加したtaintと合致するため、どちらのtolerationが設定されたPodもnode1へスケジューリングされることができます。
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoSchedule"
tolerations :
key : "key1"
operator : "Exists"
effect : "NoSchedule"
tolerationを設定したPodの例を示します。
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
env : test
spec :
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
tolerations :
- key : "example-key"
operator : "Exists"
effect : "NoSchedule"
operatorのデフォルトはEqualです。
tolerationがtaintと合致するのは、keyとeffectが同一であり、さらに下記の条件のいずれかを満たす場合です。
operatorがExists(valueを指定すべきでない場合)operatorがEqualであり、かつvalueが同一である場合
備考: 2つ特殊な場合があります。
空のkeyと演算子Existsは全てのkey、value、effectと一致するため、すべてのtaintと合致します。
空のeffectはkey1が一致する全てのeffectと合致します。
上記の例ではeffectにNoScheduleを指定しました。代わりに、effectにPreferNoScheduleを指定することができます。
これはNoScheduleの「ソフトな」バージョンであり、システムはtaintに対応するtolerationが設定されていないPodがノードへ配置されることを避けようとしますが、必須の条件とはしません。3つ目のeffectの値としてNoExecuteがありますが、これについては後述します。
同一のノードに複数のtaintを付与することや、同一のPodに複数のtolerationを設定することができます。
複数のtaintやtolerationが設定されている場合、Kubernetesはフィルタのように扱います。最初はノードの全てのtaintがある状態から始め、Podが対応するtolerationを持っているtaintは無視され外されていきます。無視されずに残ったtaintが効果を及ぼします。
具体的には、
effect NoScheduleのtaintが無視されず残った場合、KubernetesはそのPodをノードへスケジューリングしません。
effect NoScheduleのtaintは残らず、effect PreferNoScheduleのtaintは残った場合、Kubernetesはそのノードへのスケジューリングをしないように試みます。
effect NoExecuteのtaintが残った場合、既に稼働中のPodはそのノードから排除され、まだ稼働していないPodはスケジューリングされないようになります。
例として、下記のようなtaintが付与されたノードを考えます。
kubectl taint nodes node1 key1 = value1:NoSchedule
kubectl taint nodes node1 key1 = value1:NoExecute
kubectl taint nodes node1 key2 = value2:NoSchedule
Podには2つのtolerationが設定されています。
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoSchedule"
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoExecute"
この例では、3つ目のtaintと合致するtolerationがないため、Podはノードへはスケジューリングされません。
しかし、これらのtaintが追加された時点で、そのノードでPodが稼働していれば続けて稼働することが可能です。 これは、Podのtolerationと合致しないtaintは3つあるtaintのうちの3つ目のtaintのみであり、それがNoScheduleであるためです。
一般に、effect NoExecuteのtaintがノードに追加されると、合致するtolerationが設定されていないPodは即時にノードから排除され、合致するtolerationが設定されたPodが排除されることは決してありません。
しかし、effectNoExecuteに対するtolerationはtolerationSecondsフィールドを任意で指定することができ、これはtaintが追加された後にそのノードにPodが残る時間を示します。例えば、
tolerations :
key : "key1"
operator : "Equal"
value : "value1"
effect : "NoExecute"
tolerationSeconds : 3600
この例のPodが稼働中で、対応するtaintがノードへ追加された場合、Podはそのノードに3600秒残り、その後排除されます。仮にtaintがそれよりも前に外された場合、Podは排除されません。
ユースケースの例
taintとtolerationは、実行されるべきではないノードからPodを遠ざけたり、排除したりするための柔軟な方法です。いくつかのユースケースを示します。
専有ノード : あるノード群を特定のユーザーに専有させたい場合、そのノード群へtaintを追加し(kubectl taint nodes nodename dedicated=groupName:NoSchedule) 対応するtolerationをPodへ追加します(これを実現する最も容易な方法はカスタム
アドミッションコントローラー を書くことです)。
tolerationが設定されたPodはtaintの設定された(専有の)ノードと、クラスターにあるその他のノードの使用が認められます。もしPodが必ず専有ノードのみ を使うようにしたい場合は、taintと同様のラベルをそのノード群に設定し(例: dedicated=groupName)、アドミッションコントローラーはノードアフィニティを使ってPodがdedicated=groupNameのラベルの付いたノードへスケジューリングすることが必要であるということも設定する必要があります。
特殊なハードウェアを備えるノード : クラスターの中の少数のノードが特殊なハードウェア(例えばGPU)を備える場合、そのハードウェアを必要としないPodがスケジューリングされないようにして、後でハードウェアを必要とするPodができたときの余裕を確保したいことがあります。
これは特殊なハードウェアを持つノードにtaintを追加(例えば kubectl taint nodes nodename special=true:NoSchedule または
kubectl taint nodes nodename special=true:PreferNoSchedule)して、ハードウェアを使用するPodに対応するtolerationを追加することで可能です。
専有ノードのユースケースと同様に、tolerationを容易に適用する方法はカスタム
アドミッションコントローラー を使うことです。
例えば、特殊なハードウェアを表すために拡張リソース
を使い、ハードウェアを備えるノードに拡張リソースの名称のtaintを追加して、
拡張リソースtoleration
アドミッションコントローラーを実行することが推奨されます。ノードにはtaintが付与されているため、tolerationのないPodはスケジューリングされません。しかし拡張リソースを要求するPodを作成しようとすると、拡張リソースtoleration アドミッションコントローラーはPodに自動的に適切なtolerationを設定し、Podはハードウェアを備えるノードへスケジューリングされます。
これは特殊なハードウェアを備えたノードではそれを必要とするPodのみが稼働し、Podに対して手作業でtolerationを追加しなくて済むようにします。
taintを基にした排除 : ノードに問題が起きたときにPodごとに排除する設定を行うことができます。次のセクションにて説明します。
taintを基にした排除
FEATURE STATE: Kubernetes v1.18 [stable]
上述したように、effect NoExecuteのtaintはノードで実行中のPodに次のような影響を与えます。
対応するtolerationのないPodは即座に除外される
対応するtolerationがあり、それにtolerationSecondsが指定されていないPodは残り続ける
対応するtolerationがあり、それにtolerationSecondsが指定されているPodは指定された間、残される
Nodeコントローラーは特定の条件を満たす場合に自動的にtaintを追加します。
組み込まれているtaintは下記の通りです。
node.kubernetes.io/not-ready: ノードの準備ができていない場合。これはNodeCondition ReadyがFalseである場合に対応します。node.kubernetes.io/unreachable: ノードがノードコントローラーから到達できない場合。これはNodeConditionReadyがUnknownの場合に対応します。node.kubernetes.io/out-of-disk: ノードのディスクの空きがない場合。node.kubernetes.io/memory-pressure: ノードのメモリーが不足している場合。node.kubernetes.io/disk-pressure: ノードのディスクが不足している場合。node.kubernetes.io/network-unavailable: ノードのネットワークが利用できない場合。node.kubernetes.io/unschedulable: ノードがスケジューリングできない場合。node.cloudprovider.kubernetes.io/uninitialized: kubeletが外部のクラウド事業者により起動されたときに設定されるtaintで、このノードは利用不可能であることを示します。cloud-controller-managerによるコントローラーがこのノードを初期化した後にkubeletはこのtaintを外します。
ノードから追い出すときには、ノードコントローラーまたはkubeletは関連するtaintをNoExecute効果の状態で追加します。
不具合のある状態から通常の状態へ復帰した場合は、kubeletまたはノードコントローラーは関連するtaintを外すことができます。
備考: コントロールプレーンは新しいtaintをノードに加えるレートを制限しています。
このレート制限は一度に多くのノードが到達不可能になった場合(例えばネットワークの断絶)に、退役させられるノードの数を制御します。
PodにtolerationSecondsを指定することで不具合があるか応答のないノードに残る時間を指定することができます。
例えば、ローカルの状態を多数持つアプリケーションとネットワークが分断された場合を考えます。ネットワークが復旧して、Podを排除しなくて済むことを見込んで、長時間ノードから排除されないようにしたいこともあるでしょう。
この場合Podに設定するtolerationは次のようになります。
tolerations :
key : "node.kubernetes.io/unreachable"
operator : "Exists"
effect : "NoExecute"
tolerationSeconds : 6000
備考: Kubernetesはユーザーまたはコントローラーが明示的に指定しない限り、自動的にnode.kubernetes.io/not-readyとnode.kubernetes.io/unreachableに対するtolerationをtolerationSeconds=300にて設定します。
自動的に設定されるtolerationは、taintに対応する問題がノードで検知されても5分間はそのノードにPodが残されることを意味します。
DaemonSet のPodは次のtaintに対してNoExecuteのtolerationがtolerationSecondsを指定せずに設定されます。
node.kubernetes.io/unreachablenode.kubernetes.io/not-ready
これはDaemonSetのPodはこれらの問題によって排除されないことを保証します。
条件によるtaintの付与
ノードのライフサイクルコントローラーはノードの状態に応じてNoSchedule効果のtaintを付与します。
スケジューラーはノードの状態ではなく、taintを確認します。
ノードに何がスケジューリングされるかは、そのノードの状態に影響されないことを保証します。ユーザーは適切なtolerationをPodに付与することで、どの種類のノードの問題を無視するかを選ぶことができます。
DaemonSetのコントローラーは、DaemonSetが中断されるのを防ぐために自動的に次のNoScheduletolerationを全てのDaemonSetに付与します。
node.kubernetes.io/memory-pressurenode.kubernetes.io/disk-pressurenode.kubernetes.io/out-of-disk (重要なPodのみ )node.kubernetes.io/unschedulable (1.10またはそれ以降)node.kubernetes.io/network-unavailable (ホストネットワークのみ )
これらのtolerationを追加することは後方互換性を保証します。DaemonSetに任意のtolerationを加えることもできます。
次の項目
10.5 - スケジューリングフレームワーク
FEATURE STATE: Kubernetes v1.19 [stable]
スケジューリングフレームワークはKubernetesのスケジューラーに対してプラグイン可能なアーキテクチャです。
このアーキテクチャは、既存のスケジューラーに新たに「プラグイン」としてAPI群を追加するもので、プラグインはスケジューラー内部にコンパイルされます。このAPI群により、スケジューリングの「コア」の軽量かつ保守しやすい状態に保ちながら、ほとんどのスケジューリングの機能をプラグインとして実装することができます。このフレームワークの設計に関する技術的な情報についてはこちらのスケジューリングフレームワークの設計提案 をご覧ください。
フレームワークのワークフロー
スケジューリングフレームワークは、いくつかの拡張点を定義しています。スケジューラープラグインは、1つ以上の拡張点で呼び出されるように登録します。これらのプラグインの中には、スケジューリングの決定を変更できるものから、単に情報提供のみを行うだけのものなどがあります。
この1つのPodをスケジュールしようとする各動作はScheduling Cycle とBinding Cycle の2つのフェーズに分けられます。
Scheduling Cycle & Binding Cycle
Scheduling CycleではPodが稼働するNodeを決定し、Binding Cycleではそれをクラスターに適用します。この2つのサイクルを合わせて「スケジューリングコンテキスト」と呼びます。
Scheduling CycleではPodに対して1つ1つが順番に実行され、Binding Cyclesでは並列に実行されます。
Podがスケジューリング不能と判断された場合や、内部エラーが発生した場合、Scheduling CycleまたはBinding Cycleを中断することができます。その際、Podはキューに戻され再試行されます。
拡張点
次の図はPodに対するスケジューリングコンテキストとスケジューリングフレームワークが公開する拡張点を示しています。この図では「Filter」がフィルタリングのための「Predicate」、「Scoring」がスコアリングのための「Priorities」機能に相当します。
1つのプラグインを複数の拡張点に登録することで、より複雑なタスクやステートフルなタスクを実行することができます。
scheduling framework extension points
QueueSort
これらのプラグインはスケジューリングキュー内のPodをソートするために使用されます。このプラグインは、基本的にLess(Pod1, Pod2)という関数を提供します。また、このプラグインは、1つだけ有効化できます。
PreFilter
これらのプラグインは、Podに関する情報を前処理したり、クラスターやPodが満たすべき特定の条件をチェックするために使用されます。もし、PreFilterプラグインのいずれかがエラーを返した場合、Scheduling Cycleは中断されます。
Filter
FilterプラグインはPodを実行できないNodeを候補から除外します。各Nodeに対して、スケジューラーは設定された順番でFilterプラグインを呼び出します。もし、いずれかのFilterプラグインが途中でそのNodeを実行不可能とした場合、残りのプラグインではそのNodeは呼び出されません。Nodeは同時に評価されることがあります。
PostFilter
これらのプラグインはFilterフェーズで、Podに対して実行可能なNodeが見つからなかった場合にのみ呼び出されます。このプラグインは設定された順番で呼び出されます。もしいずれかのPostFilterプラグインが、あるNodeを「スケジュール可能(Schedulable)」と目星をつけた場合、残りのプラグインは呼び出されません。典型的なPostFilterの実装はプリエンプション方式で、他のPodを先取りして、Podをスケジューリングできるようにしようとします。
PreScore
これらのプラグインは、Scoreプラグインが使用する共有可能な状態を生成する「スコアリングの事前」作業を行うために使用されます。このプラグインがエラーを返した場合、Scheduling Cycleは中断されます。
Score
これらのプラグインはフィルタリングのフェーズを通過したNodeをランク付けするために使用されます。スケジューラーはそれぞれのNodeに対して、それぞれのscoringプラグインを呼び出します。スコアの最小値と最大値の範囲が明確に定義されます。NormalizeScore フェーズの後、スケジューラーは設定されたプラグインの重みに従って、全てのプラグインからNodeのスコアを足し合わせます。
NormalizeScore
これらのプラグインはスケジューラーが最終的なNodeの順位を計算する前にスコアを修正するために使用されます。この拡張点に登録されたプラグインは、同じプラグインのScore の結果を使用して呼び出されます。各プラグインはScheduling Cycle毎に、1回呼び出されます。
例えば、BlinkingLightScorerというプラグインが、点滅する光の数に基づいてランク付けをするとします。
func ScoreNode (_ * v1.pod, n * v1.Node) (int , error ) {
return getBlinkingLightCount (n)
}
ただし、NodeScoreMaxに比べ、点滅をカウントした最大値の方が小さい場合があります。これを解決するために、BlinkingLightScorerも拡張点に登録する必要があります。
func NormalizeScores (scores map [string ]int ) {
highest := 0
for _, score := range scores {
highest = max (highest, score)
}
for node, score := range scores {
scores[node] = score* NodeScoreMax/ highest
}
}
NormalizeScoreプラグインが途中でエラーを返した場合、Scheduling Cycleは中断されます。
備考: 「Reserveの事前」作業を行いたいプラグインは、NormalizeScore拡張点を使用してください。
Reserve
Reserve拡張を実装したプラグインには、ReserveとUnreserve という2つのメソッドがあり、それぞれReserve
とUnreserveと呼ばれる2つの情報スケジューリングフェーズを返します。
実行状態を保持するプラグイン(別名「ステートフルプラグイン」)は、これらのフェーズを使用して、Podに対してNodeのリソースが予約されたり予約解除された場合に、スケジューラーから通知を受け取ります。
Reserveフェーズは、スケジューラーが実際にPodを指定されたNodeにバインドする前に発生します。このフェーズはスケジューラーがバインドが成功するのを待つ間にレースコンディションの発生を防ぐためにあります。
各ReserveプラグインのReserveメソッドは成功することも失敗することもあります。もしどこかのReserveメソッドの呼び出しが失敗すると、後続のプラグインは実行されず、Reserveフェーズは失敗したものとみなされます。全てのプラグインのReserveメソッドが成功した場合、Reserveフェーズは成功とみなされ、残りのScheduling CycleとBinding Cycleが実行されます。
Unreserveフェーズは、Reserveフェーズまたは後続のフェーズが失敗した場合に、呼び出されます。この時、全ての ReserveプラグインのUnreserveメソッドが、Reserveメソッドの呼び出された逆の順序で実行されます。このフェーズは予約されたPodに関連する状態をクリーンアップするためにあります。
注意: Unreserveメソッドの実装は冪等性を持つべきであり、この処理で問題があった場合に失敗させてはなりません。
Permit
Permit プラグインは、各PodのScheduling Cycleの終了時に呼び出され、候補Nodeへのバインドを阻止もしくは遅延させるために使用されます。permitプラグインは次の3つのうちどれかを実行できます。
承認(approve)
拒否(deny) Reserveプラグイン 内のUnreserveフェーズで呼び出されます。
待機(wait) (タイムアウトあり) 待機(wait)は deny へ変わり、対象のPodはスケジューリングキューに戻されると共に、Reserveプラグイン のUnreserveフェーズが呼び出されます。
備考: どのプラグインも「待機中」Podリストにアクセスして、それらを承認(approve)することができますが(参考:
FrameworkHandle)、その中の予約済みPodのバインドを承認(approve)できるのはPermitプラグインだけであると予想します。承認(approve)されたPodは、
PreBind フェーズへ送られます。
PreBind
これらのプラグインは、Podがバインドされる前に必要な作業を行うために使用されます。例えば、Podの実行を許可する前に、ネットワークボリュームをプロビジョニングし、Podを実行予定のNodeにマウントすることができます。
もし、いずれかのPreBindプラグインがエラーを返した場合、Podは拒否 され、スケジューリングキューに戻されます。
Bind
これらのプラグインはPodをNodeにバインドするために使用されます。このプラグインは全てのPreBindプラグインの処理が完了するまで呼ばれません。それぞれのBindプラグインは設定された順序で呼び出されます。このプラグインは、与えられたPodを処理するかどうかを選択することができます。もしPodを処理することを選択した場合、残りのBindプラグインは全てスキップされます。
PostBind
これは単に情報提供のための拡張点です。Post-bindプラグインはPodのバインドが成功した後に呼び出されます。これはBinding Cycleの最後であり、関連するリソースのクリーンアップに使用されます。
プラグインAPI
プラグインAPIには2つの段階があります。まず、プラグインを登録し設定することです。そして、拡張点インターフェースを使用することです。このインターフェースは次のような形式をとります。
type Plugin interface {
Name () string
}
type QueueSortPlugin interface {
Plugin
Less (* v1.pod, * v1.pod) bool
}
type PreFilterPlugin interface {
Plugin
PreFilter (context.Context, * framework.CycleState, * v1.pod) error
}
// ...
プラグインの設定
スケジューラーの設定でプラグインを有効化・無効化することができます。Kubernetes v1.18以降を使用しているなら、ほとんどのスケジューリングプラグイン は使用されており、デフォルトで有効になっています。
デフォルトのプラグインに加えて、独自のスケジューリングプラグインを実装し、デフォルトのプラグインと一緒に使用することも可能です。詳しくはスケジューラープラグイン をご覧下さい。
Kubernetes v1.18以降を使用しているなら、プラグインのセットをスケジューラープロファイルとして設定し、様々な種類のワークロードに適合するように複数のプロファイルを定義することが可能です。詳しくは複数のプロファイル をご覧下さい。
10.6 - スケジューラーのパフォーマンスチューニング
FEATURE STATE: Kubernetes 1.14 [beta]
kube-scheduler はKubernetesのデフォルトのスケジューラーです。クラスター内のノード上にPodを割り当てる責務があります。
クラスター内に存在するノードで、Podのスケジューリング要求を満たすものはPodに対して割り当て可能 なノードと呼ばれます。スケジューラーはPodに対する割り当て可能なノードをみつけ、それらの割り当て可能なノードにスコアをつけます。その中から最も高いスコアのノードを選択し、Podに割り当てるためのいくつかの関数を実行します。スケジューラーはBinding と呼ばれる処理中において、APIサーバーに対して割り当てが決まったノードの情報を通知します。
このページでは、大規模のKubernetesクラスターにおけるパフォーマンス最適化のためのチューニングについて説明します。
大規模クラスターでは、レイテンシー(新規Podをすばやく配置)と精度(スケジューラーが不適切な配置を行うことはめったにありません)の間でスケジューリング結果を調整するスケジューラーの動作をチューニングできます。
このチューニング設定は、kube-scheduler設定のpercentageOfNodesToScoreで設定できます。KubeSchedulerConfiguration設定は、クラスター内のノードにスケジュールするための閾値を決定します。
閾値の設定
percentageOfNodesToScoreオプションは、0から100までの数値を受け入れます。0は、kube-schedulerがコンパイル済みのデフォルトを使用することを示す特別な値です。
percentageOfNodesToScoreに100より大きな値を設定した場合、kube-schedulerの挙動は100を設定した場合と同様となります。
この値を変更するためには、kube-schedulerの設定ファイル(これは/etc/kubernetes/config/kube-scheduler.yamlの可能性が高い)を編集し、スケジューラーを再起動します。
この変更をした後、
kubectl get pods -n kube-system | grep kube-scheduler
を実行して、kube-schedulerコンポーネントが正常であることを確認できます。
ノードへのスコア付けの閾値
スケジューリング性能を改善するため、kube-schedulerは割り当て可能なノードが十分に見つかるとノードの検索を停止できます。大規模クラスターでは、すべてのノードを考慮する単純なアプローチと比較して時間を節約できます。
クラスター内のすべてのノードに対する十分なノード数を整数パーセンテージで指定します。kube-schedulerは、これをノード数に変換します。スケジューリング中に、kube-schedulerが設定されたパーセンテージを超える十分な割り当て可能なノードを見つけた場合、kube-schedulerはこれ以上割り当て可能なノードを探すのを止め、スコアリングフェーズ に進みます。
スケジューラーはどのようにノードを探索するか で処理を詳しく説明しています。
デフォルトの閾値
閾値を指定しない場合、Kubernetesは100ノードのクラスターでは50%、5000ノードのクラスターでは10%になる線形方程式を使用して数値を計算します。自動計算の下限は5%です。
つまり、明示的にpercentageOfNodesToScoreを5未満の値を設定しない限り、クラスターの規模に関係なく、kube-schedulerは常に少なくともクラスターの5%のノードに対してスコア付けをします。
スケジューラーにクラスター内のすべてのノードに対してスコア付けをさせる場合は、percentageOfNodesToScoreの値に100を設定します。
例
percentageOfNodesToScoreの値を50%に設定する例は下記のとおりです。
apiVersion : kubescheduler.config.k8s.io/v1alpha1
kind : KubeSchedulerConfiguration
algorithmSource :
provider : DefaultProvider
...
percentageOfNodesToScore : 50
percentageOfNodesToScoreのチューニング
percentageOfNodesToScoreは1から100の間の範囲である必要があり、デフォルト値はクラスターのサイズに基づいて計算されます。また、クラスターのサイズの最小値は100ノードとハードコードされています。
備考: 割り当て可能なノードが100以下のクラスターでは、スケジューラの検索を早期に停止するのに十分な割り当て可能なノードがないため、スケジューラはすべてのノードをチェックします。
小規模クラスターでは、percentageOfNodesToScoreに低い値を設定したとしても、同様の理由で変更による影響は全くないか、ほとんどありません。
クラスターのノード数が数百以下の場合は、この設定オプションをデフォルト値のままにします。変更してもスケジューラの性能を大幅に改善する可能性はほとんどありません。
この値を設定する際に考慮するべき重要な注意事項として、割り当て可能ノードのチェック対象のノードが少ないと、一部のノードはPodの割り当てのためにスコアリングされなくなります。結果として、高いスコアをつけられる可能性のあるノードがスコアリングフェーズに渡されることがありません。これにより、Podの配置が理想的なものでなくなります。
kube-schedulerが頻繁に不適切なPodの配置を行わないよう、percentageOfNodesToScoreをかなり低い値を設定することは避けるべきです。スケジューラのスループットがアプリケーションにとって致命的で、ノードのスコアリングが重要でない場合を除いて、10%未満に設定することは避けてください。言いかえると、割り当て可能な限り、Podは任意のノード上で稼働させるのが好ましいです。
スケジューラーはどのようにノードを探索するか
このセクションでは、この機能の内部の詳細を理解したい人向けになります。
クラスター内の全てのノードに対して平等にPodの割り当ての可能性を持たせるため、スケジューラーはラウンドロビン方式でノードを探索します。複数のノードの配列になっているイメージです。スケジューラーはその配列の先頭から探索を開始し、percentageOfNodesToScoreによって指定された数のノードを検出するまで、割り当て可能かどうかをチェックしていきます。次のPodでは、スケジューラーは前のPodの割り当て処理でチェックしたところから探索を再開します。
ノードが複数のゾーンに存在するとき、スケジューラーは様々なゾーンのノードを探索して、異なるゾーンのノードが割り当て可能かどうかのチェック対象になるようにします。例えば2つのゾーンに6つのノードがある場合を考えます。
Zone 1: Node 1, Node 2, Node 3, Node 4
Zone 2: Node 5, Node 6
スケジューラーは、下記の順番でノードの割り当て可能性を評価します。
Node 1, Node 5, Node 2, Node 6, Node 3, Node 4
全てのノードのチェックを終えたら、1番目のノードに戻ってチェックをします。
10.7 - 拡張リソースのリソースビンパッキング
FEATURE STATE: Kubernetes v1.16 [alpha]
kube-schedulerでは、優先度関数RequestedToCapacityRatioResourceAllocationを使用した、
拡張リソースを含むリソースのビンパッキングを有効化できます。優先度関数はそれぞれのニーズに応じて、kube-schedulerを微調整するために使用できます。
RequestedToCapacityRatioResourceAllocationを使用したビンパッキングの有効化Kubernetesでは、キャパシティー比率への要求に基づいたNodeのスコアリングをするために、各リソースの重みと共にリソースを指定することができます。これにより、ユーザーは適切なパラメーターを使用することで拡張リソースをビンパックすることができ、大規模クラスターにおける希少なリソースを有効活用できるようになります。優先度関数RequestedToCapacityRatioResourceAllocationの動作はRequestedToCapacityRatioArgsと呼ばれる設定オプションによって変わります。この引数はshapeとresourcesパラメーターによって構成されます。shapeパラメーターはutilizationとscoreの値に基づいて、最も要求が多い場合か最も要求が少ない場合の関数をチューニングできます。resourcesパラメーターは、スコアリングの際に考慮されるリソース名のnameと、各リソースの重みを指定するweightで構成されます。
以下は、拡張リソースintel.com/fooとintel.com/barのビンパッキングにrequestedToCapacityRatioArgumentsを設定する例になります。
apiVersion : kubescheduler.config.k8s.io/v1beta1
kind : KubeSchedulerConfiguration
profiles :
# ...
pluginConfig :
- name : RequestedToCapacityRatio
args :
shape :
- utilization : 0
score : 10
- utilization : 100
score : 0
resources :
- name : intel.com/foo
weight : 3
- name : intel.com/bar
weight : 5
スケジューラーには、kube-schedulerフラグ--config=/path/to/config/fileを使用してKubeSchedulerConfigurationのファイルを指定することで渡すことができます。
この機能はデフォルトで無効化されています
優先度関数のチューニング
shapeはRequestedToCapacityRatioPriority関数の動作を指定するために使用されます。
shape :
- utilization : 0
score : 0
- utilization : 100
score : 10
上記の引数は、utilizationが0%の場合は0、utilizationが100%の場合は10というscoreをNodeに与え、ビンパッキングの動作を有効にしています。最小要求を有効にするには、次のようにスコアを反転させる必要があります。
shape :
- utilization : 0
score : 10
- utilization : 100
score : 0
resourcesはオプションパラメーターで、デフォルトでは以下の通りです。
resources :
- name : cpu
weight : 1
- name : memory
weight : 1
以下のように拡張リソースの追加に利用できます。
resources :
- name : intel.com/foo
weight : 5
- name : cpu
weight : 3
- name : memory
weight : 1
weightはオプションパラメーターで、指定されてない場合1が設定されます。また、マイナスの値は設定できません。
キャパシティ割り当てのためのNodeスコアリング
このセクションは、本機能の内部詳細について理解したい方を対象としています。以下は、与えられた値に対してNodeのスコアがどのように計算されるかの例です。
要求されたリソース:
intel.com/foo : 2
memory: 256MB
cpu: 2
リソースの重み:
intel.com/foo : 5
memory: 1
cpu: 3
shapeの値 {{0, 0}, {100, 10}}
Node1のスペック:
Available:
intel.com/foo: 4
memory: 1 GB
cpu: 8
Used:
intel.com/foo: 1
memory: 256MB
cpu: 1
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+1),4)
= (100 - ((4-3)*100/4)
= (100 - 25)
= 75 # requested + used = 75% * available
= rawScoringFunction(75)
= 7 # floor(75/10)
memory = resourceScoringFunction((256+256),1024)
= (100 -((1024-512)*100/1024))
= 50 # requested + used = 50% * available
= rawScoringFunction(50)
= 5 # floor(50/10)
cpu = resourceScoringFunction((2+1),8)
= (100 -((8-3)*100/8))
= 37.5 # requested + used = 37.5% * available
= rawScoringFunction(37.5)
= 3 # floor(37.5/10)
NodeScore = ((7 * 5) + (5 * 1) + (3 * 3)) / (5 + 1 + 3)
= 5
Node2のスペック:
Available:
intel.com/foo: 8
memory: 1GB
cpu: 8
Used:
intel.com/foo: 2
memory: 512MB
cpu: 6
Nodeのスコア:
intel.com/foo = resourceScoringFunction((2+2),8)
= (100 - ((8-4)*100/8)
= (100 - 50)
= 50
= rawScoringFunction(50)
= 5
memory = resourceScoringFunction((256+512),1024)
= (100 -((1024-768)*100/1024))
= 75
= rawScoringFunction(75)
= 7
cpu = resourceScoringFunction((2+6),8)
= (100 -((8-8)*100/8))
= 100
= rawScoringFunction(100)
= 10
NodeScore = ((5 * 5) + (7 * 1) + (10 * 3)) / (5 + 1 + 3)
= 7
次の項目
10.8 - Podの優先度とプリエンプション
FEATURE STATE: Kubernetes v1.14 [stable]
Pod は priority (優先度)を持つことができます。
優先度は他のPodに対する相対的なPodの重要度を示します。
もしPodをスケジューリングできないときには、スケジューラーはそのPodをスケジューリングできるようにするため、優先度の低いPodをプリエンプトする(追い出す)ことを試みます。
警告: クラスターの全てのユーザーが信用されていない場合、悪意のあるユーザーが可能な範囲で最も高い優先度のPodを作成することが可能です。これは他のPodが追い出されたりスケジューリングできない状態を招きます。
管理者はResourceQuotaを使用して、ユーザーがPodを高い優先度で作成することを防ぐことができます。
詳細はデフォルトで優先度クラスの消費を制限する
を参照してください。
優先度とプリエンプションを使う方法
優先度とプリエンプションを使うには、
1つまたは複数のPriorityClass を追加します
追加したPriorityClassをpriorityClassNamepriorityClassNameをDeploymentのようなコレクションオブジェクトのPodテンプレートに追加します。
これらの手順のより詳しい情報については、この先を読み進めてください。
PriorityClass
PriorityClassはnamespaceによらないオブジェクトで、優先度クラスの名称から優先度を表す整数値への対応を定義します。
PriorityClassオブジェクトのメタデータのnameフィールドにて名称を指定します。
値はvalueフィールドで指定し、必須です。
値が大きいほど、高い優先度を示します。
PriorityClassオブジェクトの名称はDNSサブドメイン名 として適切であり、かつsystem-から始まってはいけません。
PriorityClassオブジェクトは10億以下の任意の32ビットの整数値を持つことができます。これは、PriorityClassオブジェクトの値の範囲が-2147483648から1000000000までであることを意味します。
それよりも大きな値は通常はプリエンプトや追い出すべきではない重要なシステム用のPodのために予約されています。
クラスターの管理者は割り当てたい優先度に対して、PriorityClassオブジェクトを1つずつ作成すべきです。
PriorityClassは任意でフィールドglobalDefaultとdescriptionを設定可能です。
globalDefaultフィールドはpriorityClassNameが指定されないPodはこのPriorityClassを使うべきであることを示します。globalDefaultがtrueに設定されたPriorityClassはシステムで一つのみ存在可能です。globalDefaultが設定されたPriorityClassが存在しない場合は、priorityClassNameが設定されていないPodの優先度は0に設定されます。
descriptionフィールドは任意の文字列です。クラスターの利用者に対して、PriorityClassをどのような時に使うべきか示すことを意図しています。
PodPriorityと既存のクラスターに関する注意
もし既存のクラスターをこの機能がない状態でアップグレードすると、既存のPodの優先度は実質的に0になります。
globalDefaultがtrueに設定されたPriorityClassを追加しても、既存のPodの優先度は変わりません。PriorityClassのそのような値は、PriorityClassが追加された以後に作成されたPodのみに適用されます。
PriorityClassを削除した場合、削除されたPriorityClassの名前を使用する既存のPodは変更されませんが、削除されたPriorityClassの名前を使うPodをそれ以上作成することはできなくなります。
PriorityClassの例
apiVersion : scheduling.k8s.io/v1
kind : PriorityClass
metadata :
name : high-priority
value : 1000000
globalDefault : false
description : "この優先度クラスはXYZサービスのPodに対してのみ使用すべきです。"
非プリエンプトのPriorityClass
FEATURE STATE: Kubernetes v1.24 [stable]
preemptionPolicy: Neverと設定されたPodは、スケジューリングのキューにおいて他の優先度の低いPodよりも優先されますが、他のPodをプリエンプトすることはありません。
スケジューリングされるのを待つ非プリエンプトのPodは、リソースが十分に利用可能になるまでスケジューリングキューに残ります。
非プリエンプトのPodは、他のPodと同様に、スケジューラーのバックオフの対象になります。これは、スケジューラーがPodをスケジューリングしようと試みたものの失敗した場合、低い頻度で再試行するようにして、より優先度の低いPodが先にスケジューリングされることを許します。
非プリエンプトのPodは、他の優先度の高いPodにプリエンプトされる可能性はあります。
preemptionPolicyはデフォルトではPreemptLowerPriorityに設定されており、これが設定されているPodは優先度の低いPodをプリエンプトすることを許容します。これは既存のデフォルトの挙動です。
preemptionPolicyをNeverに設定すると、これが設定されたPodはプリエンプトを行わないようになります。
ユースケースの例として、データサイエンスの処理を挙げます。
ユーザーは他の処理よりも優先度を高くしたいジョブを追加できますが、そのとき既存の実行中のPodの処理結果をプリエンプトによって破棄させたくはありません。
preemptionPolicy: Neverが設定された優先度の高いジョブは、他の既にキューイングされたPodよりも先に、クラスターのリソースが「自然に」開放されたときにスケジューリングされます。
非プリエンプトのPriorityClassの例
apiVersion : scheduling.k8s.io/v1
kind : PriorityClass
metadata :
name : high-priority-nonpreempting
value : 1000000
preemptionPolicy : Never
globalDefault : false
description : "この優先度クラスは他のPodをプリエンプトさせません。"
Podの優先度
一つ以上のPriorityClassがあれば、仕様にPriorityClassを指定したPodを作成することができるようになります。優先度のアドミッションコントローラーはpriorityClassNameフィールドを使用し、優先度の整数値を設定します。PriorityClassが見つからない場合、そのPodの作成は拒否されます。
下記のYAMLは上記の例で作成したPriorityClassを使用するPodの設定の例を示します。優先度のアドミッションコントローラーは仕様を確認し、このPodの優先度は1000000であると設定します。
apiVersion : v1
kind : Pod
metadata :
name : nginx
labels :
env : test
spec :
containers :
- name : nginx
image : nginx
imagePullPolicy : IfNotPresent
priorityClassName : high-priority
スケジューリング順序におけるPodの優先度の効果
Podの優先度が有効な場合、スケジューラーは待機状態のPodをそれらの優先度順に並べ、スケジューリングキューにおいてより優先度の低いPodよりも前に来るようにします。その結果、その条件を満たしたときには優先度の高いPodは優先度の低いPodより早くスケジューリングされます。優先度の高いPodがスケジューリングできない場合は、スケジューラーは他の優先度の低いPodのスケジューリングも試みます。
プリエンプション
Podが作成されると、スケジューリング待ちのキューに入り待機状態になります。スケジューラーはキューからPodを取り出し、ノードへのスケジューリングを試みます。Podに指定された条件を全て満たすノードが見つからない場合は、待機状態のPodのためにプリエンプションロジックが発動します。待機状態のPodをPと呼ぶことにしましょう。プリエンプションロジックはPよりも優先度の低いPodを一つ以上追い出せばPをスケジューリングできるようになるノードを探します。そのようなノードがあれば、優先度の低いPodはノードから追い出されます。Podが追い出された後に、Pはノードへスケジューリング可能になります。
ユーザーへ開示される情報
Pod PがノードNのPodをプリエンプトした場合、ノードNの名称がPのステータスのnominatedNodeNameフィールドに設定されます。このフィールドはスケジューラーがPod Pのために予約しているリソースの追跡を助け、ユーザーにクラスターにおけるプリエンプトに関する情報を与えます。
Pod Pは必ずしも「指名したノード」へスケジューリングされないことに注意してください。スケジューラーは、他のノードに対して処理を繰り返す前に、常に「指定したノード」に対して試行します。Podがプリエンプトされると、そのPodは終了までの猶予期間を得ます。スケジューラーがPodの終了を待つ間に他のノードが利用可能になると、スケジューラーは他のノードをPod Pのスケジューリング先にすることがあります。この結果、PodのnominatedNodeNameとnodeNameは必ずしも一致しません。また、スケジューラーがノードNのPodをプリエンプトさせた後に、Pod Pよりも優先度の高いPodが来た場合、スケジューラーはノードNをその新しい優先度の高いPodへ与えることもあります。このような場合は、スケジューラーはPod PのnominatedNodeNameを消去します。これによって、スケジューラーはPod Pが他のノードのPodをプリエンプトさせられるようにします。
プリエンプトの制限
プリエンプトされるPodの正常終了
Podがプリエンプトされると、猶予期間 が与えられます。
Podは作業を完了し、終了するために十分な時間が与えられます。仮にそうでない場合、強制終了されます。この猶予期間によって、スケジューラーがPodをプリエンプトした時刻と、待機状態のPod Pがノード Nにスケジュール可能になるまでの時刻の間に間が開きます。この間、スケジューラーは他の待機状態のPodをスケジュールしようと試みます。プリエンプトされたPodが終了したら、スケジューラーは待ち行列にあるPodをスケジューリングしようと試みます。そのため、Podがプリエンプトされる時刻と、Pがスケジュールされた時刻には間が開くことが一般的です。この間を最小にするには、優先度の低いPodの猶予期間を0または小さい値にする方法があります。
PodDisruptionBudgetは対応するが、保証されない
PodDisruptionBudget (PDB)は、アプリケーションのオーナーが冗長化されたアプリケーションのPodが意図的に中断される数の上限を設定できるようにするものです。KubernetesはPodをプリエンプトする際にPDBに対応しますが、PDBはベストエフォートで考慮します。スケジューラーはプリエンプトさせたとしてもPDBに違反しないPodを探します。そのようなPodが見つからない場合でもプリエンプションは実行され、PDBに反しますが優先度の低いPodが追い出されます。
優先度の低いPodにおけるPod間のアフィニティ
次の条件が真の場合のみ、ノードはプリエンプションの候補に入ります。
「待機状態のPodよりも優先度の低いPodをノードから全て追い出したら、待機状態のPodをノードへスケジュールできるか」
備考: プリエンプションは必ずしも優先度の低いPodを全て追い出しません。
優先度の低いPodを全て追い出さなくても待機状態のPodがスケジューリングできる場合、一部のPodのみ追い出されます。
このような場合であったとしても、上記の条件は真である必要があります。偽であれば、そのノードはプリエンプションの対象とはされません。
待機状態のPodが、優先度の低いPodとの間でPod間のアフィニティ を持つ場合、Pod間のアフィニティはそれらの優先度の低いPodがなければ満たされません。この場合、スケジューラーはノードのどのPodもプリエンプトしようとはせず、代わりに他のノードを探します。スケジューラーは適切なノードを探せる場合と探せない場合があります。この場合、待機状態のPodがスケジューリングされる保証はありません。
この問題に対して推奨される解決策は、優先度が同一または高いPodに対してのみPod間のアフィニティを作成することです。
複数ノードに対するプリエンプション
Pod PがノードNにスケジューリングできるよう、ノードNがプリエンプションの対象となったとします。
他のノードのPodがプリエンプトされた場合のみPが実行可能になることもあります。下記に例を示します。
Pod PをノードNに配置することを検討します。
Pod QはノードNと同じゾーンにある別のノードで実行中です。
Pod Pはゾーンに対するQへのアンチアフィニティを持ちます (topologyKey: topology.kubernetes.io/zone)。
Pod Pと、ゾーン内の他のPodに対しては他のアンチアフィニティはない状態です。
Pod PをノードNへスケジューリングするには、Pod Qをプリエンプトすることが考えられますが、スケジューラーは複数ノードにわたるプリエンプションは行いません。そのため、Pod PはノードNへはスケジューリングできないとみなされます。
Pod Qがそのノードから追い出されると、Podアンチアフィニティに違反しなくなるので、Pod PはノードNへスケジューリング可能になります。
複数ノードに対するプリエンプションに関しては、十分な需要があり、合理的な性能を持つアルゴリズムを見つけられた場合に、将来的に機能追加を検討する可能性があります。
トラブルシューティング
Podの優先度とプリエンプションは望まない副作用をもたらす可能性があります。
いくつかの起こりうる問題と、その対策について示します。
Podが不必要にプリエンプトされる
プリエンプションは、リソースが不足している場合に優先度の高い待機状態のPodのためにクラスターの既存のPodを追い出します。
誤って高い優先度をPodに割り当てると、意図しない高い優先度のPodはクラスター内でプリエンプションを引き起こす可能性があります。Podの優先度はPodの仕様のpriorityClassNameフィールドにて指定されます。優先度を示す整数値へと変換された後、podSpecのpriorityへ設定されます。
この問題に対処するには、PodのpriorityClassNameをより低い優先度に変更するか、このフィールドを未設定にすることができます。priorityClassNameが未設定の場合、デフォルトでは優先度は0とされます。
Podがプリエンプトされたとき、プリエンプトされたPodのイベントが記録されます。
プリエンプションはPodに必要なリソースがクラスターにない場合のみ起こるべきです。
このような場合、プリエンプションはプリエンプトされるPodよりも待機状態のPodの優先度が高い場合のみ発生します。
プリエンプションは待機状態のPodがない場合や待機状態のPodがプリエンプト対象のPod以下の優先度を持つ場合には決して発生しません。そのような状況でプリエンプションが発生した場合、問題を報告してください。
Podはプリエンプトされたが、プリエンプトさせたPodがスケジューリングされない
Podがプリエンプトされると、それらのPodが要求した猶予期間が与えられます。そのデフォルトは30秒です。
Podがその期間内に終了しない場合、強制終了されます。プリエンプトされたPodがなくなれば、プリエンプトさせたPodはスケジューリング可能です。
プリエンプトさせたPodがプリエンプトされたPodの終了を待っている間に、より優先度の高いPodが同じノードに対して作成されることもあります。この場合、スケジューラーはプリエンプトさせたPodの代わりに優先度の高いPodをスケジューリングします。
これは予期された挙動です。優先度の高いPodは優先度の低いPodに取って代わります。
優先度の高いPodが優先度の低いPodより先にプリエンプトされる
スケジューラーは待機状態のPodが実行可能なノードを探します。ノードが見つからない場合、スケジューラーは任意のノードから優先度の低いPodを追い出し、待機状態のPodのためのリソースを確保しようとします。
仮に優先度の低いPodが動いているノードが待機状態のPodを動かすために適切ではない場合、スケジューラーは他のノードで動いているPodと比べると、優先度の高いPodが動いているノードをプリエンプションの対象に選ぶことがあります。この場合もプリエンプトされるPodはプリエンプトを起こしたPodよりも優先度が低い必要があります。
複数のノードがプリエンプションの対象にできる場合、スケジューラーは優先度が最も低いPodのあるノードを選ぼうとします。しかし、そのようなPodがPodDisruptionBudgetを持っており、プリエンプトするとPDBに反する場合はスケジューラーは優先度の高いPodのあるノードを選ぶこともあります。
複数のノードがプリエンプションの対象として利用可能で、上記の状況に当てはまらない場合、スケジューラーは優先度の最も低いノードを選択します。
Podの優先度とQoSの相互作用
Podの優先度とQoSクラス は直交する機能で、わずかに相互作用がありますが、デフォルトではQoSクラスによる優先度の設定の制約はありません。スケジューラーのプリエンプションのロジックはプリエンプションの対象を決めるときにQoSクラスは考慮しません。
プリエンプションはPodの優先度を考慮し、優先度が最も低いものを候補とします。より優先度の高いPodは優先度の低いPodを追い出すだけではプリエンプトを起こしたPodのスケジューリングに不十分な場合と、PodDisruptionBudgetにより優先度の低いPodが保護されている場合のみ対象になります。
kubeletはnode-pressureによる退避 を行うPodの順番を決めるために、優先度を利用します。QoSクラスを使用して、最も退避される可能性の高いPodの順番を推定することができます。
kubeletは追い出すPodの順位付けを次の順で行います。
枯渇したリソースを要求以上に使用しているか
Podの優先度
要求に対するリソースの使用量
詳細はkubeletによるPodの退避 を参照してください。
kubeletによるリソース不足時のPodの追い出しでは、リソースの消費が要求を超えないPodは追い出されません。優先度の低いPodのリソースの利用量がその要求を超えていなければ、追い出されることはありません。より優先度が高く、要求を超えてリソースを使用しているPodが追い出されます。
次の項目
10.9 - APIを起点とした退避
APIを起点とした退避は、Eviction API を使用して退避オブジェクトを作成し、Podの正常終了を起動させるプロセスです。
Eviction APIを直接呼び出すか、kubectl drainコマンドのようにAPIサーバー のクライアントを使って退避を要求することが可能です。これにより、Evictionオブジェクトを作成し、APIサーバーにPodを終了させます。
APIを起点とした退避はPodDisruptionBudgetsterminationGracePeriodSeconds
APIを使用してPodのEvictionオブジェクトを作成することは、Podに対してポリシー制御されたDELETE操作
Eviction APIの実行
Kubernetes APIへアクセスしてEvictionオブジェクトを作るためにKubernetesのプログラミング言語のクライアント を使用できます。
そのためには、次の例のようなデータをPOSTすることで操作を試みることができます。
備考: policy/v1においてEvictionはv1.22以上で利用可能です。それ以前のリリースでは、policy/v1beta1を使用してください。
{
"apiVersion" : "policy/v1" ,
"kind" : "Eviction" ,
"metadata" : {
"name" : "quux" ,
"namespace" : "default"
}
}
備考: v1.22で非推奨となり、policy/v1が採用されました。
{
"apiVersion" : "policy/v1beta1" ,
"kind" : "Eviction" ,
"metadata" : {
"name" : "quux" ,
"namespace" : "default"
}
}
また、以下の例のようにcurlやwgetを使ってAPIにアクセスすることで、操作を試みることもできます。
curl -v -H 'Content-type: application/json' https://your-cluster-api-endpoint.example/api/v1/namespaces/default/pods/quux/eviction -d @eviction.json
APIを起点とした退避の仕組み
APIを使用して退去を要求した場合、APIサーバーはアドミッションチェックを行い、以下のいずれかを返します。
200 OK:この場合、退去が許可されるとEvictionサブリソースが作成され、PodのURLにDELETEリクエストを送るのと同じように、Podが削除されます。429 Too Many Requests:PodDisruptionBudget の設定により、現在退去が許可されていないことを示します。しばらく時間を空けてみてください。また、APIのレート制限のため、このようなレスポンスが表示されることもあります。500 Internal Server Error:複数のPodDisruptionBudgetが同じPodを参照している場合など、設定に誤りがあり退去が許可されないことを示します。
退去させたいPodがPodDisruptionBudgetを持つワークロードの一部でない場合、APIサーバーは常に200 OKを返して退去を許可します。
APIサーバーが退去を許可した場合、以下の流れでPodが削除されます。
APIサーバーのPodリソースの削除タイムスタンプが更新され、APIサーバーはPodリソースが終了したと見なします。またPodリソースは、設定された猶予期間が設けられます。
ローカルのPodが動作しているNodeのkubelet は、Podリソースが終了するようにマークされていることに気付き、Podの適切なシャットダウンを開始します。
kubeletがPodをシャットダウンしている間、コントロールプレーンはEndpoint オブジェクトからPodを削除します。その結果、コントローラーはPodを有効なオブジェクトと見なさないようになります。
Podの猶予期間が終了すると、kubeletはローカルPodを強制的に終了します。
kubeletはAPIサーバーにPodリソースを削除するように指示します。
APIサーバーはPodリソースを削除します。
トラブルシューティング
場合によっては、アプリケーションが壊れた状態になり、対処しない限りEviction APIが429または500レスポンスを返すだけとなることがあります。例えば、ReplicaSetがアプリケーション用のPodを作成しても、新しいPodがReady状態にならない場合などです。また、最後に退去したPodの終了猶予期間が長い場合にも、この事象が見られます。
退去が進まない場合は、以下の解決策を試してみてください。
問題を引き起こしている自動化された操作を中止または一時停止し、操作を再開する前に、スタックしているアプリケーションを調査を行ってください。
しばらく待ってから、Eviction APIを使用する代わりに、クラスターのコントロールプレーンから直接Podを削除してください。
次の項目
11 - クラスターの管理
11.1 - クラスター管理の概要
このページはKubernetesクラスターの作成や管理者向けの内容です。Kubernetesのコアコンセプト についてある程度精通していることを前提とします。
クラスターのプランニング
Kubernetesクラスターの計画、セットアップ、設定の例を知るには設定 のガイドを参照してください。この記事で列挙されているソリューションはディストリビューション と呼ばれます。
ガイドを選択する前に、いくつかの考慮事項を挙げます。
ユーザーのコンピューター上でKubernetesを試したいでしょうか、それとも高可用性のあるマルチノードクラスターを構築したいでしょうか?あなたのニーズにあったディストリビューションを選択してください。
もしあなたが高可用性を求める場合 、 複数ゾーンにまたがるクラスター の設定について学んでください。Google Kubernetes Engine のようなホストされているKubernetesクラスター を使用するのか、それとも自分自身でクラスターをホストするのでしょうか ?使用するクラスターはオンプレミス なのか、それともクラウド(IaaS) でしょうか?Kubernetesはハイブリッドクラスターを直接サポートしていません。その代わりユーザーは複数のクラスターをセットアップできます。
Kubernetesを 「ベアメタル」なハードウェア 上で稼働させますか?それとも仮想マシン(VMs) 上で稼働させますか?
もしオンプレミスでKubernetesを構築する場合 、どのネットワークモデル が最適か検討してください。ただクラスターを稼働させたいだけ でしょうか、それともKubernetesプロジェクトのコードの開発 を行いたいでしょうか?もし後者の場合、開発が進行中のディストリビューションを選択してください。いくつかのディストリビューションはバイナリリリースのみ使用していますが、多くの選択肢があります。クラスターを稼働させるのに必要なコンポーネント についてよく理解してください。
注意: 全てのディストリビューションがアクティブにメンテナンスされている訳ではありません。最新バージョンのKubernetesでテストされたディストリビューションを選択してください。
クラスターの管理
クラスターをセキュアにする
kubeletをセキュアにする
オプションのクラスターサービス
11.2 - 証明書
クライアント証明書認証を使用する場合、easyrsaやopenssl、cfsslを用いて、手動で証明書を生成できます。
easyrsa
easyrsa を用いると、クラスターの証明書を手動で生成できます。
パッチを当てたバージョンのeasyrsa3をダウンロードして解凍し、初期化します。
curl -LO https://dl.k8s.io/easy-rsa/easy-rsa.tar.gz
tar xzf easy-rsa.tar.gz
cd easy-rsa-master/easyrsa3
./easyrsa init-pki
新しい認証局(CA)を生成します。--batchは自動モードを設定し、--req-cnはCAの新しいルート証明書の共通名(CN)を指定します。
./easyrsa --batch "--req-cn=${MASTER_IP}@`date +%s`" build-ca nopass
サーバー証明書と鍵を生成します。
引数--subject-alt-nameは、APIサーバーへのアクセスに使用できるIPおよびDNS名を設定します。
MASTER_CLUSTER_IPは通常、APIサーバーとコントローラーマネージャーコンポーネントの両方で引数--service-cluster-ip-rangeとして指定されるサービスCIDRの最初のIPです。
引数--daysは、証明書の有効期限が切れるまでの日数を設定するために使われます。
以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。
./easyrsa --subject-alt-name="IP:${MASTER_IP},"\
"IP:${MASTER_CLUSTER_IP},"\
"DNS:kubernetes,"\
"DNS:kubernetes.default,"\
"DNS:kubernetes.default.svc,"\
"DNS:kubernetes.default.svc.cluster,"\
"DNS:kubernetes.default.svc.cluster.local" \
--days=10000 \
build-server-full server nopass
pki/ca.crt、pki/issued/server.crt、pki/private/server.keyをディレクトリーにコピーします。
以下のパラメーターを、APIサーバーの開始パラメーターとして追加します。
--client-ca-file=/yourdirectory/ca.crt
--tls-cert-file=/yourdirectory/server.crt
--tls-private-key-file=/yourdirectory/server.key
openssl
openssl はクラスターの証明書を手動で生成できます。
2048ビットのca.keyを生成します。
openssl genrsa -out ca.key 2048
ca.keyに応じて、ca.crtを生成します。証明書の有効期間を設定するには、-daysを使用します。
openssl req -x509 -new -nodes -key ca.key -subj "/CN=${MASTER_IP}" -days 10000 -out ca.crt
2048ビットのserver.keyを生成します。
openssl genrsa -out server.key 2048
証明書署名要求(CSR)を生成するための設定ファイルを生成します。
ファイル(例: csr.conf)に保存する前に、かぎ括弧で囲まれた値(例: <MASTER_IP>)を必ず実際の値に置き換えてください。
MASTER_CLUSTER_IPの値は、前節で説明したAPIサーバーのサービスクラスターIPであることに注意してください。
以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。
[ req ]
default_bits = 2048
prompt = no
default_md = sha256
req_extensions = req_ext
distinguished_name = dn
[ dn ]
C = <country>
ST = <state>
L = <city>
O = <organization>
OU = <organization unit>
CN = <MASTER_IP>
[ req_ext ]
subjectAltName = @alt_names
[ alt_names ]
DNS.1 = kubernetes
DNS.2 = kubernetes.default
DNS.3 = kubernetes.default.svc
DNS.4 = kubernetes.default.svc.cluster
DNS.5 = kubernetes.default.svc.cluster.local
IP.1 = <MASTER_IP>
IP.2 = <MASTER_CLUSTER_IP>
[ v3_ext ]
authorityKeyIdentifier=keyid,issuer:always
basicConstraints=CA:FALSE
keyUsage=keyEncipherment,dataEncipherment
extendedKeyUsage=serverAuth,clientAuth
subjectAltName=@alt_names
設定ファイルに基づいて、証明書署名要求を生成します。
openssl req -new -key server.key -out server.csr -config csr.conf
ca.key、ca.crt、server.csrを使用してサーバー証明書を生成します。
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key \
-CAcreateserial -out server.crt -days 10000 \
-extensions v3_ext -extfile csr.conf -sha256
証明書を表示します。
openssl x509 -noout -text -in ./server.crt
最後にAPIサーバーの起動パラメーターに、同様のパラメーターを追加します。
cfssl
cfssl も証明書を生成するためのツールです。
以下のように、ダウンロードして解凍し、コマンドラインツールを用意します。
使用しているハードウェアアーキテクチャやcfsslのバージョンに応じて、サンプルコマンドの調整が必要な場合があります。
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl_1.5.0_linux_amd64 -o cfssl
chmod +x cfssl
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssljson_1.5.0_linux_amd64 -o cfssljson
chmod +x cfssljson
curl -L https://github.com/cloudflare/cfssl/releases/download/v1.5.0/cfssl-certinfo_1.5.0_linux_amd64 -o cfssl-certinfo
chmod +x cfssl-certinfo
アーティファクトを保持するディレクトリーを生成し、cfsslを初期化します。
mkdir cert
cd cert
../cfssl print-defaults config > config.json
../cfssl print-defaults csr > csr.json
CAファイルを生成するためのJSON設定ファイル(例: ca-config.json)を生成します。
{
"signing": {
"default": {
"expiry": "8760h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "8760h"
}
}
}
}
CA証明書署名要求(CSR)用のJSON設定ファイル(例: ca-csr.json)を生成します。
かぎ括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names":[{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
CA鍵(ca-key.pem)と証明書(ca.pem)を生成します。
../cfssl gencert -initca ca-csr.json | ../cfssljson -bare ca
APIサーバーの鍵と証明書を生成するためのJSON設定ファイル(例: server-csr.json)を生成します。
かぎ括弧で囲まれた値は、必ず使用したい実際の値に置き換えてください。
MASTER_CLUSTER_IPの値は、前節で説明したAPIサーバーのサービスクラスターIPです。
以下の例は、デフォルトのDNSドメイン名としてcluster.localを使用していることを前提とします。
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"<MASTER_IP>",
"<MASTER_CLUSTER_IP>",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "<country>",
"ST": "<state>",
"L": "<city>",
"O": "<organization>",
"OU": "<organization unit>"
}]
}
APIサーバーの鍵と証明書を生成します。デフォルトでは、それぞれserver-key.pemとserver.pemというファイルに保存されます。
../cfssl gencert -ca=ca.pem -ca-key=ca-key.pem \
--config=ca-config.json -profile=kubernetes \
server-csr.json | ../cfssljson -bare server
自己署名CA証明書の配布
クライアントノードは、自己署名CA証明書を有効だと認識しないことがあります。
プロダクション用でない場合や、会社のファイアウォールの背後で実行する場合は、自己署名CA証明書をすべてのクライアントに配布し、有効な証明書のローカルリストを更新できます。
各クライアントで、以下の操作を実行します。
sudo cp ca.crt /usr/local/share/ca-certificates/kubernetes.crt
sudo update-ca-certificates
Updating certificates in /etc/ssl/certs...
1 added, 0 removed; done.
Running hooks in /etc/ca-certificates/update.d....
done.
証明書API
certificates.k8s.ioAPIを用いることで、こちら のドキュメントにあるように、認証に使用するx509証明書をプロビジョニングすることができます。
11.3 - リソースの管理
アプリケーションをデプロイし、Serviceを介して外部に公開できました。さて、どうしますか?Kubernetesは、スケーリングや更新など、アプリケーションのデプロイを管理するための多くのツールを提供します。
我々が取り上げる機能についての詳細は設定ファイル とラベル について詳細に説明します。
リソースの設定を管理する
多くのアプリケーションではDeploymentやServiceなど複数のリソースの作成を要求します。複数のリソースの管理は、同一のファイルにひとまとめにしてグループ化すると簡単になります(YAMLファイル内で---で区切る)。
例えば:
apiVersion : v1
kind : Service
metadata :
name : my-nginx-svc
labels :
app : nginx
spec :
type : LoadBalancer
ports :
- port : 80
selector :
app : nginx
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : my-nginx
labels :
app : nginx
spec :
replicas : 3
selector :
matchLabels :
app : nginx
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
複数のリソースは単一のリソースと同様の方法で作成できます。
kubectl apply -f https://k8s.io/examples/application/nginx-app.yaml
service/my-nginx-svc created
deployment.apps/my-nginx created
リソースは、ファイル内に記述されている順番通りに作成されます。そのため、Serviceを最初に指定するのが理想です。スケジューラーがServiceに関連するPodを、Deploymentなどのコントローラーによって作成されるときに確実に拡散できるようにするためです。
kubectl applyもまた、複数の-fによる引数指定を許可しています。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-svc.yaml -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
個別のファイルに加えて、-fの引数としてディレクトリ名も指定できます:
kubectl apply -f https://k8s.io/examples/application/nginx/
kubectlは.yaml、.yml、.jsonといったサフィックスの付くファイルを読み込みます。
同じマイクロサービス、アプリケーションティアーのリソースは同一のファイルにまとめ、アプリケーションに関するファイルをグループ化するために、それらのファイルを同一のディレクトリに配備するのを推奨します。アプリケーションのティアーがDNSを通じて互いにバインドされると、アプリケーションスタックの全てのコンポーネントをひとまとめにして簡単にデプロイできます。
リソースの設定ソースとして、URLも指定できます。githubから取得した設定ファイルから直接手軽にデプロイができます:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/website/master/content/en/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx created
kubectlによる一括操作
kubectlが一括して実行できる操作はリソースの作成のみではありません。作成済みのリソースの削除などの他の操作を実行するために、設定ファイルからリソース名を取得することができます。
kubectl delete -f https://k8s.io/examples/application/nginx-app.yaml
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
2つのリソースだけを削除する場合には、コマンドラインでリソース/名前というシンタックスを使うことで簡単に指定できます。
kubectl delete deployments/my-nginx services/my-nginx-svc
さらに多くのリソースに対する操作では、リソースをラベルでフィルターするために-lや--selectorを使ってセレクター(ラベルクエリ)を指定するのが簡単です:
kubectl delete deployment,services -l app = nginx
deployment.apps "my-nginx" deleted
service "my-nginx-svc" deleted
kubectlは同様のシンタックスでリソース名を出力するので、$()やxargsを使ってパイプで操作するのが容易です:
kubectl get $( kubectl create -f docs/concepts/cluster-administration/nginx/ -o name | grep service)
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT( S) AGE
my-nginx-svc LoadBalancer 10.0.0.208 <pending> 80/TCP 0s
上記のコマンドで、最初にexamples/application/nginx/配下でリソースを作成し、-o nameという出力フォーマットにより、作成されたリソースの名前を表示します(各リソースをresource/nameという形式で表示)。そして"service"のみgrepし、kubectl getを使って表示させます。
あるディレクトリ内の複数のサブディレクトリをまたいでリソースを管理するような場合、--filename,-fフラグと合わせて--recursiveや-Rを指定することでサブディレクトリに対しても再帰的に操作が可能です。
例えば、開発環境用に必要な全てのマニフェスト をリソースタイプによって整理しているproject/k8s/developmentというディレクトリがあると仮定します。
project/k8s/development
├── configmap
│ └── my-configmap.yaml
├── deployment
│ └── my-deployment.yaml
└── pvc
└── my-pvc.yaml
デフォルトでは、project/k8s/developmentにおける一括操作は、どのサブディレクトリも処理せず、ディレクトリの第1階層で処理が止まります。下記のコマンドによってこのディレクトリ配下でリソースを作成しようとすると、エラーが発生します。
kubectl apply -f project/k8s/development
error: you must provide one or more resources by argument or filename ( .json|.yaml|.yml|stdin)
代わりに、下記のように--filename,-fフラグと合わせて--recursiveや-Rを指定してください:
kubectl apply -f project/k8s/development --recursive
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
--recursiveフラグはkubectl {create,get,delete,describe,rollout}などのような--filename,-fフラグを扱うどの操作でも有効です。
また、--recursiveフラグは複数の-fフラグの引数を指定しても有効です。
kubectl apply -f project/k8s/namespaces -f project/k8s/development --recursive
namespace/development created
namespace/staging created
configmap/my-config created
deployment.apps/my-deployment created
persistentvolumeclaim/my-pvc created
kubectlについてさらに知りたい場合は、コマンドラインツール(kubectl) を参照してください。
ラベルを有効に使う
これまで取り上げた例では、リソースに対して最大1つのラベルを適用してきました。リソースのセットを他のセットと区別するために、複数のラベルが必要な状況があります。
例えば、異なるアプリケーション間では、異なるappラベルを使用したり、ゲストブックの例 のようなマルチティアーのアプリケーションでは、各ティアーを区別する必要があります。frontendというティアーでは下記のラベルを持ちます。:
labels :
app : guestbook
tier : frontend
Redisマスターやスレーブでは異なるtierラベルを持ち、加えてroleラベルも持つことでしょう。:
labels :
app : guestbook
tier : backend
role : master
そして
labels :
app : guestbook
tier : backend
role : slave
ラベルを使用すると、ラベルで指定された任意の次元に沿ってリソースを分割できます。
kubectl apply -f examples/guestbook/all-in-one/guestbook-all-in-one.yaml
kubectl get pods -Lapp -Ltier -Lrole
NAME READY STATUS RESTARTS AGE APP TIER ROLE
guestbook-fe-4nlpb 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-ght6d 1/1 Running 0 1m guestbook frontend <none>
guestbook-fe-jpy62 1/1 Running 0 1m guestbook frontend <none>
guestbook-redis-master-5pg3b 1/1 Running 0 1m guestbook backend master
guestbook-redis-slave-2q2yf 1/1 Running 0 1m guestbook backend slave
guestbook-redis-slave-qgazl 1/1 Running 0 1m guestbook backend slave
my-nginx-divi2 1/1 Running 0 29m nginx <none> <none>
my-nginx-o0ef1 1/1 Running 0 29m nginx <none> <none>
kubectl get pods -lapp= guestbook,role= slave
NAME READY STATUS RESTARTS AGE
guestbook-redis-slave-2q2yf 1/1 Running 0 3m
guestbook-redis-slave-qgazl 1/1 Running 0 3m
Canary deployments カナリアデプロイ
複数のラベルが必要な他の状況として、異なるリリース間でのDeploymentや、同一コンポーネントの設定を区別することが挙げられます。よく知られたプラクティスとして、本番環境の実際のトラフィックを受け付けるようにするために、新しいリリースを完全にロールアウトする前に、新しいカナリア版 のアプリケーションを過去のリリースと合わせてデプロイする方法があります。
例えば、異なるリリースバージョンを分けるためにtrackラベルを使用できます。
主要な安定板のリリースではtrackラベルにstableという値をつけることがあるでしょう。:
name : frontend
replicas : 3
...
labels :
app : guestbook
tier : frontend
track : stable
...
image : gb-frontend:v3
そして2つの異なるPodのセットを上書きしないようにするため、trackラベルに異なる値を持つ(例: canary)ようなguestbookフロントエンドの新しいリリースを作成できます。
name : frontend-canary
replicas : 1
...
labels :
app : guestbook
tier : frontend
track : canary
...
image : gb-frontend:v4
frontend Serviceは、トラフィックを両方のアプリケーションにリダイレクトさせるために、両方のアプリケーションに共通したラベルのサブセットを選択して両方のレプリカを扱えるようにします。:
selector :
app : guestbook
tier : frontend
安定版とカナリア版リリースで本番環境の実際のトラフィックを転送する割合を決めるため、双方のレプリカ数を変更できます(このケースでは3対1)。
最新版のリリースをしても大丈夫な場合、安定版のトラックを新しいアプリケーションにして、カナリア版を削除します。
さらに具体的な例については、tutorial of deploying Ghost を参照してください。
ラベルの更新
新しいリソースを作成する前に、既存のPodと他のリソースのラベルの変更が必要な状況があります。これはkubectl labelで実行できます。
例えば、全てのnginx Podを frontendティアーとしてラベル付けするには、下記のコマンドを実行するのみです。
kubectl label pods -l app = nginx tier = fe
pod/my-nginx-2035384211-j5fhi labeled
pod/my-nginx-2035384211-u2c7e labeled
pod/my-nginx-2035384211-u3t6x labeled
これは最初に"app=nginx"というラベルのついたPodをフィルターし、そのPodに対して"tier=fe"というラベルを追加します。
ラベル付けしたPodを確認するには、下記のコマンドを実行してください。
kubectl get pods -l app = nginx -L tier
NAME READY STATUS RESTARTS AGE TIER
my-nginx-2035384211-j5fhi 1/1 Running 0 23m fe
my-nginx-2035384211-u2c7e 1/1 Running 0 23m fe
my-nginx-2035384211-u3t6x 1/1 Running 0 23m fe
このコマンドでは"app=nginx"というラベルのついた全てのPodを出力し、Podのtierという項目も表示します(-Lまたは--label-columnsで指定)。
さらなる情報は、ラベル やkubectl label を参照してください。
アノテーションの更新
リソースに対してアノテーションを割り当てたい状況があります。アノテーションは、ツール、ライブラリなどのAPIクライアントによって取得するための任意の非識別メタデータです。アノテーションの割り当てはkubectl annotateで可能です。例:
kubectl annotate pods my-nginx-v4-9gw19 description = 'my frontend running nginx'
kubectl get pods my-nginx-v4-9gw19 -o yaml
apiVersion: v1
kind: pod
metadata:
annotations:
description: my frontend running nginx
...
さらなる情報は、アノテーション や、kubectl annotate を参照してください。
アプリケーションのスケール
アプリケーションの負荷が増減するとき、kubectlを使って簡単にスケールできます。例えば、nginxのレプリカを3から1に減らす場合、下記を実行します:
kubectl scale deployment/my-nginx --replicas= 1
deployment.apps/my-nginx scaled
実行すると、Deploymentによって管理されるPod数が1となります。
kubectl get pods -l app = nginx
NAME READY STATUS RESTARTS AGE
my-nginx-2035384211-j5fhi 1/1 Running 0 30m
システムに対してnginxのレプリカ数を自動で選択させるには、下記のように1から3の範囲で指定します。:
kubectl autoscale deployment/my-nginx --min= 1 --max= 3
horizontalpodautoscaler.autoscaling/my-nginx autoscaled
実行すると、nginxのレプリカは必要に応じて自動でスケールアップ、スケールダウンします。
さらなる情報は、kubectl scale 、kubectl autoscale and horizontal pod autoscaler を参照してください。
リソースの直接的アップデート
場合によっては、作成したリソースに対して処理を中断させずに更新を行う必要があります。
kubectl apply
開発者が設定するリソースをコードとして管理しバージョニングも行えるように、設定ファイルのセットをソースによって管理する方法が推奨されています。
この場合、クラスターに対して設定の変更をプッシュするためにkubectl apply
このコマンドは、リソース設定の過去のバージョンと、今適用した変更を比較し、差分に現れないプロパティーに対して上書き変更することなくクラスターに適用させます。
kubectl apply -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml
deployment.apps/my-nginx configured
注意として、前回の変更適用時からの設定の変更内容を決めるため、kubectl applyはリソースに対してアノテーションを割り当てます。変更が実施されるとkubectl applyは、1つ前の設定内容と、今回変更しようとする入力内容と、現在のリソースの設定との3つの間で変更内容の差分をとります。
現在、リソースはこのアノテーションなしで作成されました。そのため、最初のkubectl paplyの実行においては、与えられた入力と、現在のリソースの設定の2つの間の差分が取られ、フォールバックします。この最初の実行の間、リソースが作成された時にプロパティーセットの削除を検知できません。この理由により、プロパティーの削除はされません。
kubectl applyの実行後の全ての呼び出しや、kubectl replaceやkubectl editなどの設定を変更する他のコマンドではアノテーションを更新します。kubectl applyした後の全ての呼び出しにおいて3-wayの差分取得によってプロパティの検知と削除を実施します。
kubectl edit
その他に、kubectl editによってリソースの更新もできます。:
kubectl edit deployment/my-nginx
このコマンドは、最初にリソースをgetし、テキストエディタでリソースを編集し、更新されたバージョンでリソースをapplyします。:
kubectl get deployment my-nginx -o yaml > /tmp/nginx.yaml
vi /tmp/nginx.yaml
# yamlファイルを編集し、ファイルを保存します。
kubectl apply -f /tmp/nginx.yaml
deployment.apps/my-nginx configured
rm /tmp/nginx.yaml
このコマンドによってより重大な変更を簡単に行えます。注意として、あなたのEDITORやKUBE_EDITORといった環境変数も指定できます。
さらなる情報は、kubectl edit を参照してください。
kubectl patch
APIオブジェクトの更新にはkubectl patchを使うことができます。このコマンドはJSON patch、JSON merge patch、戦略的merge patchをサポートしています。
kubectl patchを使ったAPIオブジェクトの更新 やkubectl patch を参照してください。
破壊的なアップデート
一度初期化された後、更新できないようなリソースフィールドの更新が必要な場合や、Deploymentによって作成され、壊れている状態のPodを修正するなど、再帰的な変更を即座に行いたい場合があります。このようなフィールドを変更するため、リソースの削除と再作成を行うreplace --forceを使用してください。このケースでは、シンプルに元の設定ファイルを修正するのみです。:
kubectl replace -f https://k8s.io/examples/application/nginx/nginx-deployment.yaml --force
deployment.apps/my-nginx deleted
deployment.apps/my-nginx replaced
サービス停止なしでアプリケーションを更新する
ある時点で、前述したカナリアデプロイのシナリオにおいて、新しいイメージやイメージタグを指定することによって、デプロイされたアプリケーションを更新が必要な場合があります。kubectlではいくつかの更新操作をサポートしており、それぞれの操作が異なるシナリオに対して適用可能です。
ここでは、Deploymentを使ってアプリケーションの作成と更新についてガイドします。
まずnginxのバージョン1.14.2を稼働させていると仮定します。:
kubectl create deployment my-nginx --image= nginx:1.14.2
deployment.apps/my-nginx created
レプリカ数を3にします(新旧のリビジョンは混在します)。:
kubectl scale deployment my-nginx --current-replicas= 1 --replicas= 3
deployment.apps/my-nginx scaled
バージョン1.16.1に更新するには、上述したkubectlコマンドを使って.spec.template.spec.containers[0].imageの値をnginx:1.14.2からnginx:1.16.1に変更するだけでできます。
kubectl edit deployment/my-nginx
できました!Deploymentはデプロイされたnginxのアプリケーションを宣言的にプログレッシブに更新します。更新途中では、決まった数の古いレプリカのみダウンし、一定数の新しいレプリカが希望するPod数以上作成されても良いことを保証します。詳細について学ぶにはDeployment page を参照してください。
次の項目
11.4 - クラスターのネットワーク
ネットワークはKubernetesにおける中心的な部分ですが、どのように動作するかを正確に理解することは難解な場合もあります。
Kubernetesには、4つの異なる対応すべきネットワークの問題があります:
高度に結合されたコンテナ間の通信: これは、Pod およびlocalhost通信によって解決されます。
Pod間の通信: 本ドキュメントの主な焦点です。
Podからサービスへの通信: これはService でカバーされています。
外部からサービスへの通信: これはService でカバーされています。
Kubernetesは、言ってしまえばアプリケーション間でマシンを共有するためのものです。通常、マシンを共有するには、2つのアプリケーションが同じポートを使用しないようにする必要があります。
複数の開発者間でのポートの調整は、大規模に行うことが非常に難しく、ユーザーが制御できないクラスターレベルの問題に直面することになります。
動的ポート割り当てはシステムに多くの複雑さをもたらします。すべてのアプリケーションはポートをフラグとして受け取らなければならない、APIサーバーは設定ブロックに動的ポート番号を挿入する方法を知っていなければならない、各サービスは互いを見つける方法を知らなければならない、などです。Kubernetesはこれに対処するのではなく、別のアプローチを取ります。
Kubernetesネットワークモデルについては、こちら を参照してください。
Kubernetesネットワークモデルの実装方法
ネットワークモデルは、各ノード上のコンテナランタイムによって実装されます。最も一般的なコンテナランタイムは、Container Network Interface (CNI)プラグインを使用して、ネットワークとセキュリティ機能を管理します。CNIプラグインは、さまざまなベンダーから多数提供されています。これらの中には、ネットワークインターフェースの追加と削除という基本的な機能のみを提供するものもあれば、他のコンテナオーケストレーションシステムとの統合、複数のCNIプラグインの実行、高度なIPAM機能など、より洗練されたソリューションを提供するものもあります。
Kubernetesがサポートするネットワークアドオンの非網羅的なリストについては、このページ を参照してください。
次の項目
ネットワークモデルの初期設計とその根拠、および将来の計画については、ネットワーク設計ドキュメント で詳細に説明されています。
11.5 - ロギングのアーキテクチャ
アプリケーションログは、アプリケーション内で何が起こっているかを理解するのに役立ちます。ログは、問題のデバッグとクラスターアクティビティの監視に特に役立ちます。最近のほとんどのアプリケーションには、何らかのロギングメカニズムがあります。同様に、コンテナエンジンはロギングをサポートするように設計されています。コンテナ化されたアプリケーションで、最も簡単で最も採用されているロギング方法は、標準出力と標準エラーストリームへの書き込みです。
ただし、コンテナエンジンまたはランタイムによって提供されるネイティブ機能は、たいていの場合、完全なロギングソリューションには十分ではありません。
たとえば、コンテナがクラッシュした場合やPodが削除された場合、またはノードが停止した場合に、アプリケーションのログにアクセスしたい場合があります。
クラスターでは、ノードやPod、またはコンテナに関係なく、ノードに個別のストレージとライフサイクルが必要です。この概念は、クラスターレベルロギング と呼ばれます。
クラスターレベルロギングのアーキテクチャでは、ログを保存、分析、およびクエリするための個別のバックエンドが必要です。Kubernetesは、ログデータ用のネイティブストレージソリューションを提供していません。代わりに、Kubernetesに統合される多くのロギングソリューションがあります。次のセクションでは、ノードでログを処理および保存する方法について説明します。
Kubernetesでの基本的なロギング
この例では、1秒に1回標準出力ストリームにテキストを書き込むコンテナを利用する、Pod specificationを使います。
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox
args : [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done' ]
このPodを実行するには、次のコマンドを使用します:
kubectl apply -f https://k8s.io/examples/debug/counter-pod.yaml
出力は次のようになります:
ログを取得するには、以下のようにkubectl logsコマンドを使用します:
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
コンテナの以前のインスタンスからログを取得するために、kubectl logs --previousを使用できます。Podに複数のコンテナがある場合は、次のように-cフラグでコマンドにコンテナ名を追加することで、アクセスするコンテナのログを指定します。
kubectl logs counter -c count
詳細については、kubectl logsドキュメント
ノードレベルでのロギング
コンテナエンジンは、生成された出力を処理して、コンテナ化されたアプリケーションのstdoutとstderrストリームにリダイレクトします。たとえば、Dockerコンテナエンジンは、これら2つのストリームをロギングドライバー にリダイレクトします。ロギングドライバーは、JSON形式でファイルに書き込むようにKubernetesで設定されています。
備考: Docker JSONロギングドライバーは、各行を個別のメッセージとして扱います。Dockerロギングドライバーを使用する場合、複数行メッセージを直接サポートすることはできません。ロギングエージェントレベルあるいはそれ以上のレベルで、複数行のメッセージを処理する必要があります。
デフォルトでは、コンテナが再起動すると、kubeletは1つの終了したコンテナをログとともに保持します。Podがノードから削除されると、対応する全てのコンテナが、ログとともに削除されます。
ノードレベルロギングでの重要な考慮事項は、ノードで使用可能な全てのストレージをログが消費しないように、ログローテーションを実装することです。Kubernetesはログのローテーションを担当しませんが、デプロイツールでそれに対処するソリューションを構築する必要があります。たとえば、kube-up.shスクリプトによってデプロイされたKubernetesクラスターには、1時間ごとに実行するように構成されたlogrotate
例として、configure-helper scriptkube-up.shが、どのようにGCPでCOSイメージのロギングを構築しているかについて、詳細な情報を見つけることができます。
CRIコンテナランタイム を使用する場合、kubeletはログのローテーションとログディレクトリ構造の管理を担当します。kubeletはこの情報をCRIコンテナランタイムに送信し、ランタイムはコンテナログを指定された場所に書き込みます。2つのkubeletパラメーター、container-log-max-sizeとcontainer-log-max-fileskubelet設定ファイル で使うことで、各ログファイルの最大サイズと各コンテナで許可されるファイルの最大数をそれぞれ設定できます。
基本的なロギングの例のように、kubectl logs
備考: 外部システムがローテーションを実行した場合、またはCRIコンテナランタイムが使用されている場合は、最新のログファイルの内容のみがkubectl logsで利用可能になります。例えば、10MBのファイルがある場合、logrotateによるローテーションが実行されると、2つのファイルが存在することになります: 1つはサイズが10MBのファイルで、もう1つは空のファイルです。この例では、kubectl logsは最新のログファイルの内容、つまり空のレスポンスを返します。
システムコンポーネントログ
システムコンポーネントには、コンテナ内で実行されるものとコンテナ内で実行されないものの2種類があります。例えば以下のとおりです。
Kubernetesスケジューラーとkube-proxyはコンテナ内で実行されます。
kubeletとコンテナランタイムはコンテナ内で実行されません。
systemdを搭載したマシンでは、kubeletとコンテナランタイムがjournaldに書き込みます。systemdが存在しない場合、kubeletとコンテナランタイムはvar/logディレクトリ内の.logファイルに書き込みます。コンテナ内のシステムコンポーネントは、デフォルトのロギングメカニズムを迂回して、常に/var/logディレクトリに書き込みます。それらはklogdevelopment docs on logging に記載されています。
コンテナログと同様に、/var/logディレクトリ内のシステムコンポーネントログはローテーションする必要があります。kube-up.shスクリプトによって生成されたKubernetesクラスターでは、これらのログは、logrotateツールによって毎日、またはサイズが100MBを超えた時にローテーションされるように設定されています。
クラスターレベルロギングのアーキテクチャ
Kubernetesはクラスターレベルロギングのネイティブソリューションを提供していませんが、検討可能な一般的なアプローチがいくつかあります。ここにいくつかのオプションを示します:
全てのノードで実行されるノードレベルのロギングエージェントを使用します。
アプリケーションのPodにログインするための専用のサイドカーコンテナを含めます。
アプリケーション内からバックエンドに直接ログを送信します。
ノードロギングエージェントの使用
各ノードに ノードレベルのロギングエージェント を含めることで、クラスターレベルロギングを実装できます。ロギングエージェントは、ログを公開したり、ログをバックエンドに送信したりする専用のツールです。通常、ロギングエージェントは、そのノード上の全てのアプリケーションコンテナからのログファイルを含むディレクトリにアクセスできるコンテナです。
ロギングエージェントは全てのノードで実行する必要があるため、エージェントをDaemonSetとして実行することをおすすめします。
ノードレベルのロギングは、ノードごとに1つのエージェントのみを作成し、ノードで実行されているアプリケーションに変更を加える必要はありません。
コンテナはstdoutとstderrに書き込みますが、合意された形式はありません。ノードレベルのエージェントはこれらのログを収集し、集約のために転送します。
ロギングエージェントでサイドカーコンテナを使用する
サイドカーコンテナは、次のいずれかの方法で使用できます:
サイドカーコンテナは、アプリケーションログを自身のstdoutにストリーミングします。
サイドカーコンテナは、アプリケーションコンテナからログを取得するように設定されたロギングエージェントを実行します。
ストリーミングサイドカーコンテナ
サイドカーコンテナに自身のstdoutやstderrストリームへの書き込みを行わせることで、各ノードですでに実行されているkubeletとロギングエージェントを利用できます。サイドカーコンテナは、ファイル、ソケット、またはjournaldからログを読み取ります。各サイドカーコンテナは、ログを自身のstdoutまたはstderrストリームに出力します。
このアプローチにより、stdoutまたはstderrへの書き込みのサポートが不足している場合も含め、アプリケーションのさまざまな部分からいくつかのログストリームを分離できます。ログのリダイレクトの背後にあるロジックは最小限であるため、大きなオーバーヘッドにはなりません。さらに、stdoutとstderrはkubeletによって処理されるため、kubectl logsのような組み込みツールを使用できます。
たとえば、Podは単一のコンテナを実行し、コンテナは2つの異なる形式を使用して2つの異なるログファイルに書き込みます。Podの構成ファイルは次のとおりです:
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
volumes :
- name : varlog
emptyDir : {}
両方のコンポーネントをコンテナのstdoutストリームにリダイレクトできたとしても、異なる形式のログエントリを同じログストリームに書き込むことはおすすめしません。代わりに、2つのサイドカーコンテナを作成できます。各サイドカーコンテナは、共有ボリュームから特定のログファイルを追跡し、ログを自身のstdoutストリームにリダイレクトできます。
2つのサイドカーコンテナを持つPodの構成ファイルは次のとおりです:
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-log-1
image : busybox
args : [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-log-2
image : busybox
args : [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts :
- name : varlog
mountPath : /var/log
volumes :
- name : varlog
emptyDir : {}
これで、このPodを実行するときに、次のコマンドを実行して、各ログストリームに個別にアクセスできます:
kubectl logs counter count-log-1
出力は次のようになります:
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
kubectl logs counter count-log-2
出力は次のようになります:
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
クラスターにインストールされているノードレベルのエージェントは、それ以上の設定を行わなくても、これらのログストリームを自動的に取得します。必要があれば、ソースコンテナに応じてログをパースするようにエージェントを構成できます。
CPUとメモリーの使用量が少ない(CPUの場合は数ミリコアのオーダー、メモリーの場合は数メガバイトのオーダー)にも関わらず、ログをファイルに書き込んでからstdoutにストリーミングすると、ディスクの使用量が2倍になる可能性があることに注意してください。単一のファイルに書き込むアプリケーションがある場合は、ストリーミングサイドカーコンテナアプローチを実装するのではなく、/dev/stdoutを宛先として設定することをおすすめします。
サイドカーコンテナを使用して、アプリケーション自体ではローテーションできないログファイルをローテーションすることもできます。このアプローチの例は、logrotateを定期的に実行する小さなコンテナです。しかし、stdoutとstderrを直接使い、ローテーションと保持のポリシーをkubeletに任せることをおすすめします。
ロギングエージェントを使用したサイドカーコンテナ
ノードレベルロギングのエージェントが、あなたの状況に必要なだけの柔軟性を備えていない場合は、アプリケーションで実行するように特別に構成した別のロギングエージェントを使用してサイドカーコンテナを作成できます。
備考: サイドカーコンテナでロギングエージェントを使用すると、大量のリソースが消費される可能性があります。さらに、これらのログはkubeletによって制御されていないため、kubectl logsを使用してこれらのログにアクセスすることができません。
ロギングエージェントを使用したサイドカーコンテナを実装するために使用できる、2つの構成ファイルを次に示します。最初のファイルには、fluentdを設定するためのConfigMap
apiVersion : v1
kind : ConfigMap
metadata :
name : fluentd-config
data :
fluentd.conf : |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
2番目のファイルは、fluentdを実行しているサイドカーコンテナを持つPodを示しています。Podは、fluentdが構成データを取得できるボリュームをマウントします。
apiVersion : v1
kind : Pod
metadata :
name : counter
spec :
containers :
- name : count
image : busybox:1.28
args :
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts :
- name : varlog
mountPath : /var/log
- name : count-agent
image : registry.k8s.io/fluentd-gcp:1.30
env :
- name : FLUENTD_ARGS
value : -c /etc/fluentd-config/fluentd.conf
volumeMounts :
- name : varlog
mountPath : /var/log
- name : config-volume
mountPath : /etc/fluentd-config
volumes :
- name : varlog
emptyDir : {}
- name : config-volume
configMap :
name : fluentd-config
サンプル構成では、fluentdを任意のロギングエージェントに置き換えて、アプリケーションコンテナ内の任意のソースから読み取ることができます。
アプリケーションから直接ログを公開する
すべてのアプリケーションから直接ログを公開または送信するクラスターロギングは、Kubernetesのスコープ外です。
11.6 - システムログ
システムコンポーネントのログは、クラスター内で起こったイベントを記録します。このログはデバッグのために非常に役立ちます。ログのverbosityを設定すると、ログをどの程度詳細に見るのかを変更できます。ログはコンポーネント内のエラーを表示する程度の荒い粒度にすることも、イベントのステップバイステップのトレース(HTTPのアクセスログ、Podの状態の変更、コントローラーの動作、スケジューラーの決定など)を表示するような細かい粒度に設定することもできます。
klog
klogは、Kubernetesのログライブラリです。klog は、Kubernetesのシステムコンポーネント向けのログメッセージを生成します。
klogの設定に関する詳しい情報については、コマンドラインツールのリファレンス を参照してください。
klogネイティブ形式の例:
I1025 00:15:15.525108 1 httplog.go:79] GET /api/v1/namespaces/kube-system/pods/metrics-server-v0.3.1-57c75779f-9p8wg: (1.512ms) 200 [pod_nanny/v0.0.0 (linux/amd64) kubernetes/$Format 10.56.1.19:51756]
構造化ログ
FEATURE STATE: Kubernetes v1.19 [alpha]
警告: 構造化ログへのマイグレーションは現在進行中の作業です。このバージョンでは、すべてのログメッセージが構造化されているわけではありません。ログファイルをパースする場合、JSONではないログの行にも対処しなければなりません。
ログの形式と値のシリアライズは変更される可能性があります。
構造化ログは、ログメッセージに単一の構造を導入し、プログラムで情報の抽出ができるようにするものです。構造化ログは、僅かな労力とコストで保存・処理できます。新しいメッセージ形式は後方互換性があり、デフォルトで有効化されます。
構造化ログの形式:
<klog header> "<message>" <key1> = "<value1>" <key2>="<value2>" ...
例:
I1025 00:15:15.525108 1 controller_utils.go:116] "Pod status updated" pod = "kube-system/kubedns" status="ready"
JSONログ形式
FEATURE STATE: Kubernetes v1.19 [alpha]
警告: JSONの出力は多数の標準のklogフラグをサポートしていません。非対応のklogフラグの一覧については、コマンドラインツールリファレンス を参照してください。
すべてのログがJSON形式で書き込むことに対応しているわけではありません(たとえば、プロセスの開始時など)。ログのパースを行おうとしている場合、JSONではないログの行に対処できるようにしてください。
フィールド名とJSONのシリアライズは変更される可能性があります。
--logging-format=jsonフラグは、ログの形式をネイティブ形式klogからJSON形式に変更します。以下は、JSONログ形式の例(pretty printしたもの)です。
{
"ts" : 1580306777.04728 ,
"v" : 4 ,
"msg" : "Pod status updated" ,
"pod" :{
"name" : "nginx-1" ,
"namespace" : "default"
},
"status" : "ready"
}
特別な意味を持つキー:
ts - Unix時間のタイムスタンプ(必須、float)v - verbosity (必須、int、デフォルトは0)err - エラー文字列 (オプション、string)msg - メッセージ (必須、string)
現在サポートされているJSONフォーマットの一覧:
ログのサニタイズ
FEATURE STATE: Kubernetes v1.20 [alpha]
警告: ログのサニタイズ大きな計算のオーバーヘッドを引き起こす可能性があるため、本番環境では有効にするべきではありません。
--experimental-logging-sanitizationフラグはklogのサニタイズフィルタを有効にします。有効にすると、すべてのログの引数が機密データ(パスワード、キー、トークンなど)としてタグ付けされたフィールドについて検査され、これらのフィールドのログの記録は防止されます。
現在ログのサニタイズをサポートしているコンポーネント一覧:
kube-controller-manager
kube-apiserver
kube-scheduler
kubelet
備考: ログのサニタイズフィルターは、ユーザーのワークロードのログが機密データを漏洩するのを防げるわけではありません。
ログのverbosityレベル
-vフラグはログのverbosityを制御します。値を増やすとログに記録されるイベントの数が増えます。値を減らすとログに記録されるイベントの数が減ります。verbosityの設定を増やすと、ますます多くの深刻度の低いイベントをログに記録するようになります。verbosityの設定を0にすると、クリティカルなイベントだけをログに記録します。
ログの場所
システムコンポーネントには2種類あります。コンテナ内で実行されるコンポーネントと、コンテナ内で実行されないコンポーネントです。たとえば、次のようなコンポーネントがあります。
Kubernetesのスケジューラーやkube-proxyはコンテナ内で実行されます。
kubeletやDockerのようなコンテナランタイムはコンテナ内で実行されません。
systemdを使用しているマシンでは、kubeletとコンテナランタイムはjournaldに書き込みを行います。それ以外のマシンでは、/var/logディレクトリ内の.logファイルに書き込みます。コンテナ内部のシステムコンポーネントは、デフォルトのログ機構をバイパスするため、常に/var/logディレクトリ内の.logファイルに書き込みます。コンテナのログと同様に、/var/logディレクトリ内のシステムコンポーネントのログはローテートする必要があります。kube-up.shスクリプトによって作成されたKubernetesクラスターでは、ログローテーションはlogrotateツールで設定されます。logrotateツールはログを1日ごとまたはログのサイズが100MBを超えたときにローテートします。
次の項目
11.7 - Kubernetesのプロキシ
このページではKubernetesと併用されるプロキシについて説明します。
プロキシ
Kubernetesを使用する際に、いくつかのプロキシを使用する場面があります。
kubectlのプロキシ :
ユーザーのデスクトップ上かPod内で稼働します
ローカルホストのアドレスからKubernetes apiserverへのプロキシを行います
クライアントからプロキシ間ではHTTPを使用します
プロキシからapiserverへはHTTPSを使用します
apiserverの場所を示します
認証用のヘッダーを追加します
apiserverのプロキシ :
apiserver内で動作する踏み台となります
これがなければ到達不可能であるクラスターIPへ、クラスターの外部からのユーザーを接続します
apiserverのプロセス内で稼働します
クライアントからプロキシ間ではHTTPSを使用します(apiserverの設定により、HTTPを使用します)
プロキシからターゲット間では利用可能な情報を使用して、プロキシによって選択されたHTTPかHTTPSのいずれかを使用します
Node、Pod、Serviceへ到達するのに使えます
Serviceへ到達するときは負荷分散を行います
kube proxy :
各ノード上で稼働します
UDP、TCP、SCTPをプロキシします
HTTPを解釈しません
負荷分散機能を提供します
Serviceへ到達させるためのみに使用されます
apiserverの前段にあるプロキシ/ロードバランサー:
実際に存在するかどうかと実装はクラスターごとに異なります(例: nginx)
全てのクライアントと、1つ以上のapiserverの間に位置します
複数のapiserverがあるときロードバランサーとして稼働します
外部サービス上で稼働するクラウドロードバランサー:
いくつかのクラウドプロバイダーによって提供されます(例: AWS ELB、Google Cloud Load Balancer)
LoadBalancerというtypeのKubernetes Serviceが作成されたときに自動で作成されますたいていのクラウドロードバランサーはUDP/TCPのみサポートしています
SCTPのサポートはクラウドプロバイダーのロードバランサーの実装によって異なります
ロードバランサーの実装はクラウドプロバイダーによって異なります
Kubernetesユーザーのほとんどは、最初の2つのタイプ以外に心配する必要はありません。クラスター管理者はそれ以外のタイプのロードバランサーを正しくセットアップすることを保証します。
リダイレクトの要求
プロキシはリダイレクトの機能を置き換えました。リダイレクトの使用は非推奨となります。
11.8 - アドオンのインストール
備考: このセクションでは、Kubernetesが必要とする機能を提供するサードパーティープロジェクトにリンクしています。これらのプロジェクトはアルファベット順に記載されていて、Kubernetesプロジェクトの作者は責任を持ちません。このリストにプロジェクトを追加するには、変更を提出する前に
content guide をお読みください。
詳細はこちら。 アドオンはKubernetesの機能を拡張するものです。
このページでは、利用可能なアドオンの一部の一覧と、それぞれのアドオンのインストール方法へのリンクを提供します。この一覧は、すべてを網羅するものではありません。
ネットワークとネットワークポリシー
ACI は、統合されたコンテナネットワークとネットワークセキュリティをCisco ACIを使用して提供します。Antrea は、L3またはL4で動作して、Open vSwitchをネットワークデータプレーンとして活用する、Kubernetes向けのネットワークとセキュリティサービスを提供します。Calico はネットワークとネットワークポリシーのプロバイダーです。Calicoは、BGPを使用または未使用の非オーバーレイおよびオーバーレイネットワークを含む、フレキシブルなさまざまなネットワークオプションをサポートします。Calicoはホスト、Pod、そして(IstioとEnvoyを使用している場合には)サービスメッシュ上のアプリケーションに対してネットワークポリシーを強制するために、同一のエンジンを使用します。Canal はFlannelとCalicoをあわせたもので、ネットワークとネットワークポリシーを提供します。Cilium は、L3のネットワークとネットワークポリシーのプラグインで、HTTP/API/L7のポリシーを透過的に強制できます。ルーティングとoverlay/encapsulationモードの両方をサポートしており、他のCNIプラグイン上で機能できます。CNI-Genie は、KubernetesをCalico、Canal、Flannel、Weaveなど選択したCNIプラグインをシームレスに接続できるようにするプラグインです。Contiv は、さまざまなユースケースと豊富なポリシーフレームワーク向けに設定可能なネットワーク(BGPを使用したネイティブのL3、vxlanを使用したオーバーレイ、古典的なL2、Cisco-SDN/ACI)を提供します。Contivプロジェクトは完全にオープンソース です。インストーラー はkubeadmとkubeadm以外の両方をベースとしたインストールオプションがあります。Contrail は、Tungsten Fabric をベースにしている、オープンソースでマルチクラウドに対応したネットワーク仮想化およびポリシー管理プラットフォームです。ContrailおよびTungsten Fabricは、Kubernetes、OpenShift、OpenStack、Mesosなどのオーケストレーションシステムと統合されており、仮想マシン、コンテナ/Pod、ベアメタルのワークロードに隔離モードを提供します。Flannel は、Kubernetesで使用できるオーバーレイネットワークプロバイダーです。Knitter は、1つのKubernetes Podで複数のネットワークインターフェースをサポートするためのプラグインです。Multus は、すべてのCNIプラグイン(たとえば、Calico、Cilium、Contiv、Flannel)に加えて、SRIOV、DPDK、OVS-DPDK、VPPをベースとするKubernetes上のワークロードをサポートする、複数のネットワークサポートのためのマルチプラグインです。OVN-Kubernetes は、Open vSwitch(OVS)プロジェクトから生まれた仮想ネットワーク実装であるOVN(Open Virtual Network) をベースとする、Kubernetesのためのネットワークプロバイダーです。OVN-Kubernetesは、OVSベースのロードバランサーおよびネットワークポリシーの実装を含む、Kubernetes向けのオーバーレイベースのネットワーク実装を提供します。Nodus は、OVNベースのCNIコントローラープラグインで、クラウドネイティブベースのService function chaining(SFC)を提供します。NSX-T Container Plug-in(NCP)は、VMware NSX-TとKubernetesなどのコンテナオーケストレーター間のインテグレーションを提供します。また、NSX-Tと、Pivotal Container Service(PKS)とOpenShiftなどのコンテナベースのCaaS/PaaSプラットフォームとのインテグレーションも提供します。Nuage は、Kubernetes Podと非Kubernetes環境間で可視化とセキュリティモニタリングを使用してポリシーベースのネットワークを提供するSDNプラットフォームです。Romana は、NetworkPolicy APIもサポートするPodネットワーク向けのL3のネットワークソリューションです。Weave Net は、ネットワークパーティションの両面で機能し、外部データベースを必要とせずに、ネットワークとネットワークポリシーを提供します。
サービスディスカバリー
可視化と制御
インフラストラクチャ
レガシーなアドオン
いくつかのアドオンは、廃止されたcluster/addons ディレクトリに掲載されています。
よくメンテナンスされたアドオンはここにリンクしてください。PRを歓迎しています。
12 - Kubernetesを拡張する
Kubernetesクラスターの挙動を変えるいろいろな方法
Kubernetesは柔軟な設定が可能で、高い拡張性を持っています。
結果として、Kubernetesのプロジェクトソースコードをフォークしたり、パッチを当てて利用することは滅多にありません。
このガイドは、Kubernetesクラスターをカスタマイズするための選択肢を記載します。
管理しているKubernetesクラスターを、動作環境の要件にどのように適合させるべきかを理解したいクラスター管理者 を対象にしています。
将来の プラットフォーム開発者 、またはKubernetesプロジェクトのコントリビューター にとっても、どのような拡張のポイントやパターンが存在するのか、また、それぞれのトレードオフや制限事項を学ぶための導入として役立つでしょう。
概要
カスタマイズのアプローチには大きく分けて、フラグ、ローカル設定ファイル、またはAPIリソースの変更のみを含んだ 設定 と、稼働しているプログラムまたはサービスも含んだ 拡張 があります。このドキュメントでは、主に拡張について説明します。
設定
設定ファイル と フラグ はオンラインドキュメントのリファレンスセクションの中の、各項目に記載されています:
ホスティングされたKubernetesサービスやマネージドなKubernetesでは、フラグと設定ファイルが常に変更できるとは限りません。変更可能な場合でも、通常はクラスターの管理者のみが変更できます。また、それらは将来のKubernetesバージョンで変更される可能性があり、設定変更にはプロセスの再起動が必要になるかもしれません。これらの理由により、この方法は他の選択肢が無いときにのみ利用するべきです。
ResourceQuota 、PodSecurityPolicy 、NetworkPolicy 、そしてロールベースアクセス制御(RBAC )といった ビルトインポリシーAPI は、ビルトインのKubernetes APIです。APIは通常、ホスティングされたKubernetesサービスやマネージドなKubernetesで利用されます。これらは宣言的で、Podのような他のKubernetesリソースと同じ慣例に従っています。そのため、新しいクラスターの設定は繰り返し再利用することができ、アプリケーションと同じように管理することが可能です。さらに、安定版(stable)を利用している場合、他のKubernetes APIのような定義済みのサポートポリシー を利用することができます。これらの理由により、この方法は、適切な用途の場合、 設定ファイル や フラグ よりも好まれます。
拡張
拡張はKubernetesを拡張し、深く統合されたソフトウェアの構成要素です。
これは新しいタイプと、新しい種類のハードウェアをサポートするために利用されます。
ほとんどのクラスター管理者は、ホスティングされている、またはディストリビューションとしてのKubernetesを使っているでしょう。
結果として、ほとんどのKubernetesユーザーは既存の拡張を使えばよいため、新しい拡張を書く必要は無いと言えます。
拡張パターン
Kubernetesは、クライアントのプログラムを書くことで自動化ができるようにデザインされています。
Kubernetes APIに読み書きをするどのようなプログラムも、役に立つ自動化機能を提供することができます。
自動化機能 はクラスター上、またはクラスター外で実行できます。
このドキュメントに後述のガイダンスに従うことで、高い可用性を持つ頑強な自動化機能を書くことができます。
自動化機能は通常、ホスティングされているクラスター、マネージドな環境など、どのKubernetesクラスター上でも動きます。
Kubernetes上でうまく動くクライアントプログラムを書くために、コントローラー パターンという明確なパターンがあります。
コントローラーは通常、オブジェクトの .spec を読み取り、何らかの処理をして、オブジェクトの .status を更新します。
コントローラーはKubernetesのクライアントです。Kubernetesがクライアントとして動き、外部のサービスを呼び出す場合、それは Webhook と呼ばれます。
呼び出されるサービスは Webhookバックエンド と呼ばれます。コントローラーのように、Webhookも障害点を追加します。
Webhookのモデルでは、Kubernetesは外部のサービスを呼び出します。
バイナリプラグイン モデルでは、Kubernetesはバイナリ(プログラム)を実行します。
バイナリプラグインはkubelet(例、FlexVolumeプラグイン 、ネットワークプラグイン )、またkubectlで利用されています。
下図は、それぞれの拡張ポイントが、Kubernetesのコントロールプレーンとどのように関わっているかを示しています。
拡張ポイント
この図は、Kubernetesにおける拡張ポイントを示しています。
ユーザーは頻繁にkubectlを使って、Kubernetes APIとやり取りをします。Kubectlプラグイン は、kubectlのバイナリを拡張します。これは個別ユーザーのローカル環境のみに影響を及ぼすため、サイト全体にポリシーを強制することはできません。
APIサーバーは全てのリクエストを処理します。APIサーバーのいくつかの拡張ポイントは、リクエストを認可する、コンテキストに基づいてブロックする、リクエストを編集する、そして削除を処理することを可能にします。これらはAPIアクセス拡張 セクションに記載されています。
APIサーバーは様々な種類の リソース を扱います。Podのような ビルトインリソース はKubernetesプロジェクトにより定義され、変更できません。ユーザーも、自身もしくは、他のプロジェクトで定義されたリソースを追加することができます。それは カスタムリソース と呼ばれ、カスタムリソース セクションに記載されています。カスタムリソースは度々、APIアクセス拡張と一緒に使われます。
KubernetesのスケジューラーはPodをどのノードに配置するかを決定します。スケジューリングを拡張するには、いくつかの方法があります。それらはスケジューラー拡張 セクションに記載されています。
Kubernetesにおける多くの振る舞いは、APIサーバーのクライアントであるコントローラーと呼ばれるプログラムに実装されています。コントローラーは度々、カスタムリソースと共に使われます。
kubeletはサーバー上で実行され、Podが仮想サーバーのようにクラスターネットワーク上にIPを持った状態で起動することをサポートします。ネットワークプラグイン がPodのネットワーキングにおける異なる実装を適用することを可能にします。
kubeletはまた、コンテナのためにボリュームをマウント、アンマウントします。新しい種類のストレージはストレージプラグイン を通じてサポートされます。
もしあなたがどこから始めるべきかわからない場合、このフローチャートが役立つでしょう。一部のソリューションは、いくつかの種類の拡張を含んでいることを留意してください。
API拡張
ユーザー定義タイプ
新しいコントローラー、アプリケーションの設定に関するオブジェクト、また宣言型APIを定義し、それらをkubectlのようなKubernetesのツールから管理したい場合、Kubernetesにカスタムリソースを追加することを検討して下さい。
カスタムリソースはアプリケーション、ユーザー、監視データのデータストレージとしては使わないで下さい。
カスタムリソースに関するさらなる情報は、カスタムリソースコンセプトガイド を参照して下さい。
新しいAPIと自動化機能の連携
カスタムリソースAPIと制御ループの組み合わせはオペレーターパターン と呼ばれています。オペレーターパターンは、通常ステートフルな特定のアプリケーションを管理するために利用されます。これらのカスタムAPIと制御ループは、ストレージ、またはポリシーのような他のリソースを管理するためにも利用されます。
ビルトインリソースの変更
カスタムリソースを追加し、KubernetesAPIを拡張する場合、新たに追加されたリソースは常に新しいAPIグループに分類されます。既存のAPIグループを置き換えたり、変更することはできません。APIを追加することは直接、既存のAPI(例、Pod)の振る舞いに影響を与えることは無いですが、APIアクセス拡張の場合、その可能性があります。
APIアクセス拡張
リクエストがKubernetes APIサーバーに到達すると、まず最初に認証が行われ、次に認可、その後、様々なAdmission Controlの対象になります。このフローの詳細はKubernetes APIへのアクセスをコントロールする を参照して下さい。
これらの各ステップごとに拡張ポイントが用意されています。
Kubdernetesはいくつかのビルトイン認証方式をサポートしています。それは認証プロキシの後ろに配置することも可能で、認可ヘッダーを通じて(Webhookの)検証のために外部サービスにトークンを送ることもできます。全てのこれらの方法は認証ドキュメント でカバーされています。
認証
認証 は、全てのリクエストのヘッダーまたは証明書情報を、リクエストを投げたクライアントのユーザー名にマッピングします。
Kubernetesはいくつかのビルトイン認証方式と、それらが要件に合わない場合、認証Webhook を提供します。
認可
認可 は特定のユーザーがAPIリソースに対して、読み込み、書き込み、そしてその他の操作が可能かどうかを決定します。それはオブジェクト全体のレベルで機能し、任意のオブジェクトフィールドに基づいての区別は行いません。もしビルトインの認可メカニズムが要件に合わない場合、認可Webhook が、ユーザー提供のコードを呼び出し認可の決定を行うことを可能にします。
動的Admission Control
リクエストが認可された後、もしそれが書き込み操作だった場合、リクエストはAdmission Control のステップを通ります。ビルトインのステップに加え、いくつかの拡張が存在します:
インフラストラクチャ拡張
ストレージプラグイン
Flex Volumes は、Kubeletがバイナリプラグインを呼び出してボリュームをマウントすることにより、ユーザーはビルトインのサポートなしでボリュームタイプをマウントすることを可能にします。
デバイスプラグイン
デバイスプラグイン を通じて、ノードが新たなノードのリソース(CPU、メモリなどのビルトインのものに加え)を見つけることを可能にします。
ネットワークプラグイン
他のネットワークファブリックがネットワークプラグイン を通じてサポートされます。
スケジューラー拡張
スケジューラーは特別な種類のコントローラーで、Podを監視し、Podをノードに割り当てます。デフォルトのコントローラーを完全に置き換えることもできますが、他のKubernetesのコンポーネントの利用を継続する、または複数のスケジューラー を同時に動かすこともできます。
これはかなりの大きな作業で、ほとんど全てのKubernetesユーザーはスケジューラーを変更する必要はありません。
スケジューラはWebhook もサポートしており、Webhookバックエンド(スケジューラー拡張)を通じてPodを配置するために選択されたノードをフィルタリング、優先度付けすることが可能です。
次の項目
12.1 - Kubernetesクラスターの拡張
Kubernetesは柔軟な設定が可能で、高い拡張性を持っています。
結果として、Kubernetesのプロジェクトソースコードをフォークしたり、パッチを当てて利用することは滅多にありません。
このガイドは、Kubernetesクラスターをカスタマイズするための選択肢を記載します。
管理しているKubernetesクラスターを、動作環境の要件にどのように適合させるべきかを理解したいクラスター管理者 を対象にしています。
将来の プラットフォーム開発者 、またはKubernetesプロジェクトのコントリビューター にとっても、どのような拡張のポイントやパターンが存在するのか、また、それぞれのトレードオフや制限事項を学ぶための導入として役立つでしょう。
概要
カスタマイズのアプローチには大きく分けて、フラグ、ローカル設定ファイル、またはAPIリソースの変更のみを含んだ コンフィグレーション と、稼働しているプログラムまたはサービスも含んだ エクステンション があります。このドキュメントでは、主にエクステンションについて説明します。
コンフィグレーション
設定ファイル と フラグ はオンラインドキュメントのリファレンスセクションの中の、各項目に記載されています:
ホスティングされたKubernetesサービスやマネージドなKubernetesでは、フラグと設定ファイルが常に変更できるとは限りません。変更可能な場合でも、通常はクラスターの管理者のみが変更できます。また、それらは将来のKubernetesバージョンで変更される可能性があり、設定変更にはプロセスの再起動が必要になるかもしれません。これらの理由により、この方法は他の選択肢が無いときにのみ利用するべきです。
ResourceQuota 、PodSecurityPolicy 、NetworkPolicy 、そしてロールベースアクセス制御(RBAC )といった ビルトインポリシーAPI は、ビルトインのKubernetes APIです。APIは通常、ホスティングされたKubernetesサービスやマネージドなKubernetesで利用されます。これらは宣言的で、Podのような他のKubernetesリソースと同じ慣例に従っています。そのため、新しいクラスターの設定は繰り返し再利用することができ、アプリケーションと同じように管理することが可能です。さらに、安定版(stable)を利用している場合、他のKubernetes APIのような定義済みのサポートポリシー を利用することができます。これらの理由により、この方法は、適切な用途の場合、 設定ファイル や フラグ よりも好まれます。
エクステンション
エクステンションはKubernetesを拡張し、深く統合されたソフトウェアの構成要素です。
これは新しいタイプと、新しい種類のハードウェアをサポートするために利用されます。
ほとんどのクラスター管理者は、ホスティングされている、またはディストリビューションとしてのKubernetesを使っているでしょう。
結果として、ほとんどのKubernetesユーザーは既存のエクステンションを使えばよいため、新しいエクステンションを書く必要は無いと言えます。
エクステンションパターン
Kubernetesは、クライアントのプログラムを書くことで自動化ができるようにデザインされています。
Kubernetes APIに読み書きをするどのようなプログラムも、役に立つ自動化機能を提供することができます。
自動化機能 はクラスター上、またはクラスター外で実行できます。
このドキュメントに後述のガイダンスに従うことで、高い可用性を持つ頑強な自動化機能を書くことができます。
自動化機能は通常、ホスティングされているクラスター、マネージドな環境など、どのKubernetesクラスター上でも動きます。
Kubernetes上でうまく動くクライアントプログラムを書くために、コントローラー パターンという明確なパターンがあります。
コントローラーは通常、オブジェクトの .spec を読み取り、何らかの処理をして、オブジェクトの .status を更新します。
コントローラーはKubernetesのクライアントです。Kubernetesがクライアントとして動き、外部のサービスを呼び出す場合、それは Webhook と呼ばれます。
呼び出されるサービスは Webhookバックエンド と呼ばれます。コントローラーのように、Webhookも障害点を追加します。
Webhookのモデルでは、Kubernetesは外部のサービスを呼び出します。
バイナリプラグイン モデルでは、Kubernetesはバイナリ(プログラム)を実行します。
バイナリプラグインはkubelet(例、FlexVolumeプラグイン 、ネットワークプラグイン )、またkubectlで利用されています。
下図は、それぞれの拡張ポイントが、Kubernetesのコントロールプレーンとどのように関わっているかを示しています。
拡張ポイント
この図は、Kubernetesにおける拡張ポイントを示しています。
ユーザーは頻繁にkubectlを使って、Kubernetes APIとやり取りをします。Kubectlプラグイン は、kubectlのバイナリを拡張します。これは個別ユーザーのローカル環境のみに影響を及ぼすため、サイト全体にポリシーを強制することはできません。
APIサーバーは全てのリクエストを処理します。APIサーバーのいくつかの拡張ポイントは、リクエストを認可する、コンテキストに基づいてブロックする、リクエストを編集する、そして削除を処理することを可能にします。これらはAPIアクセスエクステンション セクションに記載されています。
APIサーバーは様々な種類の リソース を扱います。Podのような ビルトインリソース はKubernetesプロジェクトにより定義され、変更できません。ユーザーも、自身もしくは、他のプロジェクトで定義されたリソースを追加することができます。それは カスタムリソース と呼ばれ、カスタムリソース セクションに記載されています。カスタムリソースは度々、APIアクセスエクステンションと一緒に使われます。
KubernetesのスケジューラーはPodをどのノードに配置するかを決定します。スケジューリングを拡張するには、いくつかの方法があります。それらはスケジューラーエクステンション セクションに記載されています。
Kubernetesにおける多くの振る舞いは、APIサーバーのクライアントであるコントローラーと呼ばれるプログラムに実装されています。コントローラーは度々、カスタムリソースと共に使われます。
kubeletはサーバー上で実行され、Podが仮想サーバーのようにクラスターネットワーク上にIPを持った状態で起動することをサポートします。ネットワークプラグイン がPodのネットワーキングにおける異なる実装を適用することを可能にします。
kubeletはまた、コンテナのためにボリュームをマウント、アンマウントします。新しい種類のストレージはストレージプラグイン を通じてサポートされます。
もしあなたがどこから始めるべきかわからない場合、このフローチャートが役立つでしょう。一部のソリューションは、いくつかの種類のエクステンションを含んでいることを留意してください。
APIエクステンション
ユーザー定義タイプ
新しいコントローラー、アプリケーションの設定に関するオブジェクト、また宣言型APIを定義し、それらをkubectlのようなKubernetesのツールから管理したい場合、Kubernetesにカスタムリソースを追加することを検討して下さい。
カスタムリソースはアプリケーション、ユーザー、監視データのデータストレージとしては使わないで下さい。
カスタムリソースに関するさらなる情報は、カスタムリソースコンセプトガイド を参照して下さい。
新しいAPIと自動化機能の連携
カスタムリソースAPIと制御ループの組み合わせはオペレーターパターン と呼ばれています。オペレーターパターンは、通常ステートフルな特定のアプリケーションを管理するために利用されます。これらのカスタムAPIと制御ループは、ストレージ、またはポリシーのような他のリソースを管理するためにも利用されます。
ビルトインリソースの変更
カスタムリソースを追加し、KubernetesAPIを拡張する場合、新たに追加されたリソースは常に新しいAPIグループに分類されます。既存のAPIグループを置き換えたり、変更することはできません。APIを追加することは直接、既存のAPI(例、Pod)の振る舞いに影響を与えることは無いですが、APIアクセスエクステンションの場合、その可能性があります。
APIアクセスエクステンション
リクエストがKubernetes APIサーバーに到達すると、まず最初に認証が行われ、次に認可、その後、様々なAdmission Controlの対象になります。このフローの詳細はKubernetes APIへのアクセスをコントロールする を参照して下さい。
これらの各ステップごとに拡張ポイントが用意されています。
Kubdernetesはいくつかのビルトイン認証方式をサポートしています。それは認証プロキシの後ろに配置することも可能で、認可ヘッダーを通じて(Webhookの)検証のために外部サービスにトークンを送ることもできます。全てのこれらの方法は認証ドキュメント でカバーされています。
認証
認証 は、全てのリクエストのヘッダーまたは証明書情報を、リクエストを投げたクライアントのユーザー名にマッピングします。
Kubernetesはいくつかのビルトイン認証方式と、それらが要件に合わない場合、認証Webhook を提供します。
認可
認可 は特定のユーザーがAPIリソースに対して、読み込み、書き込み、そしてその他の操作が可能かどうかを決定します。それはオブジェクト全体のレベルで機能し、任意のオブジェクトフィールドに基づいての区別は行いません。もしビルトインの認可メカニズムが要件に合わない場合、認可Webhook が、ユーザー提供のコードを呼び出し認可の決定を行うことを可能にします。
動的Admission Control
リクエストが認可された後、もしそれが書き込み操作だった場合、リクエストはAdmission Control のステップを通ります。ビルトインのステップに加え、いくつかのエクステンションが存在します:
インフラストラクチャエクステンション
ストレージプラグイン
Flex Volumes は、Kubeletがバイナリプラグインを呼び出してボリュームをマウントすることにより、ユーザーはビルトインのサポートなしでボリュームタイプをマウントすることを可能にします。
デバイスプラグイン
デバイスプラグイン を通じて、ノードが新たなノードのリソース(CPU、メモリなどのビルトインのものに加え)を見つけることを可能にします。
ネットワークプラグイン
他のネットワークファブリックがネットワークプラグイン を通じてサポートされます。
スケジューラーエクステンション
スケジューラーは特別な種類のコントローラーで、Podを監視し、Podをノードに割り当てます。デフォルトのコントローラーを完全に置き換えることもできますが、他のKubernetesのコンポーネントの利用を継続する、または複数のスケジューラー を同時に動かすこともできます。
これはかなりの大きな作業で、ほとんど全てのKubernetesユーザーはスケジューラーを変更する必要はありません。
スケジューラはWebhook もサポートしており、Webhookバックエンド(スケジューラーエクステンション)を通じてPodを配置するために選択されたノードをフィルタリング、優先度付けすることが可能です。
次の項目
12.2 - Kubernetes APIの拡張
12.2.1 - カスタムリソース
カスタムリソース はKubernetes APIの拡張です。このページでは、いつKubernetesのクラスターにカスタムリソースを追加するべきなのか、そしていつスタンドアローンのサービスを利用するべきなのかを議論します。カスタムリソースを追加する2つの方法と、それらの選択方法について説明します。
カスタムリソース
リソース は、Kubernetes API のエンドポイントで、特定のAPIオブジェクト のコレクションを保持します。例えば、ビルトインの Pods リソースは、Podオブジェクトのコレクションを包含しています。
カスタムリソース は、Kubernetes APIの拡張で、デフォルトのKubernetesインストールでは、必ずしも利用できるとは限りません。つまりそれは、特定のKubernetesインストールのカスタマイズを表します。しかし、今現在、多数のKubernetesのコア機能は、カスタムリソースを用いて作られており、Kubernetesをモジュール化しています。
カスタムリソースは、稼働しているクラスターに動的に登録され、現れたり、消えたりし、クラスター管理者はクラスター自体とは無関係にカスタムリソースを更新できます。一度、カスタムリソースがインストールされると、ユーザーはkubectl を使い、ビルトインのリソースである Pods と同じように、オブジェクトを作成、アクセスすることが可能です。
カスタムコントローラー
カスタムリソースそれ自身は、単純に構造化データを格納、取り出す機能を提供します。カスタムリソースを カスタムコントローラー と組み合わせることで、カスタムリソースは真の 宣言的API を提供します。
宣言的API は、リソースのあるべき状態を 宣言 または指定することを可能にし、Kubernetesオブジェクトの現在の状態を、あるべき状態に同期し続けるように動きます。
コントローラーは、構造化データをユーザーが指定したあるべき状態と解釈し、その状態を管理し続けます。
稼働しているクラスターのライフサイクルとは無関係に、カスタムコントローラーをデプロイ、更新することが可能です。カスタムコントローラーはあらゆるリソースと連携できますが、カスタムリソースと組み合わせると特に効果を発揮します。オペレーターパターン は、カスタムリソースとカスタムコントローラーの組み合わせです。カスタムコントローラーにより、特定アプリケーションのドメイン知識を、Kubernetes APIの拡張に変換することができます。
カスタムリソースをクラスターに追加するべきか?
新しいAPIを作る場合、APIをKubernetesクラスターAPIにアグリゲート(集約)する か、もしくはAPIをスタンドアローンで動かすかを検討します。
APIアグリゲーションを使う場合:
スタンドアローンAPIを使う場合:
APIが宣言的
APIが宣言的 モデルに適さない
新しいリソースをkubectlを使い読み込み、書き込みしたい
kubectlのサポートは必要ない
新しいリソースをダッシュボードのような、Kubernetes UIで他のビルトインリソースと同じように管理したい
Kubernetes UIのサポートは必要ない
新しいAPIを開発している
APIを提供し、適切に機能するプログラムが既に存在している
APIグループ、名前空間というような、RESTリソースパスに割り当てられた、Kubernetesのフォーマット仕様の制限を許容できる(API概要 を参照)
既に定義済みのREST APIと互換性を持っていなければならない
リソースはクラスターごとか、クラスター内の名前空間に自然に分けることができる
クラスター、または名前空間による分割がリソース管理に適さない。特定のリソースパスに基づいて管理したい
Kubernetes APIサポート機能 を再利用したいこれらの機能は必要ない
宣言的API
宣言的APIは、通常、下記に該当します:
APIは、比較的少数の、比較的小さなオブジェクト(リソース)で構成されている
オブジェクトは、アプリケーションの設定、インフラストラクチャーを定義する
オブジェクトは、比較的更新頻度が低い
人は、オブジェクトの情報をよく読み書きする
オブジェクトに対する主要な手続きは、CRUD(作成、読み込み、更新、削除)になる
複数オブジェクトをまたいだトランザクションは必要ない: APIは今現在の状態ではなく、あるべき状態を表現する
命令的APIは、宣言的ではありません。
APIが宣言的ではない兆候として、次のものがあります:
クライアントから"これを実行"と命令がきて、完了の返答を同期的に受け取る
クライアントから"これを実行"と命令がきて、処理IDを取得する。そして処理が完了したかどうかを、処理IDを利用して別途問い合わせる
リモートプロシージャコール(RPC)という言葉が飛び交っている
直接、大量のデータを格納している(例、1オブジェクトあたり数kBより大きい、または数千オブジェクトより多い)
高帯域アクセス(持続的に毎秒数十リクエスト)が必要
エンドユーザーのデータ(画像、PII、その他)を格納している、またはアプリケーションが処理する大量のデータを格納している
オブジェクトに対する処理が、CRUDではない
APIをオブジェクトとして簡単に表現できない
停止している処理を処理ID、もしくは処理オブジェクトで表現することを選択している
ConfigMapとカスタムリソースのどちらを使うべきか?
下記のいずれかに該当する場合は、ConfigMapを使ってください:
mysql.cnf、pom.xmlのような、十分に文書化された設定ファイルフォーマットが既に存在している単一キーのConfigMapに、設定ファイルの内容の全てを格納している
設定ファイルの主な用途は、クラスター上のPodで実行されているプログラムがファイルを読み込み、それ自体を構成することである
ファイルの利用者は、Kubernetes APIよりも、Pod内のファイルまたはPod内の環境変数を介して利用することを好む
ファイルが更新されたときに、Deploymentなどを介してローリングアップデートを行いたい
備考: センシティブなデータには、ConfigMapに類似していますがよりセキュアな
secret を使ってください
下記のほとんどに該当する場合、カスタムリソース(CRD、またはアグリゲートAPI)を使ってください:
新しいリソースを作成、更新するために、Kubernetesのクライアントライブラリー、CLIを使いたい
kubectlのトップレベルサポートが欲しい(例、kubectl get my-object object-name)
新しい自動化の仕組みを作り、新しいオブジェクトの更新をウォッチしたい、その更新を契機に他のオブジェクトのCRUDを実行したい、またはその逆を行いたい
オブジェクトの更新を取り扱う、自動化の仕組みを書きたい
.spec、.status、.metadataというような、Kubernetes APIの慣習を使いたいオブジェクトは、制御されたリソースコレクションの抽象化、または他のリソースのサマリーとしたい
カスタムリソースを追加する
Kubernetesは、クラスターへカスタムリソースを追加する2つの方法を提供しています:
CRDはシンプルで、プログラミングなしに作成可能
APIアグリゲーション は、プログラミングが必要だが、データがどのように格納され、APIバージョン間でどのように変換されるかというような、より詳細なAPIの振る舞いを制御できる
Kubernetesは、さまざまなユーザーのニーズを満たすためにこれら2つのオプションを提供しており、使いやすさや柔軟性が損なわれることはありません。
アグリゲートAPIは、プロキシとして機能するプライマリAPIサーバーの背後にある、下位のAPIServerです。このような配置はAPIアグリゲーション (AA)と呼ばれています。ユーザーにとっては、単にAPIサーバーが拡張されているように見えます。
CRDでは、APIサーバーの追加なしに、ユーザーが新しい種類のリソースを作成できます。CRDを使うには、APIアグリゲーションを理解する必要はありません。
どのようにインストールされたかに関わらず、新しいリソースはカスタムリソースとして参照され、ビルトインのKubernetesリソース(Podなど)とは区別されます。
CustomResourceDefinition
CustomResourceDefinition APIリソースは、カスタムリソースを定義します。CRDオブジェクトを定義することで、指定した名前、スキーマで新しいカスタムリソースが作成されます。Kubernetes APIは、作成したカスタムリソースのストレージを提供、および処理します。
CRDオブジェクトの名前はDNSサブドメイン名 に従わなければなりません。
これはカスタムリソースを処理するために、独自のAPIサーバーを書くことから解放してくれますが、一般的な性質としてAPIサーバーアグリゲーション と比べると、柔軟性に欠けます。
新しいカスタムリソースをどのように登録するか、新しいリソースタイプとの連携、そしてコントローラーを使いイベントを処理する方法例について、カスタムコントローラー例 を参照してください。
APIサーバーアグリゲーション
通常、Kubernetes APIの各リソースは、RESTリクエストとオブジェクトの永続的なストレージを管理するためのコードが必要です。メインのKubernetes APIサーバーは Pod や Service のようなビルトインのリソースを処理し、またカスタムリソースもCRD を通じて同じように管理することができます。
アグリゲーションレイヤー は、独自のAPIサーバーを書き、デプロイすることで、カスタムリソースに特化した実装の提供を可能にします。メインのAPIサーバーが、処理したいカスタムリソースへのリクエストを独自のAPIサーバーに委譲することで、他のクライアントからも利用できるようにします。
カスタムリソースの追加方法を選択する
CRDは簡単に使えます。アグリゲートAPIはより柔軟です。ニーズに最も合う方法を選択してください。
通常、CRDは下記の場合に適しています:
少数のフィールドしか必要ない
そのリソースは社内のみで利用している、または小さいオープンソースプロジェクトの一部で利用している(商用プロダクトではない)
使いやすさの比較
CRDは、アグリゲートAPIと比べ、簡単に作れます。
CRD
アグリゲートAPI
プログラミングが不要で、ユーザーはCRDコントローラーとしてどの言語でも選択可能
Go言語でプログラミングし、バイナリとイメージの作成が必要
追加のサービスは不要。CRDはAPIサーバーで処理される
追加のサービス作成が必要で、障害が発生する可能性がある
CRDが作成されると、継続的なサポートは無い。バグ修正は通常のKubernetesマスターのアップグレードで行われる
定期的にアップストリームからバグ修正の取り込み、リビルド、そしてアグリゲートAPIサーバーの更新が必要かもしれない
複数バージョンのAPI管理は不要。例えば、あるリソースを操作するクライアントを管理していた場合、APIのアップグレードと一緒に更新される
複数バージョンのAPIを管理しなければならない。例えば、世界中に共有されている拡張機能を開発している場合
高度な機能、柔軟性
アグリゲートAPIは、例えばストレージレイヤーのカスタマイズのような、より高度なAPI機能と他の機能のカスタマイズを可能にします。
機能
詳細
CRD
アグリゲートAPI
バリデーション
エラーを予防し、クライアントと無関係にAPIを発達させることができるようになる。これらの機能は多数のクライアントがおり、同時に全てを更新できないときに最も効果を発揮する
はい、ほとんどのバリデーションはOpenAPI v3.0 validation で、CRDに指定できる。その他のバリデーションはWebhookのバリデーション によりサポートされている
はい、任意のバリデーションが可能
デフォルト設定
上記を参照
はい、OpenAPI v3.0 validation のdefaultキーワード(1.17でGA)、またはMutating Webhook を通じて可能 (ただし、この方法は古いオブジェクトをetcdから読み込む場合には動きません)
はい
複数バージョニング
同じオブジェクトを、違うAPIバージョンで利用可能にする。フィールドの名前を変更するなどのAPIの変更を簡単に行うのに役立つ。クライアントのバージョンを管理する場合、重要性は下がる
はい はい
カスタムストレージ
異なる性能のストレージが必要な場合(例えば、キーバリューストアの代わりに時系列データベース)または、セキュリティの分離(例えば、機密情報の暗号化、その他)
いいえ
はい
カスタムビジネスロジック
オブジェクトが作成、読み込み、更新、また削除されるときに任意のチェック、アクションを実行する
はい、Webhooks を利用
はい
サブリソースのスケール
HorizontalPodAutoscalerやPodDisruptionBudgetなどのシステムが、新しいリソースと連携できるようにする
はい はい
サブリソースの状態
ユーザーがspecセクションに書き込み、コントローラーがstatusセクションに書き込む際に、より詳細なアクセスコントロールができるようにする。カスタムリソースのデータ変換時にオブジェクトの世代を上げられるようにする(リソース内のspecとstatusでセクションが分離している必要がある)
はい はい
その他のサブリソース
"logs"や"exec"のような、CRUD以外の処理の追加
いいえ
はい
strategic-merge-patch
Content-Type: application/strategic-merge-patch+jsonで、PATCHをサポートする新しいエンドポイント。ローカル、サーバー、どちらでも更新されうるオブジェクトに有用。さらなる情報は"APIオブジェクトをkubectl patchで決まった場所で更新" を参照いいえ
はい
プロトコルバッファ
プロトコルバッファを使用するクライアントをサポートする新しいリソース
いいえ
はい
OpenAPIスキーマ
サーバーから動的に取得できる型のOpenAPI(Swagger)スキーマはあるか、許可されたフィールドのみが設定されるようにすることで、ユーザーはフィールド名のスペルミスから保護されているか、型は強制されているか(言い換えると、「文字列」フィールドに「int」を入れさせない)
はい、OpenAPI v3.0 validation スキーマがベース(1.16でGA)
はい
一般的な機能
CRD、またはアグリゲートAPI、どちらを使ってカスタムリソースを作った場合でも、Kubernetesプラットフォーム外でAPIを実装するのに比べ、多数の機能が提供されます:
機能
何を実現するか
CRUD
新しいエンドポイントが、HTTP、kubectlを通じて、基本的なCRUD処理をサポート
Watch
新しいエンドポイントが、HTTPを通じて、KubernetesのWatch処理をサポート
Discovery
kubectlやダッシュボードのようなクライアントが、自動的にリソースの一覧表示、個別表示、フィールドの編集処理を提供
json-patch
新しいエンドポイントがContent-Type: application/json-patch+jsonを用いたPATCHをサポート
merge-patch
新しいエンドポイントがContent-Type: application/merge-patch+jsonを用いたPATCHをサポート
HTTPS
新しいエンドポイントがHTTPSを利用
ビルトイン認証
拡張機能へのアクセスに認証のため、コアAPIサーバー(アグリゲーションレイヤー)を利用
ビルトイン認可
拡張機能へのアクセスにコアAPIサーバーで使われている認可メカニズムを再利用(例、RBAC)
ファイナライザー
外部リソースの削除が終わるまで、拡張リソースの削除をブロック
Admission Webhooks
拡張リソースの作成/更新/削除処理時に、デフォルト値の設定、バリデーションを実施
UI/CLI 表示
kubectl、ダッシュボードで拡張リソースを表示
未設定 対 空設定
クライアントは、フィールドの未設定とゼロ値を区別することができる
クライアントライブラリーの生成
Kubernetesは、一般的なクライアントライブラリーと、タイプ固有のクライアントライブラリーを生成するツールを提供
ラベルとアノテーション
ツールがコアリソースとカスタムリソースの編集方法を知っているオブジェクト間で、共通のメタデータを提供
カスタムリソースのインストール準備
クラスターにカスタムリソースを追加する前に、いくつか認識しておくべき事項があります。
サードパーティのコードと新しい障害点
CRDを作成しても、勝手に新しい障害点が追加されてしまうことはありませんが(たとえば、サードパーティのコードをAPIサーバーで実行することによって)、パッケージ(たとえば、Chart)またはその他のインストールバンドルには、多くの場合、CRDと新しいカスタムリソースのビジネスロジックを実装するサードパーティコードが入ったDeploymentが含まれます。
アグリゲートAPIサーバーのインストールすると、常に新しいDeploymentが付いてきます。
ストレージ
カスタムリソースは、ConfigMapと同じ方法でストレージの容量を消費します。多数のカスタムリソースを作成すると、APIサーバーのストレージ容量を超えてしまうかもしれません。
アグリゲートAPIサーバーも、メインのAPIサーバーと同じストレージを利用するかもしれません。その場合、同じ問題が発生しえます。
認証、認可、そして監査
CRDでは、APIサーバーのビルトインリソースと同じ認証、認可、そして監査ロギングの仕組みを利用します。
もしRBACを使っている場合、ほとんどのRBACのロールは新しいリソースへのアクセスを許可しません。(クラスター管理者ロール、もしくはワイルドカードで作成されたロールを除く)新しいリソースには、明示的にアクセスを許可する必要があります。多くの場合、CRDおよびアグリゲートAPIには、追加するタイプの新しいロール定義がバンドルされています。
アグリゲートAPIサーバーでは、APIサーバーのビルトインリソースと同じ認証、認可、そして監査の仕組みを使う場合と使わない場合があります。
カスタムリソースへのアクセス
Kubernetesのクライアントライブラリー を使い、カスタムリソースにアクセスすることが可能です。全てのクライアントライブラリーがカスタムリソースをサポートしているわけでは無いですが、Go と Python のライブラリーはサポートしています。
カスタムリソースは、下記のような方法で操作できます:
kubectlkubernetesの動的クライアント
自作のRESTクライアント
Kubernetesクライアント生成ツール を使い生成したクライアント(生成は高度な作業ですが、一部のプロジェクトは、CRDまたはAAとともにクライアントを提供する場合があります)
次の項目
12.2.2 - アグリゲーションレイヤーを使ったKubernetes APIの拡張
アグリゲーションレイヤーを使用すると、KubernetesのコアAPIで提供されている機能を超えて、追加のAPIでKubernetesを拡張できます。追加のAPIは、service-catalog のような既製のソリューション、または自分で開発したAPIのいずれかです。
アグリゲーションレイヤーは、カスタムリソース とは異なり、kube-apiserver に新しい種類のオブジェクトを認識させる方法です。
アグリゲーションレイヤー
アグリゲーションレイヤーは、kube-apiserverのプロセス内で動きます。拡張リソースが登録されるまでは、アグリゲーションレイヤーは何もしません。APIを登録するには、ユーザーはKubernetes APIで使われるURLのパスを"要求"した、APIService オブジェクトを追加します。それを追加すると、アグリゲーションレイヤーはAPIパス(例、/apis/myextension.mycompany.io/v1/…)への全てのアクセスを、登録されたAPIServiceにプロキシします。
APIServiceを実装する最も一般的な方法は、クラスター内で実行されるPodで拡張APIサーバー を実行することです。クラスター内のリソース管理に拡張APIサーバーを使用している場合、拡張APIサーバー("extension-apiserver"とも呼ばれます)は通常、1つ以上のコントローラー とペアになっています。apiserver-builderライブラリは、拡張APIサーバーと関連するコントローラーの両方にスケルトンを提供します。
応答遅延
拡張APIサーバーは、kube-apiserverとの間の低遅延ネットワーキングが必要です。
kube-apiserverとの間を5秒以内に往復するためには、ディスカバリーリクエストが必要です。
拡張APIサーバーがそのレイテンシ要件を達成できない場合は、その要件を満たすように変更することを検討してください。また、kube-apiserverでEnableAggregatedDiscoveryTimeout=false フィーチャーゲート を設定することで、タイムアウト制限を無効にすることができます。この非推奨のフィーチャーゲートは将来のリリースで削除される予定です。
次の項目
12.3 - オペレーターパターン
オペレーターはカスタムリソース を使用するKubernetesへのソフトウェア拡張です。
オペレーターは、特に制御ループ のようなKubernetesが持つ仕組みに準拠しています。
モチベーション
オペレーターパターンはサービス、またはサービス群を管理している運用担当者の主な目的をキャプチャすることが目標です。
特定のアプリケーション、サービスの面倒を見ている運用担当者は、システムがどのように振る舞うべきか、どのようにデプロイをするか、何らかの問題があったときにどのように対応するかについて深い知識を持っています。
Kubernetes上でワークロードを稼働させている人は、しばしば繰り返し可能なタスクを自動化することを好みます。
オペレーターパターンは、Kubernetes自身が提供している機能を超えて、あなたがタスクを自動化するために、どのようにコードを書くかをキャプチャします。
Kubernetesにおけるオペレーター
Kubernetesは自動化のために設計されています。追加の作業、設定無しに、Kubernetesのコア機能によって多数のビルトインされた自動化機能が提供されます。
ワークロードのデプロイおよび稼働を自動化するためにKubernetesを使うことができます。 さらに Kubernetesがそれをどのように行うかの自動化も可能です。
Kubernetesのオペレーターパターン コンセプトは、Kubernetesのソースコードを修正すること無く、一つ以上のカスタムリソースにカスタムコントローラー をリンクすることで、クラスターの振る舞いを拡張することを可能にします。
オペレーターはKubernetes APIのクライアントで、Custom Resource にとっての、コントローラーのように振る舞います。
オペレーターの例
オペレーターを使い自動化できるいくつかのことは、下記のようなものがあります:
必要に応じてアプリケーションをデプロイする
アプリケーションの状態のバックアップを取得、リストアする
アプリケーションコードの更新と同時に、例えばデータベーススキーマ、追加の設定修正など必要な変更の対応を行う
Kubernetes APIをサポートしていないアプリケーションに、サービスを公開してそれらを発見する
クラスターの回復力をテストするために、全て、または一部分の障害をシミュレートする
内部のリーダー選出プロセス無しに、分散アプリケーションのリーダーを選択する
オペレーターをもっと詳しく見るとどのように見えるでしょうか?より詳細な例を示します:
クラスターに設定可能なSampleDBという名前のカスタムリソース
オペレーターの、コントローラー部分を含むPodが実行されていることを保証するDeployment
オペレーターのコードを含んだコンテナイメージ
設定されているSampleDBのリソースを見つけるために、コントロールプレーンに問い合わせるコントローラーのコード
オペレーターのコアは、現実を、設定されているリソースにどのように合わせるかをAPIサーバーに伝えるコードです。
もし新しいSampleDBを追加した場合、オペレーターは永続化データベースストレージを提供するためにPersistentVolumeClaimsをセットアップし、StatefulSetがSampleDBの起動と、初期設定を担うJobを走らせます
もしそれを削除した場合、オペレーターはスナップショットを取り、StatefulSetとVolumeも合わせて削除されたことを確認します
オペレーターは定期的なデータベースのバックアップも管理します。それぞれのSampleDBリソースについて、オペレーターはデータベースに接続可能な、バックアップを取得するPodをいつ作成するかを決定します。これらのPodはデータベース接続の詳細情報、クレデンシャルを保持するConfigMapとSecret、もしくはどちらかに依存するでしょう。
オペレーターは、管理下のリソースの堅牢な自動化を提供することを目的としているため、補助的な追加コードが必要になるかもしれません。この例では、データベースが古いバージョンで動いているかどうかを確認するコードで、その場合、アップグレードを行うJobをあなたに代わり作成します。
オペレーターのデプロイ
オペレーターをデプロイする最も一般的な方法は、Custom Resource Definitionとそれに関連するコントローラーをクラスターに追加することです。
このコントローラーは通常、あなたがコンテナアプリケーションを動かすのと同じように、コントロールプレーン 外で動作します。
例えば、コントローラーをDeploymentとしてクラスター内で動かすことができます。
オペレーターを利用する
一度オペレーターをデプロイすると、そのオペレーターを使って、それ自身が使うリソースの種類を追加、変更、または削除できます。
上記の利用例に従ってオペレーターそのもののためのDeploymentをセットアップし、以下のようなコマンドを実行します:
kubectl get SampleDB # 設定したデータベースを発見します
kubectl edit SampleDB/example-database # 手動でいくつかの設定を変更します
これだけです!オペレーターが変更の適用だけでなく既存のサービスがうまく稼働し続けるように面倒を見てくれます。
自分でオペレーターを書く
必要な振る舞いを実装したオペレーターがエコシステム内に無い場合、自分で作成することができます。
次の項目 で、自分でクラウドネイティブオペレーターを作るときに利用できるライブラリやツールのリンクを見つけることができます。
オペレーター(すなわち、コントローラー)はどの言語/ランタイムでも実装でき、Kubernetes APIのクライアント として機能させることができます。
次の項目
12.4 - コンピュート、ストレージ、ネットワーキングの拡張機能
このセクションでは、Kubernetes自体の一部としては提供されていない、クラスターへの拡張について説明します。
これらの拡張を使用して、クラスター内のノードを強化したり、Pod同士をつなぐネットワークファブリックを提供したりすることができます。
CSI およびFlexVolume ストレージプラグイン
Container Storage Interface (CSI)プラグインは、新しい種類のボリュームをサポートするためのKubernetesの拡張方法を提供します。
これらのボリュームは、永続性のある外部ストレージにバックアップすることができます。また、一時的なストレージを提供することも、ファイルシステムのパラダイムを使用して、情報への読み取り専用のインターフェースを提供することもできます。
Kubernetesには、Kubernetes v1.23から非推奨とされている(CSIに置き換えられる)FlexVolume プラグインへのサポートも含まれています。
FlexVolumeプラグインは、Kubernetesがネイティブにサポートしていないボリュームタイプをマウントすることをユーザーに可能にします。
FlexVolumeストレージに依存するPodを実行すると、kubeletはバイナリプラグインを呼び出してボリュームをマウントします。
アーカイブされたFlexVolume デザインの提案には、このアプローチの詳細が記載されています。
Kubernetes Volume Plugin FAQ for Storage Vendors には、ストレージプラグインに関する一般的な情報が含まれています。
デバイスプラグイン
デバイスプラグインは、ノードが(cpuやmemoryなどの組み込みノードリソースに加えて)新しいNode設備を発見し、これらのカスタムなノードローカル設備を要求するPodに提供することを可能にします。
ネットワークプラグイン
ネットワークプラグインにより、Kubernetesはさまざまなネットワーキングのトポロジーや技術を扱うことができます。
動作するPodネットワークを持ち、Kubernetesネットワークモデルの他の側面をサポートするためには、Kubernetesクラスターに ネットワークプラグイン が必要です。
Kubernetes 1.30は、CNI ネットワークプラグインと互換性があります。
12.4.1 - ネットワークプラグイン
Kubernetes 1.30は、クラスターネットワーキングのためにContainer Network Interface (CNI)プラグインをサポートしています。
クラスターと互換性があり、需要に合ったCNIプラグインを使用する必要があります。
様々なプラグイン(オープンソースあるいはクローズドソース)が幅広いKubernetesエコシステムで利用可能です。
Kubernetesネットワークモデル を実装するには、CNIプラグインが必要です。
v0.4.0 以降のCNI仕様のリリースと互換性のあるCNIプラグインを使用する必要があります。
Kubernetesプロジェクトは、v1.0.0 のCNI仕様と互換性のあるプラグインの使用を推奨しています(プラグインは複数の仕様のバージョンに対応できます)。
インストール
ネットワーキングの文脈におけるコンテナランタイムは、ノード上のデーモンであり、kubelet向けのCRIサービスを提供するように設定されています。
特に、コンテナランタイムは、Kubernetesネットワークモデルを実装するために必要なCNIプラグインを読み込むように設定する必要があります。
備考: Kubernetes 1.24以前は、CNIプラグインはcni-bin-dirやnetwork-pluginといったコマンドラインパラメーターを使用してkubeletによって管理することもできました。
これらのコマンドラインパラメーターはKubernetes 1.24で削除され、CNIの管理はkubeletの範囲外となりました。
dockershimの削除に伴う問題に直面している場合は、CNIプラグイン関連のエラーのトラブルシューティング を参照してください。
コンテナランタイムがCNIプラグインをどのように管理しているかについての具体的な情報については、そのコンテナランタイムのドキュメントを参照してください。
例えば:
CNIプラグインのインストールや管理方法についての具体的な情報については、そのプラグインまたはネットワーキングプロバイダー のドキュメントを参照してください。
ネットワークプラグインの要件
ループバックCNI
Kubernetesネットワークモデルを実装するためにノードにインストールされたCNIプラグインに加えて、Kubernetesはコンテナランタイムにループバックインターフェースloを提供することも要求します。
これは各サンドボックス(Podサンドボックス、VMサンドボックスなど)に使用されます。
ループバックインターフェースの実装は、CNIループバックプラグイン を再利用するか、自分で実装することで達成できます(例: CRI-Oを用いた例 )。
hostPortのサポート
CNIネットワーキングプラグインはhostPortをサポートしています。
CNIプラグインチームが提供する公式のportmap プラグインを使用するか、ポートマッピング(portMapping)機能を持つ独自のプラグインを使用できます。
hostPortサポートを有効にする場合、cni-conf-dirでportMappings capabilityを指定する必要があります。
例:
{
"name" : "k8s-pod-network" ,
"cniVersion" : "0.4.0" ,
"plugins" : [
{
"type" : "calico" ,
"log_level" : "info" ,
"datastore_type" : "kubernetes" ,
"nodename" : "127.0.0.1" ,
"ipam" : {
"type" : "host-local" ,
"subnet" : "usePodCidr"
},
"policy" : {
"type" : "k8s"
},
"kubernetes" : {
"kubeconfig" : "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type" : "portmap" ,
"capabilities" : {"portMappings" : true },
"externalSetMarkChain" : "KUBE-MARK-MASQ"
}
]
}
トラフィックシェーピングのサポート
これは実験的な機能です
CNIネットワーキングプラグインは、Podの入出力トラフィックシェーピングにも対応しています。
CNIプラグインチームが提供する公式のbandwidth プラグインを使用するか、帯域制御機能を持つ独自のプラグインを使用できます。
トラフィックシェーピングのサポートを有効にする場合、bandwidthプラグインをCNIの設定ファイル(デフォルトは/etc/cni/net.d)に追加し、バイナリがCNIのbinディレクトリ(デフォルトは/opt/cni/bin)に含まれていることを確認する必要があります。
{
"name" : "k8s-pod-network" ,
"cniVersion" : "0.4.0" ,
"plugins" : [
{
"type" : "calico" ,
"log_level" : "info" ,
"datastore_type" : "kubernetes" ,
"nodename" : "127.0.0.1" ,
"ipam" : {
"type" : "host-local" ,
"subnet" : "usePodCidr"
},
"policy" : {
"type" : "k8s"
},
"kubernetes" : {
"kubeconfig" : "/etc/cni/net.d/calico-kubeconfig"
}
},
{
"type" : "bandwidth" ,
"capabilities" : {"bandwidth" : true }
}
]
}
これでPodにkubernetes.io/ingress-bandwidthとkubernetes.io/egress-bandwidthのアノテーションを追加できます。
例:
apiVersion : v1
kind : Pod
metadata :
annotations :
kubernetes.io/ingress-bandwidth : 1M
kubernetes.io/egress-bandwidth : 1M
...
次の項目